Comme tout le monde ces jours-ci, ici à Elastic, nous nous lançons à fond dans le Chat, les agents et le RAG. Dans le département Search, nous avons récemment travaillé sur un Agent Builder et un Tool Registry, dans le but de rendre trivial le "chat" avec vos données dans Elasticsearch.
Lisez le blog Building AI Agentic Workflows with Elasticsearch pour en savoir plus sur la "vue d'ensemble" de cet effort, ou Your First Elastic Agent : From a Single Query to an AI-Powered Chat pour une introduction plus pratique.
Dans ce blog, nous allons nous intéresser à l'une des premières choses qui se produisent lorsque vous commencez à discuter et vous présenter quelques-unes des améliorations récentes que nous avons apportées.
Que se passe-t-il ici ?

Lorsque vous discutez avec vos données Elasticsearch, notre agent IA par défaut suit ce flux standard :
- Inspecter l'invite.
- Identifiez l'index susceptible de contenir les réponses à cette question.
- Générer une requête pour cet index, sur la base de l'invite.
- Effectuez une recherche dans cet index avec cette requête.
- Synthétiser les résultats.
- Les résultats peuvent-ils répondre à l'invitation ? Si oui, répondez. Si ce n'est pas le cas, répétez l'opération, mais essayez quelque chose de différent.
Cela ne devrait pas sembler trop nouveau - il s'agit simplement de Retrieval Augmented Generation (RAG). Et comme on peut s'y attendre, la qualité de vos réponses dépend fortement de la pertinence de vos premiers résultats de recherche. En travaillant à l'amélioration de la qualité de nos réponses, nous avons donc accordé une attention toute particulière aux requêtes générées à l'étape 3 et exécutées à l'étape 4. Et nous avons remarqué une tendance intéressante.
Souvent, lorsque nos premières réponses étaient "mauvaises", ce n'était pas parce que nous avions lancé une mauvaise requête. C'est parce que nous avions choisi le mauvais index à interroger. Les étapes 3 et 4 ne nous posaient généralement pas de problème - c'était l'étape 2.
Que faisions-nous ?
Notre mise en œuvre initiale était simple. Nous avions construit un outil (appelé index_explorer) qui faisait effectivement un _cat/indices pour lister tous les indices disponibles, puis demandait au LLM d'identifier lequel de ces indices correspondait le mieux au message/à la question/à l'invitation de l'utilisateur. Vous pouvez voir cette mise en œuvre originale ici.
Dans quelle mesure cela a-t-il fonctionné ? Nous n'étions pas sûrs ! Nous avions des exemples clairs de dysfonctionnements, mais notre premier défi était de quantifier notre situation actuelle.
Établir une base de référence
Cela commence par des données
Nous avions besoin d'un ensemble de données en or pour mesurer l'efficacité d'un outil à sélectionner le bon indice à partir d'une demande de l'utilisateur et d'un ensemble préexistant d'indices. Comme nous ne disposions pas d'un tel ensemble de données, nous en avons créé un.
Reconnaissance : Il ne s'agit pas d'une "meilleure pratique", nous le savons. Mais parfois, il est préférable d'aller de l'avant plutôt que de faire du surplace. Le progrès, la perfection SIMPLE.
