O Elasticsearch conta com integrações nativas com as principais ferramentas e provedores de IA generativa do setor. Confira nossos webinars sobre como ir além do básico do RAG ou criar aplicativos prontos para produção com o banco de dados vetorial da Elastic.
Para criar as melhores soluções de busca para seu caso de uso, inicie um teste gratuito na nuvem ou experimente o Elastic em sua máquina local agora mesmo.
O modelo de agente de recuperação LangGraph é um projeto inicial desenvolvido pela LangChain para facilitar a criação de sistemas de perguntas e respostas baseados em recuperação usando o LangGraph no LangGraph Studio. Este modelo é pré-configurado para integração perfeita com o Elasticsearch, permitindo que os desenvolvedores criem rapidamente agentes que podem indexar e recuperar documentos de forma eficiente.
Este blog se concentra na execução e personalização do modelo do agente de recuperação LangChain usando o LangGraph Studio e o LangGraph CLI. O modelo fornece uma estrutura para a criação de aplicativos de geração aumentada de recuperação (RAG), aproveitando vários backends de recuperação, como o Elasticsearch.
Orientaremos você na configuração do ambiente e na execução eficiente do modelo com o Elastic, ao mesmo tempo em que personalizamos o fluxo do agente.
Pré-requisitos
Antes de prosseguir, certifique-se de ter o seguinte instalado:
- Implantação do Elasticsearch Cloud ou implantação do Elasticsearch no local (ou crie uma avaliação gratuita de 14 dias no Elastic Cloud) - Versão 8.0.0 ou superior
- Python 3.9+
- Acesso a um provedor de LLM como Cohere (usado neste guia), OpenAI ou Anthropic/Claude
Criando o aplicativo LangGraph
1. Instale o LangGraph CLI
2. Crie o aplicativo LangGraph a partir do modelo de agente de recuperação
Será apresentado um menu interativo que permitirá que você escolha entre uma lista de modelos disponíveis. Selecione 4 para Agente de Recuperação e 1 para Python, conforme mostrado abaixo:
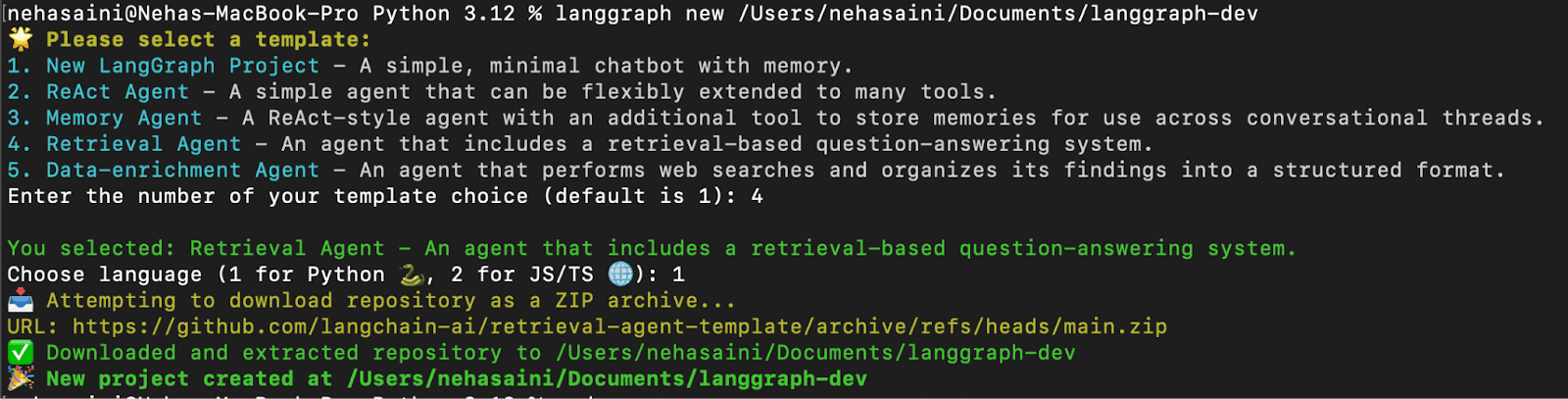
- Solução de problemas: se você encontrar o erro “urllib.error.URLError: <erro urlopen [SSL: CERTIFICATE_VERIFY_FAILED] falha na verificação do certificado: não é possível obter o certificado do emissor local (_ssl.c:1000)> “
Execute o comando Instalar Certificado do Python para resolver o problema, conforme mostrado abaixo.

