Get hands-on with Elasticsearch: Dive into our sample notebooks in the Elasticsearch Labs repo, start a free cloud trial, or try Elastic on your local machine now.
Building generative AI (GenAI) applications is all the rage, and context engineering, that is, providing the prompt structure and data needed for a large language model (LLM) to return specific, relevant answers to a question without filling in the blanks itself, is one of the most popular patterns that has emerged in the past 24 months. One particular subset of context engineering, retrieval-augmented generation (RAG), is being used widely to bring additional context to LLM interactions by using the power of natural language-based search to surface the most relevant results in private datasets based on meaning rather than on keywords.
As context engineering is exploding, ensuring that rapid prototype projects don’t expose business- or mission-critical data to unauthorized recipients is a significant concern. For audiences interested in technology and policy alike, I've championed the concept of a privacy-first GenAI sandbox, which I’ll simply refer to as a sandbox from here on. In this article, the term sandbox refers to a self-service, secure prototyping space (much like a child's sandbox, where the wooden edges prevent sand from escaping), allowing organization members to test their custom context engineering applications safely, without risking exposure of confidential data.
Production-grade GenAI sandboxes = enabling privacy
GenAI, from text-generating tools, like ChatGPT, Claude, and Gemini, to image creators, such as Google’s Nano Banana, OpenAI’s DALL-E, and Midjourney, has sparked discussions everywhere: in classrooms, at dinner tables, in regulatory circles, in courts, and in boardrooms over the past two years.
I’ve had the privilege of sharing Elastic’s approach to context engineering, and particularly RAG, with customers, including developers and C-suite executives, and with contacts of mine, ranging from friends and family to legislators. Think of context engineering as a librarian that looks up and then serves contextual data to augment text, audio, or image GenAI apps that they don’t have in the data they were trained on for their intended tasks; for example, looking up sports scores and headlines to help a text-generation application answer the question, “What happened in the National Hockey League yesterday?”
Elasticsearch Labs has fabulous primers on context engineering here and RAG here, if you’re unfamiliar with the concept and would like to do more reading.
A privacy first approach ensures that context engineering supplies the GenAI app with protected, selected, or delicate data, fostering responses that are better informed and more pertinent than what might be generated using solely public information. An example of this would be providing a GenAI-powered, interactive text chat experience (chatbot) for university students to obtain financial aid and scholarship information relevant to their personal background, without risking exposure of personally identifiable information (PII), such as their Social Security number or birthdate, to malicious actors extracting information via common vulnerabilities, as per the OWASP Top 10, or the LLM itself.
The core tenets of the logic behind deploying a sandbox are as follows:
- Users will find a way to incorporate GenAI into their daily workflow, regardless of whether one’s organization provides the tools. Even in organizations where preventing such “shadow IT” is, realistically, impractical or impossible, providing and monitoring access to prevent disclosure of an organization’s sensitive data still remains imperative; a sandbox is just the place to turn such tools loose.
- Providing a sandbox to deploy applications with Application Performance Monitoring (APM) and information security (InfoSec) best practices embedded allows an organization to derive insights into potential use cases for GenAI while also safeguarding privacy, enabling audit and accountability of GenAI use, and establishing centralized cost management.
- An organization’s sandbox should allow either self-service or low-touch deployment of peer-reviewed GenAI applications to permit maximum experimentation with minimum friction by those inclined to develop their own applications.
- If properly implemented and contained within the organization’s controlled perimeter, the sandbox allows leveraging data assets available to the organization without triggering the liabilities that could attach to unauthorized or unintended external sharing or other leakage of protected data such as PII – think California CCPA, or the EU/UK GDPR for instance.
This article will not focus on building a GenAI app; there are numerous excellent examples here on Elasticsearch Labs. Instead, I’ll be focusing on the recipe necessary for deploying a sandbox that provides the security and availability needed to implement principle #3 above.
