GPUs go brrr! Elastic Inference Service (EIS): GPU-accelerated inference for Elasticsearch
_(1).png)

 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
We are excited to announce the Elastic Inference Service (EIS), which introduces GPU-accelerated inference that’s natively integrated with Elasticsearch on Elastic Cloud.
Elasticsearch is the most widely deployed vector and semantic search database. Modern search and AI workloads depend on fast, scalable inference for embeddings, reranking, and language models. As volumes grow, managing infrastructure, testing models, handling integrations, and stitching together point solutions add heavy operational lift. This has created a clear customer need for managed GPU-accelerated fleets that deliver speed, scalability, and cost efficiency without the operational overhead of infrastructure or integrations. The Elastic Inference Service is designed to provide inference-as-a-service and to provide embedding, reranking, and large and small language models as a service at scale. We have also designed EIS to be a multi-cloud service provider (CSP), multi-region, and multimodal service to meet all of your long-term inference needs.
EIS already provides access to a state-of-the-art large language model (LLM), which in turn powers out-of-the-box AI features for automatic ingest, threat detection, problem investigation, root cause analysis, and more for Playground and AI assistants. We are now thrilled to bring Elastic Learned Sparse EncodeR (ELSER) — Elastic’s built-in sparse vector model for state-of-the-art search relevance — as the first text-embedding model on EIS in technical preview. ELSER powers a majority of the semantic search use cases on our platform and provides industry-leading relevance and performance. This is just the beginning; additional models for multilingual embeddings, reranking, and models from Jina.ai, which recently joined Elastic via acquisition, are on the way to further expand what’s possible.
State-of-the-art architecture and performance
EIS provides a scalable architecture with modern NVIDIA GPUs to deliver low-latency, high-throughput inference. GPUs allow machine learning (ML) models to process many calculations in parallel, boosting overall efficiency by an order of magnitude.
EIS gives Elasticsearch users a fast inference experience while simplifying setup and workflow management. The service ensures consistent superior performance and developer experience by providing easy-to-consume inference through APIs for end-to-end semantic_text experience, generating vector embeddings and using LLMs to power context engineering and agentic workflows.
-
Streamlined developer experience: No model downloads, manual configuration, or resource provisioning needed. EIS integrates directly with semantic_text and the inference APIs for a delightful developer experience. There are no cold starts when deploying models and no need to implement your own automatic scaling.
- Improved end-to-end semantic search experience: Sparse vectors, dense vectors, or semantic reranking — we have you covered. More models coming soon!
- Enhanced performance: GPU-accelerated inference provides consistent latency and up to 10x better ingest throughput compared to CPU-based alternatives, especially at higher loads.
- Simplified generative AI (GenAI) workflows: Skip the friction of external services, API keys, and contracts. With Elastic Managed LLM, AI features for ingest, investigation, detection, and analysis work out of the box from day one.
- Backward compatibility: Existing Elasticsearch ML nodes remain supported while the inference API gives you full flexibility to connect any third-party service.
- Easy-to-understand pricing: EIS provides consumption-based pricing similar to other inference services charged per model per million tokens. Elastic also indemnifies all models developed by Elastic and its subsidiaries provided on EIS, making it easy to get started and access support.
- Access: Elastic Cloud Serverless and Elastic Cloud Hosted deployments in all CSPs and regions can access the inference endpoints on EIS.
The following diagrams outline the evolution of inference in Elasticsearch from self-managed, CPU-based workflows to the GPU-optimized, fully integrated Elastic Inference Service.