Nous avons généré des indices de semences pour plusieurs domaines différents à l'aide de cette invite. Ensuite, pour chaque domaine généré, nous avons généré quelques indices supplémentaires en utilisant cette invite (l'objectif étant ici de semer la confusion pour le LLM avec des négatifs durs et des exemples difficiles à classer). Ensuite, nous avons édité manuellement chaque index généré et ses descriptions. Enfin, nous avons généré des requêtes de test à l'aide de cette invite, ce qui nous a permis d'obtenir des échantillons de données tels que les suivants :

et des cas de test tels que :
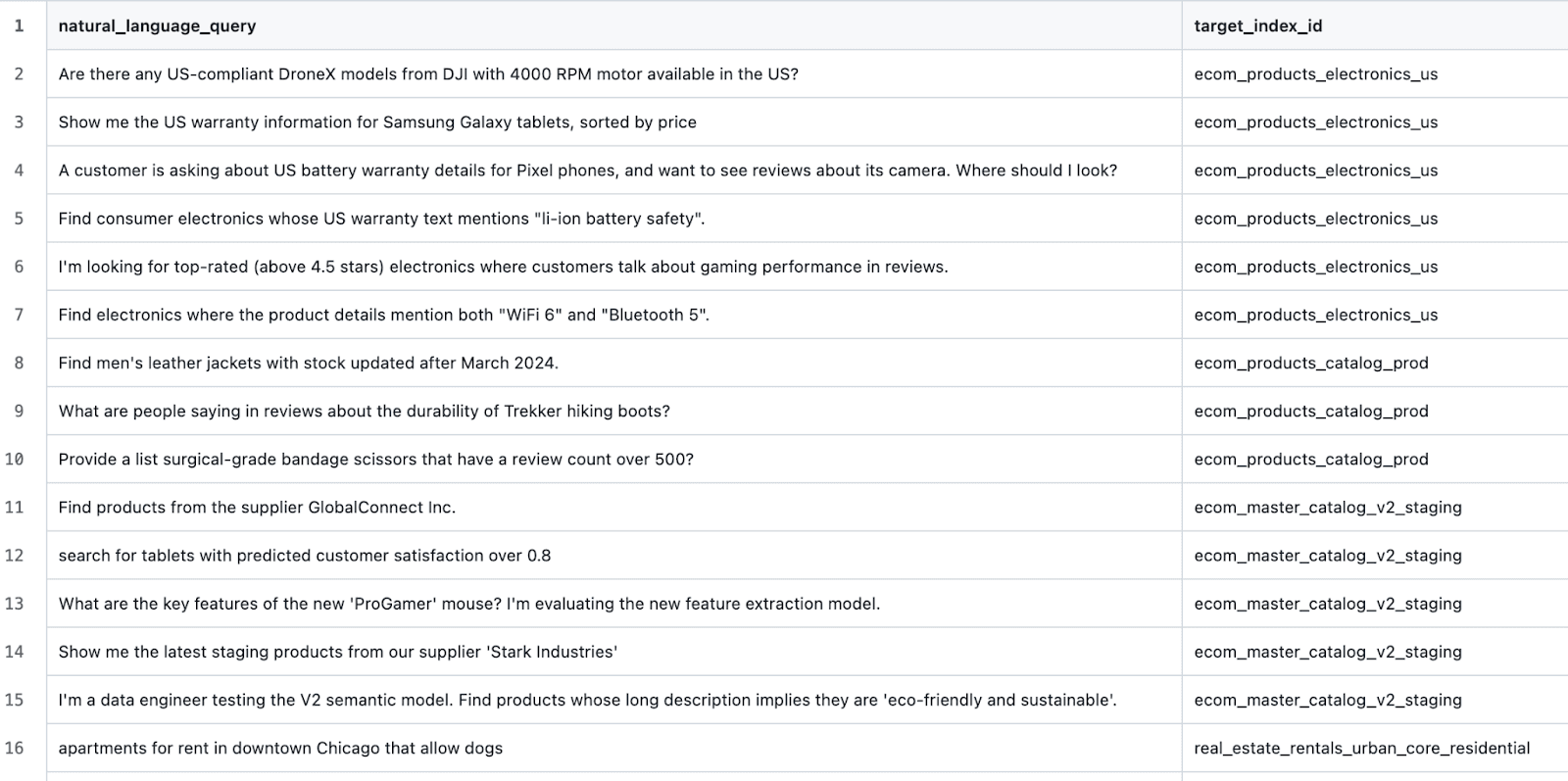
Élaboration d'un harnais de test
À partir de là, la procédure a été très simple. Script up a tool that could :
- Faire table rase du passé avec un cluster Elasticsearch cible.
- Créer tous les indices définis dans le jeu de données cible.
- Pour chaque scénario de test, exécutez l'outil i
ndex_explorer(nous disposons d'une API pour l'exécution de l'outil). - Comparez l'indice du résultat à l'indice attendu et saisissez le résultat.
- Une fois tous les scénarios de test terminés, les résultats sont présentés sous forme de tableau.
L'enquête dit...
Les premiers résultats ont été, sans surprise, médiocres.
