Überwachen Sie Ihren KI-Stack mit LLM-Beobachtbarkeit
Erkennen Sie Risiken, lösen Sie Probleme und halten Sie Ihre agentischen und generativen KI-Anwendungen produktionsbereit – mit den End-to-End-Überwachungsfunktionen von Elastic Observability.
Kernfähigkeiten
Beobachten Sie jede Ebene Ihres Agenten-KI-Stacks
Überwachen Sie die Leistung, kontrollieren Sie die Kosten, verfolgen Sie Leitplanken und sorgen Sie dafür, dass GenAI-Workloads zuverlässig ausgeführt werden.




Von Bibliotheken bis zu Modellen – wir haben alles für Sie
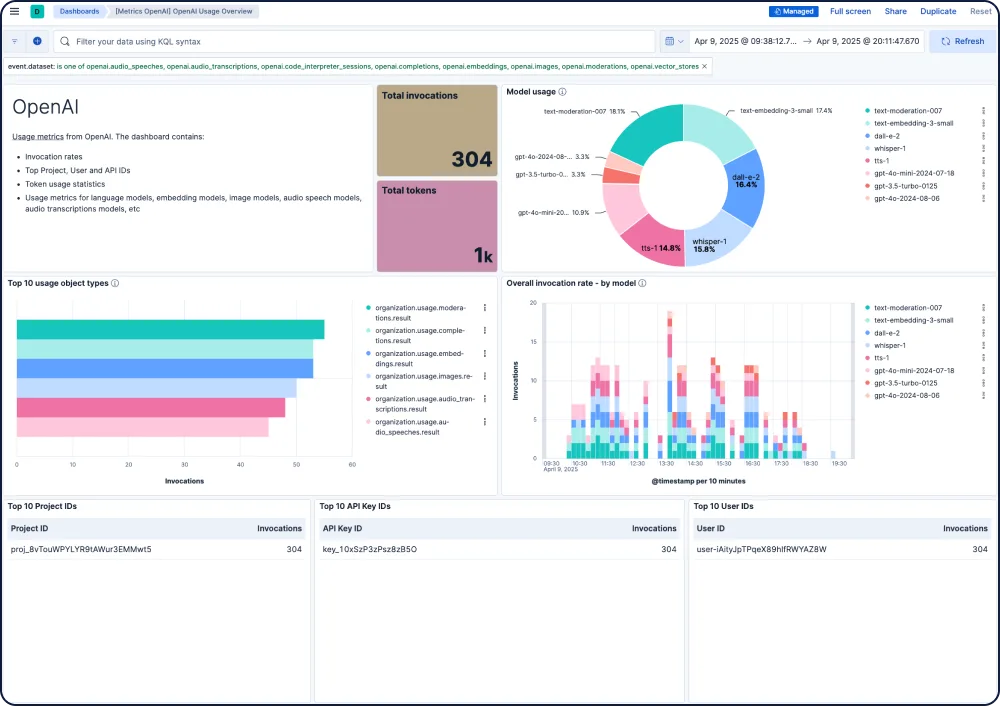
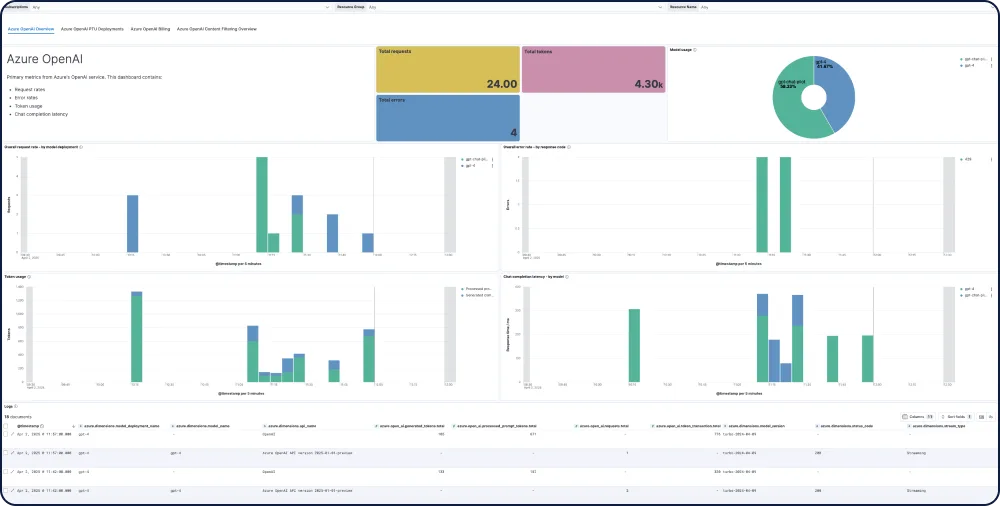
Elastic bietet Ihnen End-to-End-Sichtbarkeit für KI-Apps, integriert sich in beliebte Tracing-Bibliotheken und liefert sofort einsatzbereite Einblicke in Modelle aller großen LLM-Anbieter, einschließlich GPT-4o, Mistral, LLaMA, Anthropic, Cohere und DALL·E.









