De busca vetorial a poderosas APIs REST, o Elasticsearch oferece aos desenvolvedores o kit de ferramentas de busca mais completo. Confira nossos notebooks de amostra no repositório Elasticsearch Labs para experimentar algo novo. Você também pode começar uma avaliação gratuita ou executar o Elasticsearch localmente hoje mesmo.
Todo o código pode ser encontrado no repositório Searchlabs, na branch advanced-rag-techniques.
Bem-vindo(a) à Parte 2 do nosso artigo sobre Técnicas Avançadas de RAG! Na parte 1 desta série, configuramos, discutimos e implementamos os componentes de processamento de dados do pipeline RAG avançado:
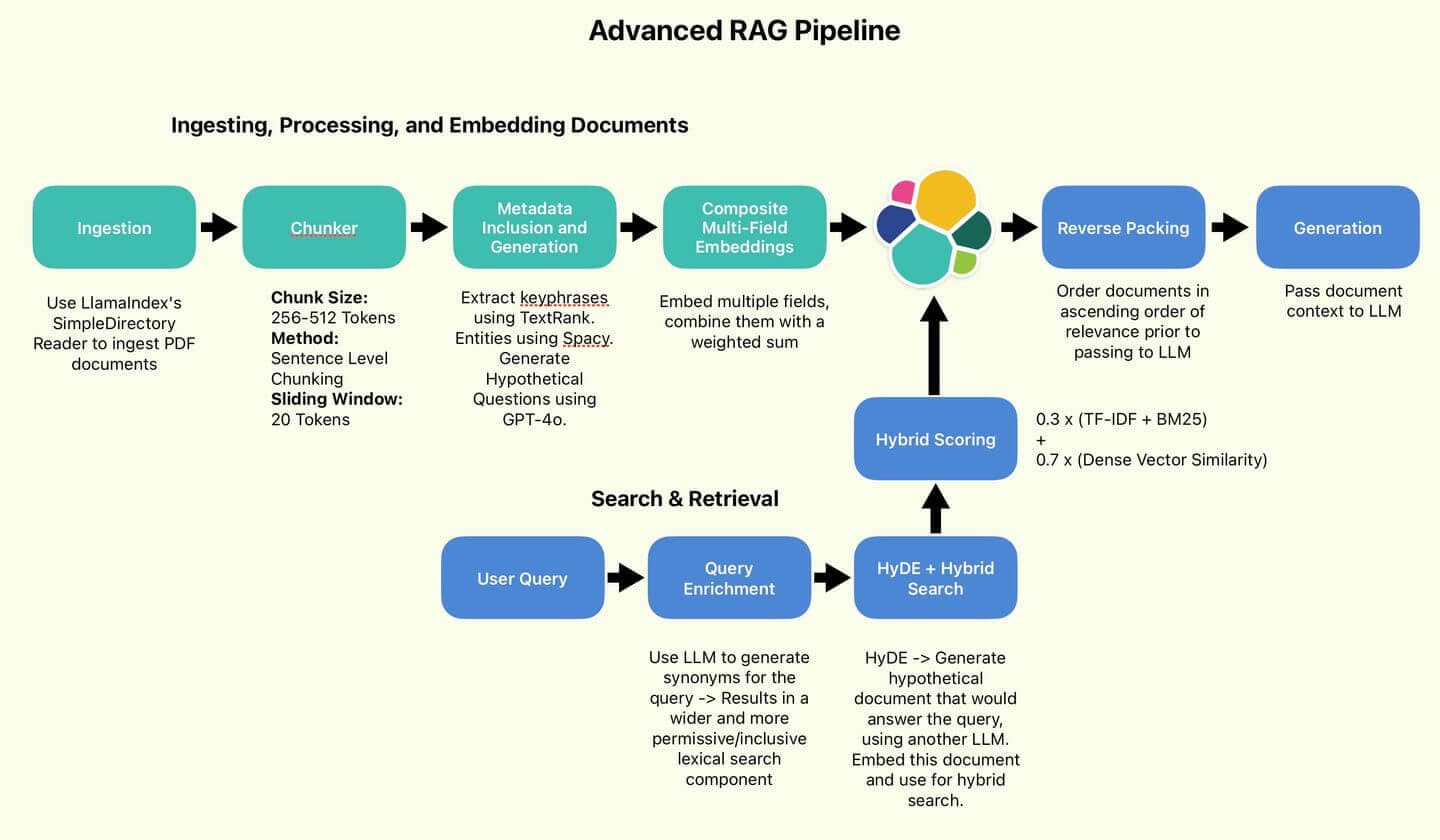
O pipeline RAG utilizado pelo autor.
Nesta parte, vamos prosseguir com a consulta e o teste da nossa implementação. Vamos direto ao assunto!
Índice
- Pesquisar e recuperar, gerar respostas
- Experimentos
- Conclusão
- Apêndice
Pesquisar e recuperar, gerar respostas
Vamos fazer nossa primeira pergunta, idealmente alguma informação encontrada principalmente no relatório anual. Que tal:
Agora, vamos aplicar algumas de nossas técnicas para aprimorar a consulta.
Enriquecendo as consultas com sinônimos
Em primeiro lugar, vamos aumentar a diversidade na formulação da consulta e transformá-la em um formato que possa ser facilmente processado em uma consulta do Elasticsearch. Vamos utilizar o GPT-4o para converter a consulta em uma lista de cláusulas OR. Vamos escrever esta pergunta:
Quando aplicado à nossa consulta, o GPT-4o gera sinônimos da consulta base e vocabulário relacionado.
Na classe ESQueryMaker , defini uma função para dividir a consulta:
Sua função é pegar essa sequência de cláusulas OR e dividi-las em uma lista de termos, permitindo-nos fazer uma correspondência múltipla em nossos campos-chave do documento:
Finalmente, cheguei a esta pergunta:
Isso abrange muito mais aspectos do que a consulta original, reduzindo, esperamos, o risco de perder um resultado de pesquisa por termos esquecido um sinônimo. Mas podemos fazer mais.
HyDE (Incorporação Hipotética de Documentos)
Vamos recorrer ao GPT-4o novamente, desta vez para implementar o HyDE.
A premissa básica do HyDE é gerar um documento hipotético – o tipo de documento que provavelmente conteria a resposta à consulta original. A veracidade ou exatidão do documento não é uma preocupação. Com isso em mente, vamos escrever a seguinte pergunta:
Como a busca vetorial normalmente opera com base na similaridade de vetores de cosseno, a premissa do HyDE é que podemos obter melhores resultados combinando documentos com documentos em vez de consultas com documentos.
O que nos interessa é a estrutura, a fluidez e a terminologia. Não se trata tanto de factualidade. O GPT-4o gera um documento HyDE como este:
