Elastic's journey to build Elastic Cloud Serverless
Stateless architecture that auto-scales no matter your data, usage, and performance needs


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
In this blog
Describes architectural decisions made to create Elastic's serverless platform from a stateful system.
- Motivation for Serverless: Shifting customer expectations for simplified infrastructure management and pay-per-use models.
- Architectural Transformation: The evolution from a stateful to a stateless architecture by offloading persistent storage to cloud-native object stores.
- Technical Challenges and Solutions: Optimizing object store efficiency, choosing Kubernetes for orchestration, addressing networking challenges with Cilium, and implementing a robust ingress traffic solution.
- Infrastructure Management: The use of Crossplane for Kubernetes provisioning and a multi-layered approach to managing infrastructure.
- Capacity Management: Strategies to avoid "out of capacity" errors, including priority-based capacity pools and proactive planning.
- Automated Upgrades: Process for automated Kubernetes cluster upgrades to ensure continuous availability.
- Architecture Resilience: Implementation of a cell-based architecture and canary deployments for scalability and fault isolation.
- Control Plane vs. Data Plane: The decision to adopt a "Push Model" for communication between the global control plane and data plane.
- Autoscaling: Development of custom autoscaling controllers that go beyond basic horizontal and vertical scaling to optimize resource allocation for different workloads.
- Flexible Pricing Model: The design of a usage-based pricing model for Observability, Security, and Elasticsearch solutions, supported by a usage and billing pipeline.
How do you take a stateful, performance-critical system like Elasticsearch and make it serverless?
At Elastic, we reimagined everything — from storage to orchestration — to build a truly serverless platform that customers can trust.
Elastic Cloud Serverless is a fully managed, cloud-native platform designed to bring the power of Elastic Stack to developers without the operational burden. In this blog post, we will walk you through why we built it, how we approached the architecture, and what we learned along the way.
Why serverless?
Over the years, customer expectations have shifted dramatically. Users no longer want to concern themselves with the complexities of infrastructure management, such as sizing, monitoring, and scaling. Instead, they seek a seamless experience where they can focus purely on their workloads. This evolving demand pushed us toward building a solution that reduces operational overhead, delivers a frictionless SaaS experience, and introduces a pay-per-use pricing model. By removing the need for customers to manually provision and maintain resources, we created a platform that scales dynamically based on demand while optimizing efficiency.
Milestones
Elastic Cloud Serverless is rapidly expanding to meet customer demand, having reached general availability (GA) on AWS in December 2024, GCP in April 2025, and Azure in June 2025. Since then we have expanded to four regions on AWS, three regions on GCP, and one region on Azure with additional regions planned across all three cloud service providers (CSPs).
Rethinking architecture: From stateful to stateless
Elastic Cloud Hosted (ECH) was originally built as a stateful system, relying on local NVMe-based storage or managed disks to ensure data durability. As Elastic Cloud scaled globally, we saw an opportunity to evolve our architecture to better support operational efficiency and long-term growth. Our hosted approach to managing persistent state across distributed environments proved effective but introduced added operational complexity around node replacements, maintenance, ensuring redundancy across availability zones, and scaling compute-intensive workloads such as indexing and search.
We decided to evolve our system architecture by embracing a stateless approach. The key shift was offloading persistent storage from compute nodes to cloud-native object stores. This delivered multiple benefits: reducing the infrastructure overhead required for indexing, enabling the search/index separation, removing the need for replication, and enhancing data durability by leveraging CSPs’ built-in redundancy mechanisms.
The move to object storage
One of the major shifts in our architecture was using cloud-native object storage as the primary data store. ECH was designed to store data on local NVMe SSDs or managed SSD disks. However, as data volumes grew, so did the challenges of scaling storage efficiently. We then introduced searchable snapshots in ECH, which allowed us to search data directly from object stores, significantly reducing storage costs, but we needed to go further.
A key challenge was determining whether object stores could handle high-ingestion workloads while maintaining the performance level that Elasticsearch users expect. Through rigorous testing and implementation, we validated that object storage could meet the demands of large-scale indexing. The shift to object storage eliminated the need for indexing replication, reduced infrastructure requirements, and provided enhanced durability by replicating data across availability zones, ensuring high availability and resilience.
