Ollama を推論 API と共に使用する
Inference API を使用して Ollama を Elasticsearch と統合する方法を学びます。
この記事では、Ollama を使用してローカル モデルを Elasticsearch 推論モデルに接続し、Playground を使用してドキュメントに質問する方法を学習します。
Elasticsearch を使用すると、ユーザーは Open Inference APIを使用して LLM に接続でき、Amazon Bedrock、Cohere、Google AI、Azure AI Studio、HuggingFace などのプロバイダーをサービスとしてサポートします。
Ollama は、独自のインフラストラクチャ (ローカル マシン/サーバー) を使用して LLM モデルをダウンロードおよび実行できるツールです。ここでは、Ollama と互換性のある利用可能なモデルのリストを見つけることができます。
Ollama は、各モデルをセットアップする方法の違いや、モデル関数にアクセスするための API の作成方法について心配することなく、さまざまなオープンソース モデルをホストしてテストしたい場合に最適なオプションです。Ollama がすべてを処理します。
Ollama API は OpenAI API と互換性があるため、推論モデルを簡単に統合し、Playground を使用して RAG アプリケーションを作成できます。
要件
エラスティックサーチ 8.17
キバナ 8.17
Python
ステップ
Ollama LLMサーバーのセットアップ
Ollama を使用して、LLM サーバーを設定し、Playground インスタンスに接続します。以下のことが必要です:
Ollamaをダウンロードして実行します。
ngrokを使用して、インターネット経由でOllamaをホストするローカルWebサーバーにアクセスします。
Ollamaをダウンロードして実行する
Ollama を使用するには、まずダウンロードする必要があります。Ollama は Linux、Windows、macOS をサポートしているので、ここからお使いの OS と互換性のある Ollama バージョンをダウンロードしてください。Ollama がインストールされると、サポートされている LLM のリストからモデルを選択できます。この例では、汎用多言語モデルであるllama3.2モデルを使用します。セットアップ プロセスでは、Ollama のコマンド ライン ツールを有効にします。ダウンロードが完了したら、次の行を実行できます。
ollama pull llama3.2出力は次のようになります:
pulling manifest
pulling dde5aa3fc5ff... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████▏ 2.0 GB
pulling 966de95ca8a6... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████▏ 1.4 KB
pulling fcc5a6bec9da... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████▏ 7.7 KB
pulling a70ff7e570d9... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████▏ 6.0 KB
pulling 56bb8bd477a5... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████▏ 96 B
pulling 34bb5ab01051... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████▏ 561 B
verifying sha256 digest
writing manifest
successインストールしたら、次のコマンドでテストできます。
ollama run llama3.2質問してみましょう:
モデルを実行すると、Ollama はポート「11434」でデフォルトで実行される API を有効にします。公式ドキュメントに従って、その API にリクエストを送信してみましょう。
curl http://localhost:11434/api/generate -d '{
"model": "llama3.2",
"prompt": "What is the capital of France?"
}'私たちが受け取った回答は次のとおりです。
{"model":"llama3.2","created_at":"2024-11-28T21:48:42.152817532Z","response":"The","done":false}
{"model":"llama3.2","created_at":"2024-11-28T21:48:42.251884485Z","response":" capital","done":false}
{"model":"llama3.2","created_at":"2024-11-28T21:48:42.347365913Z","response":" of","done":false}
{"model":"llama3.2","created_at":"2024-11-28T21:48:42.446837322Z","response":" France","done":false}
{"model":"llama3.2","created_at":"2024-11-28T21:48:42.542367394Z","response":" is","done":false}
{"model":"llama3.2","created_at":"2024-11-28T21:48:42.644580384Z","response":" Paris","done":false}
{"model":"llama3.2","created_at":"2024-11-28T21:48:42.739865362Z","response":".","done":false}
{"model":"llama3.2","created_at":"2024-11-28T21:48:42.834347518Z","response":"","done":true,"done_reason":"stop","context":[128006,9125,128007,271,38766,1303,33025,2696,25,6790,220,2366,18,271,128009,128006,882,128007,271,3923,374,279,6864,315,9822,30,128009,128006,78191,128007,271,791,6864,315,9822,374,12366,13],"total_duration":6948567145,"load_duration":4386106503,"prompt_eval_count":32,"prompt_eval_duration":1872000000,"eval_count":8,"eval_duration":684000000}このエンドポイントの特定の応答はストリーミングであることに注意してください。
ngrokを使用してエンドポイントをインターネットに公開する
エンドポイントはローカル環境で動作するため、Elastic Cloud インスタンスなどの別のポイントからインターネット経由でアクセスすることはできません。ngrok を使用すると、パブリック IP を提供するポートを公開できます。ngrok でアカウントを作成し、公式のセットアップ ガイドに従ってください。
ngrok エージェントをインストールして構成したら、Ollama が使用しているポートを公開できます。
ngrok http 11434 --host-header="localhost:11434"注: ヘッダー--host-header="localhost:11434"は、リクエスト内の「Host」ヘッダーが「localhost:11434」と一致することを保証します。
このコマンドを実行すると、ngrok と Ollama サーバーがローカルで実行されている限り機能するパブリック リンクが返されます。
Session Status online
Account xxxx@yourEmailProvider.com (Plan: Free)
Version 3.18.4
Region United States (us)
Latency 561ms
Web Interface http://127.0.0.1:4040
Forwarding https://your-ngrok-url.ngrok-free.app -> http://localhost:11434
Connections ttl opn rt1 rt5 p50 p90
0 0 0.00 0.00 0.00 0.00 ```「転送」では、ngrok が URL を生成したことがわかります。後で使用するために保存します。
ngrok によって生成された URL を使用して、エンドポイントへの HTTP リクエストを再度実行してみましょう。
curl https://your-ngrok-endpoint.ngrok-free.app/api/generate -d '{
"model": "llama3.2",
"prompt": "What is the capital of France?"
