Detecting unusual network activity with Elastic Security and machine learning
As we’ve shown in a previous blog, search-based detection rules and Elastic’s machine learning-based anomaly detection can be a powerful way to identify rare and unusual activity in cloud API logs. Now, as of Elastic Security 7.13, we’ve introduced a new set of unsupervised machine learning jobs for network data, and accompanying alert rules, several of which look for geographic anomalies. In this blog post, we’ll explore a case study demonstrating how network data can yield important detections.
Before the advent of endpoint detection and response (EDR) tools, security teams relied heavily on network instrumentation like firewall logs and intrusion detection (IDS) alerts. Given the lack of process information or user context, in network logs, the false positive rate for network events could be high at times, and host-based live response could be slow and uncertain. During live response — the intermediate step between incident, alert, or case triage and formal forensics — analysts would examine hosts or assets to determine whether they had been compromised. This can be slow, and inaccurate, when analysts lack hands-on access to hosts and need to work through intermediaries or wait for information requests to be fulfilled.
The rise of EDR tooling, and the rich information it provides, gives us a much faster, clearer, and complete picture of what is going on in a host operating system and whether a genuine compromise or malware infestation is present. Over the years, considerable debate has taken place as to whether detection teams should use network or endpoint events based on their relative merits. A better solution, rather than forcing security teams to choose one set of logs or another, is to use a sort of “nuclear triad” of detection data — the combination of endpoint, cloud, and network data.
The “nuclear triad”
The crux of my business case for the combination of endpoint, cloud, and network data is similar to the raison d’etre of the so-called “nuclear triad” — the proverbial eggs-in-one-basket condition. The nuclear triad refers to a three-pronged strategic doctrine intended to provide for a high level of deterrence by making strategic nuclear forces so robust and diverse that it becomes infeasible to try to develop plans to neutralize them in a first strike. The triad consists of a mix of air, land, and sea-based nuclear forces: long-range bombers, ballistic missiles, and “boomers” — submarines capable of launching smaller ballistic missiles after approaching a target. No identifiable strategy can neutralize enough of the triad to reduce the threat of a counter-strike enough to make a first strike plan strategically viable to a nuclear war planner.
The combination of the three detection data types — endpoint, cloud, and network data — poses a similar problem for threat actors. They may tamper with endpoint data sources or operate from hosts without instrumentation, but their command and control (C2) will still be visible in the network logs. Simply put, no single element of the triad provides for guaranteed detection of all threats under all scenarios — such an expectation is not reasonable. Of course, combining the three elements of the detection triad does not provide for guaranteed detection either, but the possibility of something being missed by all three is exponentially lower than relying on one or another alone. Let’s consider an example case study where network data yielded an important detection.
A case study
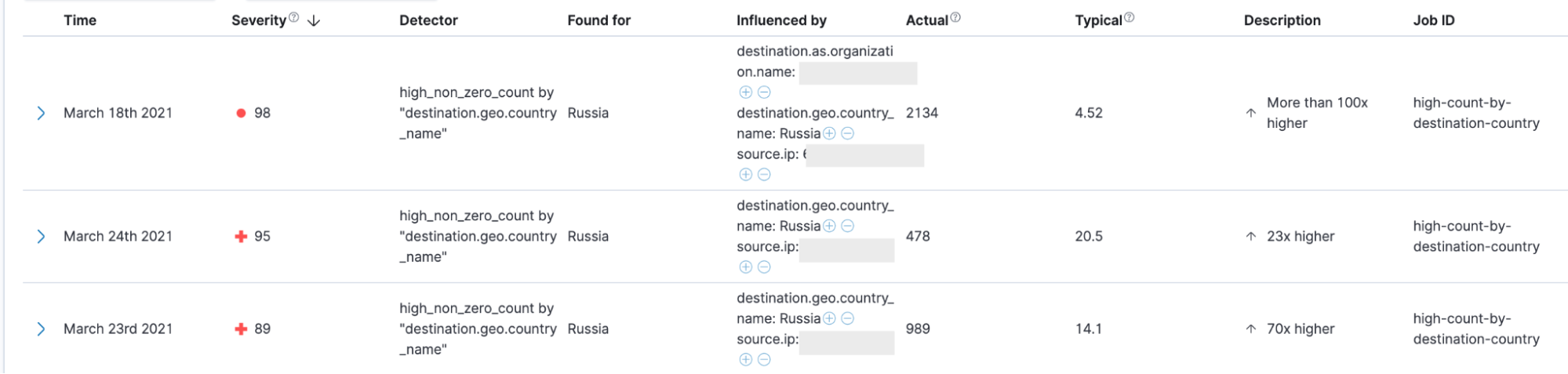
I developed a set of network anomaly detection rules after making an accidental discovery, as I sometimes do when sifting data. I had sort of borrowed (for research purposes) a prod cluster containing, among other things, a medium-sized set of firewall logs. While sifting and plotting the network data, along geographic lines, I noticed that Russia was in the top 3 destination countries for the destination IP addresses that had been geolocated. This was odd because there were no workflows or business relationships of size with Russian organizations (and because Russian activity is sort of top-of-mind today simply due to recent events)
I like to have at least one confirmation from a system owner that activity is actually anomalous before raising the question of an incident. Not every anomaly is an incident, and not every incident is critical. In this case, the system owner felt the Russian IP address activity was quite inexplicable, so we proceeded to chat with a larger group, including the team leads whose infrastructure inhabited the network in question. We got on a Zoom and traced the source of the traffic back to a smaller enclave firewall, which was a NAT point, so we needed to read its logs to identify the pre-NAT source of the traffic. The source was a Windows instance in a lab where malware was occasionally detonated. Lacking endpoint events, we ran netstat in a one-second loop, while piped to a text file, as we once did, before the invention of endpoint detection and response (EDR) tools.