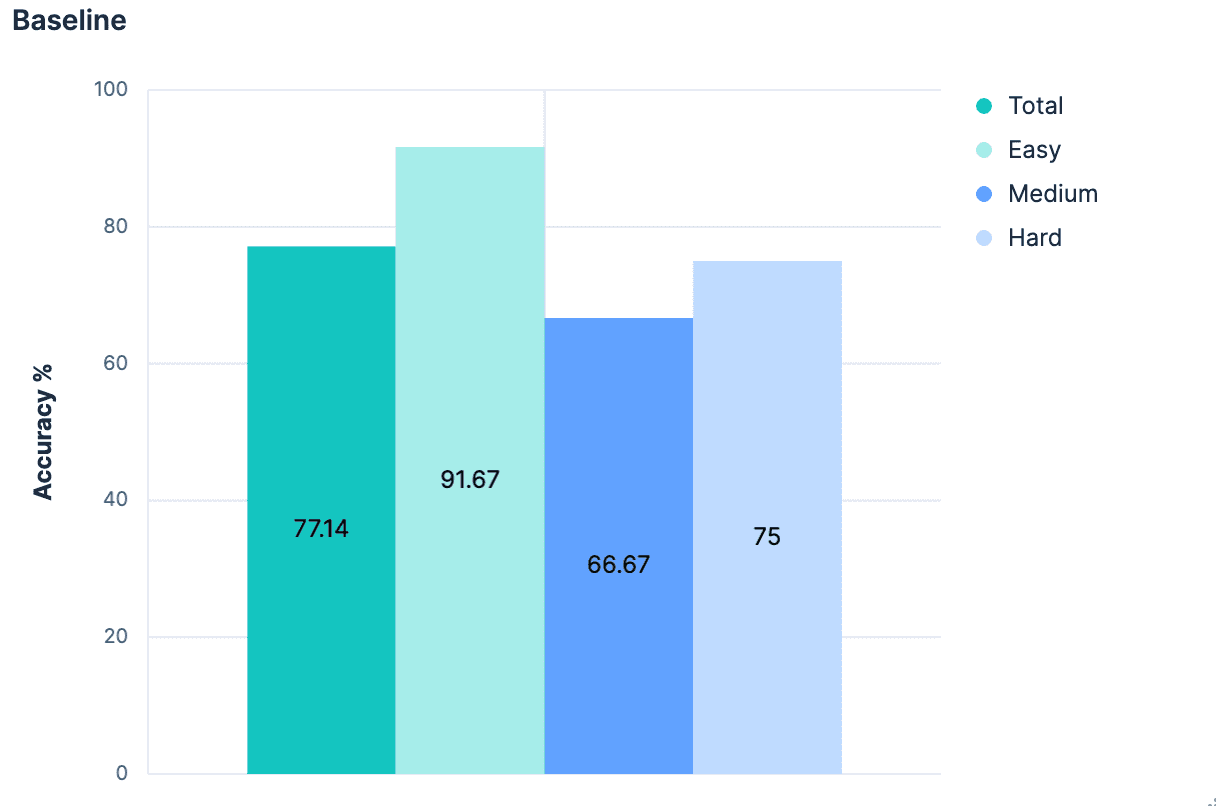
Dans l'ensemble, 77,14% ont identifié avec précision le bon indice. Et ce, dans le meilleur des cas, c'est-à-dire lorsque tous les indices ont des noms appropriés et sémantiquement significatifs. Quiconque a déjà fait un `PUT test2/_doc/foo {...}` sait que vos index n'ont pas toujours des noms significatifs.
Nous disposons donc d'une base de référence, qui montre qu'il y a beaucoup de place pour l'amélioration. Il était temps de faire de la science ! 🧪
Expérimentation
Hypothèse 1 : Les cartographies aideront à
L'objectif est ici d'identifier un index qui contiendra des données pertinentes pour le message original. La partie d'un index qui décrit le mieux les données qu'il contient est le mappage de l'index. Même sans saisir d'échantillons du contenu de l'index, le fait de savoir que l'index possède un champ prix de type double implique que les données représentent quelque chose à vendre. Un champ auteur de type texte implique des données linguistiques non structurées. L'association des deux pourrait impliquer que les données sont des livres, des histoires ou des poèmes. De nombreux indices sémantiques peuvent être déduits de la seule connaissance des propriétés d'un index. Dans une branche locale, j'ai donc ajusté notre `.index_explorer` pour envoyer les mappings complets d'un index (ainsi que son nom) au LLM afin qu'il prenne sa décision.
Le résultat (à partir des journaux Kibana) :
Les premiers auteurs de l'outil l'avaient prévu. Si le mappage d'un index est une mine d'or d'informations, c'est aussi un bloc de JSON assez verbeux. Et dans un scénario réaliste où vous comparez de nombreux indices (notre ensemble de données d'évaluation en définit 20), ces blobs JSON s'accumulent. Nous voulons donc donner au LLM plus de contexte pour sa décision que de simples noms d'index pour toutes les options, mais pas autant que les mappings complets de chacune d'entre elles.
Hypothèse 2 : des correspondances "aplaties" (listes de champs) en guise de compromis
Nous sommes partis de l'hypothèse que les créateurs d'index utiliseront des noms d'index sémantiquement significatifs. Et si nous étendions cette hypothèse aux noms des champs ? Notre expérience précédente a échoué parce que le mappage de JSON comprend BEAUCOUP de métadonnées et d'éléments parasites.