Foundational ingredients
For a sandbox to be considered production grade, the following foundational ingredients should be considered:
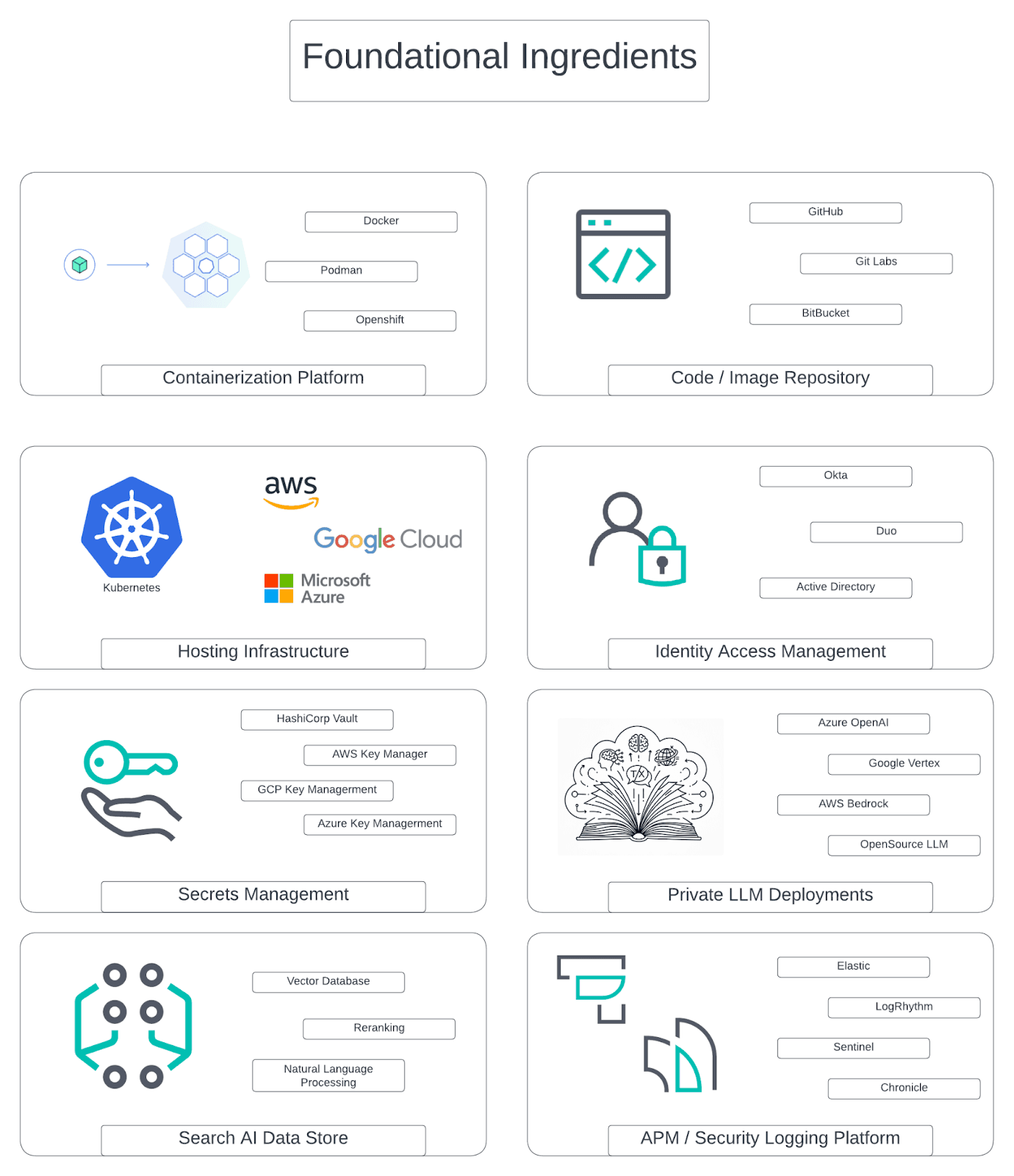
Figure 1: The ingredients we'll use in our cookbook. (Click to enlarge.)
Let's explore why each ingredient plays a crucial role in our sandbox recipe. As we do, please note that brand-name decisions I’ve listed below are based on personal experience and aren’t an endorsement of one technology or another by Elastic. As with any recipe, these then form my preferred ingredients. You can, of course, substitute in each area to make the recipe to your liking:
1. Containerization platform
The first ingredient in our sandbox recipe is the selection of a containerization platform. These platforms, while conceptually similar to the virtual machines that have been a staple of enterprise IT for the past 15+ years, represent a significant evolution in how applications are packaged and deployed. They’re designed for rapid deployment, upgrades without service disruption, and native distribution across both on-premises and cloud computing environments, while also providing increased testability, validation of infrastructure, and auditability. The platform you choose, often managed through infrastructure as code (IaC) to ensure reproducibility and consistency, is the foundation that enables agility and scalability for your GenAI applications.
Key components of a containerization platform
A robust containerization platform is built on several key components:
- Container runtime: The software that executes containers and manages their lifecycle. A popular example is Docker, which provides the tools to build, share, and run container images.
- Image build infrastructure: This is the process and tooling used to create container images from your application's source code. Tools like Dockerfiles provide a clear, repeatable way to define the environment, dependencies, and application code within an image, ensuring consistency across development, testing, and production environments.
- Orchestration engine: For a production-grade environment, you need a system to automate the deployment, scaling, and management of containers. Kubernetes (k8s) is the industry-standard for this, providing powerful features for load balancing, self-healing, and service discovery. More on that below in ingredient #2.
1. 1 Infrastructure as code:
To ensure the reproducibility and maintainability of your sandbox, a containerization platform should be managed using IaC principles. This means that instead of manually configuring your platform, you define your infrastructure (for example, Kubernetes clusters, networking rules, security policies) in code files (for example, using Terraform or Pulumi). This approach provides several benefits:
- Version control: Your infrastructure can be treated like any other code, allowing you to track changes, revert to previous versions, and collaborate with your team using Git.
- Consistency: IaC dramatically reduces manual errors and ensures that your sandbox environment can be recreated identically in any cloud or on-premises location.
- Automation: It enables you to automate the entire setup and teardown process, making it easy to create temporary sandboxes for specific projects or testing.
2. Hosting and orchestration
As we introduced in the "Containerization platform" section, a powerful orchestration engine is needed to manage our containers at scale. For this, k8s is the de facto standard for orchestrating a production-grade sandbox. If you’re unfamiliar, check out the Cloud Native Computing Foundation (CNCF) primer on k8s available here. Whether running in the cloud or on-premises, Kubernetes provides the robust framework needed to deploy, scale, and manage the lifecycle of containerized applications. Major cloud providers, like Google Cloud (Google Kubernetes Engine [GKE]), Amazon Web Services (Elastic Kubernetes Service [EKS]), and Microsoft Azure (Azure Kubernetes Service [AKS]), all offer mature, managed Kubernetes services that handle the underlying complexity, including in particular contractually assured and independently certified compliance with statutory privacy and information security mandates, allowing your teams to focus on building and deploying applications.
