Kosteneinsparungsstrategien für den Elasticsearch Service: Effizienz bei der Datenspeicherung
Tausende Kunden nutzen den offiziellen Elasticsearch Service (ESS) auf Elastic Cloud, um nicht nur von Elasticsearch, sondern auch von exklusiven Produkten wie Elastic Logs, Elastic APM, Elastic SIEM und anderen zu profitieren. Der ESS, den es inzwischen seit mehr als sieben Jahren gibt, ist der einzige verwaltete Dienst, der das komplette Elasticsearch-Erlebnis mit allen Features, allen Lösungen und der Unterstützung durch seine Macher bietet – und darüber hinaus auch eine Reihe von Vorteilen bei Betrieb und Deployment bietet, die dieses Angebot ergänzen.
In einem früheren Post haben wir erläutert, welche versteckten Netzwerkkosten mit einer SaaS-Lösung verbunden sind, die nicht in derselben Region stationiert ist wie Ihre Dienste, Ihre Infrastruktur oder Ihre Logging-Geräte. Die zusätzlichen Kosten können enorm sein. In diesem Blogpost zeigen wir Ihnen, wie der Elasticsearch Service auf Elastic Cloud Ihnen die Flexibilität gibt, verschiedene Strategien auszuwählen, um die durch steigende Arbeitslasten entstehenden Kosten unter Kontrolle zu halten.
Jede Zunahme bei den Arbeitslasten, ganz besonders in den Bereichen Observability und Security, führt zu einem erhöhten Bedarf an Infrastruktur, damit die durch Anwendungen generierten Logdaten, Metriken, AMP-Traces und Sicherheitsereignisse gespeichert und analysiert werden können. Das wiederum hat zusätzliche Kosten zur Folge. Der ESS bietet eine Reihe von Möglichkeiten, Ihnen bei der Verwaltung Ihrer Daten zu helfen, gleichzeitig die Kosten unter Kontrolle zu halten und dennoch aussagekräftige Daten für längere Zeiträume aufzubewahren – und zur selben Zeit all die nützlichen Funktionen des Elastic Stack, wie Konsolidierung von Daten aus verschiedenen Quellen, Visualisierungsoptionen, Alerting, Anomalieerkennung und mehr, zur Verfügung zu stellen.
Sehen wir uns an, welche Möglichkeiten zur Kosteneinsparung es bei Zeitreihendaten z. B. in Observability- und Sicherheitsanwendungsfällen gibt. Betrachten wir dazu eine der häufigsten Anwendungen für den Elastic Stack: das Infrastruktur-Monitoring. Der Elastic Stack enthält Beats, eine Zusammenstellung leichtgewichtiger Agents, die auf Ihren Clients ausgeführt werden und Ihre Cluster mit Daten versorgen. Metricbeat ist ein häufig verwendeter Agent, mit dem Systemmetriken wie CPU-Auslastung, Datenträger-IOPS oder Container-Telemetrie für Anwendungen gesendet werden, die auf Kubernetes laufen.
Je mehr Sie Ihr Anwendungsportfolio erweitern, desto mehr Speicherplatz benötigen Sie, um die beim Monitoring generierten Metriken aufzubewahren. Eine der Strategien, die Teams heute nutzen, um Zeitreihendaten in den Griff zu bekommen, besteht darin, eine Aufbewahrungszeit festzulegen. Wir zeigen im Folgenden zusätzliche Möglichkeiten für eine effiziente Speicherung, die mit dem ESS standardmäßig genutzt werden können.
Szenario
Zur Illustration der verschiedenen Kosteneinsparungsstrategien gehen wir von einem Cluster aus, das 1.000 Hosts überwacht. Jeder Agent im Cluster erfasst pro Metrik 100 Byte, und alle 10 Sekunden werden 100 Metriken erfasst, die dann 30 Tage lange aufbewahrt werden. Zur Gewährleistung einer hohen Verfügbarkeit wird zudem eine Kopie der Daten im Cluster gespeichert, um einen Datenverlust bei Ausfall eines Knotens zu vermeiden. Berechnen wir nun, wie viel Speicherplatz wir benötigen:
|
|
Zum Speichern dieser Metriken benötigen wir also 5,2 TB Speicherplatz. Um es nicht zu kompliziert zu machen, ignorieren wir den Speicherbedarf, der sich aus dem Betrieb des Elasticsearch-Clusters ergibt.