3. Instalar dependências
Na raiz do seu novo aplicativo LangGraph, crie um ambiente virtual e instale as dependências no modo edit para que suas alterações locais sejam usadas pelo servidor:
Configurando o ambiente
1. Crie um arquivo .environment arquivo
O arquivo .env contém chaves de API e configurações para que o aplicativo possa se conectar ao LLM e ao provedor de recuperação escolhidos. Gere um novo arquivo .env duplicando a configuração de exemplo:
2. Configure o arquivo .env arquivo
O arquivo .env vem com um conjunto de configurações padrão. Você pode atualizá-lo adicionando as chaves de API e os valores necessários com base na sua configuração. Quaisquer chaves que não sejam relevantes para seu caso de uso podem ser deixadas inalteradas ou removidas.
- Exemplo de arquivo
.env(usando Elastic Cloud e Cohere)
Abaixo está um exemplo de configuração .env para usar o Elastic Cloud como provedor de recuperação e o Cohere como LLM, conforme demonstrado neste blog:
Observação: embora este guia utilize o Cohere para geração de respostas e incorporações, você pode usar outros provedores de LLM, como OpenAI, Claudeou até mesmo um modelo de LLM local, dependendo do seu caso de uso. Certifique-se de que cada chave que você pretende usar esteja presente e definida corretamente no arquivo.env.
3. Atualize o arquivo de configuração - configuration.py
Depois de configurar seu arquivo .env com as chaves de API apropriadas, a próxima etapa é atualizar a configuração do modelo padrão do seu aplicativo. Atualizar a configuração garante que o sistema use os serviços e modelos que você especificou no seu arquivo .env .
Navegue até o arquivo de configuração:
O arquivo configuration.py contém as configurações de modelo padrão usadas pelo agente de recuperação para três tarefas principais:
- Modelo de incorporação – converte documentos em representações vetoriais
- Modelo de consulta – processa a consulta do usuário em um vetor
- Modelo de resposta – gera a resposta final
Por padrão, o código usa modelos do OpenAI (por exemplo, openai/text-embedding-3-small) e do Anthropic (por exemplo, anthropic/claude-3-5-sonnet-20240620 and anthropic/claude-3-haiku-20240307).
Neste blog, estamos mudando para o uso de modelos Cohere. Se você já estiver usando OpenAI ou Anthropic, nenhuma alteração será necessária.
