ベクトル検索からパワフルなREST APIまで、Elasticsearchは最も広範な検索ツールキットを開発者に提供します。Elasticsearch Labsリポジトリのサンプルノートで新しいことに挑戦してみましょう。また、無料トライアルを始めるか、ローカルでElasticsearchを実行することもできます。
すべてのコードは 、Searchlabs リポジトリの advanced-rag-techniques ブランチに あります 。
高度な RAG テクニックに関する記事のパート 2 へようこそ。このシリーズのパート 1では、高度な RAG パイプラインのデータ処理コンポーネントを設定、説明、実装しました。
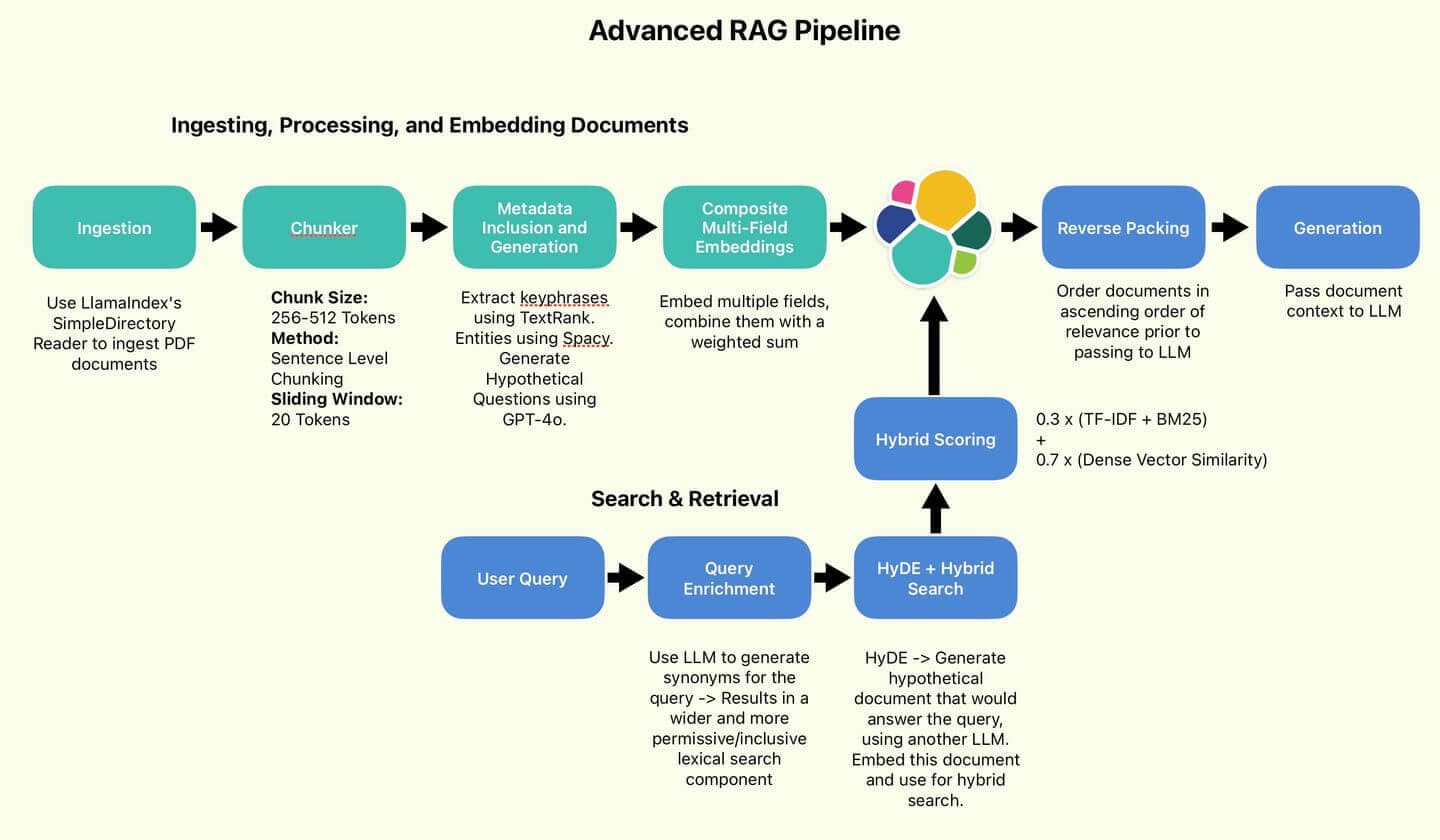
著者が使用した RAG パイプライン。
この部分では、実装のクエリとテストを進めていきます。早速始めましょう!
目次
検索と取得、回答の生成
最初のクエリ、理想的には主に年次報告書に記載されている情報を尋ねてみましょう。いかがでしょうか:
ここで、クエリを強化するためにいくつかのテクニックを適用してみましょう。
同義語によるクエリの強化
まず、クエリの文言の多様性を高めて、Elasticsearch クエリに簡単に処理できる形式に変えてみましょう。GPT-4o の助けを借りて、クエリを OR 句のリストに変換します。次のプロンプトを書いてみましょう:
GPT-4o をクエリに適用すると、基本クエリの同義語と関連語彙が生成されます。
ESQueryMakerクラスでは、クエリを分割する関数を定義しました。
その役割は、この OR 句の文字列を取得して用語のリストに分割し、主要なドキュメント フィールドで複数の一致を実行できるようにすることです。
最終的にこのクエリに至ります:
これにより、元のクエリよりも多くのベースがカバーされ、同義語を忘れたために検索結果を見逃すリスクが軽減されることが期待されます。しかし、私たちにはもっとできることがある。
HyDE(仮想文書埋め込み)
今回はHyDE を実装するために、再び GPT-4o を活用しましょう。
HyDE の基本的な前提は、仮想ドキュメント (元のクエリに対する回答が含まれる可能性のある種類のドキュメント) を生成することです。文書の事実性や正確性は問題ではありません。それを念頭に置いて、次のプロンプトを書いてみましょう。
ベクトル検索は通常、コサインベクトルの類似度に基づいて行われるため、クエリをドキュメントに一致させるのではなく、ドキュメントをドキュメントに一致させることでより良い結果を達成できるというのが HyDE の前提です。
私たちが重視するのは、構造、フロー、用語です。あまり事実ではない。GPT-4o は次のような HyDE ドキュメントを出力します。
