Try out vector search for yourself using this self-paced hands-on learning for Search AI. You can start a free cloud trial or try Elastic on your local machine now.
Elasticsearch as a vector database offers you an efficient way to create, store, and search vector embeddings at scale. Its core is built on simdvec, which offers up to ~50x faster vector search than serial code and 2–3x over Java's Panama Vector API. Simdvec speed comes from Single Instruction, Multiple Data (SIMD) instructions implemented in modern CPUs, in many cases from instructions that CPU vendors never built for vector search at all.
Modern CPUs contain astonishingly fast execution units, but they only accelerate a limited set of carefully chosen operations, and the ones you need often don't exist. The challenge is not finding the fastest instruction, but rather to reformulate the computation so it can be expressed in terms of instructions the hardware executes efficiently.
This post covers four examples of that reformulation in action:
- Quantization to int7 to fit neural-network unsigned*signed multiply-accumulate instructions.
- Algebraic bias rewrites for full int8 vectors scoring, using video-encoding sum of absolute differences instructions.
- Express bf16 euclidean distance as three dot products, making the most of the few bf16 instructions available.
- Rework binary vector dot product in terms of multi-element (and multi-vector) bit operations, using SIMD popcount when available, and byte shuffles and lookups when it's not.
The bit the compiler can't see: How int7 enables the fastest integer multiply-accumulate
In our byte-vector kernels for x86, we wanted to make use of vpdpbusd, the fastest integer dot-product instruction available on modern x86 CPUs. There was just one problem: It was designed for neural-network inference, not vector search. One operand of vpdpbusd must be unsigned and the other signed, which doesn’t match how vector embeddings are normally represented.
The x86 SIMD instruction set includes multiple multiply-accumulate instructions designed for integer byte data: Besides the more general maddubs (available on all AVX2 and AVX-512 processors), newer processors implement the faster vpdpbusd (available on processors with Vector Neural Network Instructions [VNNI]), which fuses maddubs, madd, and accumulation (add) into a single instruction.
For both instructions, one operand is treated as unsigned bytes [0, 255] and the other as signed bytes [-128, 127]. This asymmetry comes from their original deep-learning inference purpose, where post-ReLU activations are unsigned and weights are signed. We cannot directly use these instructions with two signed operands; the result would be wrong. For example, if you feed a signed byte with value -1 (bit pattern 0xFF) into the unsigned operand, the instruction silently interprets it as 255.
So why should we bother with vpdpbusd? Besides its intrinsic speed (it performs multiple ops with the same throughput of a single instruction), the alternative is to use instructions operating at 16-bit width: Load half a register of byte data, widen each byte to 16-bit, and multiply at 16-bit width. This would halve the number of elements per register and per load; byte-width multiply-accumulate, like vpdpbusd, would process 2x as many elements for the same memory bandwidth. As we saw in the previous post, these kernels are often limited by how fast they can load data, more than how fast they can compute. Using vpdpbusd translates to a direct 2x advantage.
Elasticsearch's optimized scalar quantization (OSQ) supports multiple bit widths, including a 7-bit mode. At 7 bits, every quantized value is in the range [0, 127]. The high bit is always zero, meaning that the signed and unsigned interpretations of every number in the range are identical. This means we can use the unsigned*signed multiply-accumulate instructions, as they will produce the correct result without any transformation.
This was a co-design decision: By quantizing to 7 bits instead of 8, we trade one bit of precision for direct access to the fastest integer multiply-accumulate available on the hardware. The trade-off is well worth it: Benchmarks show a ~6x speedup with negligible recall loss. (All details and JMH benchmarks can be found in the linked PR.)
Intuition and design choices drove this gain: A compiler could never make this call. For the compiler, data is an int8_t, a signed type with range [-128, 127]. It cannot prove the values are non-negative or infer that vpdpbusd is safe to use on non-negative numbers, so it would never emit vpdpbusd. The call requires knowledge about the quantization scheme that goes beyond language-level type information.
When the values don't fit: How we process signed int8 with unsigned ops
Full int8 vectors are still affected by this problem: Both operands can contain negative values, while vpdpbusd requires one operand to be unsigned.
Elasticsearch supports input vector data in byte format; for these datasets, we don’t control the input range, so we must support operands spanning the whole [-128, 127] range. Our first kernels used the naive widening path we described earlier: sign-extend bytes to 16-bit and multiply at double width. It's correct, but it halves throughput.