}'応答は前のものと同様になるはずです。
マッピングの作成
ELSERエンドポイント
この例では、 Elasticsearch 推論 API を使用して推論エンドポイントを作成します。さらに、 ELSERを使用して埋め込みを生成します。
PUT _inference/sparse_embedding/medicines-inference
{
"service": "elasticsearch",
"service_settings": {
"num_allocations": 1,
"num_threads": 1,
"model_id": ".elser_model_2_linux-x86_64"
}
}この例では、2 種類の薬を販売する薬局があるとします。
処方箋が必要な医薬品。
処方箋を必要としない医薬品。
この情報は各薬剤の説明欄に含まれます。
LLM はこのフィールドを解釈する必要があるため、次のデータ マッピングを使用します。
PUT medicines
{
"mappings": {
"properties": {
"name": {
"type": "text",
"copy_to": "semantic_field"
},
"semantic_field": {
"type": "semantic_text",
"inference_id": "medicines-inference"
},
"text_description": {
"type": "text",
"copy_to": "semantic_field"
}
}
}
}フィールドtext_descriptionは説明のプレーンテキストが格納され、 semantic_textフィールド タイプであるsemantic_fieldには ELSER によって生成された埋め込みが格納されます。
プロパティcopy_to は、フィールド名とtext_descriptionの内容をセマンティック フィールドにコピーし、それらのフィールドの埋め込みが生成されます。
データのインデックス作成
ここで、 _bulk APIを使用してデータをインデックス化してみましょう。
POST _bulk
{"index":{"_index":"medicines"}}
{"id":1,"name":"Paracetamol","text_description":"An analgesic and antipyretic that does NOT require a prescription."}
{"index":{"_index":"medicines"}}