これはかなり信憑性があり、インデックスを作成したい種類のドキュメントに最適な候補のように見えます。これを埋め込み、ハイブリッド検索に使用します。
ハイブリッド検索
これが私たちの検索ロジックの中核です。語彙検索コンポーネントは、生成された OR 句の文字列になります。高密度ベクトル コンポーネントには、HyDE ドキュメント (検索ベクトルとも呼ばれます) が埋め込まれます。KNN を使用して、検索ベクトルに最も近い候補ドキュメントをいくつか効率的に識別します。デフォルトでは、語彙検索コンポーネントをTF-IDF と BM25 によるスコアリングと呼びます。最後に、語彙スコアと密なベクトルスコアは、 Wang らが推奨する 30/70 比率を使用して結合されます。
最後に、RAG 関数を組み立てることができます。クエリから回答までの RAG の流れは次のようになります。
- クエリを OR 句に変換します。
- HyDE ドキュメントを生成して埋め込みます。
- 両方をハイブリッド検索への入力として渡します。
- 上位 n 件の結果を取得し、最も関連性の高いスコアが LLM のコンテキスト メモリ内で「最新」になるように結果を逆にします (逆パッキング)。逆パッキングの例: クエリ:「Elasticsearch クエリ最適化手法」取得されたドキュメント (関連性の高い順): LLM コンテキストの順序を逆にする: 順序を逆にすることで、最も関連性の高い情報 (1) がコンテキストの最後に表示され、回答生成中に LLM からより多くの注目を受ける可能性が高くなります。
- 「ブールクエリを使用して、複数の検索条件を効率的に組み合わせます。」
- 「クエリの応答時間を改善するためのキャッシュ戦略を実装します。」
- 「インデックス マッピングを最適化して、検索パフォーマンスを高速化します。」
- 「インデックス マッピングを最適化して、検索パフォーマンスを高速化します。」
- 「クエリの応答時間を改善するためのキャッシュ戦略を実装します。」
- 「ブールクエリを使用して、複数の検索条件を効率的に組み合わせます。」
- 生成のためにコンテキストを LLM に渡します。
クエリを実行して回答を取得してみましょう。
ニース。そうです。
実験
今答えなければならない重要な質問があります。これらの実装に多大な労力と追加の複雑さを投資することで、何が得られましたか?
少し比較してみましょう。私たちが実装した RAG パイプラインと、私たちが行った機能強化のないベースライン ハイブリッド検索を比較したものです。小規模な一連のテストを実行して、大きな違いが見られるか確認します。ここで実装した RAG を AdvancedRAG と呼び、基本パイプラインを SimpleRAG と呼びます。