There is, however, a way to make vpdpbusd work on signed data. The key is an algebraic identity:
Adding 128 to every element of a shifts the range from [-128, 127] to [0, 255], allowing a to be supplied as the unsigned-byte operand that vpdpbusd expects. In practice, this shift can be implemented as a single XOR with 0x80 per register (flipping the sign bit is the same as adding 128 in two's complement). The price is a correction term, 128 * sum(b), that must be subtracted from the result. This technique is well-known in the deep-learning inference world: Intel's oneDNN library uses the same identity to handle signed activations with vpdpbusd.
The correction uses another instruction that exists for someone else's problem: vpsadbw computes the sum of absolute differences between unsigned bytes and was originally designed for motion estimation in video encoding. When one operand is a zero vector, those absolute differences reduce to the byte values themselves, so vpsadbw effectively computes partial sums of the bytes in b. Those partial sums can be accumulated into the correction term. An instruction designed for a completely different purpose turns out to be useful through a bit of algebraic reframing.
Here’s where the bulk scoring architecture from the previous post pays off again. If we treat b as our query vector, the correction term is a single scalar that depends only on the query, not on any document. In the bulk path, we can precompute the correction term before the scoring loop, and every document vector only needs XOR + vpdpbusd, with zero per-document correction overhead. The single-pair path, by contrast, has to compute the correction for every call, and the overhead eats the vpdpbusd speedup entirely.
We measured this honestly: JMH benchmarks run on AMD Turin (AWS c8a.xlarge, Zen 5 cores) showed a ~20% improvement for bulk scoring, but no advantage on single-pair. (Details are in the linked PR.) So simdvec uses both paths: vpdpbusd with the bias trick for bulk, the widening path for single-pair. We let benchmarks guide us, not the elegance of the tricks.
Three instructions are faster than one: How we compute Euclidean distance using dot products
This was supposed to be the easy one: The CPU already has a dedicated bf16 dot-product instruction. Unfortunately, there’s no such a thing as a “bf16 Euclidean distance instruction.”
BFloat16 (bf16) is becoming a popular format for vector embeddings: It covers the same range of magnitudes as float32 at reduced precision, halving the storage, which means half the memory bandwidth per vector. Hardware vendors have responded with dedicated instructions (vdpbf16ps on AVX-512 and bfdot on ARM Scalable Vector Extension [SVE]) that compute a bf16 dot product directly into 32-bit floating point accumulators. On AVX-512, this means processing 32 bf16 elements per 512-bit register with no conversion step.
At first glance, there seems to be no story here: For once, the instructions do exactly what we need. Indeed, the bf16 dot product kernels map directly onto these instructions. But Elasticsearch also needs squared Euclidean distance: |a − b|².
When we started work on AVX-512 bf16 support, the initial squared distance implementation followed the obvious path: Convert both bf16 vectors to float32, subtract, and square:
512-bit registers hold 32 bf16 values but only 16 float32 values. After conversion, every subsequent operation runs at half the element density. And the bf16_to_f32 conversion function uses integer ALU operations (zero-extend 16-bit to 32-bit, then shift left by 16). This means processing half elements (16) per step; furthermore, the conversion ops take execution resources away from the actual math (they compete for ALU ports; see “Ports, pipes, latency, throughput” in our previous post).
When the query is already stored as float32, this is the right path: The kernel must work at 32-bit width regardless. But when both vectors are bf16, we can do much better, using an algebraic equivalence.
Squared Euclidean distance expands as:
Each term is a dot product, which means every term maps directly onto the hardware primitive the CPU already accelerates (vdpbf16ps/bfdot). The new kernel uses three native bf16 dot products, needs no conversion, and operates at full 32-element register width:
We’re executing more arithmetic instructions, but each instruction operates on bf16 data at full density. The baseline executes fewer arithmetic instructions but operates at half width. Plus, the entire inner loop is pure floating-point: no integer ALU ops, which leads to less resource contention. The same identity works identically on ARM SVE with svbfdot_f32.
The cost depends on how expensive vdpbf16ps is on the target microarchitecture or, in other words, how much silicon the CPU vendors decided to invest in this instruction. On AMD Zen 5, vdpbf16ps is heavily optimized: Each instruction is a single micro-operation (uop) with a throughput of two instructions per cycle; three calls per step process 32 elements with 3 uops. In comparison, the conversion path processes 16 elements per step with a longer instruction chain (2 integer ops for each conversion, 1 subtract, 1 fused multiply-add [FMA]). This gives the three-dot-product path a 2.1–2.4x speedup over the pre-existing AVX2 implementation for bf16 Euclidean distance on that CPU.