The below diagram illustrates the new “stateless” architecture compared with existing “ECH” architecture:
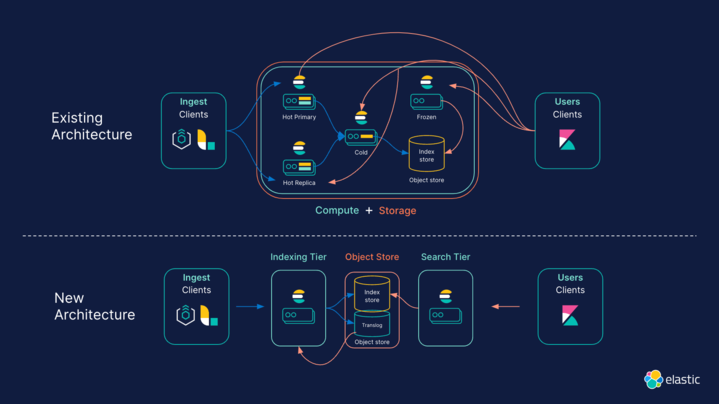
Optimizing object store efficiency
While the shift to object storage delivered operational and durability benefits, it introduced a new challenge: object store API costs. Writes to Elasticsearch — particularly translog updates and refreshes — translate directly into object store API calls, which can scale up quickly and unpredictably, especially under high-ingestion or high-refresh workloads.
To address this, we implemented a per-node translog buffering mechanism that coalesces writes before flushing to the object store, significantly reducing write amplification. We also decoupled refreshes from object store writes, instead sending refreshed segments directly to search nodes while deferring object store persistence. This architectural refinement reduced refresh-related object store API calls by two orders of magnitude, with no compromise to data durability. For more details, please refer to this blog post.
Choosing Kubernetes for orchestration
ECH uses an in-house developed container orchestrator that also powers Elastic Cloud Enterprise (ECE). As the development of ECE started prior to Kubernetes (K8s) existed, we had a choice between extending ECE to support serverless or use K8s for serverless. With the rapid industry-wide adoption of K8s and the growing ecosystem around it, we decided to adopt managed Kubernetes services across CSPs in Elastic Cloud Serverless where it aligns with our operational and scaling goals.
By embracing Kubernetes, we reduced operational complexity, standardized APIs for improved scalability, and positioned Elastic Cloud for long-term innovation. Kubernetes allowed us to focus on higher-value features instead of reinventing container orchestration.
CSP-managed vs. self-managed Kubernetes
While transitioning to Kubernetes, we faced the decision of whether to manage Kubernetes clusters ourselves or use managed Kubernetes services provided by CSPs. Kubernetes implementations vary significantly across CSPs, but to accelerate our deployment timelines and lower operational overhead, we opted for CSP-managed Kubernetes services on AWS, GCP, and Azure. This approach allowed us to focus on building applications and adopting industry best practices rather than dealing with the intricacies of Kubernetes cluster management.
Our key requirements included the ability to provision and manage Kubernetes clusters consistently across multiple CSPs; a cloud-agnostic API for managing compute, storage, and databases; and simplified operations that were cost-efficient. Additionally, by choosing CSP-managed Kubernetes, we were able to contribute upstream to open source projects like Crossplane, improving the overall Kubernetes ecosystem while benefiting from its evolving capabilities.
Networking challenges and the choice of Cilium
Operating Kubernetes at scale with tens of thousands of pods per Kubernetes cluster requires a networking solution that is cloud-agnostic, offers high performance with minimal latency, and supports advanced security policies. We selected Cilium, a modern eBPF-based solution, to address these requirements. Initially, we aimed to implement a uniform self-managed Cilium solution across all CSPs. However, differences in cloud implementations led us to adopt a hybrid approach, using CSP-native Cilium solutions where available while maintaining a self-managed deployment on AWS. This flexibility ensured we could meet our performance and security needs without unnecessary complexity.
Ingress traffic
For ingress, we chose to adapt and continue using our existing, battle-tested proxy from ECH. The evaluation was not simply whether we could replace the proxy with an off-the-shelf solution, but whether we should.
While a standard reverse proxy would provide basic functionality, it would lack differentiating features the ECH proxy already handles. We would have needed to build extensions for ingress traffic filters, support for AWS PrivateLink and Google Cloud Private Service Connect, and FIPS-compliant TLS termination. The existing proxy has also already passed all relevant compliance audits and penetration tests.
Starting with a new solution would have required significant effort for no additional customer value. Adapting our proxy for Kubernetes primarily involved updating how we distribute awareness of service endpoints, leaving the core, well-tested functionality intact. This approach provides several advantages:
It ensures customer-visible behavior remains consistent between ECH and Kubernetes.
Teams can work more efficiently with a familiar, well-understood codebase, especially when implementing new features that would require scripting or extensions in an off-the-shelf solution.
