ベクトル検索からパワフルなREST APIまで、Elasticsearchは最も広範な検索ツールキットを開発者に提供します。Elasticsearch Labsリポジトリのサンプルノートで新しいことに挑戦してみましょう。また、無料トライアルを始めるか、ローカルでElasticsearchを実行することもできます。
これは、高度なRAGテクニックを探るパート1です。パート2はこちらをクリックしてください!
最近の論文「検索拡張生成におけるベスト プラクティスの探求」では、 RAG のベスト プラクティスのセットに収束することを目的として、さまざまな RAG 強化手法の有効性を経験的に評価しています。

Wang 氏とその同僚が推奨する RAG パイプライン。
提案されたベストプラクティスのいくつか、つまり検索の品質を向上させることを目的としたベストプラクティス(センテンスチャンキング、HyDE、リバースパッキング)を実装します。
簡潔にするために、効率性の向上に重点を置いた手法(クエリの分類と要約)は省略します。
また、ここでは取り上げなかったものの、個人的には便利で興味深いと思われるいくつかのテクニック(メタデータの包含、複合マルチフィールドの埋め込み、クエリの強化) も実装します。
最後に、検索結果と生成された回答の品質がベースラインと比較して向上したかどうかを確認するための短いテストを実行します。さあ始めましょう!
RAGの概要
RAG は、外部の知識ベースから情報を取得して生成された回答を充実させることで、LLM を強化することを目的としています。ドメイン固有の情報を提供することで、LLM はトレーニング データの範囲外のユース ケースに迅速に適応できます。微調整よりも大幅にコストが安く、最新の状態に保つのも簡単になります。
RAG の品質を向上させるための対策は、通常、次の 2 つの点に重点を置いています。
- ナレッジベースの品質と明確さを向上します。
- 検索クエリの範囲と特定性を向上させます。
これら 2 つの対策により、LLM が関連する事実や情報にアクセスできる可能性が高まり、幻覚を起こしたり、古くなったり無関係になったりする可能性のある独自の知識を利用したりする可能性が低くなるという目標が達成されます。
方法の多様性を数文で説明するのは困難です。わかりやすくするために、すぐに実装に移りましょう。
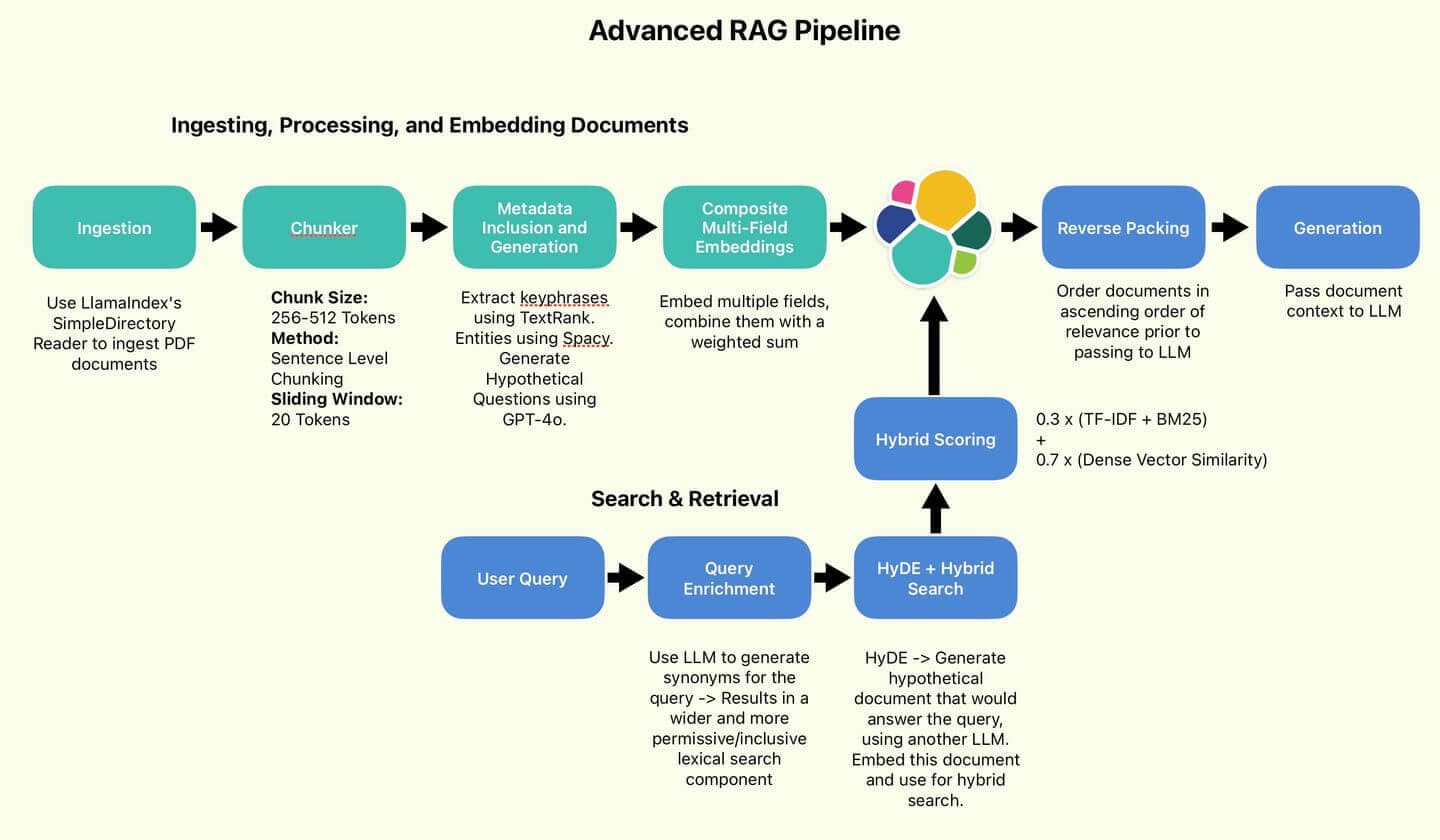
図 1: 著者が使用した RAG パイプライン。
目次
設定
すべてのコードは Searchlabs リポジトリに あります 。
まずは第一に。次のものが必要になります:
- 弾力性のあるクラウドの展開
- LLM API - このノートブックでは、Azure OpenAI 上の GPT-4o デプロイメントを使用しています。
- Python バージョン 3.12.4 以降
main.ipynb ノートブックからすべてのコードを実行します。
リポジトリを git clone し、supporting-blog-content/advanced-rag-techniques に移動して、次のコマンドを実行します。
完了したら、 .envを作成します。ファイルを開き、次のフィールドに入力します ( .env.exampleで参照されます)。有益なコメントをくれた共著者の Claude-3.5 に感謝します。
次に、取り込むドキュメントを選択し、ドキュメント フォルダーに配置します。この記事では、 Elastic NV Annual Report 2023 を使用します。これは非常に難しくて密度の高いドキュメントであり、RAG テクニックのストレス テストに最適です。