On Intel Emerald Rapids, vdpbf16ps is 4 uops with a throughput of 0.5, or one instruction every two cycles. The advantage is smaller, but the dot-product formulation still wins, giving us a 1.3–1.4x speedup, because it preserves the bf16 density throughout the loop. All details and JMH benchmarks can be found in the linked PR.
Bulk scoring: Hoisting query-only terms out of the per-vector loop
As with int8 scoring, bf16 Euclidean distance also has a query-only term that can be precomputed once per query rather than once per document. If we treat b as our query vector, b·b depends only on the query, not on any document. The bulk kernel hoists b·b out of the per-document loop and accumulates it in a single shared stream, reducing the inner loop from three dot products per document to two (a·a and a·b).
The bulk bf16 Euclidean kernel delivers 1.25–1.8x over single-pair scoring. (As usual, all details and JMH benchmarks can be found in the linked PR.) Part of the advantage is due to the usual bulk benefits (better instruction-level parallelism and prefetch), but in our measurements, the hoisted b·b accounts for 10–20% of the gain, depending on the vector layout.
The road not taken: An alternative bf16 distance approach we tried (and discarded)
The three-dot-product decomposition is not the only way to express squared distance in terms of vdpbf16ps. We also explored another way: Interleave the two bf16 vectors into [a₀, b₀, a₁, b₁, ...] pairs using unpacklo/unpackhi, and then dot-product each pair against a constant vector [1, −1, 1, −1, ...]. The hardware computes aᵢ × 1 + bᵢ × (−1) = aᵢ − bᵢ, producing the element-wise difference directly in float32, so no conversion is needed. A follow-up FMA squares and accumulates the result.
It’s another inventive use of the same instruction: One approach decomposes squared distance into three dot products; the other repurposes dot-product to implement “bf16 subtraction”. Both avoid the bf16_to_f32 conversion entirely. On paper, the arithmetic of the interleaving path looks leaner, with one dpbf16 plus one FMA per step, versus three dpbf16 calls.
In practice, the shuffle instructions needed to interleave a and b added more overhead, and the resulting loop had fewer independent accumulators, limiting instruction-level parallelism. The three-dot-product version, with its clean load-compute-accumulate structure, was a clear winner in our benchmarks, so we reverted the experiment.
There was not one "obvious" approach and one "hack": Both were valid rewrites of the same identity. We explored approaches within the limits of what the hardware gave us and then measured: Intuition and reasoning about instruction counts are a starting point, not the final answer.
Dot product as bit logic: Binary vectors, AND, and SIMD popcount
In an ideal instruction set architecture, we would have a dedicated dot-product instruction for binary quantized vectors. Modern CPUs don’t provide one. Fortunately, once vectors are compressed to individual bits, the arithmetic itself starts to “disappear.”
All the rewrites so far dealt with full integers and floats. But Elasticsearch also supports binary quantized vectors (Better Binary Quantization [BBQ]), where each dimension is compressed to a single bit. At first glance, computing a dot product between a 1-bit document vector and a multi-bit query vector looks like it should require unpacking bits into integers, multiplying, and summing. However, since the values are restricted to 0 and 1, multiplication and addition collapse into much simpler operations: The product of two bits is their AND (both are 1 only when both inputs are 1), and the sum of those products is the number of 1-bits in the result, a population count.
Summing over all dimensions: dot(a, b) = popcount(a AND b). This identity isn’t new; it has been a staple of bit-manipulation algorithms for decades and is widely used in information retrieval, cryptography, and machine learning. The elegance is in how naturally it maps to hardware.
Computing binary vector dot products with AVX-512 popcount
A scalar popcnt instruction processes one 64-bit word at a time, or 64 binary dimensions per instruction. But AVX-512 processors with the VPOPCNTDQ extension can popcount eight 64-bit words in parallel in a single 512-bit register. Combined with a bitwise AND, the inner loop for a 1-bit document against one query bit plane becomes two instructions:
That computes one 512-dims binary dot-product chunk per iteration. A 4-bit query is taken as four separate bit planes, one per bit position. Each plane contributes a different weight (1, 2, 4, or 8), so a final step shifts and accumulates the popcounts to reconstruct the full dot product. The whole inner loop is a handful of instructions processing thousands of dimensions per pass.