For a GenAI sandbox, Kubernetes is particularly valuable because it can efficiently manage and scale GPU resources, which are often necessary for two key components of the GenAI stack: 1) privately hosted LLMs; and 2) the inference processes that power them (discussed in more detail in ingredients #6 and #7). Its ability to automate deployments and manage resources ensures that rapid prototypers can experiment with different models and applications without needing to become infrastructure experts, all within the secure and isolated area, called a namespace in k8s, that you define. This abstraction is key to the sandbox's success, empowering innovation while maintaining centralized control.
3. Code repository / image repository
A centralized code repository is an essential element of a secure and collaborative GenAI sandbox. It provides a single, controlled environment for developers to store, manage, and version their code, preventing the proliferation of sensitive information across disparate, unsecured locations. By establishing a centralized repository, organizations can enforce security policies, monitor for vulnerabilities, and maintain a clear audit trail of all code changes, which is critical for maintaining data privacy and integrity within the sandbox environment.
For instance, a service like GitHub, when integrated with your organization's identity and access management (IAM) and single sign-on (SSO) solutions (see ingredient #4 below), becomes a powerful tool for enforcing the principle of least privilege. This integration ensures that only authenticated and authorized developers can access specific code repositories. You can create teams and apply granular permissions, restricting access to sensitive projects and preventing unauthorized code modifications. This is especially important in a GenAI context where code might contain proprietary algorithms, sensitive data connectors, or even, in some cases, organization or user-level credentials or other confidential information.
Furthermore, modern repository platforms offer automated security scanning features. These tools continuously scan code for known vulnerabilities, insecure coding practices, and exposed secrets. If a developer accidentally commits a password or an API key, the system can automatically flag it and notify the security team. This proactive approach to security is essential for preventing data breaches, enforcing legal requirements and contractual commitments of confidentiality, and ensuring the overall integrity of the GenAI applications being developed to deploy in the sandbox. By mandating that all development occurs in a centralized and secured repository, you create a transparent, auditable, and secure foundation for innovation, allowing your developers the freedom to experiment without compromising organizational security.
4. Identity and access management
IAM is a core component of a secure, privacy-first grounded AI environment. It provides the foundation for ensuring that only authorized individuals and services can access sensitive data and powerful AI models. A robust IAM framework enforces the principle of least privilege, granting the minimum level of access necessary for a user or service to perform its function.
4.1 Single sign-on:
SSO streamlines user access by allowing users to authenticate once and gain access to multiple applications and services without re-entering their credentials. In a sandbox environment, SSO simplifies the user experience for developers, data scientists, and business users who need to interact with various components of the AI ecosystem, such as data repositories, modeling workbenches, and deployment pipelines. By centralizing authentication, SSO also enhances security by reducing the number of passwords that can be compromised and providing a single point for enforcing authentication policies. Importantly, it also lowers the barrier to entry for less-experienced developers to properly protect the data they are using in the sandbox, in turn preventing the inadvertent disclosure of sensitive information to insiders and outsiders alike.
4.2 Role-based access control:
Role-based access control (RBAC) is a method of restricting network access based on the roles of individual users within an organization. In the context of a GenAI sandbox, RBAC is used to define and enforce permissions for different user personas. For example, a data scientist role might have read/write access to specific datasets and the ability to apply machine learning models, while a business analyst role may only have read-only access to the outputs of those models. This ensures a clear separation of duties and prevents unauthorized access to or modification of sensitive data and AI assets.
4.3 Attribute-based access control:
Attribute-based access control (ABAC) provides a more granular and dynamic approach to access control than traditional RBAC. ABAC makes access decisions based on a combination of attributes of the user, the resource being accessed, and the environment. For instance, access to a particularly sensitive dataset could be restricted to users who are on the data scientist team (user attribute), accessing a resource tagged as PII (resource attribute), and are doing so from a corporate network during business hours (environment attributes). This level of granular control is critical in a GenAI sandbox for enforcing complex data governance and privacy requirements. We’ll come back to this later, when discussing the search AI datastore.
4.4 Access auditability:
A robust IAM framework also ensures that the granting, use, review and revocation of all access permissions is granularly logged, discoverable and auditable, so that in case of any suspected or confirmed incident, responders can quickly understand what happened, contain the incident, assess its extent, and comprehensively remedy its consequences. This is not only important for the organization’s own security, but also necessary to comply with any incident reporting and breach notice requirements that could be triggered.
5. Secrets management
Of all the ingredients in our recipe, secrets management is perhaps the most potent, yet most frequently overlooked. Much like a tiny pinch of saffron can dramatically alter a culinary dish, a single mishandled secret can have an outsized and devastating impact on your organization's security and reputation. In our context, a secret is any piece of sensitive information needed for our applications to function: API keys for first- or third-party services, database passwords, trust certificates, or tokens for authenticating to LLMs.