Elastic 年次報告書 2023
準備が整いましたので、摂取に移りましょう。main.ipynbを開き、最初の 2 つのセルを実行して、すべてのパッケージをインポートし、すべてのサービスを初期化します。
ドキュメントの取り込み、処理、埋め込み
データインジェスト
- 個人的なメモ: LlamaIndex の便利さに驚いています。LLM や LlamaIndex が登場する前の昔、さまざまな形式のドキュメントを取り込むには、あらゆる場所から難解なパッケージを収集する、骨の折れる作業でした。今では、関数呼び出しは 1 つに減りました。野生。
SimpleDirectoryReaderはdirectory_path.内のすべてのドキュメントをロードします。 .pdfファイルの場合は、ドキュメント オブジェクトのリストを返します。このリストは、操作しやすいように Python 辞書に変換します。
各辞書には、 textフィールドにキー コンテンツが含まれています。また、ページ番号、ファイル名、ファイル サイズ、タイプなどの便利なメタデータも含まれています。
文レベル、トークン単位のチャンキング
最初にやるべきことは、ドキュメントを標準的な長さのチャンクに削減することです (一貫性と管理性を確保するため)。埋め込みモデルには、固有のトークン制限 (処理できる最大入力サイズ) があります。トークンはモデルが処理するテキストの基本単位です。情報の損失(コンテンツの切り捨てや省略)を防ぐために、これらの制限を超えないテキストを提供する必要があります(長いテキストを短いセグメントに分割する)。
チャンク化はパフォーマンスに大きな影響を与えます。理想的には、各チャンクは自己完結的な情報を表し、単一のトピックに関するコンテキスト情報をキャプチャします。チャンク化の方法には、文書を単語数で分割する単語レベルのチャンク化と、LLM を使用して論理ブレークポイントを識別するセマンティック チャンク化があります。
単語レベルのチャンキングは安価で高速かつ簡単ですが、文が分割され、コンテキストが壊れるリスクがあります。セマンティック チャンキングは、特に 116 ページの Elastic 年次レポートのようなドキュメントを扱う場合には、時間がかかり、コストも高くなります。
中道的なアプローチを選択しましょう。文レベルのチャンキングは依然としてシンプルですが、単語レベルのチャンキングよりもコンテキストをより効果的に保持でき、コストも大幅に削減され、処理速度も速くなります。さらに、周囲のコンテキストの一部をキャプチャし、段落を分割することによる影響を軽減するために、スライディング ウィンドウを実装します。
Chunkerクラスは埋め込みモデルのトークナイザーを受け取り、テキストをエンコードおよびデコードします。ここで、20 個のトークンが重なり合う、それぞれ 512 個のトークンのチャンクを構築します。これを実行するには、テキストを文に分割し、それらの文をトークン化してから、トークン制限に違反することなく追加できなくなるまで、トークン化された文を現在のチャンクに追加します。
最後に、埋め込みのために文章を元のテキストにデコードし、 original_textというフィールドに保存します。チャンクはchunkというフィールドに保存されます。ノイズ(つまり、無駄なドキュメント)を減らすために、長さが 50 トークン未満のドキュメントは破棄されます。
これをドキュメント上で実行してみましょう。
そして、次のようなテキストのチャンクが返されます。
メタデータの包含と生成
ドキュメントをチャンクに分割しました。次は、データを充実させる段階です。追加のメタデータを生成または抽出したい。この追加のメタデータは、検索パフォーマンスに影響を与え、強化するために使用できます。
ドキュメントのリスト (Python 辞書) とプロセッサ関数のリストを受け取る役割を持つDocumentEnricherクラスを定義します。これらの関数はドキュメントのoriginal_text列を実行し、その出力を新しいフィールドに保存します。
まず、 TextRankを使用してキーフレーズを抽出します。TextRank は、単語間の関係に基づいて重要度をランク付けすることにより、テキストから主要なフレーズと文を抽出するグラフベースのアルゴリズムです。
次に、 GPT-4oを使用してpotential_questionsを生成します。
最後に、 Spacy を使用して エンティティを抽出します 。
それぞれのコードは非常に長くて複雑なので、ここで再現することは控えます。ご興味があれば、以下のコード サンプルにファイルがマークされています。
データ拡充を実行してみましょう:
結果を見てみましょう:
TextRankによって抽出されたキーフレーズ
これらのキーフレーズは、チャンクの中核トピックの代わりとなります。クエリがサイバーセキュリティに関係する場合、このチャンクのスコアは向上します。
GPT-4oによって生成される潜在的な質問
これらの潜在的な質問はユーザーのクエリと直接一致する可能性があり、スコアの向上につながります。GPT-4o に、現在のチャンクにある情報を使用して回答できる質問を生成するように指示します。
Spacyによって抽出されたエンティティ
これらのエンティティはキーフレーズと同様の目的を果たしますが、キーフレーズ抽出では見逃される可能性のある組織や個人の名前を取得します。
複合多体埋め込み
追加のメタデータでドキュメントを充実させたので、この情報を活用して、より堅牢でコンテキストを認識した埋め込みを作成できます。
プロセスの現在のポイントを確認しましょう。各ドキュメントには 4 つの興味深いフィールドがあります。
各フィールドはドキュメントのコンテキストに関する異なる視点を表し、LLM が重点を置くべき重要な領域を強調する可能性があります。