Le bloc ci-dessus, par exemple, compte 236 caractères et définit un seul champ dans une correspondance Elasticsearch. Alors que la chaîne "description_text" ne comporte que 16 caractères. Le nombre de caractères a été multiplié par près de 15, sans amélioration sémantique significative de la description de ce que ce champ implique à propos des données disponibles. Que se passerait-il si nous récupérions les correspondances pour tous les indices, mais qu'avant de les envoyer au LLM, nous les "aplatissions" en une simple liste de noms de champs ?
Nous avons essayé.

C'est formidable ! Des améliorations dans tous les domaines. Mais pourrions-nous faire mieux ?
Hypothèse 3 : Descriptions dans le mapping _meta
Si le simple fait de nommer les champs sans contexte supplémentaire a provoqué un tel saut, on peut supposer que l'ajout d'un contexte substantiel serait encore plus efficace ! Il n'est pas nécessairement conventionnel que chaque index soit accompagné d'une description, mais il est possible d'ajouter des métadonnées de tout type au niveau de l'index à l'objet _meta de la cartographie. Nous avons repris les index générés et ajouté des descriptions pour chaque index de notre ensemble de données. Tant que les descriptions ne sont pas trop longues, elles devraient utiliser moins de tokens que la cartographie complète et fournir de bien meilleures indications sur les données incluses dans l'index. Notre expérience a validé cette hypothèse.
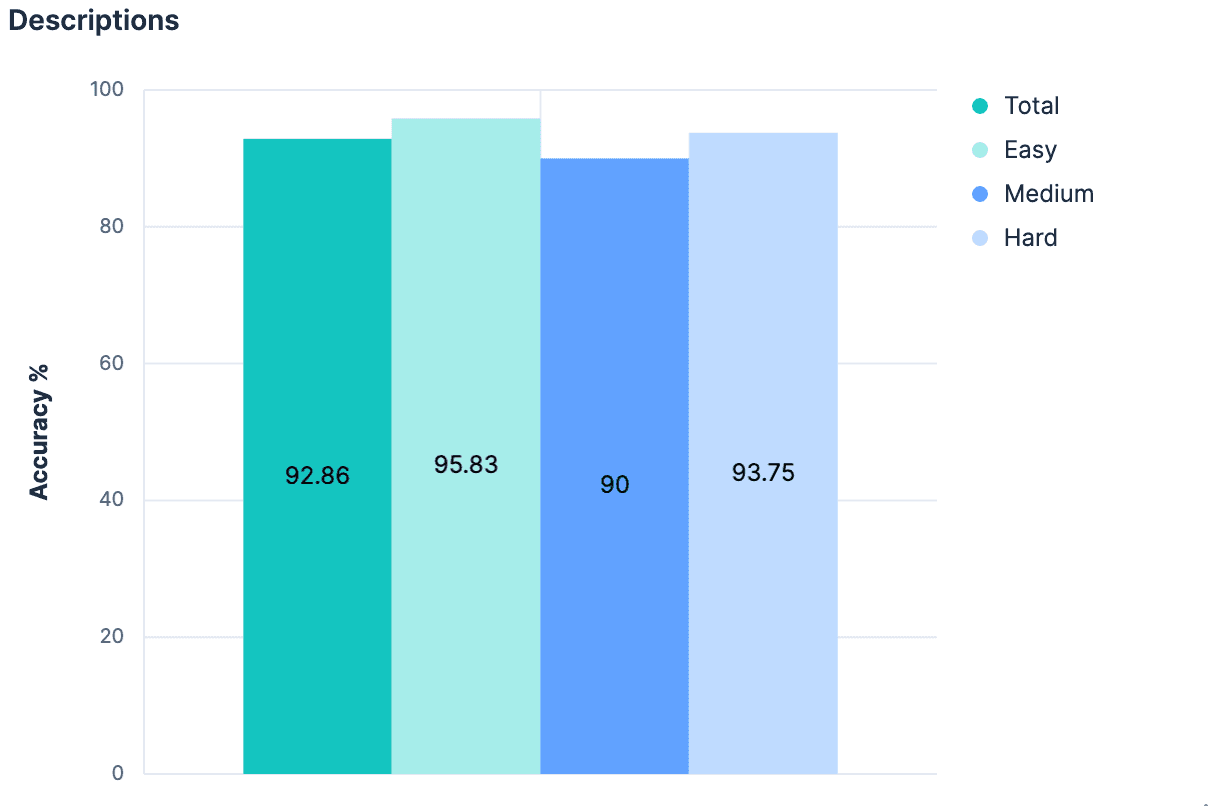
Une amélioration modeste, et nous sommes maintenant >90% précis dans tous les domaines.