When these secrets are hard-coded into source code or left in plain-text configuration files, they create a massive vulnerability. A leaked API key or an exposed database credential can bypass all other security measures, providing a direct path for attackers to access sensitive data and systems. This is especially critical in a GenAI sandbox, where developers are frequently connecting to various data sources and external model providers. Without a robust secrets management strategy, you’re leaving the keys to your kingdom scattered across your digital landscape, turning your innovative sandbox into a potential source for a major data breach.
To properly secure these secrets, a dedicated secrets management platform is an essential ingredient. These tools provide a centralized, encrypted vault for storing secrets, with robust access control, auditing, and dynamic rotation capabilities. Whether you choose a self-hosted solution, like HashiCorp Vault, or a managed cloud service, such as Google Cloud's Secret Manager, or AWS Key Management Service (KMS), the principle is the same: Programmatically inject secrets into your applications at runtime. This practice ensures that secrets are never exposed in your code, keeping your most valuable credentials secure and your sandbox environment protected.
And this is more than just a best practice: since secret management technology is readily available and widely used, it forms part of the “state-of-the-art” which certain privacy laws and regulators reference as the benchmark against which an organization’s information security posture must be assessed. Failing to protect an organization’s most valuable secrets with the latest and greatest techniques available is not only a missed opportunity, it is also a potential case of regulatory non-compliance, as enforcement agencies and courts of law often recall.
6. Private LLM deployment(s)
Early in the advent of modern GenAI, the primary driver for using managed services, like Azure OpenAI, was the assurance that customer prompts and data would not be used to retrain public models. This was a crucial first step in enterprise adoption. However, as the field has matured, the conversation has shifted. While data privacy remains paramount, the decision to use private LLM instances, whether from major cloud providers or self-hosted, is now equally driven by the need for guaranteed throughput, predictable latency, and fine-grained control over the model's operational environment to support production-grade applications.
This critical ingredient comes in three distinct flavors, each with valid use cases and its own set of trade-offs:
A. Cloud-hosted SaaS
This is the most common and accessible approach. Services like OpenAI Enterprise, Azure OpenAI, Google Cloud's Vertex AI, and AWS Bedrock provide access to powerful, state-of-the-art models through a managed API.
- Pros: This flavor offers the fastest time-to-market. The cloud provider handles all the underlying infrastructure, scaling, and maintenance, allowing teams to focus purely on application development. It provides a simple, pay-as-you-go model and access to a diverse model library of proprietary and open-source options.
- Cons: This approach offers the least control over the underlying infrastructure, which can lead to variability in performance during peak demand. It can also be more expensive at very high volumes, and it creates a dependency on the provider's roadmap and model availability. It also increases the potential vulnerability surface of the application, with data leaving the customer premises: a challenge for highly regulated and/or sovereignty-minded customers.
B. Cloud-hosted GPU + containerized LLMs
This flavor involves running open-source LLMs (like models from Mistral or Meta's Llama series) on your own virtualized GPU infrastructure within a cloud provider. This is typically managed using the containerization and Kubernetes orchestration we've already discussed, often with high-performance inference servers like vLLM.
- Pros: This approach provides a powerful balance of control and flexibility. You gain direct control over resource allocation, model versioning, and the serving configuration, allowing for significant performance tuning. In high-concurrency scenarios, a well-tuned inference server can dramatically increase throughput. For example, benchmarks have shown inference engines like vLLM delivering significantly higher tokens-per-second and lower latency compared to less production-oriented servers under heavy load [Red Hat, 2025].
- Cons: This option carries a higher operational burden. Your team is now responsible for managing the GPU instances, container images, and the inference server configuration. It requires a deeper technical expertise in machine learning operations (MLOps) and infrastructure management to implement and maintain effectively.
C. On-premises GPUs + containerized LLMs
The most controlled, and often most complex, approach involves deploying containerized LLMs on your own dedicated hardware within your own data centers. This setup is functionally similar to the second flavor but removes the reliance on a public cloud provider for the hardware layer.
- Pros: This flavor offers maximum security, control, and data sovereignty. It’s the only option for organizations that require a completely air-gapped environment, where no data leaves the physical premises. For massive, predictable workloads, it can become more cost-effective in the long run by avoiding cloud data egress fees and per-transaction costs.
- Cons: The initial capital expenditure for purchasing and maintaining high-end GPU hardware is substantial. It requires a highly specialized team to manage the physical infrastructure, networking, and the entire software stack. This approach is more difficult to scale, as it requires the physical procurement and installation of new hardware.
7. Search AI data store
If the LLM is the brain of our GenAI application, then the datastore is its heart, pumping relevant, context-rich information to be reasoned upon. For a RAG application to be truly effective, it cannot rely on a simple vector database alone. The grounding data is often complex, containing a mix of unstructured text, structured metadata, and a variety of data types. Therefore, the datastore you select must possess a unique set of characteristics to handle this complexity at scale.
Underpinning this entire process is the creation of vector embeddings, numerical representations of your data relative to the knowledge set of that embedding space. To enable semantic search, your data must first be converted into these numerical representations by an inference model. A flexible datastore should not only store these vectors but also be capable of hosting the inference process itself. Crucially, it should allow you to use your model of choice, whether it's a state-of-the-art multilingual model, a fine-tuned model for a specific domain like finance or law, a compact model built for very high-speed results, or even a model that can process images. By managing inference, the platform ensures that your data is consistently and efficiently vectorized, paving the way for the powerful search capabilities that follow.