Das Ganze im Überblick:
| Anzahl der überwachten Hosts | 1.000 |
| Täglich ingestierte Datenmenge in GB | 86,4 GB |
| Aufbewahrungszeit | 30 Tage |
| Anzahl der Kopien | 1 |
| Speicherbedarf (einschließlich Kopien) | 5,184 TB |
Effizientere Speicherung mit Heiß-Warm-Deployments und Index-Lifecycle-Management
Bei Observability-Anwendungsfällen wie Logging und Metriken nimmt der Nutzen von Daten im Laufe der Zeit ab. Teams, die Systemereignisse, plötzliche Spitzen beim Netzwerkverkehr oder Security-Alerts schnell untersuchen wollen, verwenden in der Regel die letzten verfügbaren Daten. Je älter die Daten werden, desto weniger werden sie abgefragt, aber sie befinden sich weiter im Cluster und nutzen dieselben Rechen-, Arbeitsspeicher- und Speicherressourcen wie der Rest des Clusters. Wir haben es also mit zwei sehr verschiedenen Datenzugriffsmustern zu tun, das Cluster ist aber nur für das schnelle Ingestieren und häufige Abfragen optimiert und nicht für das Speichern von Daten, auf die selten zugegriffen wird.
An dieser Stelle kommen die Heiß-Warm-Architekturen in Elasticsearch Service ins Spiel. Bei dieser Deployment-Option existieren in ein und demselben Elasticsearch-Cluster zwei Hardwareprofile nebeneinander. Auf den „heißen“ Datenknoten werden die frisch eingehenden Daten gespeichert und sie sind mit schnelleren Speichermedien ausgestattet, damit die Daten schnell ingestiert und abgerufen werden können. Die „warmen“ Knoten haben eine höhere Speicherdichte und ermöglichen die kostengünstigere Speicherung der Daten über längere Zeiträume.
Im Elasticsearch Service nutzen wir in der Regel für heiße Knoten lokal angeschlossene NVMe-SSDs mit einem RAM-zu-Datenträger-Verhältnis von 1 : 30 und für warme Knoten hochdichte Festplattenlaufwerke (HDDs) mit einem Verhältnis von 1 : 160. Diese leistungsfähige Architektur geht Hand in Hand mit einem anderen wichtigen Feature: dem Index-Lifecycle-Management (ILM). Dank ILM kann das Index-Management im Laufe der Zeit automatisiert werden, um den Prozess der Verlagerung von Daten von heißen Knoten auf warme Knoten zu vereinfachen. Dabei werden Kriterien wie die Indexgröße, die Zahl der Dokumente oder das Alter des Index berücksichtigt.
Mit diesen beiden Features erhalten Sie zwei getrennte Hardwareprofile in Ihrem Cluster und außerdem die Indexautomatisierungstools, die die automatische Verlagerung der Daten zwischen den Knoten ermöglichen.
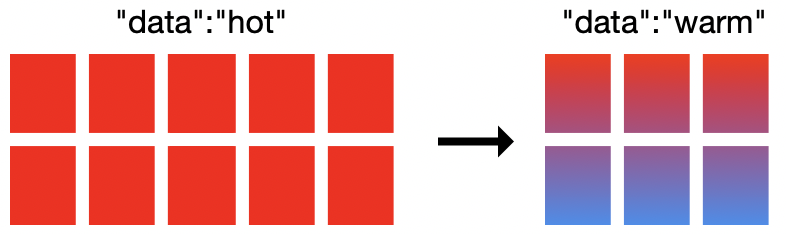
Widmen wir uns damit dem Migrieren auf ein Heiß-Warm-Deployment und dem Konfigurieren von ILM-Richtlinien. Im ESS können Sie ein neues Heiß-Warm-Deployment erstellen und optional einen Snapshot aus einem anderen Cluster wiederherstellen. Wenn Sie bereits ein Deployment mit hoher E/A-Last haben, müssen Sie zum Migrieren auf ein Heiß-Warm-Deployment Ihrem Cluster lediglich warme Knoten hinzufügen. Über eine ILM-Richtlinie können wir festlegen, dass die Daten sieben Tage auf dem heißen Knoten bleiben und anschließend auf die warmen Knoten verschoben werden.
Daten in der Warmphase stehen für das Schreiben von Indizes nicht mehr zur Verfügung. Das eröffnet uns eine weitere Möglichkeit, Kosten zu sparen: Wir brauchen auf den warmen Knoten keine Kopie mehr zu speichern. Sollte ein warmer Knoten ausfallen, würden wir die Daten aus dem zuletzt aufgenommenen Snapshot statt aus der Kopie wiederherstellen.
Der Haken bei diesem Ansatz ist, dass das Wiederherstellen aus einem Snapshot in der Regel länger dauert, sodass bis zur Wiederherstellung mehr Zeit vergeht. Das ist aber in vielen Fällen hinnehmbar, da warme Knoten typischerweise weniger häufig abgefragte Daten enthalten, sodass die Auswirkungen in der Praxis gering sind.