Building a missing instruction: Synthesizing popcount on AVX2 hardware
VPOPCNTDQ is available on AVX-512 processors from Intel Ice Lake and AMD Zen 4 onwards. But simdvec also needs to run on older AVX2 hardware that has no vector popcount instruction at all. The solution comes from Muła, Kurz, and Lemire (2018): Use the vpshufb byte-shuffle instruction as a parallel 4-bit lookup table. The idea is to use a SIMD register as the lookup table for the popcount function: Precompute popcount for every possible 4-bit value (0 through 15), and store these 16 results in a SIMD register. Then, for each byte of input, split it into its two nibbles and use vpshufb to look up both counts simultaneously:
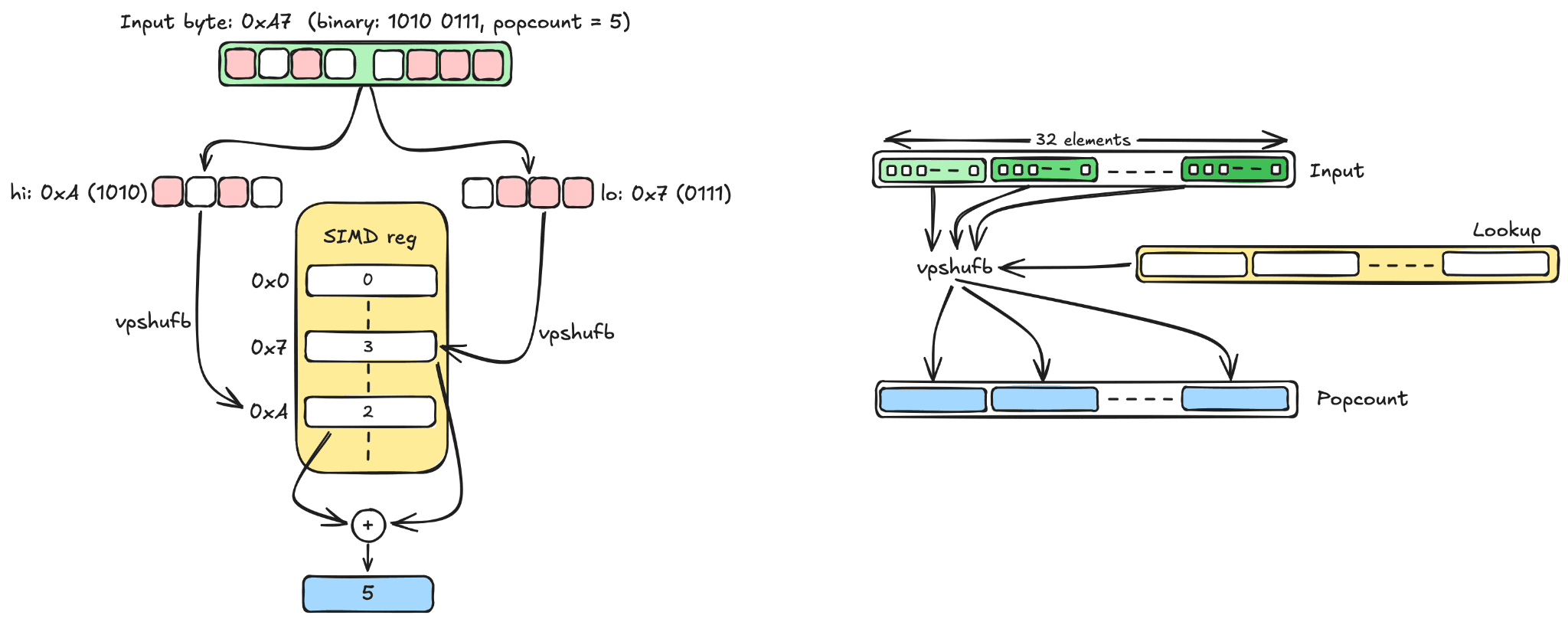
Since vpshufb performs 32 independent table lookups in parallel, two shuffles, two masks, and one add gives us the popcount of 32 bytes (256 binary dimensions) without a dedicated popcount instruction:
In this case, the instruction set architecture (ISA) didn’t offer the operation we needed, so we built it from what’s available. On AVX-512 with VPOPCNTDQ, the hardware provides the primitive directly; on AVX2, we can synthesize it from a byte-shuffle and a lookup table. Our native AVX2 implementation delivers ~4x over Java scalar scoring. Upgrading to AVX-512 with native VPOPCNTDQ adds another 1.3–2.1x on top, because a single instruction replaces the entire popcount sequence. (As usual, more details and JMH benchmarks can be found on the linked PRs.)
