De la recherche vectorielle aux API REST puissantes, Elasticsearch met à disposition des développeurs la boîte à outils de recherche la plus complète. Explorez nos notebooks d’exemple dans le dépôt Elasticsearch Labs pour tester de nouvelles approches. Vous pouvez également démarrer un essai gratuit ou exécuter Elasticsearch en local dès aujourd’hui.
Voici la première partie de notre exploration des techniques avancées de RAG. Cliquez ici pour la deuxième partie !
L'article récent intitulé Searching for Best Practices in Retrieval-Augmented Generation évalue de manière empirique l'efficacité de diverses techniques d'amélioration des RAG, dans le but de converger vers un ensemble de meilleures pratiques pour les RAG.

Le pipeline RAG recommandé par Wang et ses collègues.
Nous mettrons en œuvre quelques-unes des meilleures pratiques proposées, notamment celles qui visent à améliorer la qualité de la recherche (Sentence Chunking, HyDE, Reverse Packing).
Par souci de concision, nous omettons les techniques axées sur l'amélioration de l'efficacité (classification des requêtes et résumé).
Nous mettrons également en œuvre quelques techniques qui n'ont pas été abordées, mais que je trouve personnellement utiles et intéressantes (Metadata Inclusion, Composite Multi-Field Embeddings, Query Enrichment).
Enfin, nous effectuerons un petit test pour voir si la qualité de nos résultats de recherche et des réponses générées s'est améliorée par rapport à la base de référence. C'est parti !
Vue d'ensemble du RAG
RAG vise à améliorer les LLM en récupérant des informations dans des bases de connaissances externes afin d'enrichir les réponses générées. En fournissant des informations spécifiques au domaine, les LLM peuvent être rapidement adaptés à des cas d'utilisation qui sortent du cadre de leurs données de formation ; cela coûte beaucoup moins cher qu'un réglage fin et il est plus facile de les tenir à jour.
Les mesures visant à améliorer la qualité du RAG se concentrent généralement sur deux axes :
- Améliorer la qualité et la clarté de la base de connaissances.
- Améliorer la couverture et la spécificité des requêtes de recherche.