Parece bastante convincente, como o candidato ideal para os tipos de documentos que gostaríamos de indexar. Vamos incorporar isso e usar para busca híbrida.
Busca híbrida
Este é o núcleo da nossa lógica de busca. Nosso componente de busca lexical serão as strings da cláusula OR geradas. Nosso componente vetorial denso será um documento HyDE incorporado (também conhecido como vetor de busca). Utilizamos o KNN para identificar de forma eficiente vários documentos candidatos mais próximos do nosso vetor de busca. Por padrão, denominamos nosso componente de busca lexical como "Pontuação com TF-IDF e BM25" . Finalmente, as pontuações lexicais e de vetor denso serão combinadas usando a proporção 30/70 recomendada por Wang et al.
Finalmente, podemos montar uma função RAG. Nosso processo RAG, da pergunta à resposta, seguirá este fluxo:
- Converter consulta em cláusulas OR.
- Gere o documento HyDE e incorpore-o.
- Passe ambos como entradas para a Busca Híbrida.
- Recuperar os n melhores resultados, inverter a ordem para que a pontuação mais relevante seja a "mais recente" na memória contextual do LLM (Empacotamento Inverso). Exemplo de Empacotamento Inverso: Consulta: "Técnicas de otimização de consultas do Elasticsearch". Documentos recuperados (ordenados por relevância): Ordem invertida para o contexto do LLM: Ao inverter a ordem, a informação mais relevante (1) aparece por último no contexto, potencialmente recebendo mais atenção do LLM durante a geração de respostas.
- "Use consultas booleanas para combinar vários critérios de pesquisa de forma eficiente."
- "Implementar estratégias de cache para melhorar os tempos de resposta das consultas."
- "Otimize os mapeamentos de índice para um desempenho de pesquisa mais rápido."
- "Otimize os mapeamentos de índice para um desempenho de pesquisa mais rápido."
- "Implementar estratégias de cache para melhorar os tempos de resposta das consultas."
- "Use consultas booleanas para combinar vários critérios de pesquisa de forma eficiente."
- Passe o contexto para o LLM para geração.
Vamos executar nossa consulta e obter a resposta:
Legal. Isso mesmo.
Experimentos
Há uma pergunta importante a ser respondida agora. O que ganhamos investindo tanto esforço e complexidade adicional nessas implementações?
Vamos fazer uma pequena comparação. O pipeline RAG que implementamos em comparação com a busca híbrida básica, sem nenhuma das melhorias que fizemos. Realizaremos uma pequena série de testes para verificar se notamos alguma diferença significativa. Vamos nos referir ao RAG que acabamos de implementar como AdvancedRAG e ao pipeline básico como SimpleRAG.