{"id":2,"name":"Ibuprofen","text_description":"A nonsteroidal anti-inflammatory drug (NSAID) available WITHOUT a prescription."}
{"index":{"_index":"medicines"}}
{"id":3,"name":"Amoxicillin","text_description":"An antibiotic that requires a prescription."}
{"index":{"_index":"medicines"}}
{"id":4,"name":"Lorazepam","text_description":"An anxiolytic medication that strictly requires a prescription."}
{"index":{"_index":"medicines"}}
{"id":5,"name":"Omeprazole","text_description":"A medication for stomach acidity that does NOT require a prescription."}
{"index":{"_index":"medicines"}}
{"id":6,"name":"Insulin","text_description":"A hormone used in diabetes treatment that requires a prescription."}
{"index":{"_index":"medicines"}}
{"id":7,"name":"Cold Medicine","text_description":"A compound formula to relieve flu symptoms available WITHOUT a prescription."}
{"index":{"_index":"medicines"}}
{"id":8,"name":"Clonazepam","text_description":"An antiepileptic medication that requires a prescription."}
{"index":{"_index":"medicines"}}
{"id":9,"name":"Vitamin C","text_description":"A dietary supplement that does NOT require a prescription."}
{"index":{"_index":"medicines"}}
{"id":10,"name":"Metformin","text_description":"A medication used for type 2 diabetes that requires a prescription."}対応:
{
"errors": false,
"took": 34732020848,
"items": [
{
"index": {
"_index": "medicines",
"_id": "mYoeMpQBF7lnCNFTfdn2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "medicines",
"_id": "mooeMpQBF7lnCNFTfdn2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "medicines",
"_id": "m4oeMpQBF7lnCNFTfdn2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "medicines",
"_id": "nIoeMpQBF7lnCNFTfdn2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "medicines",
"_id": "nYoeMpQBF7lnCNFTfdn2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 4,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "medicines",
"_id": "nooeMpQBF7lnCNFTfdn2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 5,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "medicines",
"_id": "n4oeMpQBF7lnCNFTfdn2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 6,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "medicines",
"_id": "oIoeMpQBF7lnCNFTfdn2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 7,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "medicines",
