Você deseja obter a certificação da Elastic? Descubra quando será realizado o próximo treinamento do Elasticsearch Engineer! Você pode iniciar um teste gratuito na nuvem ou experimentar o Elastic na sua máquina local agora.
Quantização automática de bytes no Lucene
Embora o HNSW seja uma maneira poderosa e flexível de armazenar e pesquisar vetores, ele exige uma quantidade significativa de memória para funcionar rapidamente. Por exemplo, consultar vetores float32 de 1 milhão de dimensões e 768 dimensões requer aproximadamente de RAM. Quando você começa a pesquisar um número significativo de vetores, isso se torna caro. Uma forma de usar cerca de menos memória é através da quantização de bytes. O Lucene, e consequentemente o Elasticsearch, já suportam a indexação de vetores há algum tempo, mas a construção desses vetores era responsabilidade do usuário. Isso está prestes a mudar, pois introduzimos a quantização escalar no Lucene.
Quantização escalar 101
Todas as técnicas de quantização são consideradas transformações com perda dos dados brutos. Significa que algumas informações são perdidas em função do espaço disponível. Para uma explicação detalhada da quantização escalar, veja: Quantização Escalar 101. Em termos gerais, a quantização escalar é uma técnica de compressão com perdas. Uma matemática simples permite economizar espaço significativamente com pouco impacto na capacidade de memorização.
Explorando a arquitetura
Quem já está acostumado a trabalhar com o Elasticsearch provavelmente já conhece esses conceitos, mas aqui vai uma breve visão geral da distribuição de documentos para pesquisa.
Cada índice do Elasticsearch é composto por múltiplos shards. Embora cada fragmento só possa ser atribuído a um único nó, vários fragmentos por índice proporcionam paralelismo computacional entre os nós.
Cada fragmento é composto por um único Índice Lucene. Um índice Lucene consiste em múltiplos segmentos somente leitura. Durante a indexação, os documentos são armazenados em buffer e periodicamente transferidos para um segmento somente leitura. Quando determinadas condições são atendidas, esses segmentos podem ser mesclados em segundo plano, formando um segmento maior. Tudo isso é configurável e possui seu próprio conjunto de complexidades. Mas, quando falamos de segmentos e fusão, estamos falando de segmentos Lucene somente leitura e da fusão periódica automática desses segmentos. Aqui está uma análise mais aprofundada sobre a fusão de segmentos e as decisões de design.
Quantização por segmento no Lucene
Cada segmento no Lucene armazena o seguinte: os vetores individuais, os índices do grafo HNSW, os vetores quantizados e os quantis calculados. Por uma questão de brevidade, vamos nos concentrar em como o Lucene armazena vetores quantizados e brutos. Para cada segmento, mantemos o controle dos vetores brutos no arquivo , dos vetores quantizados e de um único multiplicador corretivo de ponto flutuante em , além dos metadados relativos à quantização no arquivo .

Figura 1: Layout simplificado de um arquivo de armazenamento vetorial bruto. Ocupa de espaço em disco, já que os valores têm 4 bytes. Como estamos utilizando quantização, esses dados não serão carregados durante a busca por HNSW. Eles só são usados se forem especificamente solicitados (por exemplo, força bruta secundária via reavaliação), ou para requantização durante a fusão de segmentos.

Figura 2: Layout simplificado do arquivo arquivo. Ocupa de espaço e será carregado na memória durante a busca. Os bytes servem para contabilizar o multiplicador corretivo de ponto flutuante, usado para ajustar a pontuação visando maior precisão e melhor recuperação da informação.