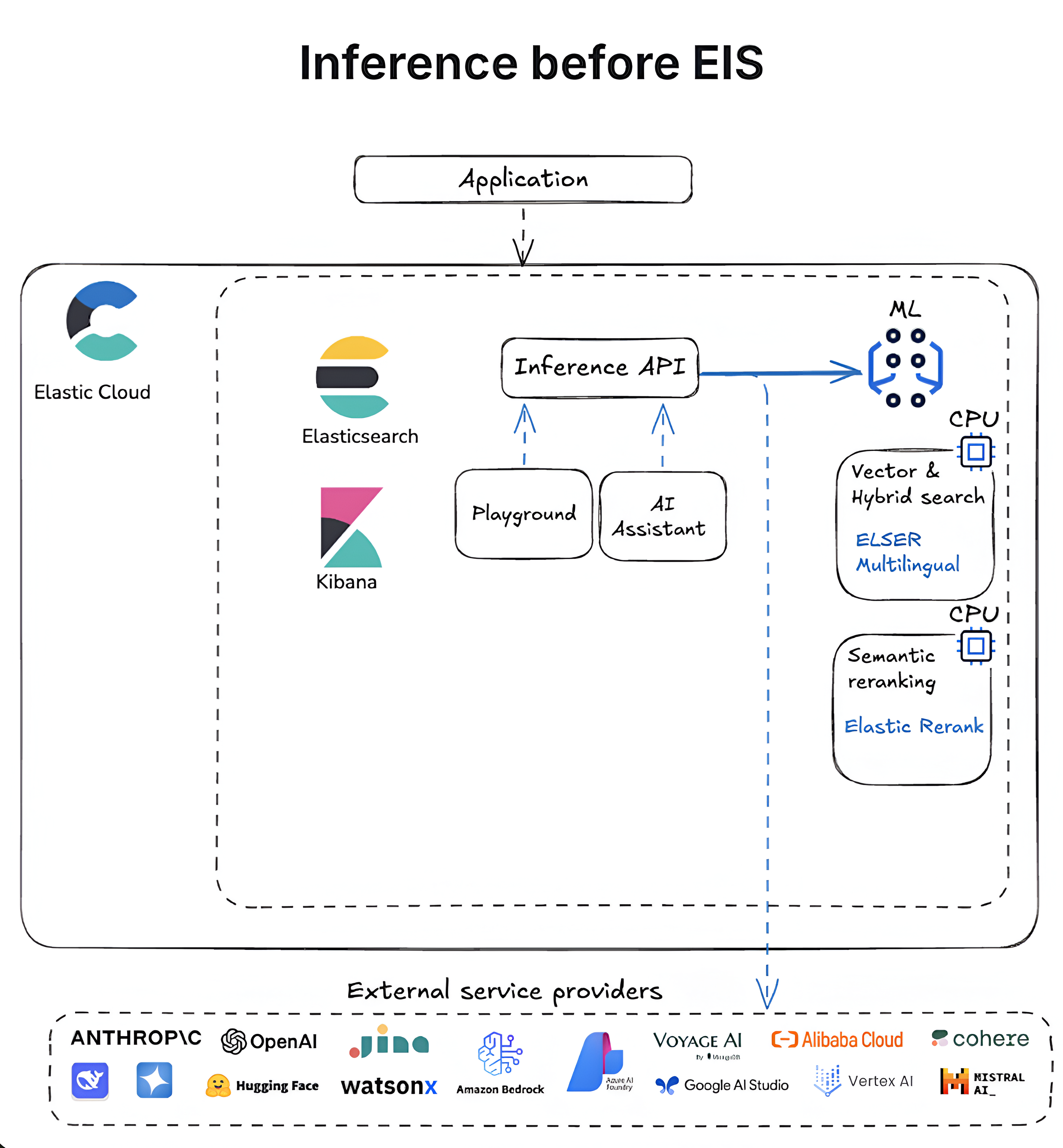
What's next?
We are working on many exciting improvements to the Elastic Inference Service to power a wide variety of use cases. Some major ones include:
More models: We are expanding our model catalogue to meet the growing inference needs of our customers. Over the coming months, we’ll introduce new models on EIS to support a wider variety of search and inference needs, including:
Multilingual embedding model for semantic search
Semantic reranking model for enhanced semantic search and improved keyword-based search
Multimodal embedding and reranking models
Small language models (SLMs)
More LLMs
We will continue to add more types of models, so if there’s a model you’d like to see, reach out to us at support@elastic.co.
More CSPs and regions: We are working on expanding the coverage to more CSPs and regions soon. For current availability, see our docs.
- Simplified semantic search: Semantic search with semantic_text, a field type in query, simplifies the inference workflow by providing inference at ingestion time and sensible default values automatically. Very soon, semantic_text will start defaulting to the ELSER endpoint on the Elastic Inference Service.
- More love for self-managed customers: Our self-managed users can join the fun soon. In the near future, Cloud Connected Mode will bring EIS to self-managed environments, reducing operational overhead and enabling hybrid architectures and scaling where it works best for you.
We have many more exciting improvements that we are focused on, so please reach out to us if you have any questions.
Try EIS on Elastic Cloud
With seamless workflows, real-time insights, and accelerated performance, EIS empowers developers to build faster, more efficient GenAI applications within the Elastic ecosystem.
All Elastic Cloud trials have access to the Elastic Inference Service. Try it now on Elastic Cloud Serverless and Elastic Cloud Hosted.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, and associated marks are trademarks, logos or registered trademarks of elasticsearch B.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print