"_id": "oYoeMpQBF7lnCNFTfdn2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 8,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "medicines",
"_id": "oooeMpQBF7lnCNFTfdn2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 9,
"_primary_term": 1,
"status": 201
}
}
]
}Playgroundを使って質問する
Playground は、Elasticsearch インデックスと LLM プロバイダーを使用して RAG システムをすばやく作成できる Kibana ツールです。詳細については、この記事をお読みください。
ローカルLLMをPlaygroundに接続する
まず、作成したパブリック URL を使用するコネクタを作成する必要があります。Kibana で、 「検索」>「プレイグラウンド」に移動し、「LLM に接続」をクリックします。
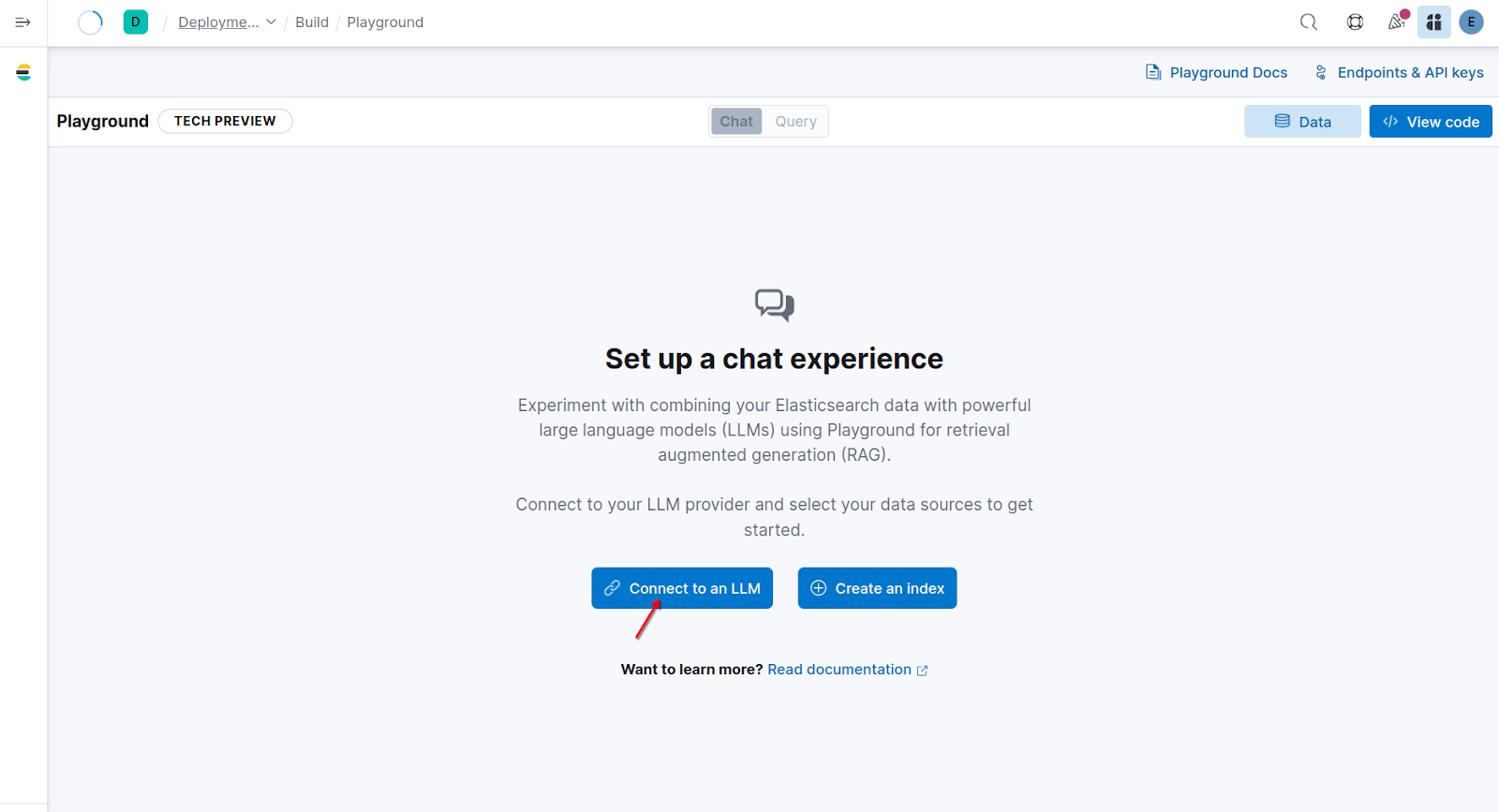
このアクションにより、Kibana インターフェースの左側にメニューが表示されます。そこで、「OpenAI」をクリックします。
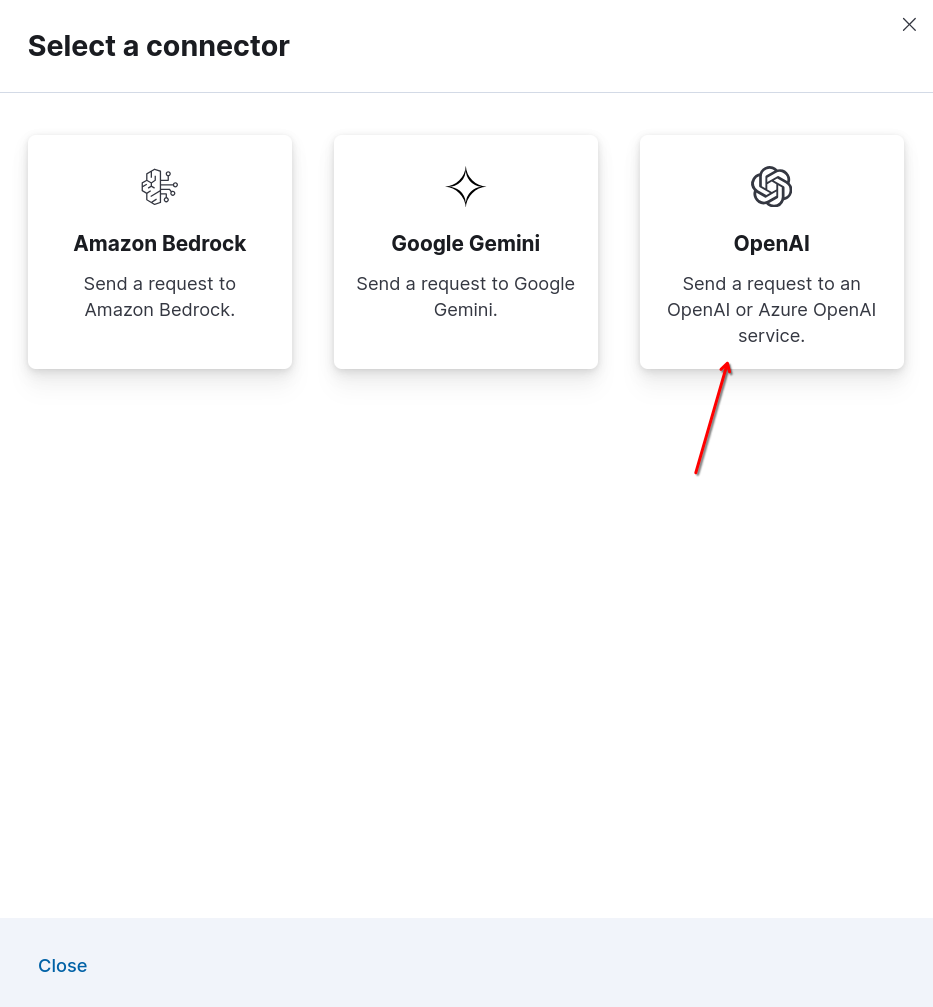
これで、OpenAI コネクタの設定を開始できます。
「コネクタ設定」に移動し、OpenAI プロバイダーの場合は「その他 (OpenAI 互換サービス)」を選択します。
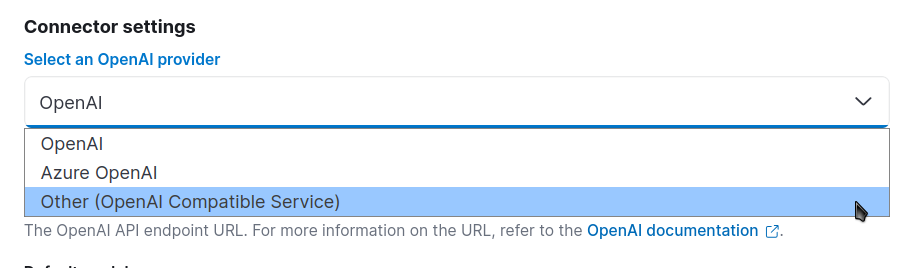
次に、他のフィールドを設定しましょう。この例では、モデル名を「medicines-llm」とします。URLフィールドには、ngrokによって生成されたURL(/v1/chat/completions)を入力します。「デフォルトモデル」フィールドで、「llama3.2」を選択します。API キーは使用しないので、任意のテキストを入力して続行します。
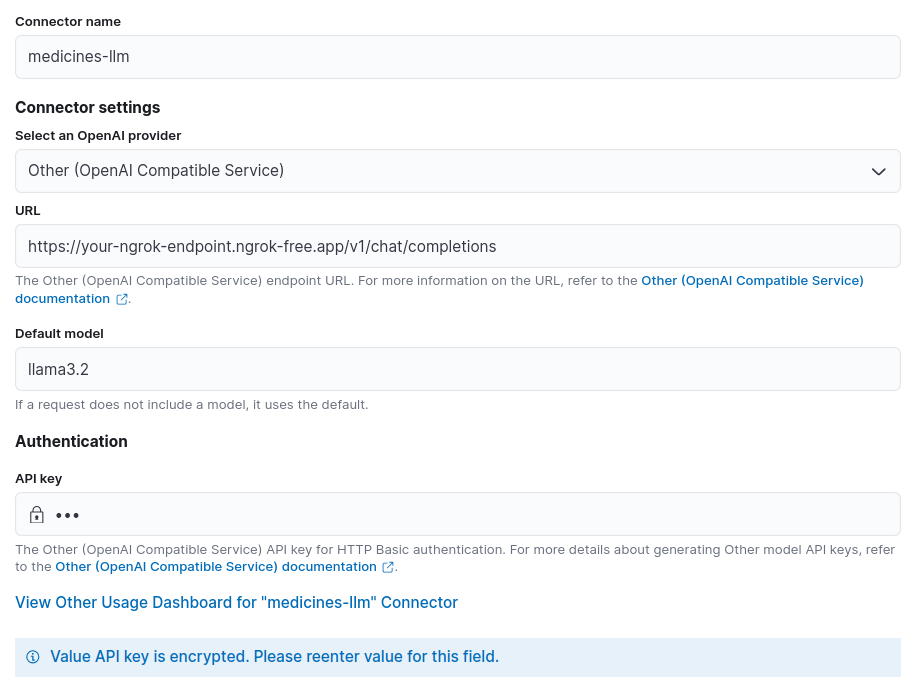
「保存」をクリックし、「データ ソースの追加」をクリックしてインデックス医薬品を追加します。
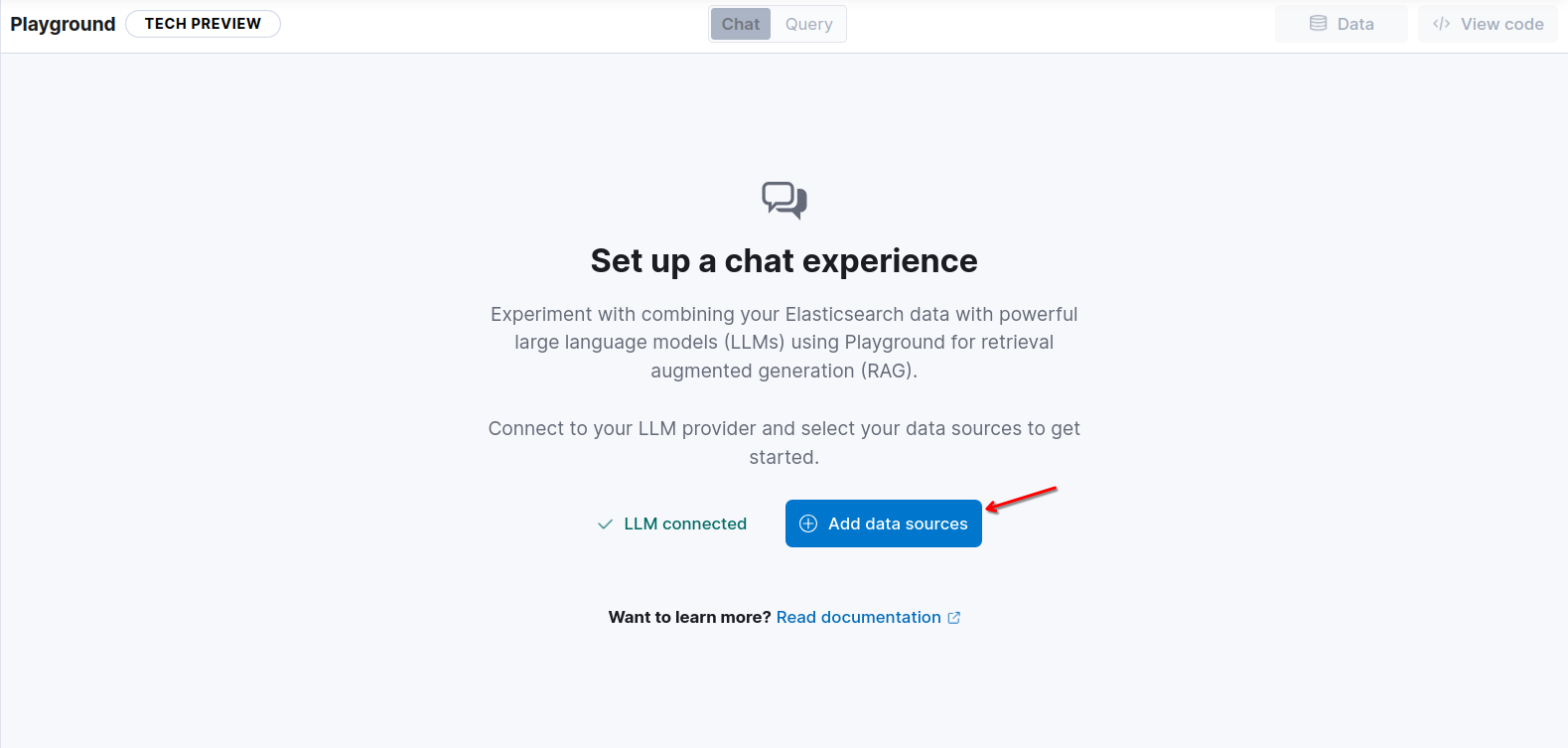