Figura 3: Layout simplificado do arquivo de metadados. Aqui, monitoramos a quantização e a configuração vetorial, juntamente com os quantis calculados para este segmento.
Assim, para cada segmento, armazenamos não apenas os vetores quantizados, mas também os quantis usados na criação desses vetores quantizados e os vetores brutos originais. Mas, afinal, por que ainda guardamos os vetores brutos?
Quantização que cresce com você
Como o Lucene periodicamente limpa os segmentos para que fiquem somente leitura, cada segmento possui apenas uma visão parcial de todos os seus dados. Isso significa que os quantis calculados se aplicam diretamente apenas a esse conjunto de amostras do total de seus dados. Isso não é um grande problema se sua amostra representar adequadamente todo o seu conjunto de dados. Mas o Lucene permite que você classifique seu índice de várias maneiras. Portanto, você pode estar indexando dados classificados de uma forma que introduza viés nos cálculos de quantis por segmento. Além disso, você pode apagar os dados quando quiser! Seu conjunto de amostras pode ser minúsculo, até mesmo contendo apenas um vetor. Outro fator complicador é que você tem controle sobre quando as fusões ocorrem. Embora o Elasticsearch tenha configurações padrão e mesclagem periódica definidas, você pode solicitar uma mesclagem sempre que desejar por meio da API _force_merge . Como podemos, então, manter toda essa flexibilidade e, ao mesmo tempo, fornecer uma boa quantização que proporcione uma boa recuperação?
A quantização vetorial do Lucene se ajustará automaticamente ao longo do tempo. Como o Lucene foi projetado com uma arquitetura de segmentos somente leitura, temos a garantia de que os dados em cada segmento não foram alterados e demarcações claras no código para quando as coisas podem ser atualizadas. Isso significa que, durante a fusão de segmentos, podemos ajustar os quantis conforme necessário e, possivelmente, requantizar os vetores.
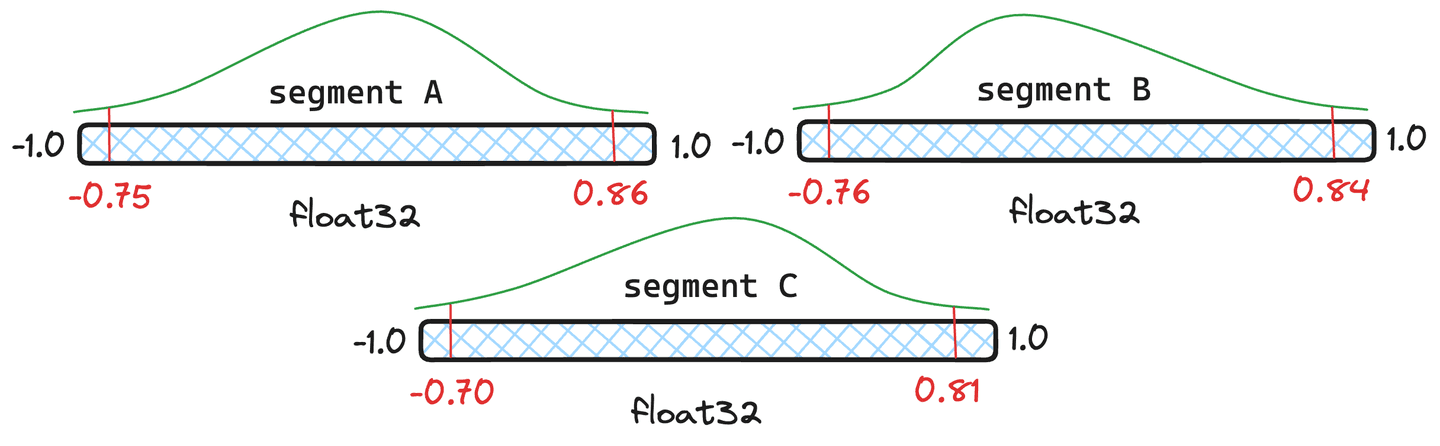
Figura 4: Três exemplos de segmentos com diferentes quantis.
Mas a requantização não é cara? Possui alguma sobrecarga, mas o Lucene lida com quantis de forma inteligente e só requantiza completamente quando necessário. Vamos usar os segmentos da Figura 4 como exemplo. Vamos atribuir e , e apenas documentos ao segmento O Lucene calculará a média ponderada dos quantis e, se o quantil resultante da fusão for suficientemente próximo dos quantis originais do segmento, não será necessário requantizar esse segmento, utilizando-se os quantis recém-combinados.
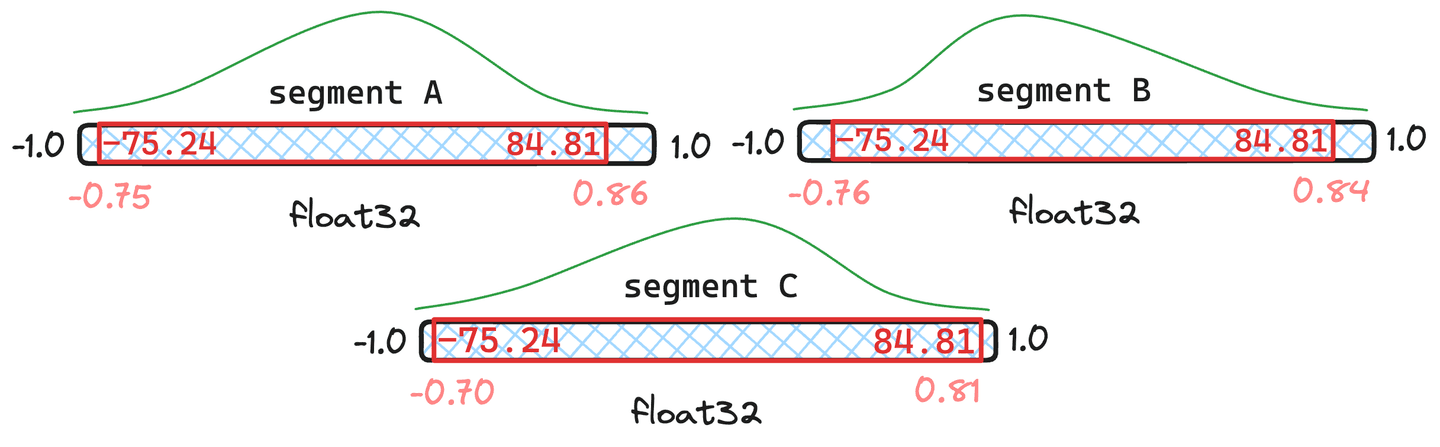
Figura 5: Exemplo de quantis combinados onde os segmentos e têm documentos e tem apenas .
Na situação visualizada na figura 5, podemos ver que os quantis resultantes da fusão são muito semelhantes aos quantis originais em e Portanto, eles não justificam a quantização dos vetores. O segmento parece desviar-se demasiado. Consequentemente, os vetores em seriam requantizados com os valores de quantil recém-combinados.
Existem, de fato, casos extremos em que os quantis combinados diferem drasticamente de quaisquer quantis originais. Neste caso, iremos extrair uma amostra de cada segmento e recalcular completamente os quantis.
Desempenho e números da quantização
Então, é rápido e ainda oferece boa capacidade de memorização? Os números a seguir foram coletados executando o experimento em uma instância c3-standard-8 do GCP. Para garantir uma comparação justa com usamos uma instância grande o suficiente para armazenar vetores brutos na memória. Indexamos vetores do Cohere Wiki usando o método do produto interno máximo.
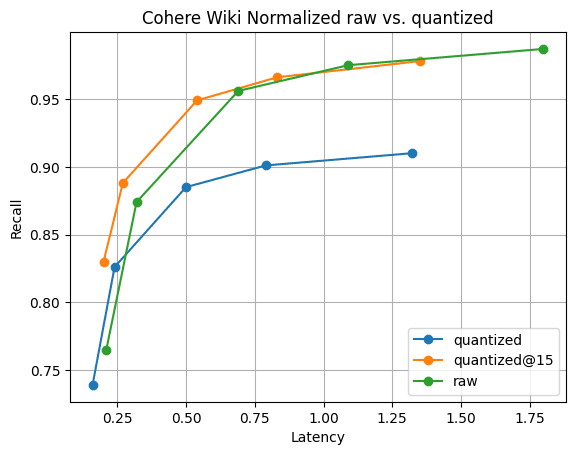
Figura 6: Recall@10 para vetores quantizados versus vetores brutos. O desempenho de busca de vetores quantizados é significativamente mais rápido do que o de vetores brutos, e a recuperação é rapidamente possível reunindo apenas mais 5 vetores; visível por .
A Figura 6 ilustra a história. Embora haja uma diferença na recordação, como era de se esperar, ela não é significativa. Além disso, a diferença na taxa de recall desaparece ao coletar apenas mais 5 vetores. Tudo isso com fusões de segmentos mais rápidas e 1/4 da memória dos vetores .
Conclusão
O Lucene oferece uma solução única para um problema difícil. Não há necessidade de uma etapa de "treinamento" ou "otimização" para a quantização. No Lucene, simplesmente funcionará. Não há necessidade de se preocupar com a possibilidade de ter que "re-treinar" seu índice vetorial caso seus dados mudem. O Lucene detectará mudanças significativas e cuidará disso automaticamente ao longo da vida útil dos seus dados. Aguardem ansiosamente o momento em que implementaremos essa funcionalidade no Elasticsearch!
Perguntas frequentes
O que é quantização escalar?
A quantização escalar é uma técnica de compressão com perdas. Uma matemática simples permite economizar espaço significativamente com pouco impacto na capacidade de memorização.
Conteúdo relacionado