Pipeline RAG simples, sem firulas.
Resumo dos resultados
Esta tabela resume os resultados de cinco testes de ambos os pipelines RAG. Avaliei a superioridade relativa de cada método com base no detalhamento e na qualidade das respostas, mas essa é uma avaliação totalmente subjetiva. As respostas corretas estão reproduzidas abaixo desta tabela para sua análise. Dito isso, vamos dar uma olhada em como eles se saíram!
O SimpleRAG não conseguiu responder às perguntas 1 e 5. O AdvancedRAG, por sua vez, apresentou respostas muito mais detalhadas nas perguntas 2, 3 e 4. Com base nesse maior nível de detalhamento, considerei as respostas do AdvancedRAG de melhor qualidade.
| Teste | Pergunta | Desempenho AdvancedRAG | Desempenho SimpleRAG | Latência RAG Avançada | Latência SimpleRAG | Ganhador |
|---|---|---|---|---|---|---|
| 1 | Quem audita a Elastic? | Identificou corretamente a PwC como auditora. | Não foi possível identificar o auditor. | 11,6s | 4,4s | RAG Avançado |
| 2 | Qual foi a receita total em 2023? | Forneceu o valor correto da receita. Incluímos contexto adicional com a receita de anos anteriores. | Forneceu o valor correto da receita. | 13,3s | 2,8s | RAG Avançado |
| 3 | De qual produto depende principalmente o crescimento? Quanto? | Identificamos corretamente o Elastic Cloud como o principal fator impulsionador. Inclui contexto geral de receita e detalhes adicionais. | Identificamos corretamente o Elastic Cloud como o principal fator impulsionador. | 14,1s | 12,8s | RAG Avançado |
| 4 | Descreva o plano de benefícios para funcionários. | Apresentou uma descrição completa dos planos de aposentadoria, programas de saúde e outros benefícios. Inclui valores de contribuição específicos para diferentes anos. | Apresentou uma boa visão geral dos benefícios, incluindo remuneração, planos de aposentadoria, ambiente de trabalho e o programa Elastic Cares. | 26,6s | 11,6s | RAG Avançado |
| 5 | Quais empresas a Elastic adquiriu? | As aquisições recentes mencionadas no relatório foram listadas corretamente (CmdWatch, Build Security, Optimyze). Foram fornecidas algumas datas de aquisição e preços de compra. | Não foi possível recuperar informações relevantes do contexto fornecido. | 11,9s | 2,7s | RAG Avançado |
Teste 1: Quem audita a Elastic?
RAG Avançado
SimpleRAG
Resumo: A SimpleRAG não identificou a PwC como auditora.
Bem, isso é realmente surpreendente. Parece ser uma falha de busca por parte do SimpleRAG. Não foram recuperados documentos relacionados à auditoria. Vamos diminuir um pouco a dificuldade no próximo teste.
Teste 2: receita total em 2023
RAG Avançado
SimpleRAG
Resumo: Ambas as equipes RAG acertaram a resposta: receita total de US$ 1.068.989.000 em 2023.
Ambos estavam bem aqui. Parece que a AdvancedRAG pode ter adquirido uma gama mais ampla de documentos? Certamente a resposta é mais detalhada e incorpora informações de anos anteriores. Isso era de se esperar, considerando as melhorias que fizemos, mas ainda é muito cedo para afirmar algo com certeza.
Vamos aumentar a dificuldade.
Teste 3: De qual produto depende principalmente o crescimento? Quanto?
RAG Avançado
SimpleRAG
Resumo: Ambos os RAGs identificaram corretamente o Elastic Cloud como o principal motor de crescimento. No entanto, o AdvancedRAG inclui mais detalhes, levando em consideração as receitas de assinaturas e o crescimento da base de clientes, e menciona explicitamente outras ofertas da Elastic.
Teste 4: Descreva o plano de benefícios para funcionários
RAG Avançado
SimpleRAG
Resumo: A AdvancedRAG aborda o assunto com muito mais profundidade e detalhes, mencionando o plano 401K para funcionários baseados nos EUA, além de definir planos de contribuição fora dos EUA. O texto também menciona planos de saúde e bem-estar, mas omite o programa Elastic Cares, que é citado pela SimpleRAG.
Teste 5: Quais empresas a Elastic adquiriu?
RAG Avançado
SimpleRAG
Resumo: O SimpleRAG não recupera nenhuma informação relevante sobre aquisições, resultando em uma resposta incorreta. A AdvancedRAG lista corretamente a CmdWatch, a Build Security e a Optimyze, que foram as principais aquisições mencionadas no relatório.
Conclusão
Com base em nossos testes, nossas técnicas avançadas parecem aumentar o alcance e a profundidade das informações apresentadas, potencialmente melhorando a qualidade das respostas RAG.
Além disso, pode haver melhorias na confiabilidade, já que perguntas formuladas de maneira ambígua, como Which companies did Elastic acquire? e Who audits Elastic foram respondidas corretamente pelo AdvancedRAG, mas não pelo SimpleRAG.
No entanto, vale a pena ter em mente que, em 3 de 5 casos, o pipeline RAG básico, incorporando a Busca Híbrida, mas nenhuma outra técnica, conseguiu produzir respostas que capturaram a maior parte das informações essenciais.
Devemos observar que, devido à incorporação de LLMs nas fases de preparação e consulta de dados, a latência do AdvancedRAG é geralmente de 2 a 5 vezes maior que a do SimpleRAG. Este é um custo significativo que pode tornar o AdvancedRAG adequado apenas para situações em que a qualidade da resposta é priorizada em detrimento da latência.
Os custos significativos de latência podem ser atenuados usando um modelo de linguagem latente (LLM) menor e mais barato, como o Claude Haiku ou o GPT-4o-mini, na fase de preparação dos dados. Salve os modelos avançados para geração de respostas.
Isso está de acordo com as conclusões de Wang et al. Conforme demonstram os resultados, quaisquer melhorias realizadas são relativamente incrementais. Resumindo, o método RAG básico e simples permite chegar a um produto final bastante satisfatório, sendo ainda mais barato e rápido. Para mim, é uma conclusão interessante. Para casos de uso em que velocidade e eficiência são essenciais, o SimpleRAG é a escolha sensata. Para casos de uso em que é necessário extrair o máximo desempenho possível, as técnicas incorporadas no AdvancedRAG podem oferecer uma solução.