DASHBOARD-GALERIE
Integrationen und Funktionen für Ihre KI-Apps
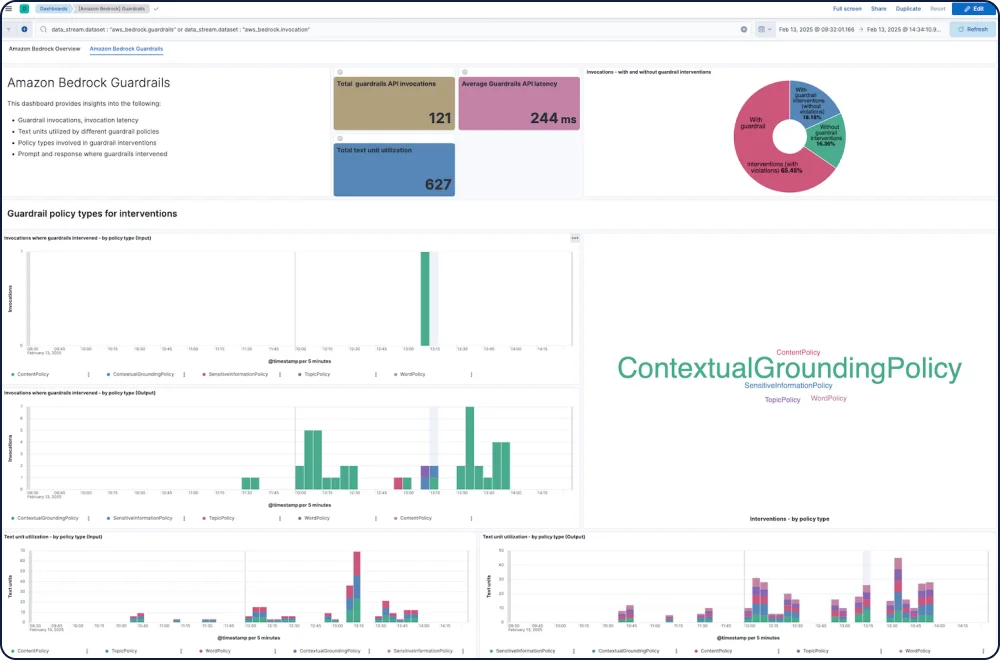
Verfolgen Sie Leistung, Sicherheit und Ausgaben für jedes Modell.
