Souhaitez-vous recevoir une certification Elastic ? Découvrez quand se déroulera la prochaine formation Elasticsearch Engineer ! Vous pouvez lancer un essai gratuit sur le cloud ou essayer Elastic sur votre machine locale dès maintenant.
Soyez prêts :
Ce blog est différent des autres. Il ne s'agit pas d'une explication d'une nouvelle fonctionnalité ou d'un tutoriel. Il s'agit d'une simple ligne de code qui a pris trois jours à écrire. Nous allons corriger une corruption potentielle de l'index Apache Lucene. J'espère que vous en tirerez quelques enseignements :
- Tous les tests défectueux sont reproductibles, avec suffisamment de temps et les bons outils.
- Pour que les systèmes soient robustes, il faut qu'il y ait plusieurs niveaux de tests. Cependant, les niveaux de tests plus élevés deviennent de plus en plus difficiles à déboguer et à reproduire.
- Le sommeil est un excellent débogueur
Comment les tests d'Elasticsearch
Chez Elastic, nous avons une pléthore de tests qui s'exécutent sur la base de code Elasticsearch. Certains sont des tests fonctionnels simples et ciblés, d'autres sont des tests d'intégration "happy path" sur un seul nœud, et d'autres encore tentent de casser le cluster pour s'assurer que tout se comporte correctement dans un scénario de défaillance. Lorsqu'un test échoue continuellement, un ingénieur ou un outil d'automatisation crée un problème sur github et le signale à une équipe particulière pour qu'elle l'étudie. Ce bogue particulier a été découvert lors d'un test du dernier type. Ces tests sont délicats et ne peuvent parfois être répétés qu'après de nombreux essais.
Qu'est-ce que ce test teste réellement ?
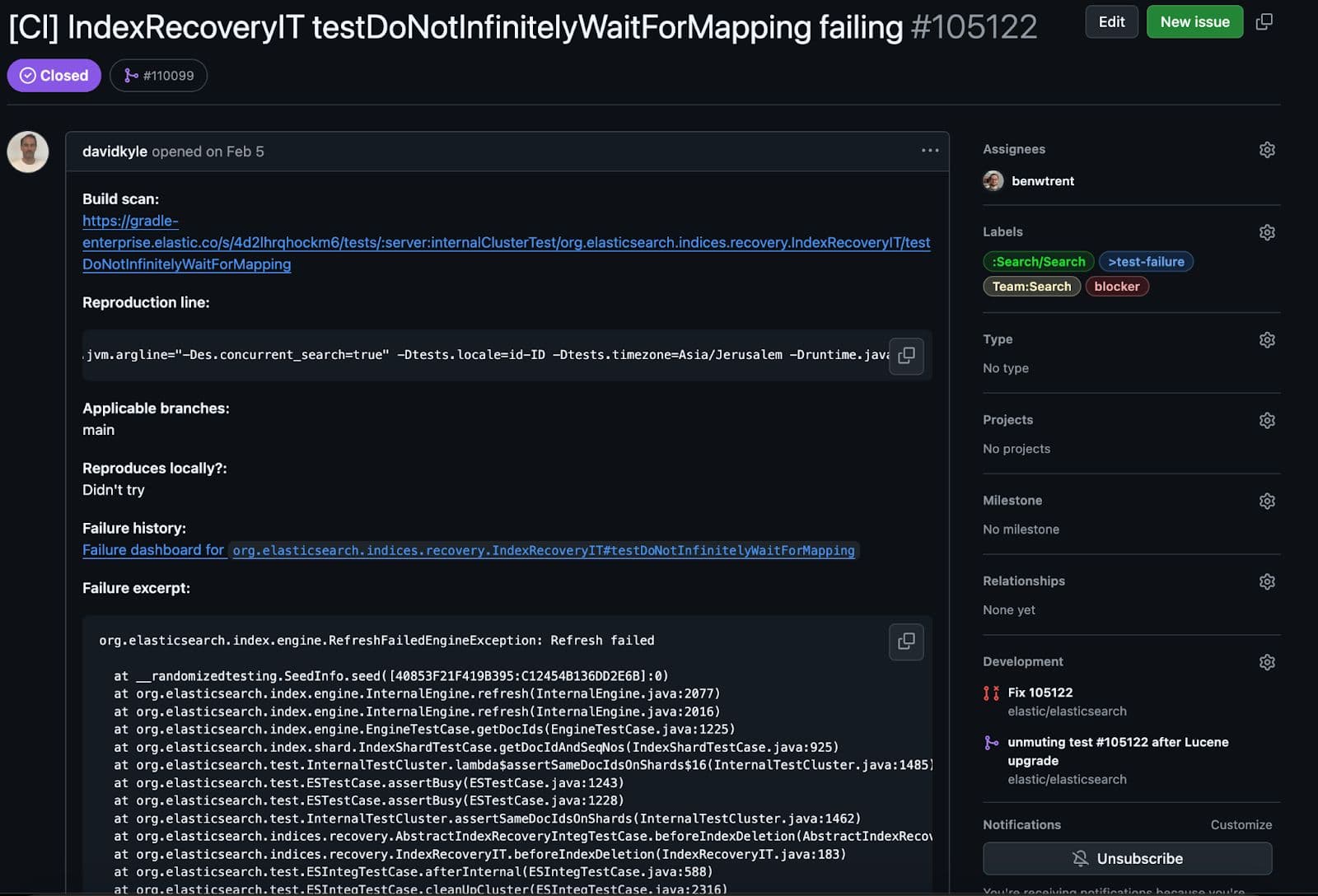
Ce test particulier est intéressant. Il créera un mappage particulier et l'appliquera à un groupe primaire. Ensuite, lors de la création d'une réplique. La principale différence est que lorsque la réplique tente d'analyser le document, le test injecte une exception, provoquant ainsi l'échec de la récupération d'une manière surprenante (mais attendue).
Tout fonctionnait comme prévu, à un détail près. Lors du nettoyage du test, nous avons validé la cohérence, et c'est là que ce test a rencontré un problème.