Zum Schluss löschen wir noch die Daten nach Ablauf von 30 Tagen entsprechend unserer ursprünglichen Aufbewahrungsrichtlinie. Die Berechnung erfolgt auf die gleiche Weise wie oben und erbringt folgende Ergebnisse im Überblick:
| Herkömmliches Cluster | Heiß-Warm + ILM | |
| Anzahl der überwachten Hosts | 1.000 | 1.000 |
| Täglich ingestierte Datenmenge in GB | 86,4 GB | 86,4 GB |
| Aufbewahrungszeit | 30 Tage |
Heiß: 7 Tage
Warm: 30 Tage |
| Benötigte Kopien | 1 |
Heiße Knoten: 1
Warme Knoten: 0 |
| Speicherbedarf | 5,184 TB |
Heiß: 1,2096 TB (mit Kopien)
Warm: 1,9872 TB (keine Kopien) |
| Benötigte Clustergröße ca. | 232 GB RAM (6,8 TB SSD-Speicher) |
Heiß: 58 GB RAM mit SSDs
Warm: 15 GB RAM mit HDDs |
| Monatliche Clusterkosten | 3.772,01 $ | 1.491,05 $ |
Mit diesem Ansatz lassen sich bemerkenswerte 60 % der monatlichen Kosten sparen und trotzdem bleiben die Daten durchsuchbar und resilient. Sie können die ILM-Richtlinien nachjustieren, um die idealen Verlagerungszeitpunkte für die maximale Ausschöpfung des Potenzials der Speicherung auf warmen Knoten zu finden.
Freigeben von zusätzlichem Speicherplatz durch Daten-Rollups
Eine weitere Möglichkeit, Speicherplatz zu sparen, besteht darin, Daten-Rollups zu nutzen. Mithilfe der Rollup-APIs können Sie Daten in einem Übersichtsdokument in Elasticsearch zusammenfassen und so kompakter speichern. Die Originaldaten können dann archiviert oder gelöscht werden, um Speicherplatz zu gewinnen.
Beim Erstellen eines Rollups können Sie alle Felder auswählen, die für zukünftige Analysen von Interesse sein könnten. Daraus wird dann ein neuer Index erstellt, der ausschließlich diese Rollup-Daten enthält. Dies ist insbesondere bei Monitoring-Anwendungsfällen hilfreich, in denen es primär um numerische Daten geht, die einfach mit einer höheren Granularität, z. B. auf Minuten-, Stunden- oder sogar Tagesebene, zusammengefasst werden können und dennoch weiterhin das Ablesen von Trends erlauben. Zusammengefasste Indizes sind überall in Kibana verfügbar und können einfach neben vorhandenen Dashboards hinzugefügt werden, damit es beim Analysieren nicht zu Unterbrechungen kommt. All dies kann direkt in Kibana konfiguriert werden.
Im Szenario oben sind wir auf einen Speicherplatz von 5,2 TB gekommen, um Metrikdaten von 1.000 Hosts einschließlich einer Kopie 30 Tage lang so speichern zu können, dass sie weiterhin hoch verfügbar sind. Anschließend haben wir ein Szenario mit einem Heiß-Warm-Deployment besprochen. Jetzt nutzen wir die Daten-Rollup-API, um einen Rollup-Job zu konfigurieren, der ausgeführt wird, wenn die Daten sieben Tage alt sind, was zwar ein klein wenig auf Kosten der Granularität geht, uns aber gleichzeitig viel mehr freien Speicherplatz verschafft.