Hypothèse 4 : La somme est plus grande que les parties
Les noms de champs ont permis d'améliorer nos résultats. Les descriptions ont permis d'accroître nos résultats. L'utilisation des descriptions ET des noms de champs devrait donc permettre d'obtenir de meilleurs résultats, n'est-ce pas ?
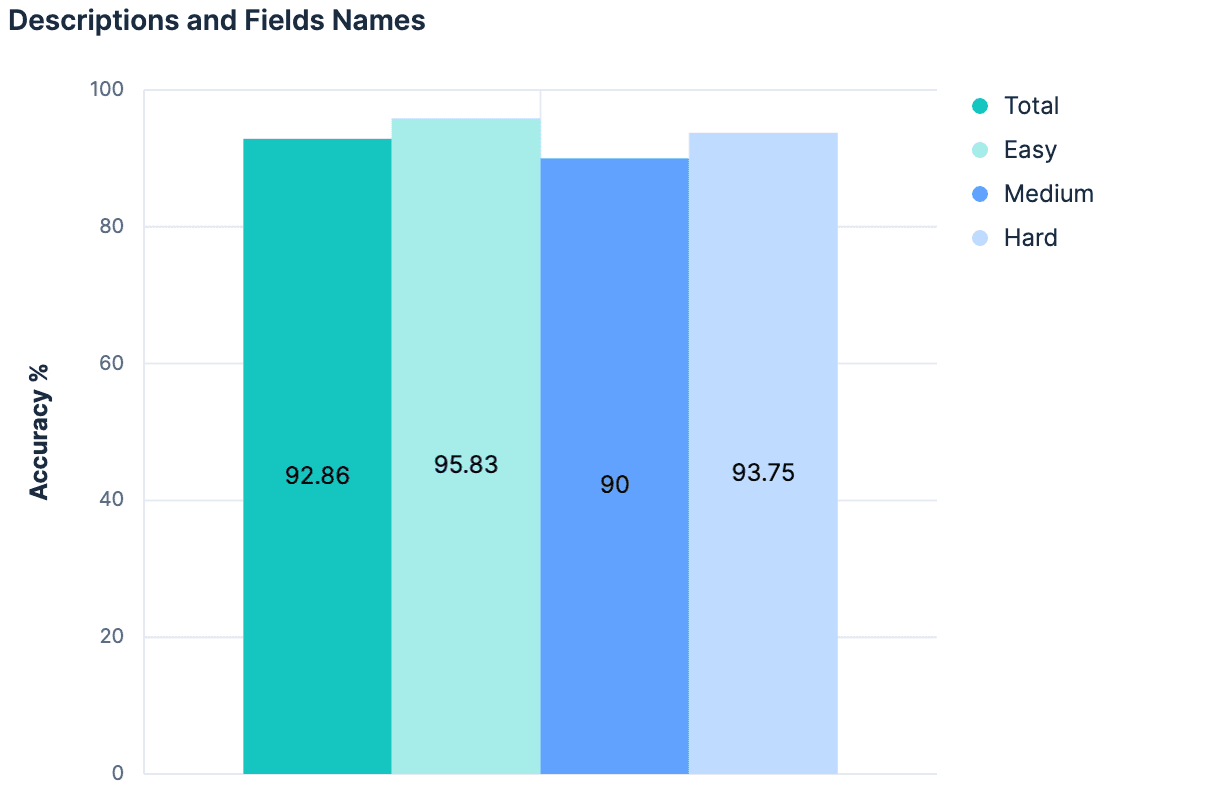
Les données ont répondu "non" (pas de changement par rapport à l'expérience précédente). La théorie principale était que, puisque les descriptions ont été générées à partir des champs/mappings de l'index, il n'y a pas assez d'informations différentes entre ces deux éléments de contexte pour ajouter quelque chose de "nouveau" lorsqu'on les combine. En outre, la charge utile que nous envoyons pour nos 20 indices de test devient assez importante. Le raisonnement que nous avons suivi jusqu'à présent n'est pas extensible. En fait, il y a de bonnes raisons de croire qu'aucune des expériences que nous avons menées jusqu'à présent ne fonctionnerait sur des clusters Elasticsearch où il y a des centaines ou des milliers d'indices à choisir. Toute approche qui augmente linéairement la taille du message envoyé au LLM à mesure que le nombre total d'indices augmente n'est probablement pas une stratégie généralisable.