Ce test n'a pas donné les résultats escomptés. Lors du contrôle de cohérence, nous vérifions que tous les fichiers de segments Lucene répliqués et primaires sont cohérents. C'est-à-dire non corrompu et entièrement répliqué. Avoir des données partielles ou corrompues est bien pire que d'avoir une défaillance totale. Voici l'effrayante et abrégée trace de pile de l'échec.
D'une manière ou d'une autre, lors de l'échec de la réplication forcée, le shard répliqué a fini par être corrompu ! Permettez-moi d'expliquer la partie essentielle de l'erreur en termes simples.
Lucene est une architecture basée sur les segments, ce qui signifie que chaque segment connaît et gère ses propres fichiers en lecture seule. Ce segment particulier était validé par ses SegmentCoreReaders pour s'assurer que tout était en ordre. Chaque lecteur central contient des métadonnées qui indiquent quels types de champs et de fichiers existent pour un segment donné. Cependant, lors de la validation du Lucene90PointsFormat, certains fichiers attendus manquaient. Avec les segments du fichier _0.cfs, nous attendons un fichier en format point appelé kdi. cfs représente le système de fichiers composés "" dans lequel Lucene combinera parfois tous les types de champs et tous les petits fichiers en un seul fichier plus grand pour une réplication et une utilisation des ressources plus efficaces. En fait, les trois extensions de fichiers de points : kdd, kdi, et kdm manquaient. Comment pouvons-nous arriver au point où un segment Lucene s'attend à trouver un fichier de points mais où il n'y en a pas ! Cela ressemble à un bug de corruption effrayant !
La première étape de la correction d'un bogue est de le reproduire.
La reproduction de l'échec de ce bogue particulier a été extrêmement douloureuse. Bien que nous tirions parti des tests de valeurs aléatoires dans Elasticsearch, nous veillons à fournir à chaque défaillance une graine aléatoire (espérons-le) reproductible afin de garantir que toutes les défaillances peuvent être étudiées. Cela fonctionne très bien pour toutes les défaillances, sauf celles qui sont dues à une condition de course.
Peu importe le nombre de fois que j'ai essayé, la graine en question n'a jamais répété l'échec localement. Mais il existe des moyens d'exercer les tests et de tendre vers un échec plus reproductible.