Dazu richten wir einen Daten-Rollup-Job ein, der die alle 10 Sekunden gespeicherten Metriken in stundenweisen Dokumenten zusammenfasst. Damit können wir unsere älteren Metriken weiterhin auf Stundenebene abrufen und visualisieren und die Abfrageergebnisse in Kibana-Visualisierungen und Lens verwenden, um Trends und Schlüsselmomente in den Daten aufzuspüren. Als Nächstes löschen wir die Originaldokumente, die wir gerade per Rollup zusammengefasst haben, und geben so jede Menge Speicherplatz im Cluster frei. Wie viel Speicher wir für die Daten benötigen, die wir gerade durch das Rollup zusammengefasst haben, lässt sich ausrechnen:
|
|
Die Originaldaten dieser Rollup-Dokumente waren älter als sieben Tage und befanden sich daher in unserem Heiß-Warm-Cluster auf warmen Knoten. Alle diese Daten, die 1,99 TB Speicherplatz belegen, können einfach gelöscht werden. In der Spalte rechts sehen wir, was wir erreicht haben:
| Herkömmliches Cluster | Heiß-Warm + ILM | Heiß-Warm + ILM mit Rollup-Daten | |
| Anzahl der überwachten Hosts | 1.000 | 1.000 | 1.000 |
| Täglich ingestierte Datenmenge in GB | 86,4 GB | 86,4 GB | 86,4 GB |
| Aufbewahrungszeit | 30 Tage |
Heiß: 7 Tage
Warm: 30 Tage |
Heiß: 7 Tage
Warm: 30 Tage |
| Granularität | 10 Sekunden | 10 Sekunden |
Erste 7 Tage: 10 Sekunden
Nach 7 Tagen: 1 Stunde |
| Benötigte Kopien | 1 |
Heiße Knoten: 1
Warme Knoten: 0 |
Heiße Knoten: 1
Warme Knoten: 0 |
| Speicherbedarf | 5,184 TB |
Heiß: 1,2096 TB (mit Kopien)
Warm: 1,9872 TB (keine Kopien) |
Heiß: 1,2096 TB (mit Kopien)
Warm: 5,52 GB (keine Kopien, Rollup-Daten) |
| Benötigte Clustergröße ca. | 232 GB RAM (6,8 TB SSD-Speicher) |
Heiß: 58 GB RAM mit SSDs
Warm: 15 GB RAM mit HDDs |
Heiß: 58 GB RAM mit SSDs
Warm: 2 GB RAM mit HDDs |
| Monatliche Clusterkosten | 3.772,01 $ | 1.491,05 $ | 1.024,92 $ |
Die Unterschiede bei den Kosteneinsparungen sind massiv. Wenn wir unser vorhandenes Heiß-Warm-Cluster um Rollups ergänzen, können wir die Kosten um 31 % reduzieren. Noch beeindruckender sind die Ergebnisse, wenn wir unser letztes Szenario mit einem herkömmlichen Cluster mit nur einer Hardwareschicht vergleichen, denn dann liegt die Ersparnis sogar bei 73 %!
Flexibilität beim Bereitstellen
Es ist wie immer: Jede Methode hat Vor- und Nachteile. Aber Sie haben die Flexibilität, die Strategien so anzupassen, dass Sie genau zu Ihrem Bedarf passen.
Mithilfe der ILM-Richtlinien können Sie anhand der Indexgröße, der Zahl der Dokumente oder des Dokumentalters festlegen, wann die Daten in Ihrem Heiß-Warm-Cluster auf die warmen Knoten verlagert werden sollen. Warme Knoten sind bestens geeignet, große Mengen von Daten effizient zu speichern und so Ihre Kosten für Rechenleistung zu senken. Da die Abfragezeiten nicht mit denen von heißen Knoten mithalten können, empfiehlt sich dieser Ansatz vor allem für Daten, die weniger häufig abgefragt werden.
Mit Daten-Rollups lassen sich Daten in Dokumenten mit geringerer Granularität zusammenfassen, was dann sinnvoll ist, wenn die Daten ein Alter erreicht haben, in dem die ursprüngliche hohe Granularität nicht mehr benötigt wird. Die Quelldokumente können anschließend gelöscht werden, um Speicherkosten zu sparen. Sie können genau festlegen, wann und mit welcher Granularität die Dokumente zusammengefasst werden sollen. Dabei kommt es darauf an, die richtige Balance zu finden, damit Sie Ihre Rollup-Daten weiterhin nutzen können, um wichtige Informationen, z. B. über Trends in einem bestimmten Zeitraum oder über das Systemverhalten bei einer Verkehrsspitze, zu gewinnen.
Sie kennen jetzt die standardmäßig verfügbaren Strategien zur Optimierung von Metrik-Arbeitslasten in Ihrem Elasticsearch-Cluster. Was machen Sie nun aber mit all dem zusätzlichen Speicherplatz? Der Elastic Stack wird weltweit für die verschiedensten Anwendungsfälle genutzt: Logdaten, APM-Traces, Auditereignisse, Endpunktdaten und vieles mehr.
Der Elasticsearch Service auf Elastic Cloud bietet alles, was der Elastic Stack auch bietet, plus die operationale Expertise seiner Macher. Wenn Sie momentan keine neuen Anwendungsfälle für sich erschließen möchten, können Sie Ihr Cluster weiter wie bisher nutzen, dabei aber die Speicherung optimieren. Entweder Sie verlängern die Aufbewahrungszeit Ihrer Daten und speichern noch mehr davon zum selben Preis oder Sie verkleinern Ihr Cluster mit ein paar wenigen Klicks, ohne Abstriche an der Sichtbarkeit zu machen – und sparen Geld.
Sie möchten den Elasticsearch Service auf Elastic Cloud ausprobieren? Nutzen Sie unser Angebot für einen kostenlosen 14-tägigen Test.