We can advance both our ECH and Kubernetes platforms with a single codebase; therefore, improvements in one environment translate to improvements in the other.
The support teams can leverage their existing knowledge, reducing the learning curve for the new platform.
Kubernetes provisioning layer
After choosing Kubernetes for Elastic Cloud Serverless, we selected Crossplane as the infrastructure management tool. Crossplane is an open source project that extends the Kubernetes API to enable the provisioning and management of cloud infrastructure and services using Kubernetes-native tools and practices. It allows users to provision, manage, and orchestrate cloud resources across multiple CSPs from within a Kubernetes cluster. This is achieved by leveraging Custom Resource Definitions (CRDs) to define cloud resources and controllers to reconcile the desired state specified in Kubernetes manifests with the actual state of cloud resources across multiple CSPs. By utilizing Kubernetes' declarative configuration and control mechanisms, it provides a consistent and scalable way to manage infrastructure as code.
Crossplane enables the management and provisioning of infrastructure using the same tools and methods employed for service deployment. This involves leveraging Kubernetes resources, a consistent GitOps architecture, and unified observability tools. Moreover, developers can establish a complete Kubernetes-based development environment, including its peripheral infrastructure, that mirrors production environments. This is achieved by simply creating a Kubernetes resource, as both environments are generated from the same underlying code.
Managing infrastructure
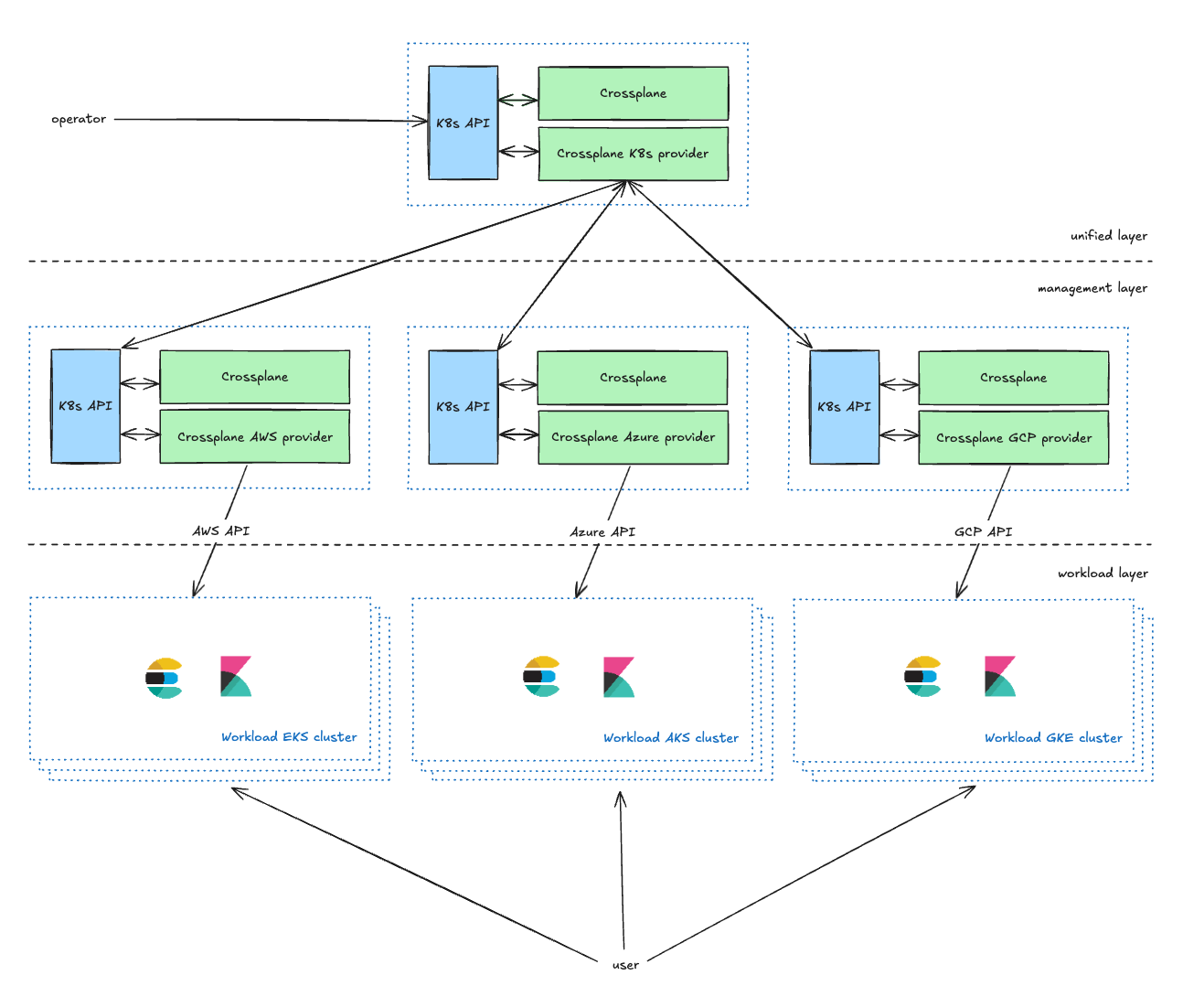
The Unified layer is the operator-facing management layer, providing Kubernetes CRDs for service owners to manage their Kubernetes clusters. They are able to define parameters including the CSP, region, and type (explained in the next section). It enriches operators' requests and forwards them to the Management layer.