Notre suite de tests particulière permet d'exécuter un test donné plus d'une fois dans la même commande via le paramètre -Dtests.iters. Mais ce n'était pas suffisant, je devais m'assurer que les fils d'exécution changeaient et augmentaient ainsi la probabilité que cette condition de course se produise. Un autre problème était que le test prenait tellement de temps à s'exécuter que le programme d'exécution du test se mettait en veilleuse. Finalement, j'ai utilisé le cauchemar bash suivant pour exécuter le test de manière répétée :
Le stress fait son apparition. Cela vous permet de lancer rapidement un processus qui mangera les cœurs de l'unité centrale pour le déjeuner. L'envoi aléatoire de spam stress-ng tout en exécutant de nombreuses itérations du test défaillant m'a finalement permis de reproduire l'échec. Un pas de plus. Pour stresser le système, il suffit d'ouvrir une autre fenêtre de terminal et d'exécuter :
Révéler le bogue
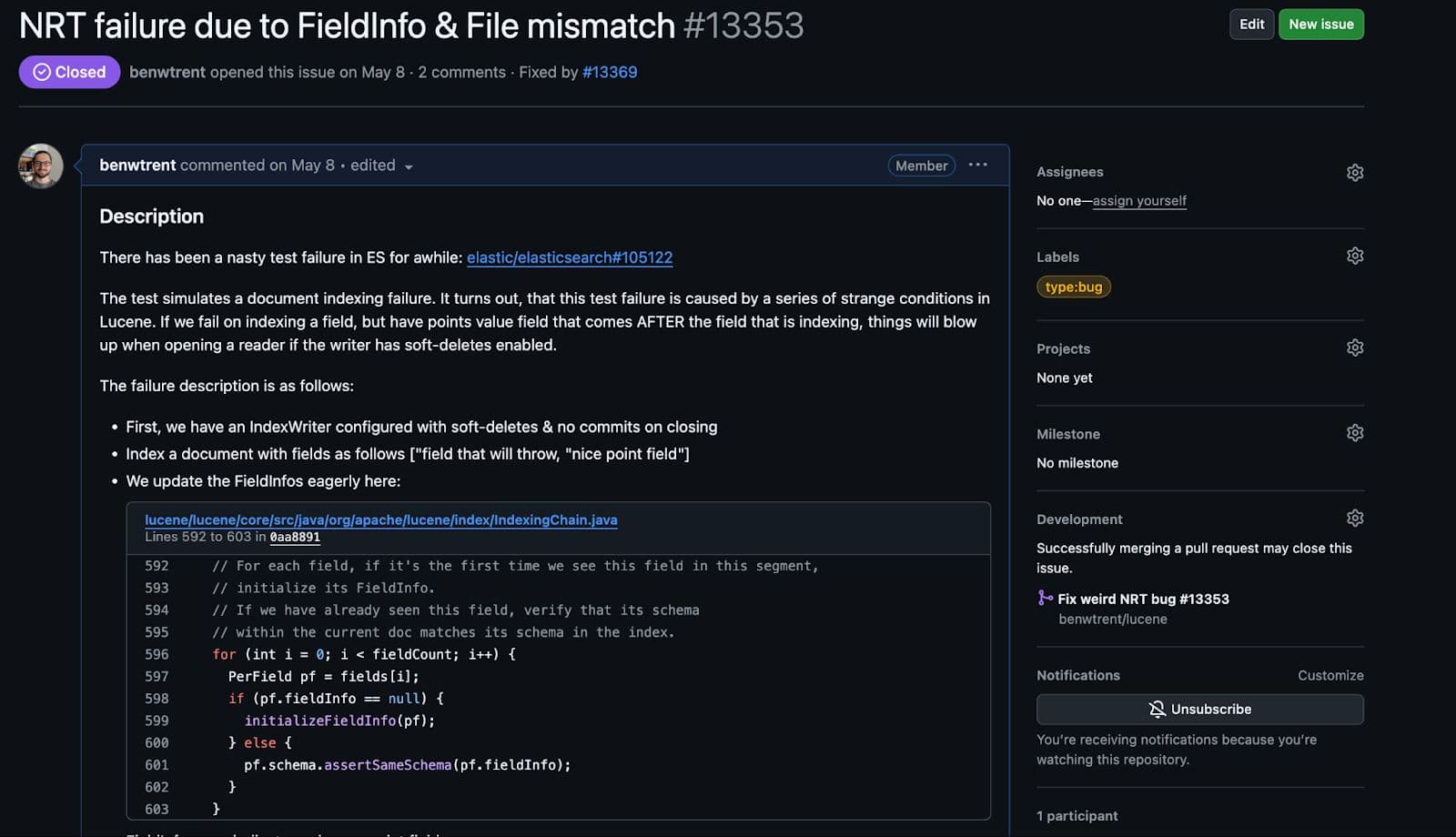
Maintenant que l'échec du test révélant le bogue est en grande partie reproductible, il est temps d'essayer d'en trouver la cause. Ce qui rend ce test particulier étrange, c'est que Lucene le lance parce qu'il attend des valeurs de point, mais qu'aucune n'est ajoutée directement par le test. Uniquement les valeurs textuelles. Cela m'a poussé à examiner les changements récents apportés à nos champs de contrôle optimiste de la concurrence: _seq_no et _primary_term. Ces deux éléments sont indexés en tant que points et existent dans chaque document Elasticsearch.