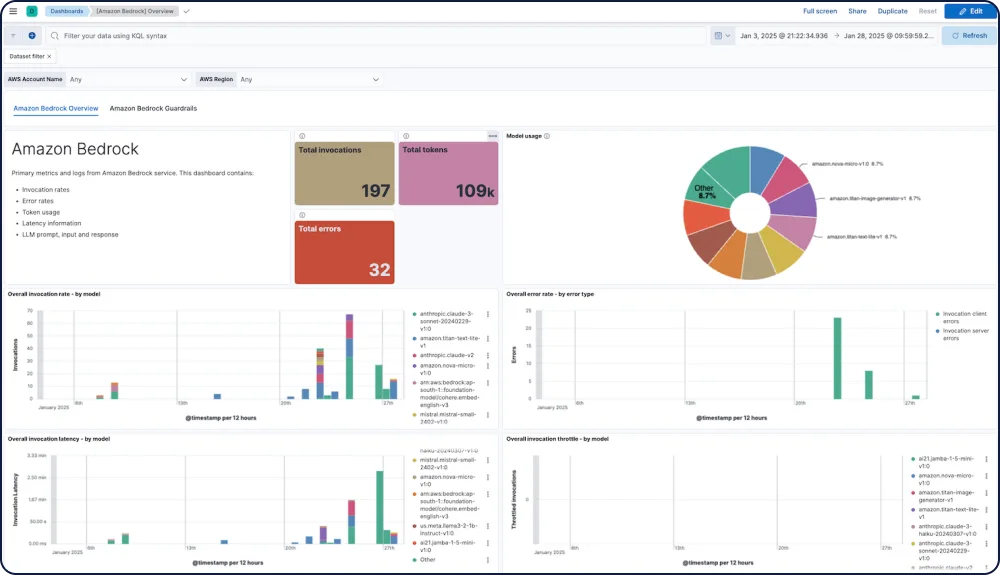
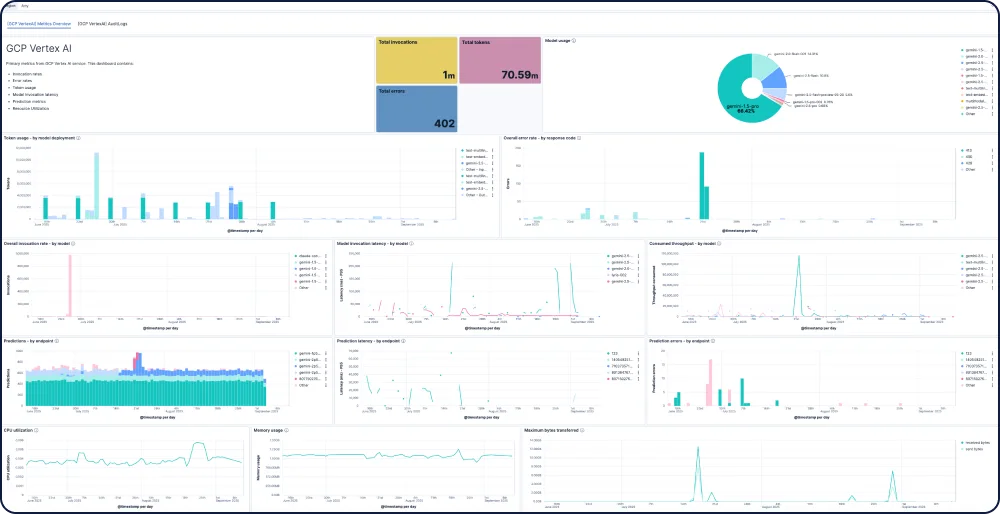
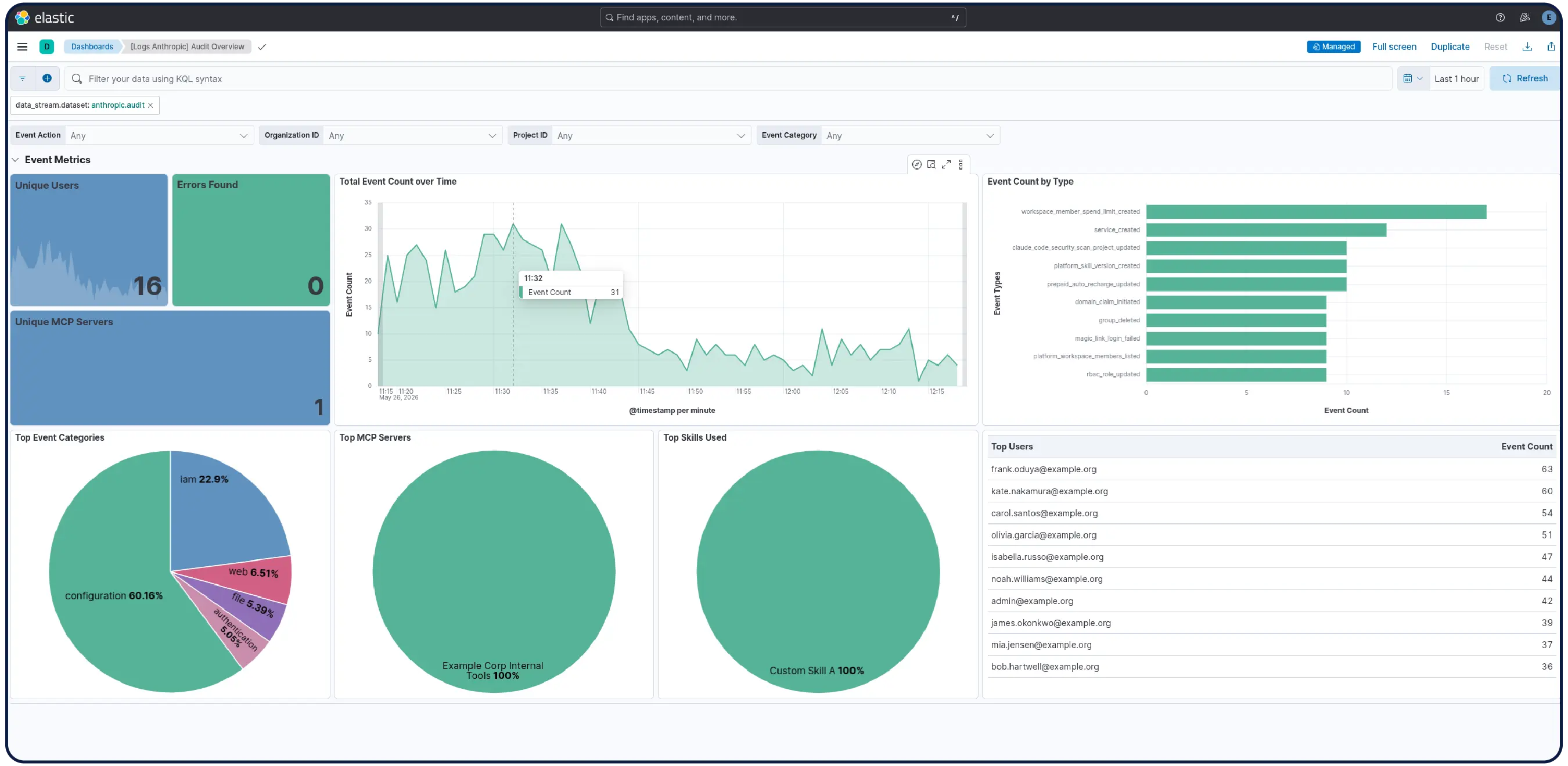
Die Amazon Bedrock-Integration für Elastic Observability bietet umfassende Einblicke in die Leistung, Nutzung und Sicherheit von Amazon Bedrock LLMs, einschließlich für Modelle von Anthropic, Mistral und Cohere.