余計な機能のないシンプルなRAGパイプライン
結果の要約
この表は、両方の RAG パイプラインの 5 つのテストの結果をまとめたものです。回答の詳細と品質に基づいて各方法の相対的な優位性を判断しましたが、これは完全に主観的な判断です。実際の回答はこの表の下に再現されていますので、ご参照ください。それでは、彼らの成果を見てみましょう!
SimpleRAG は質問 1 と 5 に答えることができませんでした。AdvancedRAG は質問 2、3、4 についても非常に詳しく説明しました。詳細度が増したことにより、AdvancedRAG の回答の質が優れていると判断しました。
| テスト | 質問 | 高度なRAGパフォーマンス | SimpleRAG パフォーマンス | AdvancedRAG レイテンシー | SimpleRAG レイテンシ | 勝者 |
|---|---|---|---|---|---|---|
| 1 | Elastic を監査するのは誰ですか? | 監査人として PwC を正しく特定しました。 | 監査人を識別できませんでした。 | 11.6秒 | 4.4秒 | アドバンスドRAG |
| 2 | 2023年の総収益はいくらでしたか? | 正しい収益数値を提供しました。前年度の収益に関する追加のコンテキストを含めました。 | 正しい収益数値を提供しました。 | 13.3秒 | 2.8秒 | アドバンスドRAG |
| 3 | 成長は主にどの製品に依存しますか?いくら? | Elastic Cloud が主要な推進力であることを正しく認識しました。全体的な収益コンテキストとより詳しい詳細が含まれています。 | Elastic Cloud が主要な推進力であることを正しく認識しました。 | 14.1秒 | 12.8秒 | アドバンスドRAG |
| 4 | 従業員福利厚生プランの説明 | 退職金制度、健康プログラム、その他の福利厚生について包括的に説明しました。異なる年ごとの具体的な寄付金額が含まれています。 | 報酬、退職金制度、職場環境、Elastic Cares プログラムなどの福利厚生の概要をわかりやすく説明しました。 | 26.6秒 | 11.6秒 | アドバンスドRAG |
| 5 | Elastic が買収した企業はどれですか? | レポートに記載されている最近の買収 (CmdWatch、Build Security、Optimyze) を正しくリストしました。いくつかの取得日と購入価格を提供しました。 | 提供されたコンテキストから関連情報を取得できませんでした。 | 11.9秒 | 2.7秒 | アドバンスドRAG |
テスト 1: Elastic を監査するのは誰ですか?
アドバンスドRAG
シンプルラグ
要約: SimpleRAGはPWCを監査人として特定しなかった
そうですね、それは実はかなり驚きました。これは SimpleRAG 側の検索失敗のようです。監査に関連する文書は取得されませんでした。次のテストでは難易度を少し下げてみましょう。
テスト2:2023年の総収入
アドバンスドRAG
シンプルラグ
要約: 両RAGとも正解: 2023年の総収益は1,068,989,000ドル
二人ともここにいました。AdvancedRAG がより広範囲の文書を入手したように思われますか?確かに、答えはより詳細で、前年からの情報が組み込まれています。私たちが行った機能強化を考えると、それは予想されることですが、判断するには時期尚早です。
難易度を上げてみましょう。
テスト 3: 成長は主にどの製品に依存しますか?いくら?
アドバンスドRAG
シンプルラグ
概要: 両方の RAG は、Elastic Cloud を主要な成長原動力として正しく認識しました。ただし、AdvancedRAG では、サブスクリプション収益と顧客の増加を考慮したより詳細な情報が含まれており、Elastic の他の製品についても明示的に言及されています。
テスト4: 従業員福利厚生制度の説明
アドバンスドRAG
シンプルラグ
概要: AdvancedRAG では、米国に拠点を置く従業員向けの 401K プランや、米国外の定義拠出金プランについてさらに詳しく取り上げています。また、健康と幸福の計画についても言及していますが、SimpleRAG が言及している Elastic Cares プログラムについては触れられていません。
テスト 5: Elastic が買収した企業はどれですか?
アドバンスドRAG
シンプルラグ
概要: SimpleRAG は買収に関する関連情報を取得せず、回答に失敗しました。AdvancedRAG は、レポートに記載されている主要な買収である CmdWatch、Build Security、Optimyze を正しくリストしています。
まとめ
私たちのテストによると、私たちの高度な技術により、提示される情報の範囲と深さが拡大し、RAG 回答の品質が向上する可能性があるようです。
さらに、 Which companies did Elastic acquire?やWho audits Elasticなどのあいまいな表現の質問に対して、AdvancedRAG では正しく回答されましたが、SimpleRAG では正しく回答されなかったため、信頼性が向上する可能性があります。
ただし、5 件中 3 件では、ハイブリッド検索のみを組み込んだ基本的な RAG パイプラインで、重要な情報のほとんどを捉えた回答を生成できたという点に留意する価値があります。
データ準備フェーズとクエリフェーズに LLM が組み込まれているため、AdvancedRAG のレイテンシは通常、SimpleRAG の 2 ~ 5 倍になることに注意してください。これは大きなコストであるため、AdvancedRAG は、応答品質がレイテンシーよりも優先される状況にのみ適している可能性があります。
データ準備段階で Claude Haiku や GPT-4o-mini などの小型で安価な LLM を使用すると、大きなレイテンシ コストを軽減できます。回答生成用の高度なモデルを保存します。
これは Wang らの研究結果と一致しています。結果が示すように、行われた改善は比較的漸進的です。つまり、シンプルなベースライン RAG を使用すると、安価で高速でありながら、適切な最終製品にほぼ到達できます。私にとっては、それは興味深い結論です。速度と効率が重要となるユースケースでは、SimpleRAG が賢明な選択です。パフォーマンスを最大限に引き出す必要があるユースケースでは、AdvancedRAG に組み込まれたテクニックが解決策となる可能性があります。