The Management layer acts as a proxy between the Unified layer and CSP APIs, transforming requests from the Unified layer to CSP resource requests and reporting the status back to the Unified layer.
In our current setup, we maintain two management Kubernetes clusters for each CSP within every environment. This dual-cluster approach primarily serves two key purposes. Firstly, it allows us to effectively address potential scalability concerns that may arise with Crossplane. Secondly, and more importantly, it enables us to use one of the clusters as a canary environment. This canary deployment strategy facilitates a phased rollout of our changes, starting with a smaller, controlled subset of each environment, minimizing risk.
The Workload layer contains all the kubernetes workload clusters running applications that users interact with (Elasticsearch, Kibana, MIS, etc.).
Managing cloud capacity: Avoiding "out of capacity" errors
A common assumption is that cloud capacity is infinite, but in reality, CSPs impose constraints that can lead to "out of capacity" errors. If an instance type is unavailable, we have to continuously retry or switch to an alternative instance type.
To mitigate this in Elastic Cloud Serverless, we implemented priority-based capacity pools, allowing workloads to migrate to use new/other capacity pools when necessary. Additionally, we invested in proactive capacity planning, reserving compute resources ahead of demand surges. These mechanisms ensure high availability while optimizing resource utilization.
Keeping up to date
Kubernetes cluster upgrades are time-consuming. To streamline this, we utilize a fully automated end-to-end process, requiring manual intervention solely for issues that cannot be automatically resolved. Once internal testing is complete and a new Kubernetes version is approved, we configure that centrally. An automated system then initiates the control plane upgrade for each cluster, with controlled concurrency and a specific order. Subsequently, custom Kubernetes controllers perform blue-green deployments to upgrade the nodepools. Despite the fact that customer pods migrate to different K8s nodes during this process, project availability and performance remain unaffected.
Architecture resilience
We use a cell-based architecture, which enables us to provide both scalable and resilient services. Every Kubernetes cluster, along with its peripheral infrastructure, is deployed in a separate CSP account to enable proper scaling without being affected by CSP limits and to provide maximum security and isolation. Individual workloads, each a separate cell, manage specific aspects of the system. These cells operate independently, enabling isolated scaling and management. This modular design minimizes the reach of failures and facilitates targeted scaling, avoiding system-wide impacts. To further minimize potential impact from issues, we employ canary deployments both for our applications and the underlying infrastructure.