10 de abril de 2026
Clustering não supervisionado de documentos com Elasticsearch + embeddings Jina
Uma abordagem prática e reproduzível para clustering não supervisionado de documentos com Elasticsearch e embeddings Jina.

2 de janeiro de 2026
Automatização da análise de logs no Streams com ML
Descubra como uma abordagem híbrida de ML alcançou 94% de precisão na análise de logs e 91% na partição de logs por meio de experimentos de automação com impressão digital de formato de log no Streams.

3 de setembro de 2025
Filtragem de pesquisa vetorial: Mantenha a relevância
Realizar uma busca vetorial para encontrar os resultados mais semelhantes a uma consulta não é suficiente. Muitas vezes, é necessário usar filtros para refinar os resultados da pesquisa. Este artigo explica como funciona a filtragem para busca vetorial no Elasticsearch e no Apache Lucene.

3 de abril de 2025
Geração de filtros e facetas usando aprendizado de máquina.
Explorando as vantagens e desvantagens de automatizar a criação de filtros e facetas em uma experiência de busca usando modelos de aprendizado de máquina versus a abordagem clássica de codificação fixa.

7 de abril de 2025
Acelerando a fusão de gráficos HNSW
Explore o trabalho que temos feito para reduzir a sobrecarga de construção de vários gráficos HNSW, particularmente reduzindo o custo de mesclagem de gráficos.