メタデータエンリッチメントパイプライン
計画としては、これらの各フィールドを埋め込み、複合埋め込みと呼ばれる埋め込みの加重合計を作成することです。
運が良ければ、この複合埋め込みにより、検索動作を制御する別の調整可能なハイパーパラメータが導入されるだけでなく、システムがよりコンテキストを認識できるようになります。
まず、main.ipynb ノートブックの先頭にインポートされたローカルに定義された埋め込みモデルを使用して、各フィールドを埋め込み、各ドキュメントを更新します。
各埋め込み関数は埋め込みのフィールドを返します。これは、 _embeddingという接尾辞が付いた元の入力フィールドです。
複合埋め込みの重みを定義しましょう。
重み付けにより、ユースケースとデータの品質に基づいて各コンポーネントに優先順位を割り当てることができます。直感的に言えば、これらの重み付けの大きさは、各コンポーネントの意味的価値に依存します。チャンクテキスト自体が圧倒的に豊富なので、重み付けを 70% に割り当てます。エンティティは組織名や人名のリストだけなので最も小さいので、重み付けを 5% に割り当てます。これらの値の正確な設定は、ユースケースごとに経験的に決定する必要があります。
最後に、重み付けを適用し、複合埋め込みを作成する関数を記述しましょう。スペースを節約するために、コンポーネントの埋め込みもすべて削除します。
これで書類の処理は完了です。次のようなドキュメント オブジェクトのリストが作成されました。
Elasticへのインデックス
ドキュメントを Elastic Search に一括アップロードしてみましょう。この目的のために、私はずっと前にelastic_helpers.pyで Elastic Helper 関数のセットを定義しました。これは非常に長いコードなので、関数呼び出しに注目してみましょう。
es_bulk_indexer.bulk_upload_documents Elasticsearch の便利な動的マッピングを活用して、辞書オブジェクトの任意のリストで動作します。
Kibana にアクセスして、すべてのドキュメントがインデックスされていることを確認します。全部で224個あるはずです。こんなに大きな文書にしては悪くないですね!
Kibanaでインデックスされた年次報告書文書
猫の休憩
ちょっと休憩しましょう。記事がちょっと重いのはわかっています。私の猫を見てください:

彼女がどれだけ怒っているか見てください
愛らしい。帽子がなくなってしまったので、彼女がそれを盗んでどこかに隠したのではないかと半分疑っています :(
ここまで来られたことおめでとうございます :)
パート 2では、RAG パイプラインのテストと評価についてご紹介します。
付記
定義
1. 文のチャンキング
- RAG システムでテキストをより小さな意味のある単位に分割するために使用される前処理手法。
- プロセス:
- 入力: 大きなテキストブロック(例: 文書、段落)
- 出力: 小さなテキストセグメント (通常は文または小さな文のグループ)
- 目的:
- きめ細やかでコンテキストに特化したテキストセグメントを作成する
- より正確なインデックス作成と検索が可能
- RAGシステムで取得した情報の関連性を向上
- 特徴:
- セグメントは意味的に意味がある
- 独立してインデックスを作成し、検索できる
- 多くの場合、独立した理解可能性を確保するためにある程度の文脈が保持される
- メリット:
- 検索精度の向上
- RAGパイプラインのより集中的な拡張を可能にします
2. HyDE(仮想文書埋め込み)
- LLM を使用して、RAG システムでのクエリ拡張用の仮想ドキュメントを生成する手法。
- プロセス:
- LLMへの入力クエリ
- LLMはクエリに答える仮説文書を生成する
- 生成されたドキュメントを埋め込む
- ベクトル検索に埋め込みを使用する
- 主な違い:
- 従来のRAG: クエリとドキュメントを一致させる
- HyDE: 文書を文書と照合する
- 目的:
- 特に複雑または曖昧なクエリの検索パフォーマンスを向上します
- 短いクエリよりも豊富な意味コンテキストをキャプチャする
- メリット:
- LLMの知識を活用してクエリを拡張する
- 検索された文書の関連性が向上する可能性がある
- 課題:
- 追加のLLM推論が必要となり、レイテンシとコストが増加する
- パフォーマンスは生成された仮想文書の品質に依存する
3. 逆パッキング
- RAG システムで、検索結果を LLM に渡す前に並べ替えるために使用される手法。
- プロセス:
- 検索エンジン (Elasticsearch など) は、関連性の高い順にドキュメントを返します。
- 順序は逆になり、最も関連性の高いドキュメントが最後に配置されます。
- 目的:
- LLM の新しさバイアスを利用します。LLM は、それぞれのコンテキストにおける最新の情報に重点を置く傾向があります。
- LLM のコンテキスト ウィンドウ内で最も関連性の高い情報が「最新」であることを保証します。
- 例:元の順序: [最も関連性の高い順、2番目に関連性の高い順、3番目に関連性の高い順、...] 逆の順序: [...、3番目に関連性の高い順、2番目に関連性の高い順、最も関連性の高い順]
4. クエリの分類
- クエリに RAG が必要かどうか、または LLM によって直接回答できるかどうかを判断して、RAG システムの効率を最適化する手法。
- プロセス:
- 使用中の LLM に固有のカスタム データセットを開発する
- 特殊な分類モデルをトレーニングする
- モデルを使用して受信したクエリを分類する
- 目的:
- 不要なRAG処理を回避することでシステム効率を向上
- 最も適切な応答メカニズムにクエリを直接送信する
- 要件:
- LLM固有のデータセットとモデル
- 精度を維持するための継続的な改良
- メリット:
- 単純なクエリの計算オーバーヘッドを削減
- 非RAGクエリの応答時間を改善する可能性がある
5. 要約
- RAG システムで検索された文書を圧縮する手法。
- プロセス:
- 関連文書を取得する
- 各文書の簡潔な要約を生成する
- RAG パイプラインでは完全なドキュメントではなく要約を使用する
- 目的:
- 重要な情報に焦点を当ててRAGのパフォーマンスを向上させる
- 関連性の低いコンテンツからのノイズや干渉を減らす
- メリット:
- LLM回答の関連性が向上する可能性がある
- コンテキスト制限内でより多くのドキュメントを含めることができます
- 課題:
- 要約時に重要な詳細が失われるリスク
- 要約生成のための追加の計算オーバーヘッド
6. メタデータの包含
- 追加のコンテキスト情報でドキュメントを充実させる手法。
- メタデータの種類:
- キーフレーズ
- タイトル
- 日付
- 著者詳細
- 宣伝文句
- 目的:
- RAGシステムで利用可能なコンテキスト情報を増やす
- LLMに文書の内容と関連性をより明確に理解させる
- メリット:
- 検索精度が向上する可能性がある
- LLMの文書有用性を評価する能力を強化する
- 実装:
- 文書の前処理中に実行できる
- 追加のデータ抽出または生成手順が必要になる場合があります
7. 複合多体埋め込み
- 異なるドキュメント コンポーネントごとに個別の埋め込みを作成する RAG システム用の高度な埋め込み手法。
- プロセス:
- 関連するフィールド(例:タイトル、キーフレーズ、宣伝文句、メインコンテンツ)を特定する
- 各フィールドごとに個別の埋め込みを生成する
- これらの埋め込みを結合または保存して検索に使用します
- 標準的なアプローチとの違い:
- 従来型: ドキュメント全体の単一の埋め込み
- 複合: さまざまなドキュメントの側面に対応する複数の埋め込み
- 目的:
- よりニュアンス豊かで文脈を考慮した文書表現を作成する
- 文書内のより多様なソースから情報を取得する
- メリット:
- 曖昧なクエリや多面的なクエリのパフォーマンスが向上する可能性があります
- 検索時にさまざまな文書の側面をより柔軟に重み付けできます
- 課題:
- 埋め込みストレージと検索プロセスの複雑さが増す
- より洗練されたマッチングアルゴリズムが必要になる場合があります
8. クエリエンリッチメント
- 元のクエリを関連用語で拡張し、検索範囲を広げる手法。
- プロセス:
- 元のクエリを分析する
- 同義語や意味的に関連するフレーズを生成する
- クエリに以下の追加用語を追加します
- 目的:
- 文書コーパス内の潜在的な一致の範囲を拡大する
- 特定の言語や専門用語を含むクエリの検索パフォーマンスを向上
- メリット:
- 元の検索語句と完全に一致しない関連文書を取得する可能性がある
- クエリとドキュメント間の語彙の不一致を克服するのに役立ちます
- 課題:
- 慎重に実装しないとクエリドリフトのリスクがある
- 検索プロセスにおける計算オーバーヘッドが増加する可能性がある
関連記事