Control Plane vs. Data Plane: The Push Model
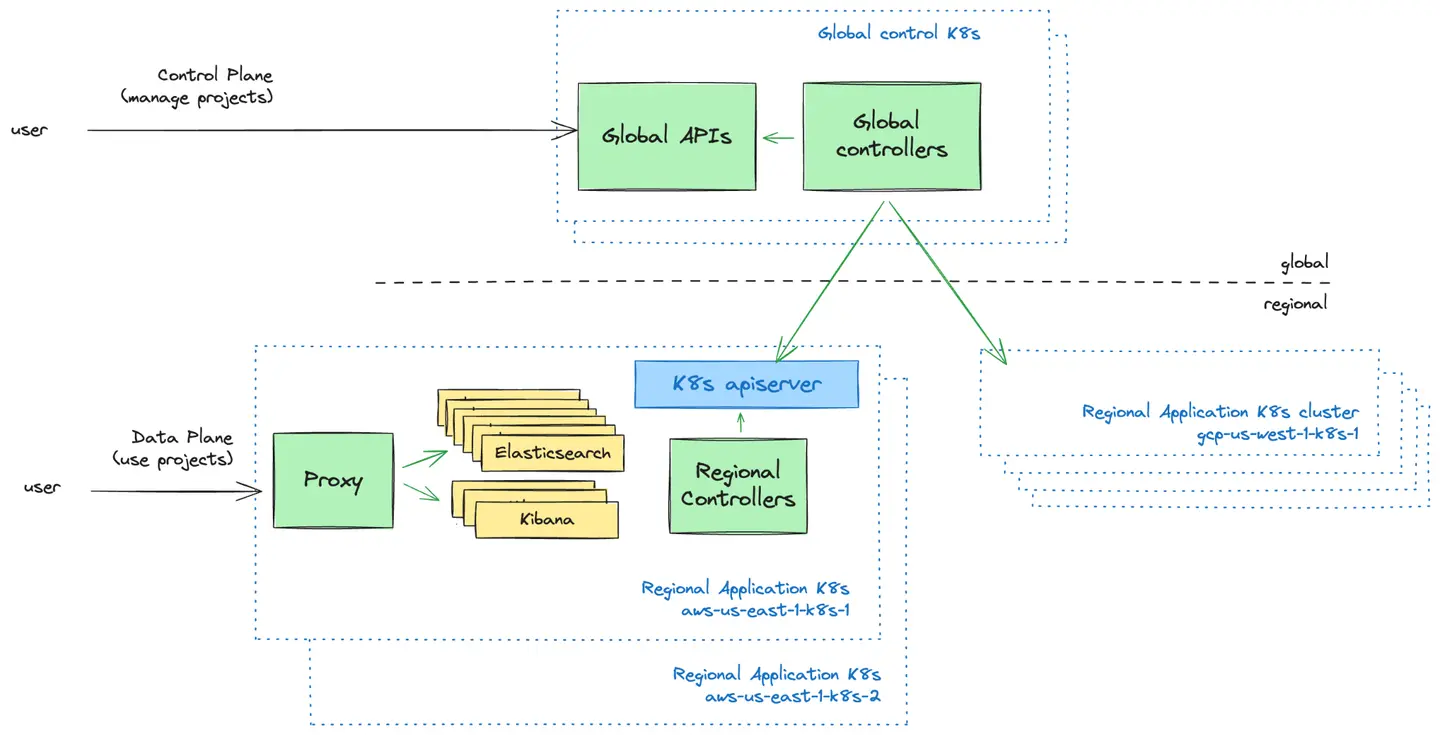
The Control Plane is the user-facing management layer. We provide UIs and APIs for users to manage their Elastic Cloud Serverless projects. This is where users can create new projects, control who has access to their projects, and get an overview of their projects.
The Data Plane is the infrastructure layer that powers the Elastic Cloud Serverless projects and that users interact with when they want to use their projects.
A fundamental design decision we faced was how the global control plane should communicate with Kubernetes clusters in the data plane. We explored two models:
Push Model: The control plane proactively pushes configurations to regional Kubernetes clusters.
Pull Model: Regional Kubernetes clusters periodically fetch configurations from the control plane.
After evaluating both approaches, we adopted the Push Model due to its simplicity, unidirectional data flow, and ability to operate Kubernetes clusters independently from the control plane during failures. This model allowed us to maintain straightforward scheduling logic while reducing operational overhead and failure recovery complexities.
Autoscaling: Beyond horizontal and vertical scaling
To deliver a truly serverless experience, we needed an intelligent autoscaling mechanism that dynamically adjusted resources based on workload demands. Our journey began with basic horizontal scaling, but we quickly realized that different services had unique scaling needs. Some required additional compute resources, while others demanded higher memory allocation.
We evolved our approach by building custom autoscaling controllers that analyze real-time, workload-specific metrics, enabling dynamic scaling that’s both responsive and resource-efficient. As a result, we can seamlessly scale both indexing and search tier operations for Elasticsearch without over-provisioning for Elasticsearch. This strategy enables the use of multidimensional pod autoscaling, allowing workloads to scale horizontally and vertically based on CPU, memory, and custom, workload-generated metrics.
For our Elasticsearch workloads, we use a serverless specific Elasticsearch API that returns certain key metrics about the cluster. Here’s how it works: Recommenders suggest the necessary compute resources (replicas, memory, and CPU) and storage for a given tier. These recommendations are then converted by mappers into concrete compute and storage configurations applicable to containers. To prevent rapid scaling fluctuations, stabilizers filter these recommendations. Limiters then come into play, enforcing both minimum and maximum resource constraints. The limiter's output is used to patch the Kubernetes deployment after taking into consideration some optional restriction policies.