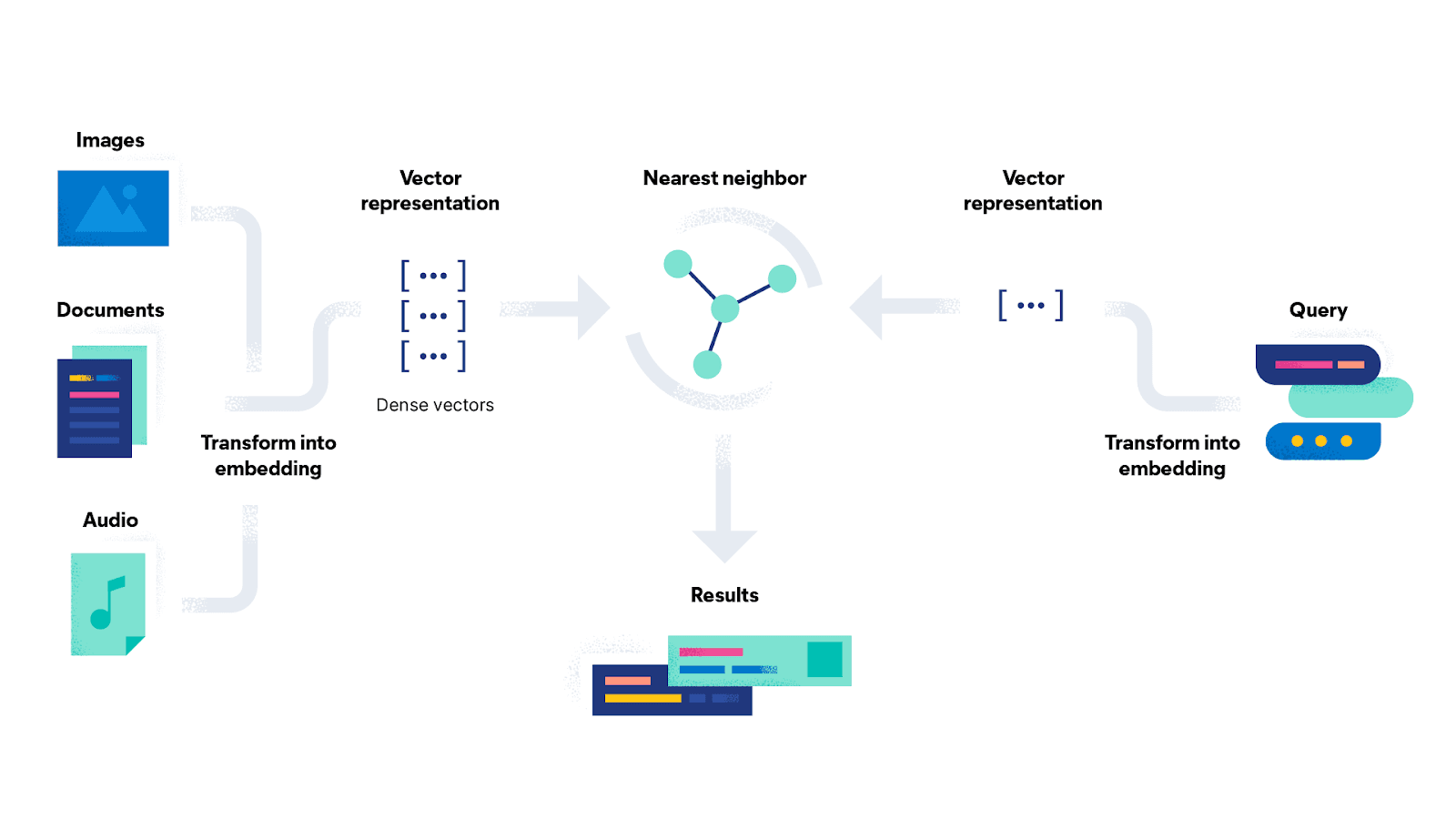
First, it must master hybrid search. The best retrieval systems don't force a choice between traditional keyword search, like BM25, which excels at finding specific keywords, and modern vector search, which excels at finding results using semantic meaning (that is, natural language). A truly capable datastore allows you to use both simultaneously in a single query. This ensures you can find documents that match exact product codes or acronyms while also finding documents that are conceptually related, providing the LLM with the most relevant possible context.
Second, it needs a sophisticated method for intelligent result reranking. When you run a hybrid search that combines multiple approaches, you need a way to merge the different result sets into a single, coherent ranking. Techniques like reciprocal rank fusion (RRF) are crucial here, as they intelligently combine the relevance scores from different queries to produce a final list that is more accurate and relevant than any single approach could deliver on its own.
Finally, a search AI-oriented datastore must be a unified engine with security built in. For enterprise RAG, it's not enough to just find similar vectors. You must be able to apply security and access controls to data before the search even happens. The aforementioned RBAC and ABAC capabilities allow prefiltering of content at search time, ensuring that the vector search is only performed on data a user is authorized to see. This mitigates risks of accidental or malicious circumvention of your access controls through the sandbox preserving demonstrable compliance with privacy and confidentiality requirements. This capability, which combines filtering, full-text search, and vector search in a single, scalable platform, is the defining characteristic of a datastore truly ready to power a secure, privacy-first GenAI sandbox.