Wang らによる研究の結果は、高度な技術の使用により、一貫性のある漸進的な改善がもたらされることを明らかにしました。
付記
プロンプト
RAG質問回答プロンプト
クエリとコンテキストに基づいて LLM に回答を生成させるためのプロンプト。
弾性クエリジェネレータプロンプト
同義語を使用してクエリを拡充し、OR 形式に変換するように要求します。
潜在的な質問ジェネレータプロンプト
潜在的な質問の生成を促し、ドキュメントのメタデータを充実させます。
HyDEジェネレータプロンプト
HyDEを使用して仮想文書を生成するためのプロンプト
ハイブリッド検索クエリのサンプル
関連記事

描くのではなく、説明する:MCPとES|QLによるAIネイティブのKibanaダッシュボード
プロンプトからダッシュボードへ。example-mcp-dashbuilderを使って、自然言語でKibanaダッシュボードを構築する方法を学びましょう。ES|QLクエリを書き、インタラクティブなグラフを作成し、全面的に機能するダッシュボードをKibanaに直接エクスポートするオープンソースのMCPアプリケーションです。

2026年4月23日
ベクトル検索を世界最速のものにするためにElasticsearch simdvecを構築した方法
Elasticsearchのすべてのベクトル検索クエリの基盤となる、手作業で調整されたSIMDカーネルライブラリElasticsearch simdvecの構築方法。

2026年5月4日
Elasticsearchの検索再現率を測定・改善する方法:ハイブリッド検索で0.43から0.75へ
Elasticsearchにおける検索再現率を測定および改善する方法を学びましょう。BM25の語彙検索とJina AIのベクトル埋め込みを組み合わせ、rank_eval APIを使用して実際の数値で改善効果を検証します。

2026年4月10日
Elasticsearch + Jina埋め込みによる教師なし文書クラスタリング
ElasticsearchとJina埋め込みを使用した教師なし文書クラスタリングへの実用的で再現可能なアプローチ。

2026年4月2日
TSDSとILMが出会うとき:遅延データを拒否しない時系列データストリームの設計
TSDSの時間制限はILMフェーズとどのように相互作用するのか、そして遅れて到着するメトリクスを許容するポリシーを設計する方法。