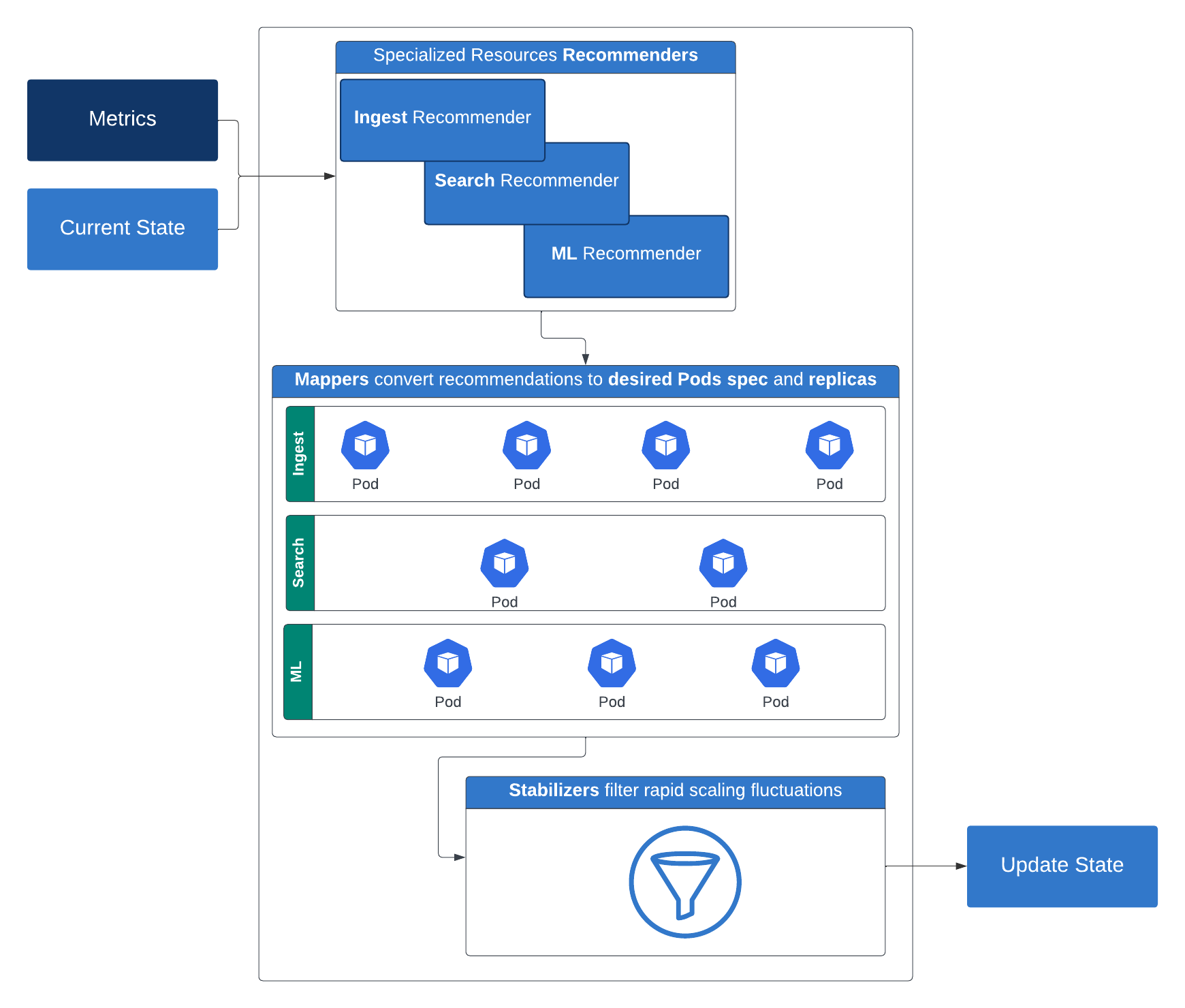
This layered, intelligent scaling strategy ensures performance and efficiency across diverse workloads — and it’s a big step toward a truly serverless platform.
Elastic Cloud Serverless introduces nuanced autoscaling capabilities tailored for the search tier — leveraging inputs such as boosted data windows, search power settings, and search load metrics (including thread pool load and queue load). These signals work together to define baseline configurations and trigger dynamic scaling decisions based on customer search usage patterns. For a deeper dive into search tier autoscaling, read this blog post. To learn more about how indexing tier autoscaling works, check out this blog post.