Ce dont nous avons vraiment besoin, c'est d'une approche qui nous aide à réduire un grand nombre de candidats aux options les plus pertinentes...
Il s'agit d'un problème de recherche.
Hypothèse 5 : Sélection par recherche sémantique
Si le nom d'un index a une signification sémantique, il peut être stocké sous forme de vecteur et faire l'objet d'une recherche sémantique.
Si les noms des champs d'un index ont une signification sémantique, ils peuvent être stockés sous forme de vecteurs et faire l'objet d'une recherche sémantique.
Si un index possède une description ayant une signification sémantique, il peut lui aussi être stocké sous forme de vecteur et faire l'objet d'une recherche sémantique.
Aujourd'hui, les index Elasticsearch ne rendent aucune de ces informations consultables (peut-être devrions-nous le faire !), mais il était assez simple de bricoler quelque chose qui pouvait combler cette lacune. En utilisant le cadre de connecteur d'Elastic, j'ai construit un connecteur qui produirait un document pour chaque index dans un cluster. Les documents de sortie ressembleraient à quelque chose comme :
J'ai envoyé ces documents vers un nouvel index où j'ai défini manuellement le mappage :
Cela crée un champ unique semantic_content, dans lequel tous les autres champs ayant une signification sémantique sont regroupés et indexés. La recherche dans cet index devient triviale, avec simplement :
L'outil index_explorer modifié est maintenant beaucoup plus rapide, car il n'a pas besoin de faire une demande à un LLM, mais peut demander un seul encastrement pour la requête donnée et effectuer une opération de recherche vectorielle efficace. En prenant le premier hit comme index sélectionné, nous avons obtenu les résultats suivants :

Cette approche est évolutive. Cette approche est efficace. Mais cette approche est à peine meilleure que notre ligne de base. Ce n'est pas surprenant, car l'approche de la recherche est incroyablement naïve. Il n'y a aucune nuance. Aucune reconnaissance du fait que le nom et la description d'un index devraient avoir plus de poids qu'un nom de champ arbitraire que l'index contient. Pas de possibilité de pondérer les correspondances lexicales exactes par rapport aux correspondances synonymes. Cependant, la construction d'une requête très nuancée nécessiterait de supposer BEAUCOUP de choses sur les données disponibles. Jusqu'à présent, nous avons déjà fait des hypothèses importantes sur la signification sémantique des noms d'index et de champs, mais nous devrions aller plus loin et commencer à supposer la signification qu 'ils ont et la manière dont ils sont liés les uns aux autres. Sans cela, nous ne pouvons probablement pas identifier de manière fiable la meilleure correspondance comme premier résultat, mais nous pouvons plus probablement dire que la meilleure correspondance se trouve quelque part dans les N premiers résultats. Nous avons besoin de quelque chose qui puisse consommer des informations sémantiques dans le contexte dans lequel elles existent, en les comparant à celles d'une autre entité qui peut se représenter d'une manière sémantiquement distincte, et juger entre elles. Comme un LLM.
Hypothèse 6 : Réduction du nombre de candidats
Il y a eu bien d'autres expériences que je vais passer sous silence, mais la principale avancée a été d'abandonner le désir de choisir la meilleure correspondance uniquement à partir d'une recherche sémantique, et d'utiliser plutôt la recherche sémantique comme un filtre pour éliminer les indices non pertinents de la considération du LLM. Nous avons combiné la recherche linéaire, la recherche hybride avec RRF et semantic_text pour notre recherche, en limitant les résultats aux 5 premiers indices correspondants.