Exemplos de alterações (usando Cohere):
Abra configuration.py e modifique os padrões do modelo conforme mostrado abaixo:
Executando o agente de recuperação com a CLI do LangGraph
1. Inicie o servidor LangGraph
Isso iniciará o servidor LangGraph API localmente. Se isso for executado com sucesso, você deverá ver algo como:
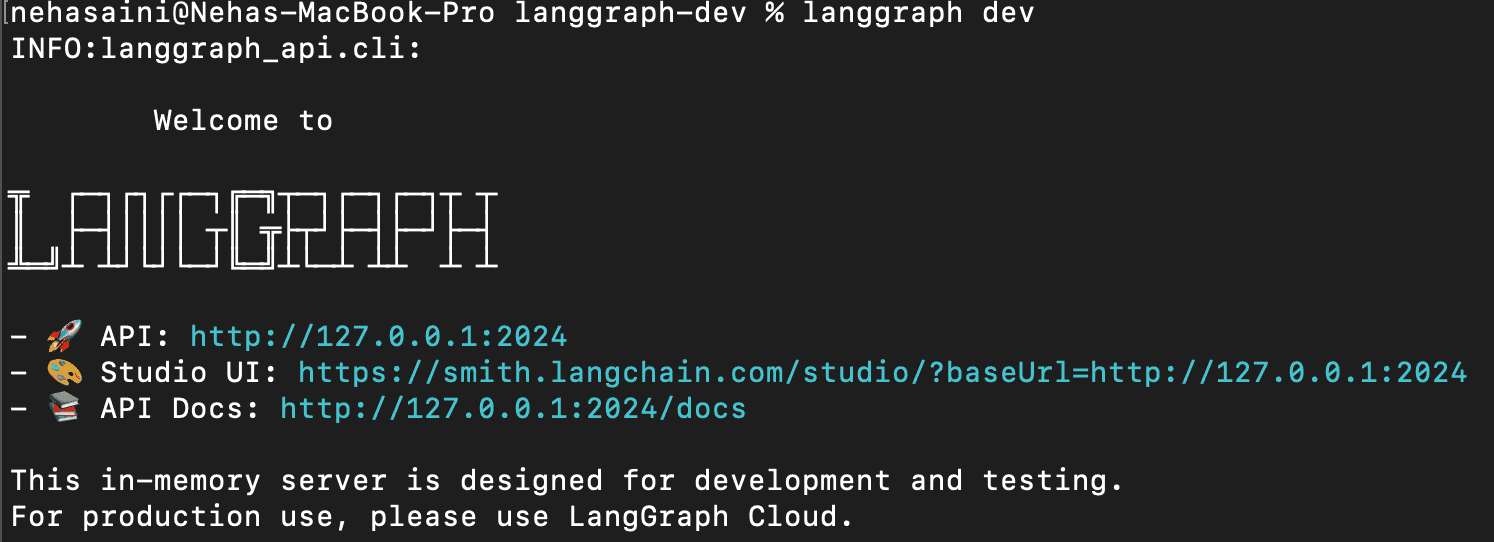
URL da interface do usuário do Open Studio.
Há dois gráficos disponíveis:
- Gráfico de recuperação: Recupera dados do Elasticsearch e responde à consulta usando um LLM (Language-Level Model).
- Gráfico do indexador: Indexa documentos no Elasticsearch e gera embeddings usando um LLM.

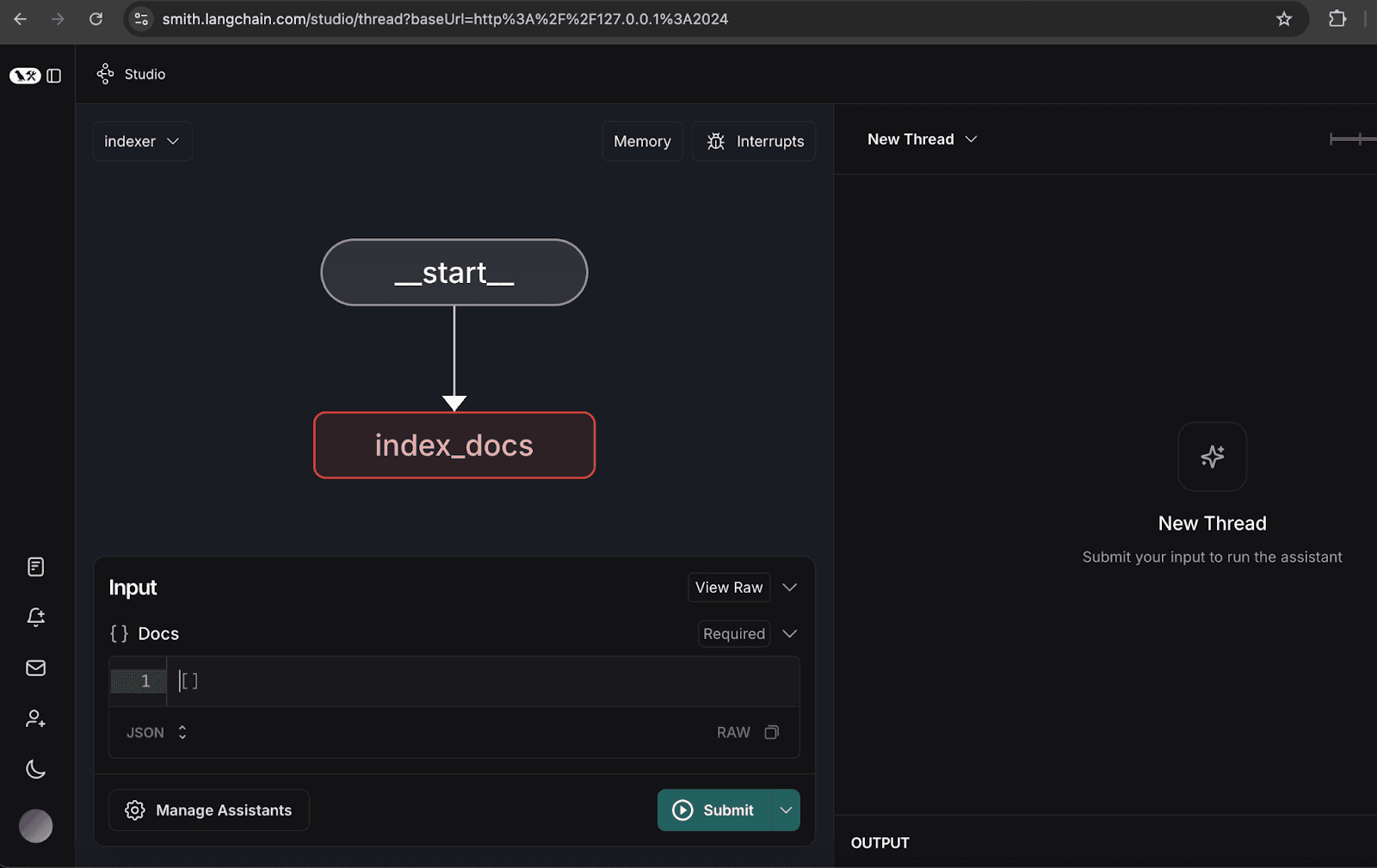
2. Configurando o gráfico do indexador
- Abra o gráfico do indexador.
- Clique em Gerenciar assistentes.
- Clique em 'Adicionar novo assistente ', insira os dados do usuário conforme especificado e, em seguida, feche a janela.


3. Indexação de documentos de amostra
- Indexe os seguintes documentos de exemplo, que representam um relatório trimestral hipotético para a organização NoveTech:
Depois que os documentos forem indexados, você verá uma mensagem de exclusão no tópico, conforme mostrado abaixo.

4. Executando o grafo de recuperação
- Mude para o gráfico de recuperação.
- Digite a seguinte consulta de pesquisa:

O sistema retornará documentos relevantes e fornecerá uma resposta exata com base nos dados indexados.
Personalize o agente de recuperação.
Para melhorar a experiência do usuário, introduzimos uma etapa de personalização no grafo de recuperação para prever as próximas três perguntas que um usuário poderá fazer. Essa previsão se baseia em:
- Contexto dos documentos recuperados
- Interações anteriores do usuário
- Última consulta do usuário
As seguintes alterações de código são necessárias para implementar o recurso de Previsão de Consulta:
1. Atualize o arquivo graph.py
- Adicione a função
predict_query:
- Modifique a função
respondpara retornar o objetoresponse, em vez da mensagem:
- Atualizar estrutura do gráfico para adicionar novo nó e aresta para predict_query:
2. Atualize o arquivo prompts.py
- Crie um prompt para previsão de guery em
prompts.py:
3. Atualize o arquivo configuration.py
- Adicionar
predict_next_question_prompt:
4. Atualize o arquivo state.py
- Adicione os seguintes atributos:
5. Execute novamente o grafo de recuperação.
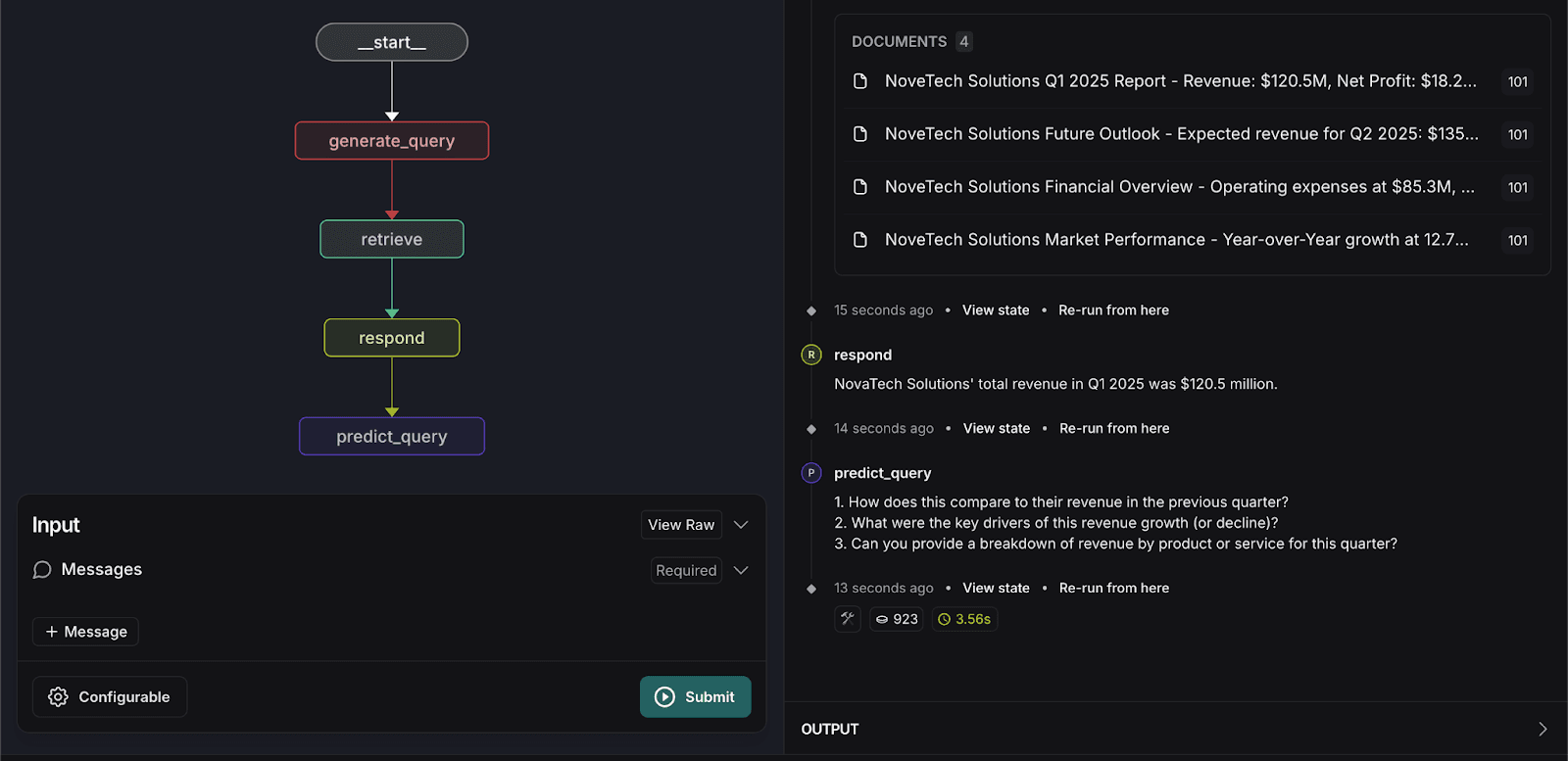
- Digite a seguinte consulta de pesquisa novamente:
O sistema processará a entrada e preverá três perguntas relacionadas que os usuários podem fazer, conforme mostrado abaixo.