8. APM and security
The final ingredient in our recipe ensures the health, security, and performance of the entire sandbox: a unified platform for APM and security information and event monitoring (SIEM). A key characteristic of a truly versatile search AI datastore is its ability to power the R in your RAG applications, while also acting as the standards-based repository for all logs, metrics, and traces generated by your infrastructure and applications. By consolidating this operational data into the same powerful datastore, you create a single pane of glass for observability and security.
This approach provides several critical capabilities. At the infrastructure level, you can monitor the performance and resource utilization of both the k8s clusters hosting your sandbox and the underlying GPUs that power your LLMs, allowing you to proactively identify bottlenecks or failures. At the application layer, APM provides detailed traces to diagnose latency issues or errors within your GenAI prototypes. For security, this centralized datastore becomes your SIEM, correlating login events, application logs, and network traffic to detect anomalous behavior or potential threats within the sandbox.
Most importantly, this unified platform allows you to gain deep insights into the usage of the GenAI applications themselves. By ingesting and analyzing the application telemetry, which should include the prompts being submitted by users wherever permissible, potentially with PII redacted, you can identify trends, understand what types of questions are being asked, and discover popular use cases. This provides an invaluable feedback loop for improving your RAG applications and demonstrates the power of using a single, scalable datastore to secure, monitor, and optimize your entire GenAI ecosystem.
Cooking the recipe
With all of the ingredients in place, let’s talk about the steps for assembling them into a production-grade sandbox.
As with any recipe book, let’s start with a photo of the cooked dish. Here’s a view of what a final architecture might look like:
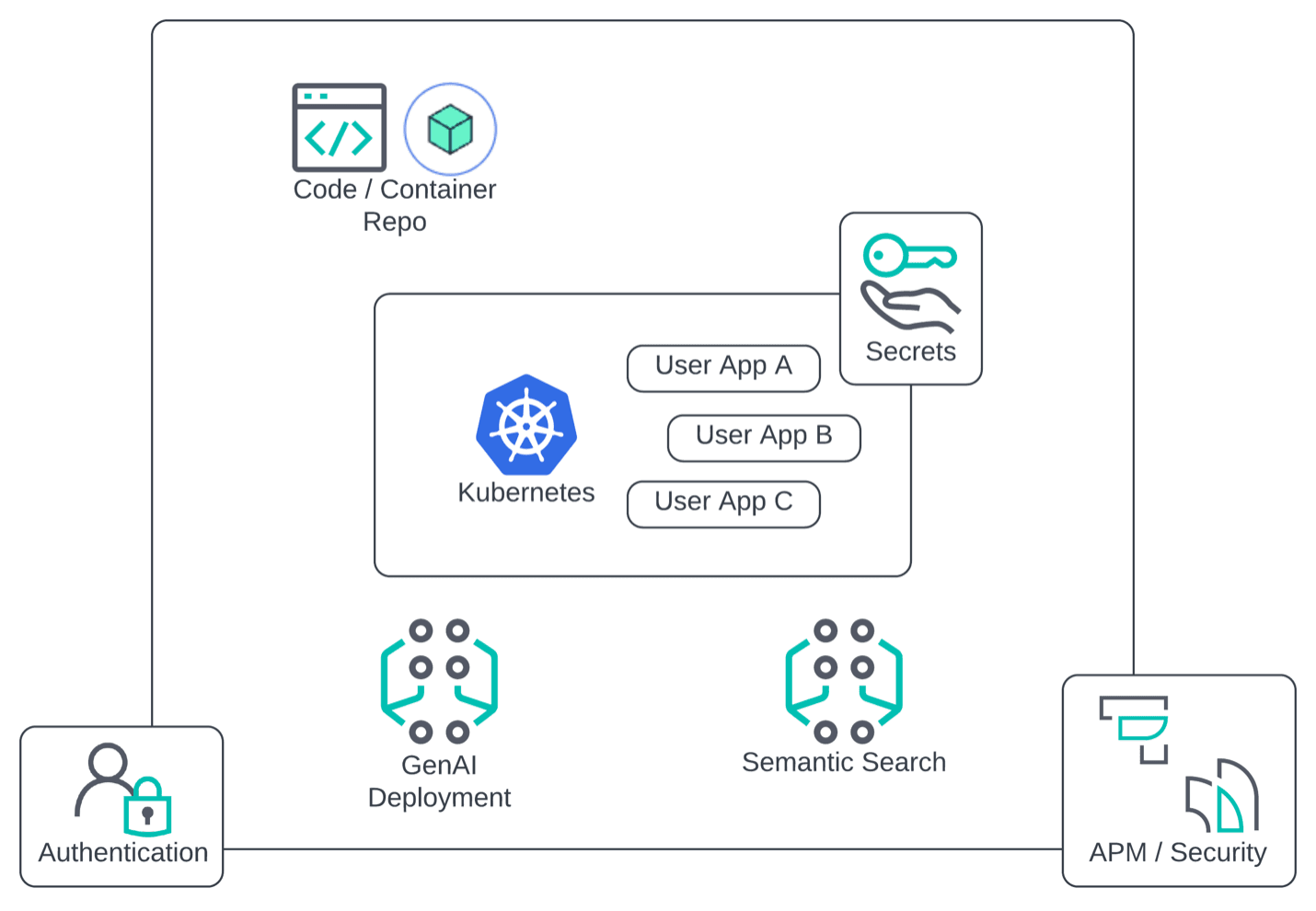
Figure 2: The finished sandbox after cooking the recipe.