En effet, un commit a modifié notre mappeur _seq_no! OUI ! Cela doit être la cause ! Mais mon excitation a été de courte durée. Cela ne fait que modifier l'ordre dans lequel les champs sont ajoutés au document. Avant cette modification, les champs _seq_no étaient ajoutés en dernier au document. Ensuite, ils ont été ajoutés en premier. Il est impossible que l'ordre d'ajout des champs dans un document Lucene soit à l'origine de cet échec...
Oui, la modification de l'ordre d'ajout des champs est à l'origine de l'échec. Ceci était surprenant et s'avère être un bogue dans Lucene lui-même ! Le fait de modifier l'ordre dans lequel les champs sont analysés ne devrait pas modifier le comportement de l'analyse d'un document.
Le bogue dans Lucene
En effet, le bogue dans Lucene se concentre sur les conditions suivantes :
- Indexation d'un champ de valeurs de points (par ex.
_seq_no) - Essai d'indexation d'un champ de texte lancé lors de l'analyse
- Dans cet état étrange, nous ouvrons un lecteur en temps quasi réel de l'auteur qui fait l'expérience de l'exception d'analyse de l'index du texte.
Mais j'ai eu beau essayer, je n'ai pas réussi à le reproduire entièrement. J'ai directement ajouté des points de pause pour le débogage dans la base de code Lucene. J'ai tenté d'ouvrir des lecteurs de manière aléatoire pendant le parcours d'exception. J'ai même imprimé des mégaoctets et des mégaoctets de journaux en essayant de trouver le chemin exact où cette défaillance s'est produite. Je n'ai pas pu le faire. J'ai passé une journée entière à me battre et à perdre.
Puis j'ai dormi.
Le lendemain, j'ai relu la trace de pile originale et j'ai découvert la ligne suivante :
Dans toutes mes tentatives de recréation, je n'ai jamais défini spécifiquement la politique de fusion de la rétention. La politique SoftDeletesRetentionMergePolicy est utilisée par Elasticsearch pour répliquer avec précision les suppressions dans les répliques et garantir que tous nos contrôles de concurrence sont en charge du moment où les documents sont effectivement supprimés. Dans le cas contraire, Lucene a le contrôle total et les supprimera à chaque fusion.
Une fois que j'ai ajouté cette politique et que j'ai répliqué les étapes les plus élémentaires mentionnées ci-dessus, la panne s'est immédiatement répliquée.
Je n'ai jamais été aussi heureux d'ouvrir un bogue dans Lucene.
Alors qu'il se présentait comme une condition de course dans Elasticsearch, il était simple d'écrire un test échouant de manière répétée dans Lucene une fois que toutes les conditions étaient remplies.