Ensuite, pour chaque correspondance, nous avons ajouté le nom de l'index, la description et les noms des champs à un message pour le LLM. Les résultats ont été fantastiques :
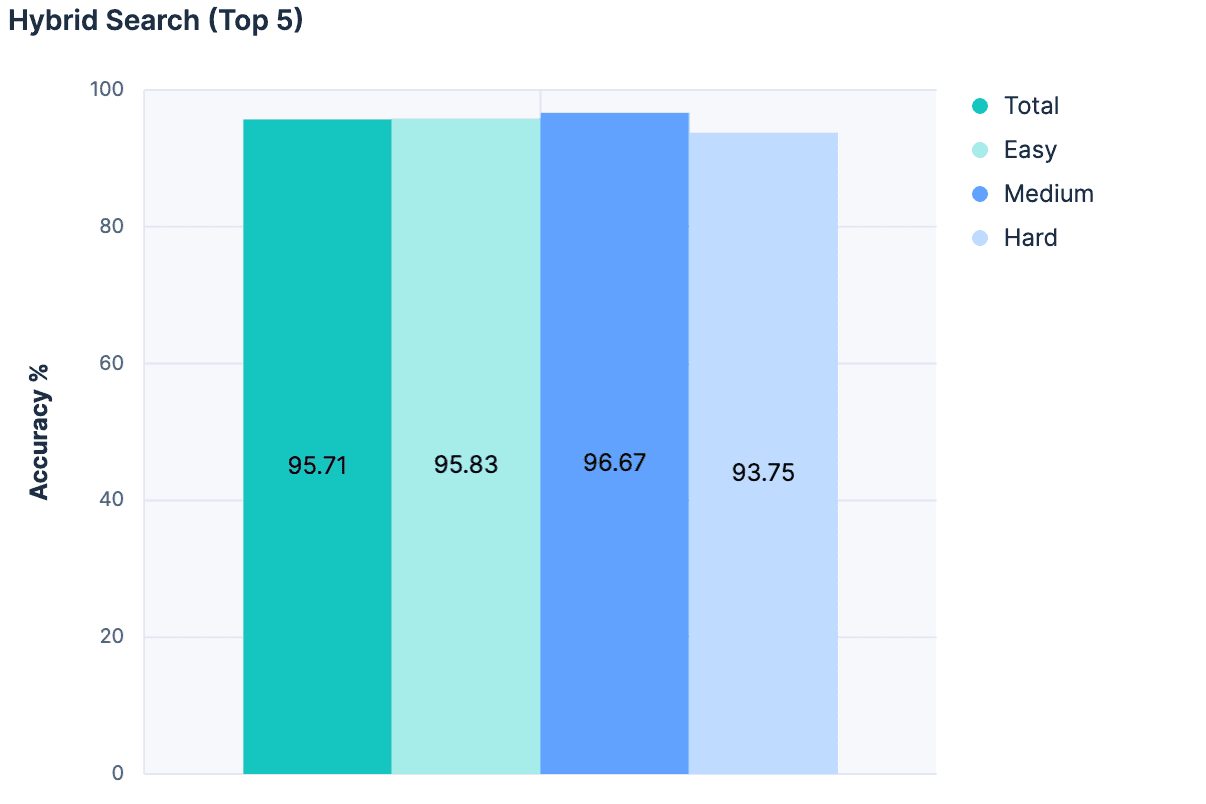
La plus grande précision de toutes les expériences réalisées à ce jour ! Et comme cette approche n'augmente pas la taille du message proportionnellement au nombre total d'indices, elle est beaucoup plus évolutive.
Résultats
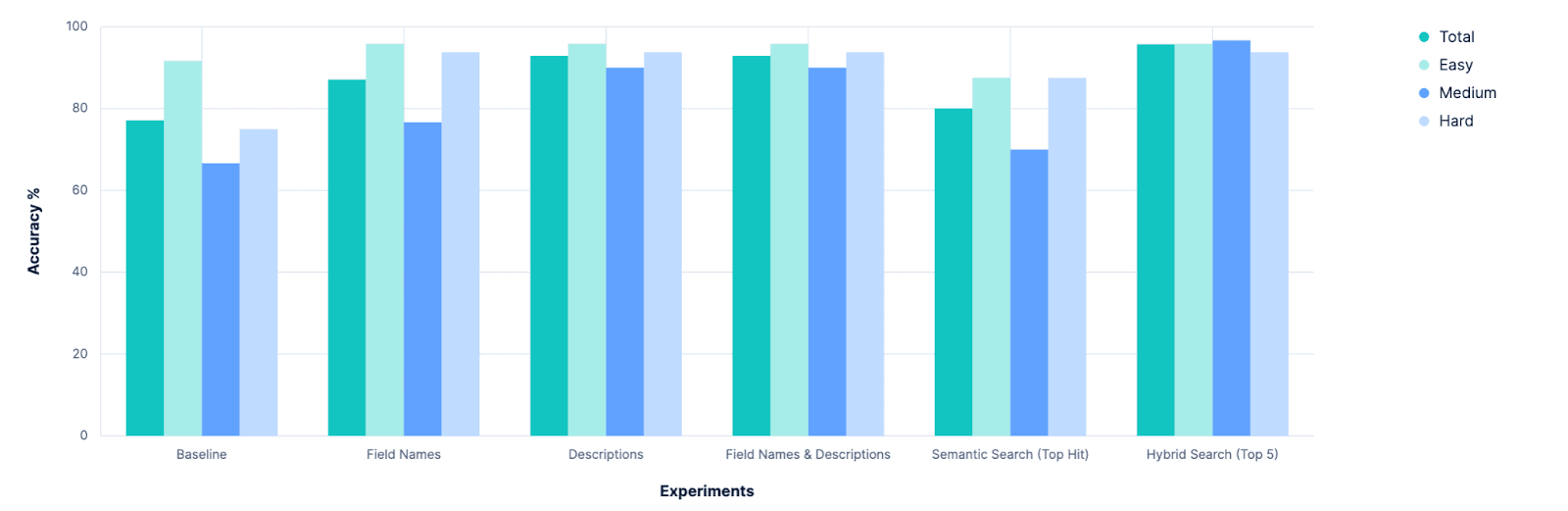
Le premier résultat clair est que notre base de référence peut être améliorée. Cela semble évident rétrospectivement, mais avant le début de l'expérimentation, des discussions sérieuses ont eu lieu sur la question de savoir si nous devions abandonner complètement notre outil index_explorer et nous fier à la configuration explicite de l'utilisateur pour limiter l'espace de recherche. Bien que cela reste une option viable et valable, cette recherche montre qu'il existe des voies prometteuses vers l'automatisation de la sélection de l'indice lorsque les données de l'utilisateur ne sont pas disponibles.