Building a flexible pricing model
A key principle of serverless computing is aligning costs with actual usage. We wanted a pricing model that was simple, flexible, and transparent. After evaluating various approaches, we designed a model that balances different workloads across our core solutions:
Observability and Security: Charged based on data ingested and retained, with tiered pricing
Elasticsearch (Search): Pricing based on virtual compute units, including ingest, search, machine learning, and data retention
This approach provides customers with pay as per use pricing, offering greater flexibility and cost predictability.
In order to implement this pricing model (which underwent many iterations during the development phase), we knew we needed a scalable and flexible architecture. Ultimately, we built a pipeline that supports a distributed ownership model, with different teams responsible for different components of the end-to-end process. Below, we describe the two main segments of this pipeline: metered usage collection via the usage pipeline, and billing calculations via the billing pipeline.
Usage pipeline
User-facing components like Elasticsearch and Kibana send metered usage data to the usage-api service, which runs in each workload cluster. This service performs some enrichment on the data and then puts it on a queue. The usage-shipper service then pulls this data from the queue and forwards it on to object storage. This decoupled architecture is necessary in order to make the pipeline resilient when shipping data across regions and CSPs, because we prioritize delivery over latency. Once the data reaches object storage, it is available to other processes in a read-only manner for further transformations or aggregations (e.g., for billing or analytics).
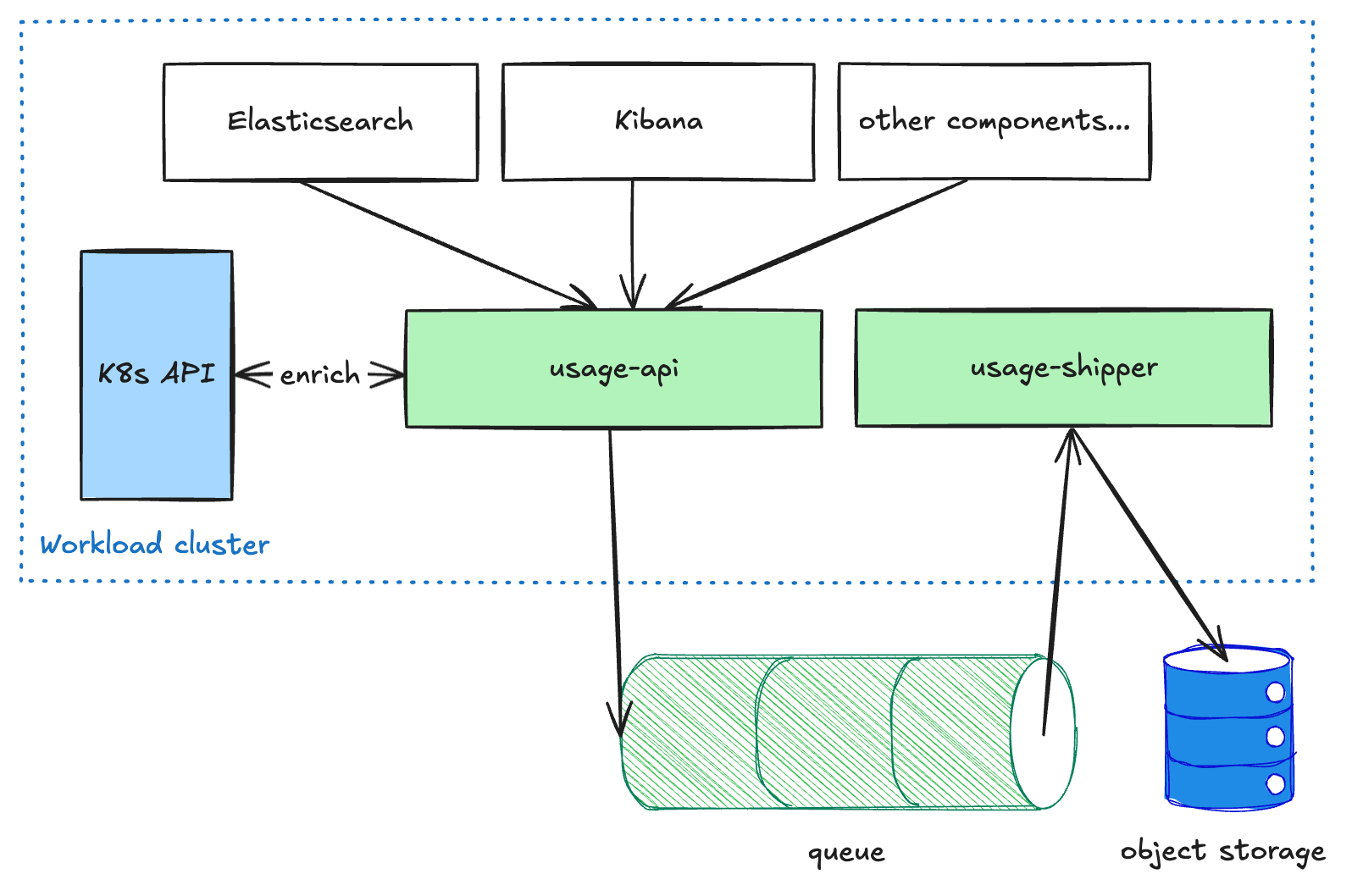
Billing pipeline
Once usage records are deposited in object storage, the billing pipeline picks up the data and turns it into quantities of ECU (Elastic Consumption Units, our currency-agnostic billing unit) that we bill for. The basic process looks like this:
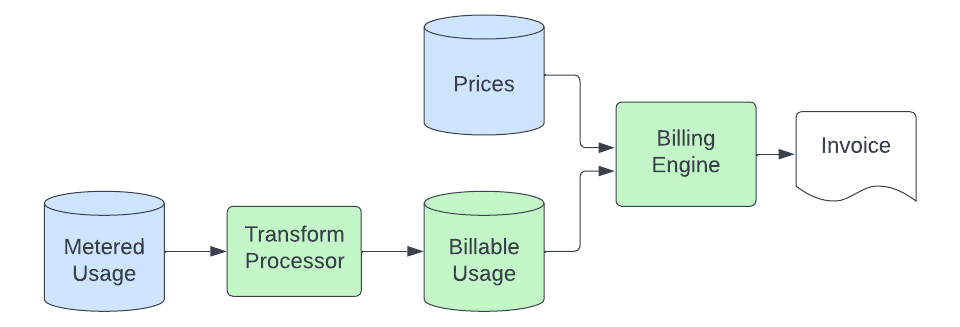
A transform process consumes the metered usage records from object storage and turns them into records that can actually be billed. This process involves unit conversion (the metered application may measure storage in bytes, but we may bill in GB), filtering out usage sources that we don't bill for, mapping the record to a specific product (this involves parsing metadata in the usage records to tie the usage to a solution-specific product that has a unique price), and sending this data to an Elasticsearch cluster which is queried by our billing engine. The purpose of this transform stage is to provide a centralized place where logic lives to convert the generic metered usage records into product-specific quantities that are ready to be priced. This enables us to keep this specialized logic out of the metered applications and the billing engine, which we want to keep simple and product-agnostic.