Os resultados do estudo de Wang et al. revelam que o uso de técnicas avançadas gera melhorias consistentes, porém incrementais.
Apêndice
Prompts
Pergunta RAG para responder:
Solicitação para que o LLM gere respostas com base na consulta e no contexto.
prompt do gerador de consultas elásticas
Solicitação para enriquecer as consultas com sinônimos e convertê-las para o formato OU.
Possíveis perguntas para o gerador
Solicitação para gerar possíveis perguntas e enriquecer os metadados do documento.
prompt do gerador HyDE
Solicitação para gerar documentos hipotéticos usando o HyDE
Exemplo de consulta de pesquisa híbrida
Conteúdo relacionado

Descreva, não desenhe: dashboards nativos de IA do Kibana via MCP e ES|QL
Do prompt ao dashboard. Aprenda a construir dashboards do Kibana com linguagem natural, usando example-mcp-dashbuilder: uma aplicação MCP open source que escreve consultas ES|QL, cria gráficos interativos e exporta dashboards totalmente funcionais diretamente para Kibana.

23 de abril de 2026
Como criamos o Elasticsearch simdvec para que a busca vetorial seja uma das mais rápidas do mundo
Como criamos o Elasticsearch simdvec, a biblioteca do kernel SIMD ajustada manualmente por trás de cada consulta de busca vetorial no Elasticsearch.

4 de maio de 2026
Como medir e melhorar o recall das buscas no Elasticsearch: de 0,43 a 0,75 com a busca híbrida
Aprenda a medir e melhorar o recall das buscas no Elasticsearch combinando a busca léxica BM25 com embeddings vetoriais do Jina AI, usando a API rank_eval para validar a melhoria com números reais.

10 de abril de 2026
Clustering não supervisionado de documentos com Elasticsearch + embeddings Jina
Uma abordagem prática e reproduzível para clustering não supervisionado de documentos com Elasticsearch e embeddings Jina.

2 de abril de 2026
Quando o TSDS encontra o ILM: projetando fluxos de dados de séries temporais que aceitam dados tardios
Como os limites de tempo do TSDS interagem com as fases do ILM e como projetar políticas que tolerem métricas atrasadas.