Le résultat suivant a été que le simple fait d'ajouter des caractères de description au problème a un rendement décroissant. Avant cette recherche, nous nous demandions si nous devions investir dans l'extension de la capacité d'Elasticsearch à stocker des métadonnées au niveau des champs. Aujourd'hui, ces valeurs meta sont plafonnées à 50 caractères, et l'on a supposé qu'il faudrait augmenter cette valeur pour pouvoir obtenir une compréhension sémantique de nos champs. Ce n'est manifestement pas le cas, et le LLM semble s'en sortir assez bien avec des noms de domaines. Nous pourrons approfondir cette question ultérieurement, mais elle ne nous semble plus urgente.
Inversement, cela a clairement démontré l'importance d'avoir des métadonnées d'index "consultables". Pour ces expériences, nous avons piraté un index des indices. Mais c'est quelque chose que nous pourrions étudier en l'intégrant directement dans Elasticsearch, en créant des API pour le gérer, ou au moins en établissant une convention à ce sujet. Nous allons évaluer nos options et en discuter en interne, alors restez à l'écoute.
Enfin, cet effort a confirmé l'intérêt de prendre le temps d'expérimenter et de prendre des décisions fondées sur des données. En fait, cela nous a aidés à réaffirmer que notre produit Agent Builder aura besoin de capacités d'évaluation robustes et intégrées au produit. Si nous devons créer un ensemble de tests uniquement pour un outil qui prélève des indices, nos clients auront absolument besoin de moyens pour évaluer qualitativement leurs outils personnalisés au fur et à mesure qu'ils procèdent à des ajustements itératifs.
Je suis impatient de voir ce que nous allons construire, et j'espère que vous l'êtes aussi !
Pour aller plus loin

23 avril 2026
Comment nous avons construit Elasticsearch simdvec pour faire de la recherche vectorielle l'une des plus rapides au monde
Comment nous avons conçu Elasticsearch simdvec, la bibliothèque de noyaux SIMD optimisée manuellement qui alimente chaque requête de recherche vectorielle dans Elasticsearch.

4 mai 2026
Comment mesurer et améliorer le rappel de recherche Elasticsearch : de 0,43 à 0,75 avec la recherche hybride
Découvrez comment mesurer et améliorer le rappel de recherche dans Elasticsearch en combinant la recherche lexicale BM25 avec les embeddings vectoriels de Jina AI, en utilisant l’API rank_eval pour valider l’amélioration avec des données chiffrées.

8 avril 2026
Comment créer des applications d'IA agentique avec Mastra et Elasticsearch
Découvrez comment créer des applications d'IA agentiques avec Mastra et Elasticsearch à travers un exemple pratique.

25 mars 2026
L'outil shell n'est pas une solution miracle pour l'ingénierie du contexte
Découvrez quels outils de récupération de contexte existent pour l'ingénierie contextuelle, comment ils fonctionnent et leurs compromis.

26 mars 2026
Annonce des autorisations en lecture seule pour les tableaux de bord Kibana
Présentation des tableaux de bord en lecture seule dans Kibana, offrant aux créateurs de tableaux de bord des contrôles de partage détaillés pour garantir l'exactitude des résultats et les protéger contre les modifications indésirables.