ベクトル検索からパワフルなREST APIまで、Elasticsearchは最も広範な検索ツールキットを開発者に提供します。Elasticsearch Labsリポジトリのサンプルノートで新しいことに挑戦してみましょう。また、無料トライアルを始めるか、ローカルでElasticsearchを実行することもできます。
Go を含むあらゆるプログラミング言語でソフトウェアを構築することは、生涯にわたる学習に取り組むことです。Carly は大学時代や仕事を通じて、ベクトル検索の最新かつ最高の実装を含む、数多くのプログラミング言語やテクノロジーに携わってきました。しかし、それだけでは十分ではありませんでした!それで最近カーリーも囲碁を始めました。
動物、プログラミング言語、そして親しみやすい著者と同じように、検索もさまざまな方法の進化を遂げており、独自の検索ユースケースに応じてどれを選択するかを決めるのは難しい場合があります。このブログでは、ベクトル検索の概要と、 Elasticsearch および Elasticsearch Go クライアント を使用した各アプローチの 例を 紹介します。これらの例では、Elasticsearch と Go のベクトル検索を使用して、ホリネズミを見つけて、その食べ物を特定する方法を説明します。
要件
この例を実行するには、次の前提条件が満たされていることを確認してください。
- Goバージョン1.21以降のインストール
- 独自のGoリポジトリを作成する
- 独自の Elasticsearch クラスターを作成し、Wikipedia のフレンドリーなGopherを含む一連のげっ歯類ベースのページを設定します。
Elasticsearchへの接続
この例では、Go クライアントが提供するTyped APIを利用します。クエリに対して安全な接続を確立するには、次のいずれかを使用してクライアントを構成する必要があります。
- Elastic Cloud を利用する場合のクラウド ID と API キー。
- クラスター URL、ユーザー名、パスワード、証明書。
Elastic Cloud にあるクラスターに接続すると、次のようになります。
後続のセクションに示すように、 client接続はベクトル検索に使用できます。
ベクトル検索
ベクトル検索は、検索問題をベクトルを使用した数学的な比較に変換することでこの問題を解決しようとします。ドキュメント埋め込みプロセスには、モデルを使用してドキュメントを高密度ベクトル表現、つまり単純な数値のストリームに変換する追加の段階があります。このアプローチの利点は、画像や音声などのテキスト以外のドキュメントをクエリと一緒にベクトルに変換して検索できることです。
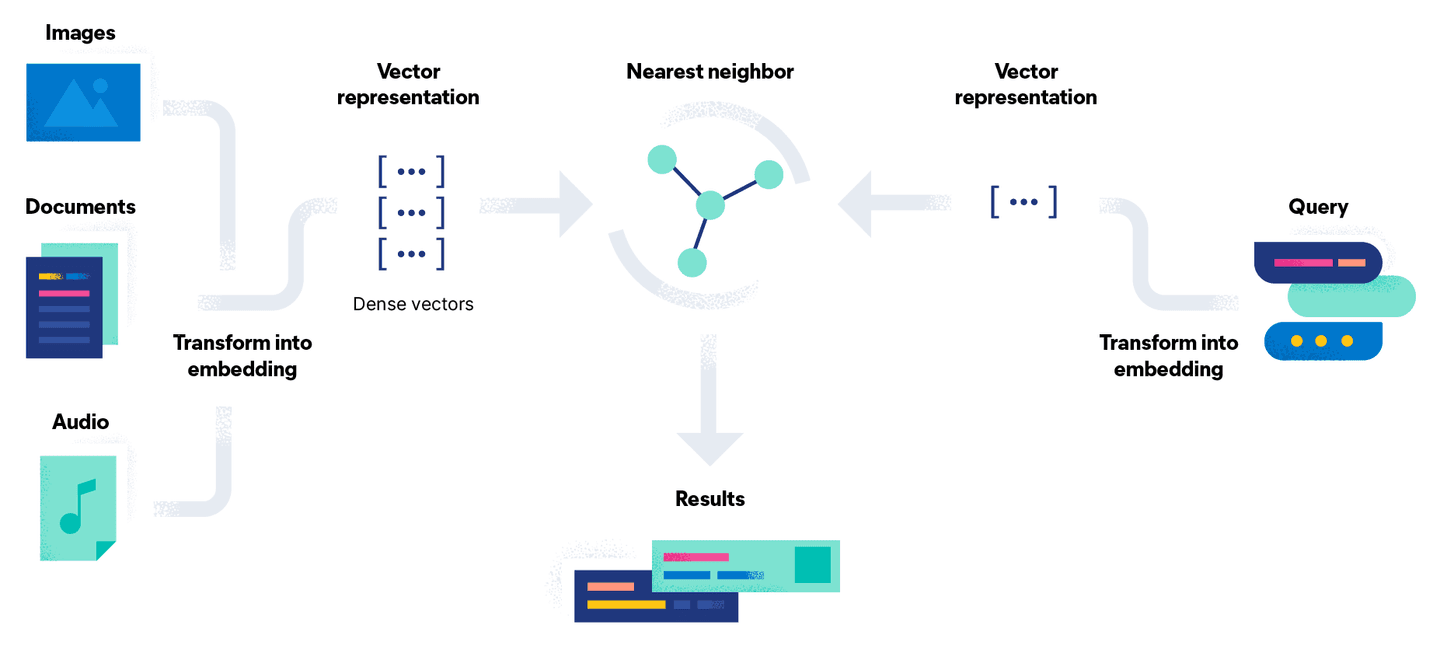
簡単に言えば、ベクトル検索はベクトル距離の計算のセットです。下の図では、クエリGo Gopherのベクトル表現がベクトル空間内のドキュメントと比較され、最も近い結果 (定数kで示される) が返されます。