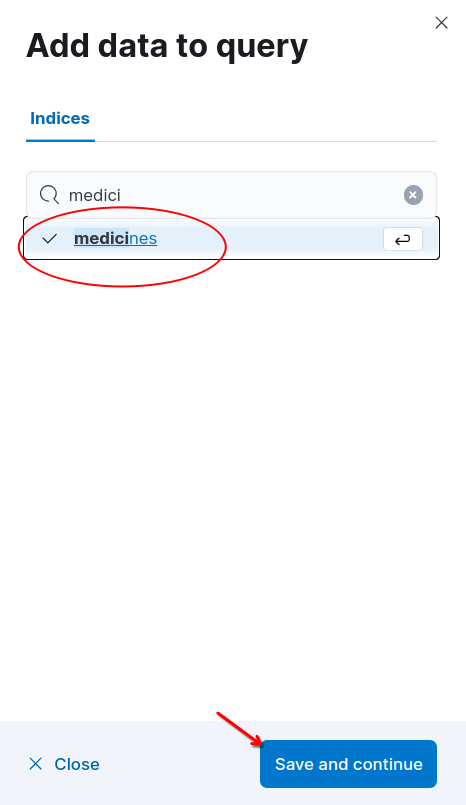
素晴らしい!これで、RAG エンジンとしてローカルで実行している LLM を使用して Playground にアクセスできるようになりました。
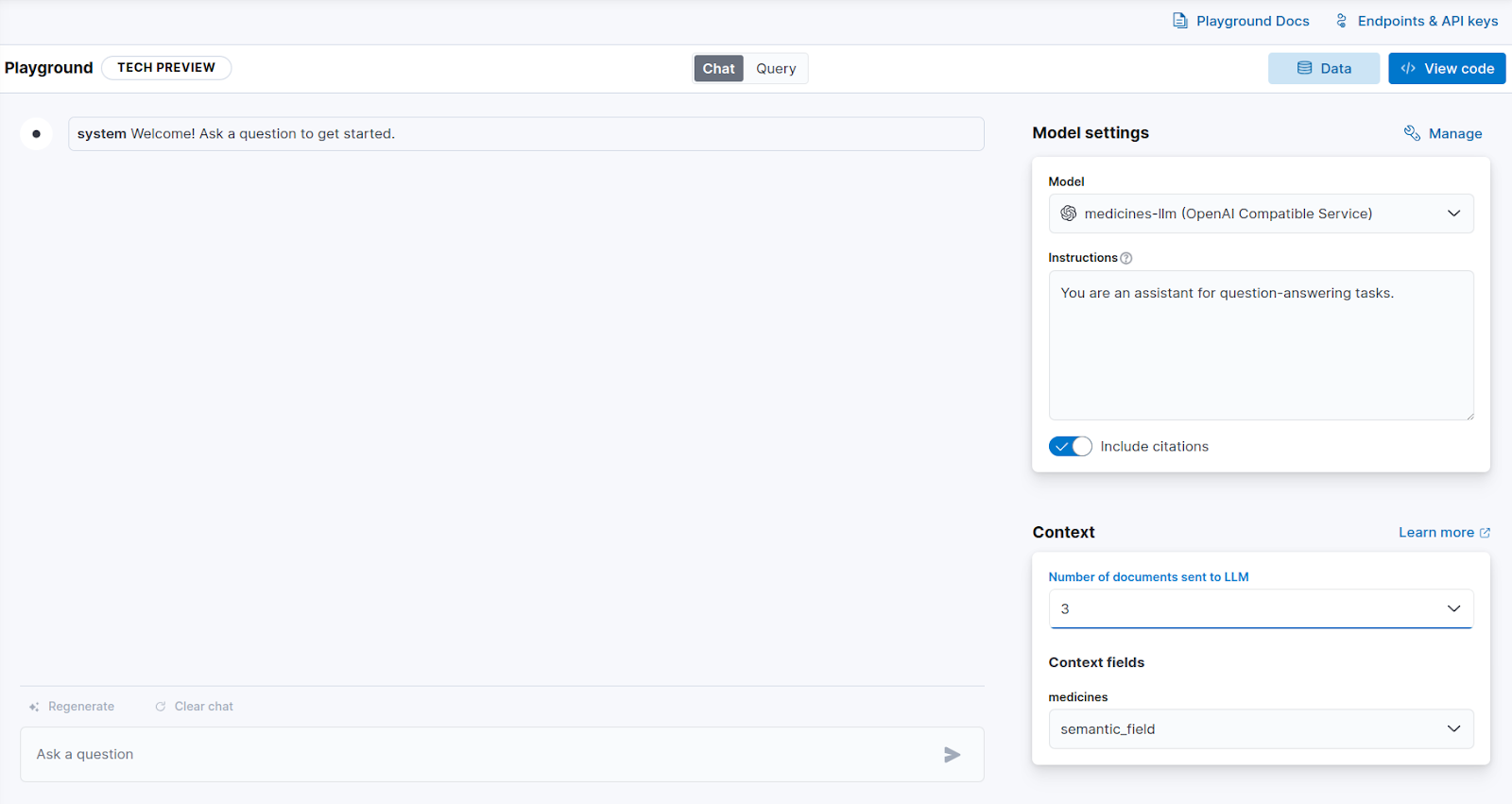
テストする前に、エージェントにさらに具体的な指示を追加し、モデルに送信されるドキュメントの数を 10 に増やして、回答にできるだけ多くのドキュメントが含まれるようにします。コンテキスト フィールドはsemantic_fieldになり、copy_to プロパティにより、薬剤の名前と説明が含まれます。
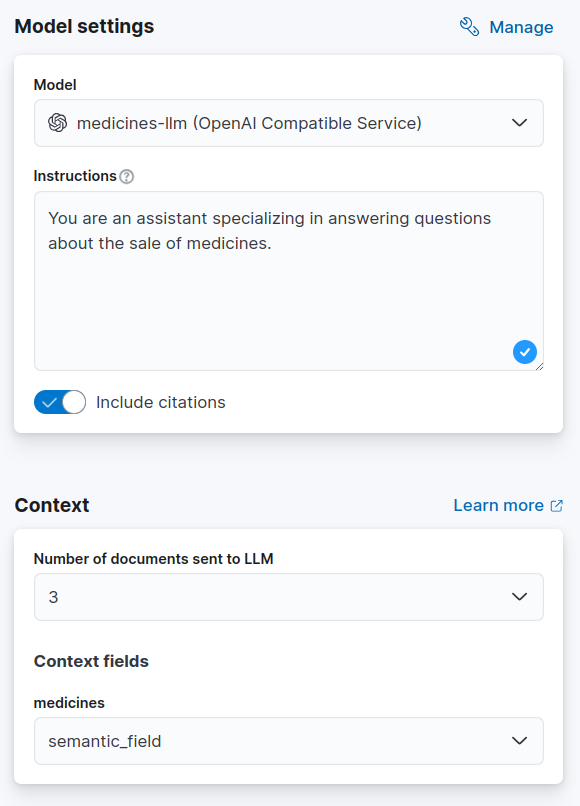
さて、質問しましょう:処方箋なしでクロナゼパムを購入できますか?そして何が起こるか見てみましょう:

予想通り、正しい答えが得られました。
今後の見通し
次のステップは、独自のアプリケーションを作成することです。Playground は、マシン上で実行し、ニーズに合わせてカスタマイズできる Python のコード スクリプトを提供します。たとえば、 FastAPIサーバーの背後に配置して、UI で使用される QA 医薬品チャットボットを作成します。
このコードは、Playground の右上のセクションにある[コードの表示]ボタンをクリックすると見つかります。
また、エンドポイントと API キーを使用して、コードで必要なES_API_KEY環境変数を生成します。
この特定の例では、コードは次のようになります。
## Install the required packages
## pip install -qU elasticsearch openai
import os
from elasticsearch import Elasticsearch
from openai import OpenAI
es_client = Elasticsearch(
"https://your-deployment.us-central1.gcp.cloud.es.io:443",
api_key=os.environ["ES_API_KEY"]
)
openai_client = OpenAI(
api_key=os.environ["OPENAI_API_KEY"],
)
index_source_fields = {
"medicines": [
"semantic_field"
]
}
def get_elasticsearch_results():
es_query = {
"retriever": {
"standard": {
"query": {
"nested": {
"path": "semantic_field.inference.chunks",
"query": {
"sparse_vector": {
"inference_id": "medicines-inference",
"field": "semantic_field.inference.chunks.embeddings",
"query": query
}
},
"inner_hits": {
"size": 2,
"name": "medicines.semantic_field",
"_source": [
"semantic_field.inference.chunks.text"
]
}
}
}
}
},
"size": 3
}
result = es_client.search(index="medicines", body=es_query)
return result["hits"]["hits"]
def create_openai_prompt(results):
context = ""
for hit in results:
inner_hit_path = f"{hit['_index']}.{index_source_fields.get(hit['_index'])[0]}"
## For semantic_text matches, we need to extract the text from the inner_hits
if 'inner_hits' in hit and inner_hit_path in hit['inner_hits']:
context += '\n --- \n'.join(inner_hit['_source']['text'] for inner_hit in hit['inner_hits'][inner_hit_path]['hits']['hits'])
else:
source_field = index_source_fields.get(hit["_index"])[0]
hit_context = hit["_source"][source_field]
context += f"{hit_context}\n"
prompt = f"""
Instructions:
- You are an assistant specializing in answering questions about the sale of medicines.