The billing engine then rates these billable usage records, which now contain an identifier that maps to a product in our prices database. At a minimum, this process entails summing the usage over a given period and multiplying the quantity by the product's price to compute the ECUs. In some cases, it must additionally segment the usage into tiers based on cumulative usage throughout the month and map these to individually priced product tiers. In order to tolerate delays in the upstream process without missing records, usage is billed at the time it arrives in the billable usage datastore, but it’s priced according to when it occurred (to ensure we don't apply the wrong price for usage that arrived "late"). This provides a "self-healing" capability to our billing process.
Finally, once the ECUs are computed, we assess any add-on costs (such as for support) and then feed this into the billing calculations, which ultimately result in an invoice (sent by us or one of our cloud marketplace partners). This final part of the process is not new or unique to Serverless and is handled by the same systems that bill our Hosted product.
Takeaways
Building an infrastructure platform that provides similar functionality across multiple CSPs is a complex challenge. Balancing reliability, scalability, and cost-efficiency requires continuous iteration and trade-offs. Kubernetes implementations vary significantly across cloud service providers, and ensuring a consistent experience across them necessitates extensive testing and customization.
Furthermore, adopting a serverless architecture is not just a technical transformation but also a cultural shift. It requires transitioning from reactive troubleshooting to proactive system optimization and prioritizing automation to minimize operational burden. Through our journey, we have learned that building a successful serverless platform is as much about architectural decisions as it is about fostering a mindset that embraces continuous innovation and improvement.
Looking ahead
Success in the serverless world depends on delivering an exceptional customer experience, proactively optimizing operations, and continuously balancing reliability, scalability, and cost efficiency. Looking ahead, our focus remains on building new features for our customers on Elastic Cloud Serverless, making serverless the best place to run Elasticsearch for everyone.
The future of search, security, and observability is here without compromise on speed, scale, or cost. Experience Elastic Cloud Serverless and Search AI Lake to unlock new opportunities with your data. Learn more about the possibilities of serverless or start your free trial now.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, and associated marks are trademarks, logos, or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos, or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print