ドキュメントの埋め込みを生成するために使用するアプローチに応じて、ホリネズミが何を食べるかを調べる方法が 2 つあります。
アプローチ1: 独自のモデルを持ち込む
Platinum ライセンスでは、モデルをアップロードし、推論 API を使用して Elasticsearch 内で埋め込みを生成できます。モデルの設定には 6 つのステップがあります。
- モデル リポジトリからアップロードする PyTorch モデルを選択します。この例では、Hugging Face のsentence-transformers/msmarco-MiniLM-L-12-v3を使用して埋め込みを生成します。
- Elasticsearch クラスターとタスク タイプ
text_embeddingsの資格情報を使用して、Python 用の Eland Machine Learning クライアントでモデルを Elastic にロードします。Eland がインストールされていない場合は、以下に示すようにDocker を使用してインポート手順を実行できます。
- アップロードしたら、サンプル ドキュメントを使用してモデル
sentence-transformers__msmarco-minilm-l-12-v3をすぐにテストし、埋め込みが期待どおりに生成されることを確認します。

- 推論プロセッサを含む取り込みパイプラインを作成します。これにより、アップロードされたモデルを使用してベクター表現を生成できるようになります。
- 各ドキュメントに対して生成されたベクトル埋め込みを格納するための、タイプ
dense_vectorのフィールドtext_embedding.predicted_valueを含む新しいインデックスを作成します。
- 新しく作成された取り込みパイプラインを使用してドキュメントのインデックスを再作成し、各ドキュメントの追加フィールド
text_embedding.predicted_valueとしてテキスト埋め込みを生成します。
次の例に示すように、新しいインデックスvector-search-rodentsを使用して、同じ検索 API でKnnオプションを使用できるようになりました。
アンマーシャリングによる JSON 結果オブジェクトの変換は、キーワード検索の例とまったく同じ方法で実行されます。定数KとNumCandidates使用すると、返される隣接ドキュメントの数と、シャードごとに考慮する候補の数を設定できます。候補の数を増やすと結果の精度は上がりますが、比較が多く実行されるためクエリの実行時間が長くなることに注意してください。
クエリWhat do Gophers eat?を使用してコードを実行すると、返される結果は以下と同様になり、以前のキーワード検索とは異なり、Gopher の記事に要求された情報が含まれていることが強調表示されます。
アプローチ2:ハグフェイス推論API
もう 1 つのオプションは、Elasticsearch の外部で同じ埋め込みを生成し、ドキュメントの一部として取り込むことです。このオプションは Elasticsearch 機械学習ノードを使用しないため、無料利用枠で実行できます。
Hugging Face は、無料で使用できるレート制限付きの推論 API を公開しています。アカウントと API トークンを使用すると、実験やプロトタイピングを開始するために同じ埋め込みを手動で生成できます。実稼働環境での使用は推奨されません。同様のアプローチを使用して、ローカルで独自のモデルを呼び出して埋め込みを生成したり、有料の API を使用したりすることもできます。
以下の関数GetTextEmbeddingForQueryでは、クエリ文字列に対して推論 API を使用して、エンドポイントへのPOSTリクエストから返されるベクトルを生成します。
結果の[]float32型のベクトルは、 QueryVectorBuilderオプションを使用する代わりにQueryVectorとして渡され、以前に Elastic にアップロードされたモデルが活用されます。
KとNumCandidatesオプションは2つのオプションに関係なく同じままであり、埋め込みを生成するために同じモデルを使用しているため、同じ結果が生成されることに注意してください。
まとめ
ここでは、 Elasticsearch Go クライアントを使用して Elasticsearch でベクトル検索を実行する方法について説明しました。このシリーズのすべてのコードについては、 GitHub リポジトリをご覧ください。パート 3に進み、パート 1で説明した Go のキーワード検索機能とベクトル検索を組み合わせる方法の概要を確認します。
それまでは、楽しいホリネズミ狩りを!
各種資料
関連記事

2026年4月23日
ベクトル検索を世界最速のものにするためにElasticsearch simdvecを構築した方法
Elasticsearchのすべてのベクトル検索クエリの基盤となる、手作業で調整されたSIMDカーネルライブラリElasticsearch simdvecの構築方法。

2026年5月4日
Elasticsearchの検索再現率を測定・改善する方法:ハイブリッド検索で0.43から0.75へ
Elasticsearchにおける検索再現率を測定および改善する方法を学びましょう。BM25の語彙検索とJina AIのベクトル埋め込みを組み合わせ、rank_eval APIを使用して実際の数値で改善効果を検証します。

2026年4月10日
Elasticsearch + Jina埋め込みによる教師なし文書クラスタリング
ElasticsearchとJina埋め込みを使用した教師なし文書クラスタリングへの実用的で再現可能なアプローチ。

2026年4月2日
TSDSとILMが出会うとき:遅延データを拒否しない時系列データストリームの設計
TSDSの時間制限はILMフェーズとどのように相互作用するのか、そして遅れて到着するメトリクスを許容するポリシーを設計する方法。

2026年4月1日
LINQ to Elasticsearch ES|QL:C#を記述してElasticsearchをクエリ
Elasticsearch .NETクライアントに新しく追加されたLINQ to Elasticsearch ES|QLプロバイダをご紹介します。C#コードを自動的にES|QLクエリに変換できます。