描くのではなく、説明する:MCPとES|QLによるAIネイティブのKibanaダッシュボード
プロンプトからダッシュボードへ。example-mcp-dashbuilderを使って、自然言語でKibanaダッシュボードを構築する方法を学びましょう。ES|QLクエリを書き、インタラクティブなグラフを作成し、全面的に機能するダッシュボードをKibanaに直接エクスポートするオープンソースのMCPアプリケーションです。

2026年4月23日
ベクトル検索を世界最速のものにするためにElasticsearch simdvecを構築した方法
Elasticsearchのすべてのベクトル検索クエリの基盤となる、手作業で調整されたSIMDカーネルライブラリElasticsearch simdvecの構築方法。

2026年5月4日
Elasticsearchの検索再現率を測定・改善する方法:ハイブリッド検索で0.43から0.75へ
Elasticsearchにおける検索再現率を測定および改善する方法を学びましょう。BM25の語彙検索とJina AIのベクトル埋め込みを組み合わせ、rank_eval APIを使用して実際の数値で改善効果を検証します。

2026年4月10日
Elasticsearch + Jina埋め込みによる教師なし文書クラスタリング
ElasticsearchとJina埋め込みを使用した教師なし文書クラスタリングへの実用的で再現可能なアプローチ。

2026年4月2日
TSDSとILMが出会うとき:遅延データを拒否しない時系列データストリームの設計
TSDSの時間制限はILMフェーズとどのように相互作用するのか、そして遅れて到着するメトリクスを許容するポリシーを設計する方法。