Single instruction, multiple vectors: Packing multiple document vectors into one SIMD register for low-dimension embeddings
With VPOPCNTDQ, each popcnt processes an entire 512-bit register, 512 binary dimensions at once. However, embedding models with 128 or 256 dimensions are very popular; at 1 bit per dimension, a 128-dimensional vector is just 16 bytes, a quarter of a 512-bit register. The standard loop loads one document vector per iteration, leaving three-quarters of the register unused.
Thanks to bulk processing, again, we can do better: If the vector is small enough, we can squeeze multiple document vectors into the same register. For example, at 128 dimensions (16 bytes), four document vectors fit in one 512-bit register. We broadcast the query bit plane four times into a register, and a single AND + POPCNT processes all four documents in one pass:
With one load, one AND and one POPCNT, we scored four documents. For 256-dimensional vectors (32 bytes each), we can fit two documents per register.
The JMH benchmarks tell an interesting story. On Intel Granite Rapids, this new kernel scales perfectly: 4.4x faster than AVX2 at 128 dimensions (3.88x compared to a single-vector implementation), and 2.4x at 256 (2.79x compared to a single-vector implementation). But on AMD Zen 5, gains are much more modest; we benchmarked different implementations, and we discovered that the multiple-vector implementation has no advantages over the single-vector one on this CPU.
This is only a theory, but it might be that Zen 5 implements VPOPCNTDQ internally using 128-bit uops, processing the 512-bit register in four sequential chunks. That would be consistent with our benchmarks: Packing four 128-bit vectors into one register doesn't help if the hardware processes each quarter separately. In any case, this is another example of different implementation choices to optimize silicon space.
At higher dimensions, both platforms benefit from AVX-512's wider registers regardless (the 1.3–2.1x gains we mentioned earlier).
A follow-up change extended the packed approach to non-power-of-2 dimensions (96, 192) via masked loads (expandloadu), bringing them to parity with 128 and 256.
Elasticsearch simdvec lessons: Fitting CPU instructions to vector search
In this post, we examined various optimizations: using int7 to fit unsigned*signed hardware, applying algebraic bias rewrites for signed int8, expressing Euclidean distance as three bf16 dot products, reworking binary vector dot product in terms of bit operations, synthesizing popcount from byte shuffles.
| Use case | Technique | Key instruction | Typical speedup |
|---|---|---|---|
| int7 vectors | 7-bit quantization fits unsigned×signed multiply-accumulate | `vpdpbusd` | ~6x vs. widening path |
| int8 vectors | Algebraic bias + precomputed correction term | `vpdpbusd` + `vpsadbw` | ~20% for bulk |
| bf16 vectors | Squared distance expanded into three dot products | `vdpbf16ps` / `bfdot` | 1.3–2.4x |
| Binary vectors | popcount(a AND b) via shuffle lookup table or via SIMD popcnt | `vpshufb` / `vpopcntd` | ~4x vs. scalar (AVX2); 1.3–2.1x more on AVX-512 |
Silicon space is scarce, so CPUs only accelerate a limited set of operations. Those operations are often designed for very different use cases: neural-network inference, video encoding, cryptography, or graphics. Every optimization in this post follows the same pattern: Start from the instructions the hardware executes efficiently, and then reformulate the computation so it can be expressed in terms of those instructions.
Pour aller plus loin

16 juillet 2026
A picture is worth 1.5x the words: What we learned benchmarking product search embeddings
We benchmarked two embedding models on 5,000 real products and found that combining image and text beats either alone by up to 50%. Here's the data and the model that won.

13 juillet 2026
The disk that never woke up: what actually decided our Qdrant vector search benchmark rematch
On the same hardware, Elasticsearch and Qdrant land in the same range at 56 QPS. The io_uring disk scorer and memory claims turned out to be the two things that mattered least.

21 juillet 2026
4 NVIDIA AI tasks, 1 Elasticsearch API: Embeddings, chat, completion, and rerank
Set up NVIDIA hosted models in Elasticsearch with one API key and a model ID. No custom integration code needed.

10 juillet 2026
How BBQ shrinks Jina v5 embeddings by 29x without losing recall in Elasticsearch
A hands-on test comparing BBQ and float32 vector indices in Elasticsearch, measuring memory, disk and recall@10 across five languages.

9 juillet 2026
Why Elasticsearch is becoming a columnar database
Elasticsearch is becoming a first-class columnar database. Columnar Mode ships in 9.5, storing data once alongside the existing modes and cutting storage footprints while speeding up analytical queries.