We determined that the traffic was coming from a malware process running in a lab. The nature of the lab was that Windows VMs would be spun up, with Windows endpoint events shipping to a local cluster, and the whole thing would be spun down after a matter of days. Due to an imperfection in the enclave firewall rules, HTTPS traffic was being allowed out of the enclave and being denied downstream at the border firewall. Because of the up-and-down nature of the lab, the Windows events and logs were not preserved after a given environment was spun down, so these events were not available in the main SOC clusters for detection. The only indicators and logs of the activity in the main clusters were the firewall logs from the border firewall that was denying the traffic. So, in this case, ingesting and analyzing network logs was valuable because it yielded an important detection that might have otherwise been missed.

We could debate whether the lab endpoint events should have been forwarded or preserved, and perhaps they should have been. Unfortunately, though, endpoint coverage is rarely complete in any given organization. Consider the many possible scenarios where exceptions and gaps may occur:
- Systems owned by independent business units, in highly federated organizations, may lack endpoint instrumentation, or may lack modern EDR-like instrumentation. Or the different business units may use incompatible endpoint tooling, or the data may be siloed in a way that makes them inaccessible to other InfoSec teams or groups.
- Consultants and/or contractors may arrive with infected laptops. These laptops, being managed by their organization, may send logs and events to an inaccessible cluster owned by their organization or simply have no modern logs or instrumentation. These may also be personal or BYOD devices that contain no modern instrumentation or logging. Visitors may also bring infected devices.
- As in my case study, laboratory or other temporary workload instances may not preserve or forward logging or instrumentation.
- Cloud instances that do not use standard templates, or are not managed by cloud orchestration and automation tooling, may lack instrumentation or logging.
- Cloud instances started by hand or by a rogue user may contain no instrumentation or logging.
- Cloud (or terrestrial) workload instances that have been tampered with by a rogue user may have instrumentation and logging disabled.
- Large fleets of virtual machines or container workloads may lack endpoint events or OS-level instrumentation due to the “thundering herd” problem where vast fleets of cloud workloads are started and stopped as compute workloads wax and wane. Additional challenges monitoring cloud workloads include the time and effort cost of instrumenting, and disambiguating data from, a fleet of ephemeral workloads.
In all of these scenarios, network monitoring can provide a valuable detection mechanism for things that could otherwise be missed.
Anomaly detection for network monitoring
Enriching network logs with geographic data and analyzing geographic patterns has long been used as an analysis technique for network security monitoring. Geographic analysis — looking for anomalous geographical relationships — in network data is a simple technique, but I like it for a few reasons. Geographic analysis, and geographic anomalies, have led to investigations that produced some of the largest cases I have worked on. I find that geographic data often contains surprises when first analyzed — things the organization needs to know. Geographic detection often works simply because malware infrastructure typically sits in the country the malware developers call home. Malware developers can, of course, locate infrastructure in the same country as the victims, as we saw in the SolarWinds case — but they usually don’t bother. Malware campaigns and incidents are often a transnational affair with command and control (C2 traffic crossing geographic and political borders. For all of these reasons, malware and persistence mechanism traffic may produce anomalous geographic relationships when network traffic is mapped and geolocated.