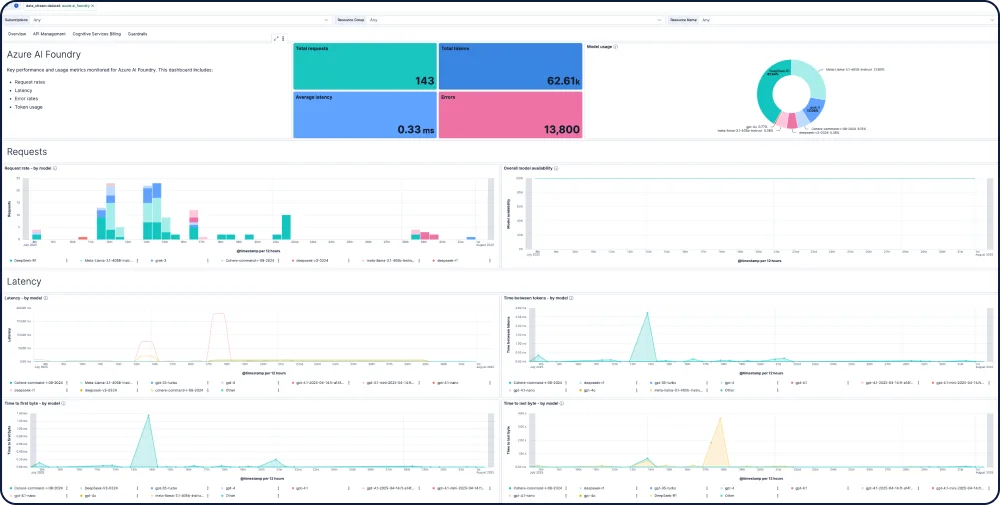
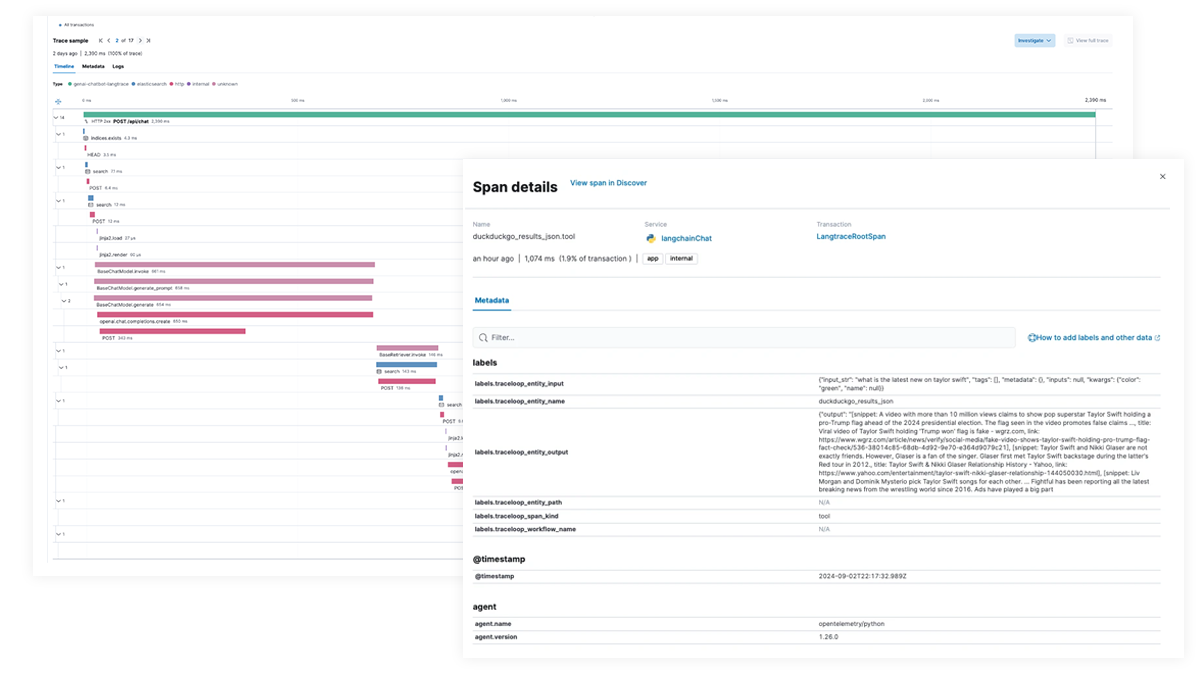
End-to-End-Tracing und -Debugging für KI-Apps und agentische Workflows
Verwenden Sie Elastic APM, um KI-Apps mit OpenTelemetry zu analysieren und Fehler zu beheben, unterstützt durch Elastic Distributions of OpenTelemetry (EDOT) für Python, Java und Node.js sowie durch Tracing-Bibliotheken von Drittanbietern wie LangTrace, OpenLIT und OpenLLMetry.
Probieren Sie die Chatbot-RAG-App von Elastic selbst aus!
Diese Beispiel-App kombiniert Elasticsearch, LangChain und verschiedene LLMs, um einen Chatbot mit ELSER und Ihren privaten Daten zu betreiben.