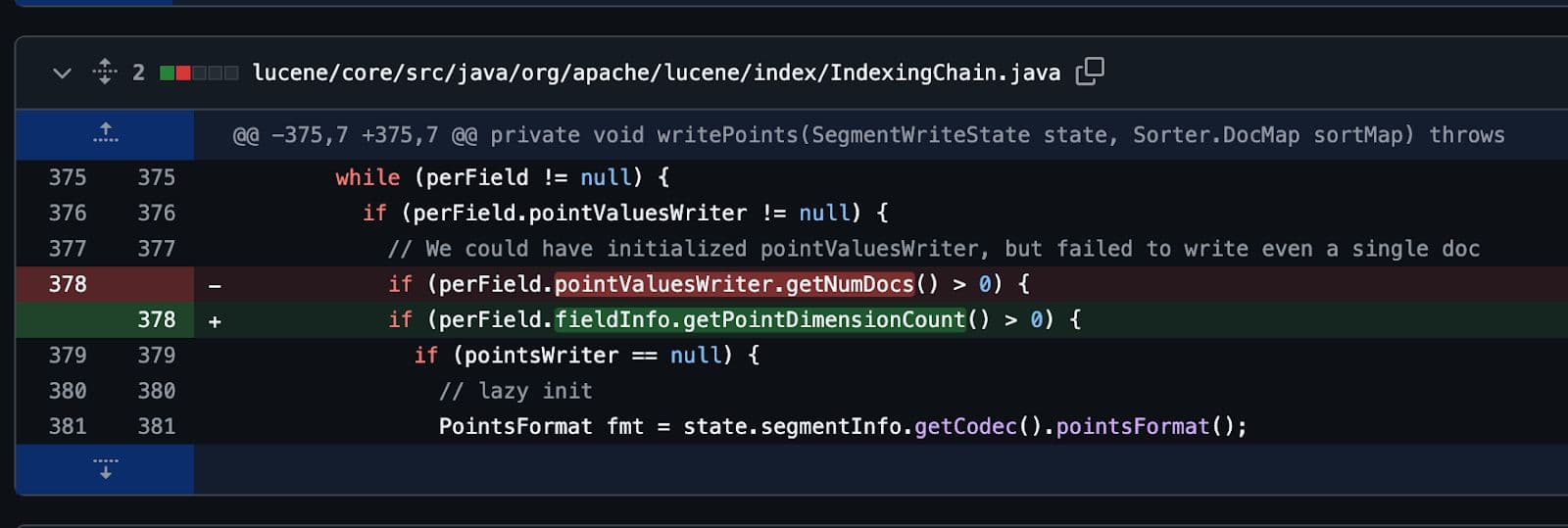
En fin de compte, comme tous les bons bogues, il a été corrigé avec une seule ligne de code. Plusieurs jours de travail pour une seule ligne de code.
Mais cela en valait la peine.
Pas la fin
J'espère que vous avez apprécié cette aventure avec moi ! Écrire des logiciels, en particulier des logiciels aussi répandus et complexes qu'Elasticsearch et Apache Lucene, est gratifiant. Cependant, il est parfois exceptionnellement frustrant. J'aime et je déteste à la fois les logiciels. La correction des bogues n'est jamais terminée !
Pour aller plus loin

3 septembre 2025
Filtrage de la recherche vectorielle : Garder la pertinence
Il ne suffit pas d'effectuer une recherche vectorielle pour trouver les résultats les plus similaires à une requête. Le filtrage est souvent nécessaire pour réduire les résultats de la recherche. Cet article explique comment fonctionne le filtrage pour la recherche vectorielle dans Elasticsearch et Apache Lucene.

7 avril 2025
Accélérer la fusion des graphiques de HNSW
Explorez le travail que nous avons effectué pour réduire la charge de travail liée à la construction de plusieurs graphes HNSW, en particulier en réduisant le coût de la fusion des graphes.

7 février 2025
Bugs de concurrence dans Lucene : Comment corriger les échecs de concurrence optimiste
Grâce à Fray, un cadre de test de concurrence déterministe du PASTA Lab de CMU, nous avons découvert un bogue Lucene délicat et l'avons éliminé.

3 janvier 2025
Lucene Wrapped 2024
2024 a été une autre année importante pour Apache Lucene. Dans ce blog, nous examinerons les points essentiels.

26 juin 2024
Elasticsearch et OpenSearch : comparatif de performance pour la recherche vectorielle.
Elasticsearch est d’emblée 2 à 12 fois plus rapide qu’OpenSearch pour la recherche vectorielle