Conclusão
A integração do modelo do Retrieval Agent no LangGraph Studio e na CLI oferece vários benefícios importantes:
- Desenvolvimento acelerado: o modelo e as ferramentas de visualização simplificam a criação e a depuração de fluxos de trabalho de recuperação, reduzindo o tempo de desenvolvimento.
- Implantação perfeita: o suporte integrado para APIs e o dimensionamento automático garantem uma implantação tranquila em todos os ambientes.
- Atualizações fáceis: modificar fluxos de trabalho, adicionar novas funcionalidades e integrar nós adicionais é simples, facilitando o dimensionamento e o aprimoramento do processo de recuperação.
- Memória persistente: o sistema retém os estados e o conhecimento dos agentes, melhorando a consistência e a confiabilidade.
- Modelagem de fluxo de trabalho flexível: os desenvolvedores podem personalizar a lógica de recuperação e as regras de comunicação para casos de uso específicos.
- Interação e depuração em tempo real: a capacidade de interagir com agentes em execução permite testes eficientes e resolução de problemas.
Ao aproveitar esses recursos, as organizações podem criar sistemas de recuperação poderosos, eficientes e escaláveis que melhoram a acessibilidade dos dados e a experiência do usuário.
O código-fonte completo deste projeto está disponível no GitHub.
Perguntas frequentes
O que é um fluxo de trabalho RAG?
Um fluxo de trabalho RAG (Retrieval-Augmented Generation) é uma maneira de dar a um modelo de IA acesso aos seus dados privados para que ele possa fornecer respostas precisas e baseadas em fatos, em vez de "alucinar".
Por que usar o Elasticsearch como banco de dados para um agente LangGraph?
O Elasticsearch funciona como a "memória de longo prazo" do agente. Diferentemente de um banco de dados padrão, ele foi desenvolvido para Busca Híbrida — combinando busca vetorial (compreensão do significado) com busca por palavras-chave (encontrar termos exatos). Isso garante que, independentemente de você solicitar "receita do primeiro trimestre" ou "crescimento financeiro", o Elasticsearch forneça os documentos mais relevantes para o LangGraph processar.
Posso criar um sistema multiusuário com o modelo de agente de recuperação LangGraph?
Sim. O artigo demonstra isso através da configuração do gráfico do indexador usando um user_id (como "101"). Isso permite que você marque documentos com proprietários específicos, possibilitando que o agente de recuperação encontre apenas as informações que um usuário específico está autorizado a visualizar.
Conteúdo relacionado

Descreva, não desenhe: dashboards nativos de IA do Kibana via MCP e ES|QL
Do prompt ao dashboard. Aprenda a construir dashboards do Kibana com linguagem natural, usando example-mcp-dashbuilder: uma aplicação MCP open source que escreve consultas ES|QL, cria gráficos interativos e exporta dashboards totalmente funcionais diretamente para Kibana.

13 de março de 2026
Resolução de entidades com Elasticsearch, parte 4: O desafio definitivo
Resolvendo e avaliando desafios de resolução de entidades em um conjunto de dados de desafio definitivo altamente diversificado, projetado para evitar atalhos.

26 de fevereiro de 2026
Resolução de entidades com Elasticsearch & LLMs, Parte 2: Correspondência de entidades com julgamento LLM e busca semântica
Uso de busca semântica e julgamento transparente de LLM para a resolução de entidades no Elasticsearch.

5 de janeiro de 2026
Criação de agentes humanos com o LangGraph e o Elasticsearch
Saiba como criar agentes humanos com LangGraph e Elasticsearch que envolvem pessoas no processo de tomada de decisão para preencher lacunas contextuais e revisar chamadas de ferramentas antes da execução.

2 de janeiro de 2026
Automatização da análise de logs no Streams com ML
Descubra como uma abordagem híbrida de ML alcançou 94% de precisão na análise de logs e 91% na partição de logs por meio de experimentos de automação com impressão digital de formato de log no Streams.