The holistic environment depicted here consists of a Kubernetes cluster to host your sandboxed AI applications (with dev/preprod/prod namespaces for a continuous integration and continuous deployment [CI/CD] pipeline), an IAM infrastructure for authentication, a few GenAI applications, a repository for code and container images, and a wrapper of APM and cyber monitoring around the entire sandbox.
Recipe step 0: Policy baseline
Before you begin mixing any ingredients, every good chef performs their mise en place, that is, setting up their station for success. In our recipe, this means establishing clear policies for how the sandbox will be used. This is the foundational step, where you decide the rules of your kitchen. Will developers be allowed to use internal production data, or production data sanitized with techniques like pseudonymization and differential privacy, or life-like synthetic data, or only public data? Will the sandbox be a completely self-service platform, or a managed service with guardrails? Will application updates require a formal Change Review Board, or is a peer-review process sufficient? These questions are highly specific to each organization’s context and purposes. Answering them up front is critical, as these policy decisions will directly influence how you configure every other ingredient in the recipe.
Recipe step 1: InfoSec baseline
As stated in the “Ingredients” section, IAM is a nonnegotiable part of our recipe. Before letting anyone into the kitchen, you must secure the perimeter and ensure only authorized chefs wearing your approved uniform and compliant protective gear can access the tools and ingredients. This means working directly with your information security organization from day one to build the sandbox on a foundation of strong security principles. Access to your datastore, your code repository, your Kubernetes hosting environment, and the applications themselves must be restricted based on established best practices.
With your organization’s IAM policies enforced in the environment, a practical authentication flow might look like the one depicted in figure 3.
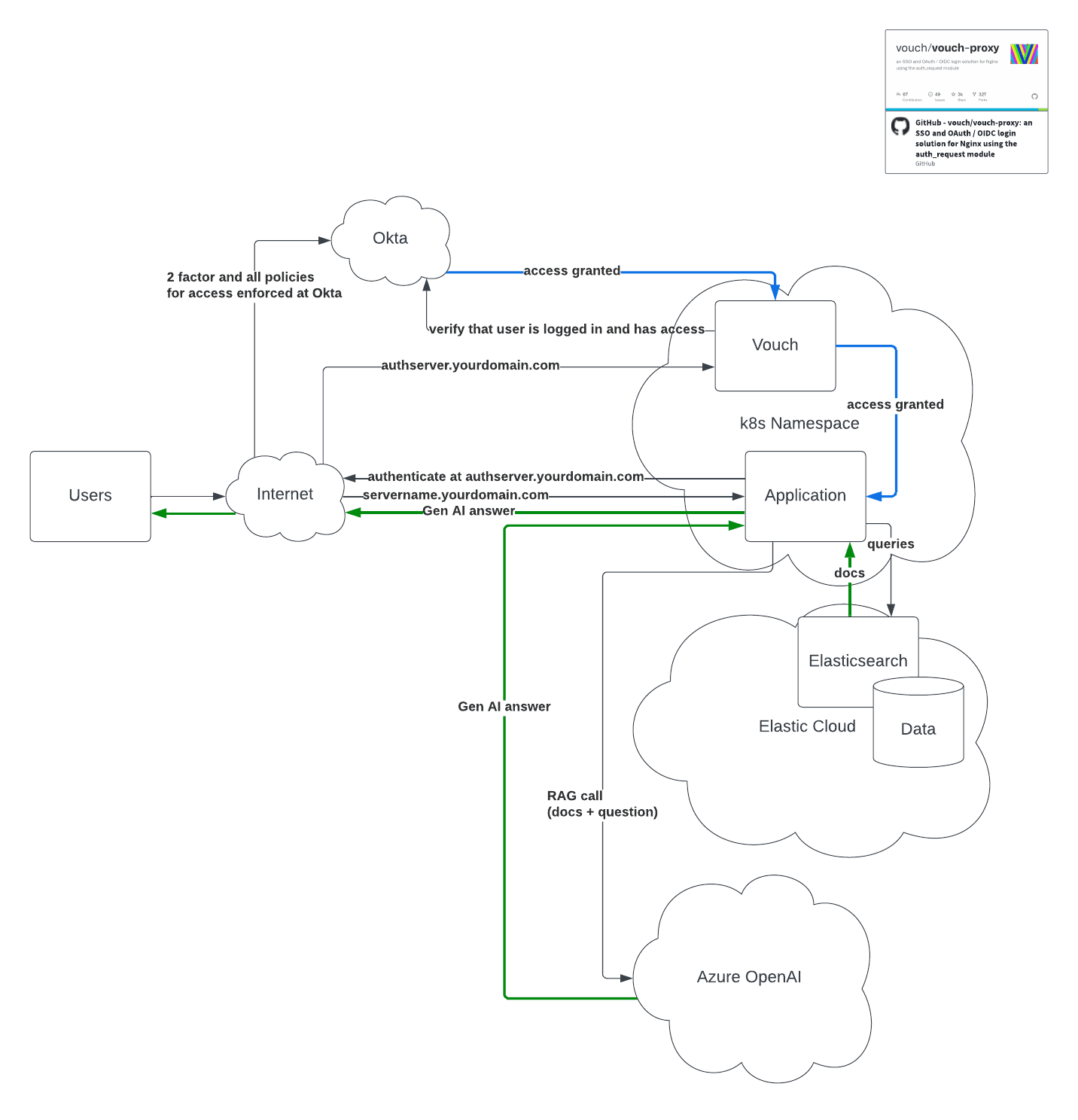
Figure 3: Reverse-proxy authentication to secure workloads from unauthorized access.