- Answer questions truthfully and factually using only the context presented.
- If you don't know the answer, just say that you don't know, don't make up an answer.
- You must always cite the document where the answer was extracted using inline academic citation style [], using the position.
- Use markdown format for code examples.
- You are correct, factual, precise, and reliable.
Context:
{context}
"""
return prompt
def generate_openai_completion(user_prompt, question):
response = openai_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": user_prompt},
{"role": "user", "content": question},
]
)
return response.choices[0].message.content
if __name__ == "__main__":
question = "my question"
elasticsearch_results = get_elasticsearch_results()
context_prompt = create_openai_prompt(elasticsearch_results)
openai_completion = generate_openai_completion(context_prompt, question)
print(openai_completion)Ollama で動作させるには、OpenAI クライアントを OpenAI サーバーではなく Ollama サーバーに接続するように変更する必要があります。OpenAI の例と互換性のあるエンドポイントの完全なリストについては、こちらをご覧ください。
openai_client = OpenAI(
# you can use http://localhost:11434/v1/ if running this code locally.
base_url='https://your-ngrok-url.ngrok-free.app/v1/',
# required but ignored
api_key='ollama',
)また、補完メソッドを呼び出すときにモデルを llama3.2 に変更します。
def generate_openai_completion(user_prompt, question):
response = openai_client.chat.completions.create(
model="llama3.2",
messages=[
{"role": "system", "content": user_prompt},
{"role": "user", "content": question},
]
)
return response.choices[0].message.content質問を追加しましょう:処方箋なしでクロナゼパムを購入できますか?Elasticsearch クエリへ:
def get_elasticsearch_results():
es_query = {
"retriever": {
"standard": {
"query": {
"nested": {
"path": "semantic_field.inference.chunks",
"query": {
"sparse_vector": {
"inference_id": "medicines-inference",
"field": "semantic_field.inference.chunks.embeddings",
"query": "Can I buy Clonazepam without a prescription?"
}
},
"inner_hits": {
"size": 2,
"name": "medicines.semantic_field",
"_source": [
"semantic_field.inference.chunks.text"
]
}
}
}
}
},
"size": 3
}
result = es_client.search(index="medicines", body=es_query)
return result["hits"]["hits"]また、いくつかの出力を伴う完了呼び出しでは、質問のコンテキストの一部として Elasticsearch の結果が送信されていることを確認できます。
if __name__ == "__main__":
question = "Can I buy Clonazepam without a prescription?"
elasticsearch_results = get_elasticsearch_results()
context_prompt = create_openai_prompt(elasticsearch_results)
print("========== Context Prompt START ==========")
print(context_prompt)
print("========== Context Prompt END ==========")
print("========== Ollama Completion START ==========")
openai_completion = generate_openai_completion(context_prompt, question)
print(openai_completion)
print("========== Ollama Completion END ==========")ではコマンドを実行してみましょう
pip install -qU elasticsearch openai
python main.py
次のような画面が表示されます。
========== Context Prompt START ==========
Instructions:
- You are an assistant specializing in answering questions about the sale of medicines.
- Answer questions truthfully and factually using only the context presented.
- If you don't know the answer, just say that you don't know, don't make up an answer.
- You must always cite the document where the answer was extracted using inline academic citation style [], using the position.
- Use markdown format for code examples.
- You are correct, factual, precise, and reliable.
Context:
Clonazepam
---
An antiepileptic medication that requires a prescription.A nonsteroidal anti-inflammatory drug (NSAID) available WITHOUT a prescription.
---
IbuprofenAn anxiolytic medication that strictly requires a prescription.
---
Lorazepam
========== Context Prompt END ==========
========== Ollama Completion START ==========
No, you cannot buy Clonazepam over-the-counter (OTC) without a prescription [1]. It is classified as a controlled substance in the United States due to its potential for dependence and abuse. Therefore, it can only be obtained from a licensed healthcare provider who will issue a prescription for this medication.
========== Ollama Completion END ==========まとめ
この記事では、Ollama などのツールを Elasticsearch 推論 API および Playground と組み合わせて使用した場合の、その強力さと汎用性について説明します。
いくつかの簡単な手順を実行するだけで、LLM を使用したチャット機能を備えた RAG アプリケーションが、コストゼロで独自のインフラストラクチャで稼働するようになりました。これにより、さまざまなタスクのさまざまなモデルにアクセスできるだけでなく、リソースと機密情報をより細かく制御できるようになります。
Ollama を Elastic Inference API と連携して使う方法
Ollama と Elastic Inference API を使用して Playground で RAG アプリを作成する
1.
Ollama LLMサーバーのセットアップ
2.
マッピングを作成する
3.
データのインデキシング
4.
Playgroundを使って質問する
よくあるご質問
Ollamaとは何ですか?
Ollama は、独自のインフラストラクチャ (ローカル マシン/サーバー) を使用して LLM モデルをダウンロードおよび実行できるツールです。