As you can see in the figure, no communication can occur between applications in the Kubernetes production namespace without first passing through an OAuth proxy, such as Vouch. This ensures every user is authenticated against a central provider, like Okta, which enforces policies such as two-factor authentication. In this model, critical user context, such as username and IP address, can be passed along with every request, enabling robust auditing and nonrepudiation at the application layer.
Recipe step 2: Container configuration baseline
Assuming that many of your rapid prototypers are passionate innovators but not necessarily seasoned software engineers or legally trained data compliance experts, it’s critical to provide a baseline configuration to ensure their success and security, without putting them at risk of breaching any rules or policies inadvertently. Think of this step as providing a master recipe card that guarantees consistency. At a minimum, you should provide clear documentation on how to build a container image, deploy it into the Kubernetes cluster, and test that all connectivity is secure.
Even better, you can create a “Clone This Starter App” template in your code repository. This gives developers a preconfigured, security-blessed starting point, complete with Dockerfiles and pipeline scripts, that they can immediately fork to begin tinkering, dramatically lowering the barrier to entry while enforcing best practices from the outset.
Additionally, many real life GenAI use cases will inevitably involve some form of PII processing, or can produce outputs that will materially impact individuals such as your employees, your consumers, or your customers’ staff. In such cases, more and more state, federal and international laws require completing various risk assessments before actual work can begin. These assessments can be cumbersome to conduct and are difficult to scale if they are carried out case by case. The “Clone This Starter App” approach also helps to prevent such compliance mandates from becoming bottlenecks to innovation, since under most legal mandates, the required assessments can be completed once for your template, and they need not be repeated for any clone that doesn’t exceed your initially defined parameters.
Recipe step 3: Deploy user applications
With your policies defined, your security baseline established, and your developer templates in place, it’s finally time to serve the dish. Whether you've chosen a self-service or managed deployment model, you can now confidently invite the rapid prototypers in your organization to start creating in the sandbox.
Because you’ve included APM and security logging (ingredient #8) from the beginning, you have the necessary observability to monitor application performance and user activity. This is where the magic happens: You can now learn from the applications people build, identify powerful new use cases, and gather real-world data to improve the platform, all while safeguarding organizational data. Coincidentally, this approach will also allow you to organically collect the information you might need to put on record, disclose to users, or share with auditors and regulators to demonstrate the transparency, accountability and explainability of your GenAI application, ticking many compliance boxes as you build (and not after the fact) – a textbook best practice of Privacy by Design.
Where do you go from here?
We've now walked through the entire cookbook, from selecting your fresh ingredients to following the recipe step by step. Most of the domains we've discussed (containerization, APM, IAM, and more) are culinary specialties in and of themselves.
Conclusion
This cookbook was designed to provide a clear recipe for building a production-grade GenAI sandbox. By carefully selecting each foundational ingredient, from your containerization platform and Kubernetes orchestration to your search AI datastore and unified APM, you ensure your final dish will be both successful and secure. Following the recipe ensures that this powerful environment is built on a foundation of security and thoughtful policy from day one.
The goal is to empower your rapid prototypers, not restrict them, and to foster a culture of responsible innovation. By providing a secure, observable, and well-equipped kitchen for experimentation, you get ahead of the curve, fostering a culture of responsible innovation. This proactive approach enables you to harness the creativity of your entire organization, transforming brilliant ideas into tangible prototypes while preventing the rise of shadow AI. You've cooked the meal; now you can enjoy the innovation it serves.
If you want to chat about this or anything else related to Elasticsearch, come join us in our Discuss forum.
関連記事

2026年7月1日
One command. Natural language. Your Elasticsearch data, straight to the terminal.
Query your Elasticsearch data from the terminal in plain English. The official Elastic GitHub Copilot CLI plugin generates and runs ES|QL queries against your cluster. No Kibana, no manual syntax.

Introducing unified API keys for Elastic Cloud Serverless and Elasticsearch
Learn how Elastic unified control plane and data plane authentication in Serverless with a globally distributed IAM architecture. Use one API key for Cloud and Elasticsearch APIs.

2026年4月14日
How big is too big? Elasticsearch sizing best practices
There’s no hard size limit in Elasticsearch, but there are clear signals you've outgrown your setup. Learn how to size shards, manage node limits, choose storage by tier, and use AutoOps to catch problems before they happen.
2026年4月3日
Monitoring Kibana dashboard views with Elastic Workflows
Learn how to use Elastic Workflows to collect Kibana dashboard view metrics every 30 minutes and index them into Elasticsearch, so you can build custom analytics and visualizations on top of your own data.

2026年2月19日
Dependency management on Kubernetes
How to streamline dependency management on Kubernetes using Renovate CLI and Argo Workflows.