Ces deux mesures permettront d'améliorer les chances que le LLM ait accès à des faits et des informations pertinents, et qu'il soit donc moins susceptible d'halluciner ou de s'appuyer sur ses propres connaissances - qui peuvent être dépassées ou non pertinentes.
La diversité des méthodes est difficile à expliquer en quelques phrases. Pour plus de clarté, passons directement à la mise en œuvre.
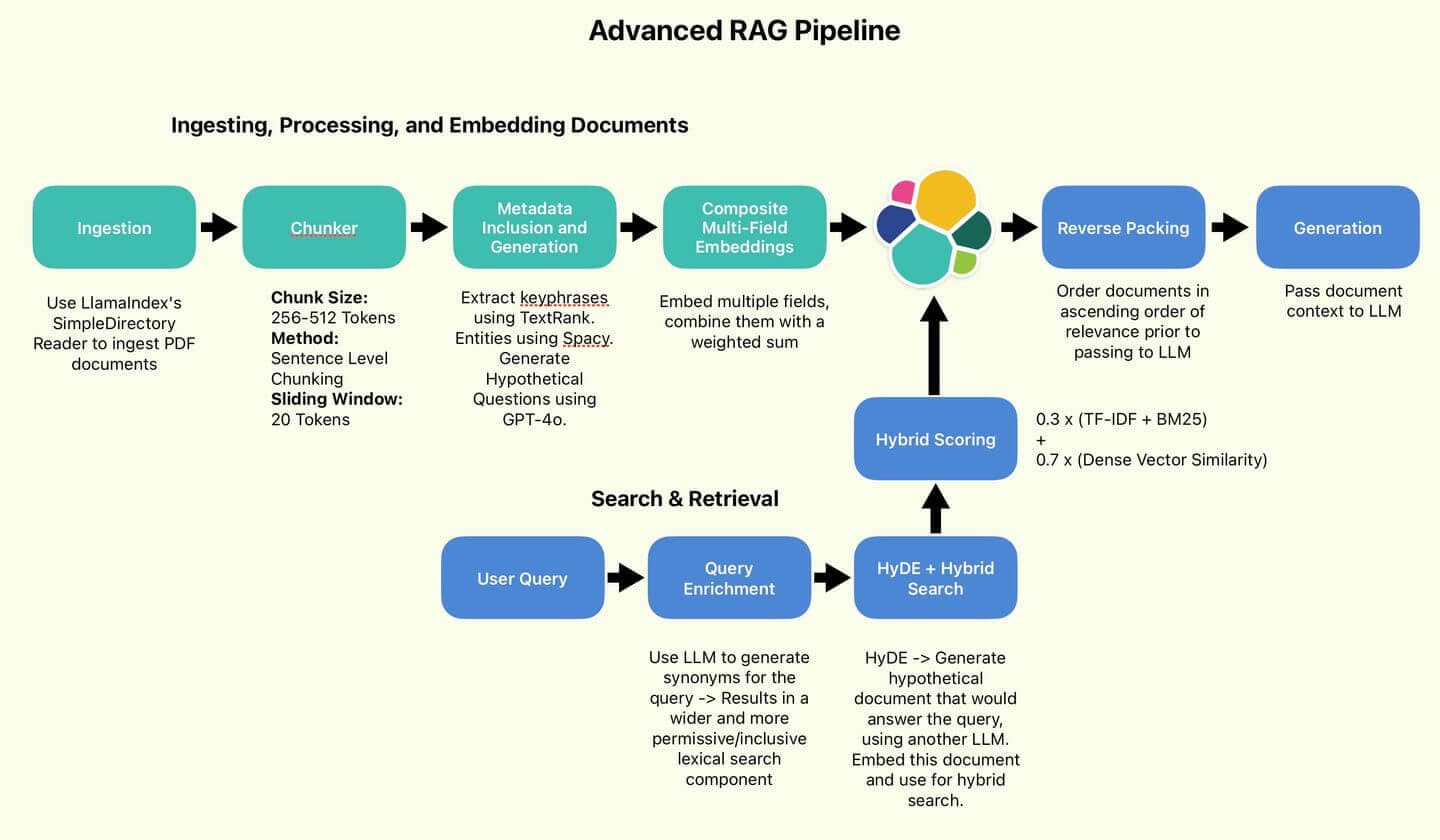
Figure 1 : Le pipeline RAG utilisé par l'auteur.
Table des matières
Mise en place
Tout le code peut être trouvé dans le repo de Searchlabs.
Commençons par le commencement. Vous aurez besoin des éléments suivants :
- Déploiement d'un nuage élastique
- Une API LLM - Nous utilisons un déploiement GPT-4o sur Azure OpenAI dans ce carnet.
- Python version 3.12.4 ou ultérieure
Nous allons exécuter tout le code du cahier main.ipynb.
Allez-y et clonez git le repo, naviguez vers supporting-blog-content/advanced-rag-techniques, puis exécutez les commandes suivantes :
Une fois que c'est fait, créez un fichier .env et remplissez les champs suivants (référencés dans l'exemple .env). Remerciements à mon co-auteur, Claude-3.5, pour ses commentaires utiles.
Ensuite, nous allons choisir le document à ingérer et le placer dans le dossier documents. Pour cet article, nous utiliserons le rapport annuel 2023 d'Elastic N.V. Il s'agit d'un document assez difficile et dense, parfait pour tester nos techniques RAG.

Rapport annuel d'Elastic 2023
Maintenant que tout est prêt, passons à l'ingestion. Ouvrez main.ipynb et exécutez les deux premières cellules pour importer tous les paquets et initialiser tous les services.
Acquisition, traitement et intégration de documents
Ingestion des données
- Note personnelle : je suis stupéfait par la commodité de LlamaIndex. Avant les LLM et LlamaIndex, l'ingestion de documents de différents formats était un processus pénible de collecte de paquets ésotériques provenant d'un peu partout. Aujourd'hui, il se réduit à un seul appel de fonction. Sauvage.
La commande SimpleDirectoryReader chargera chaque document contenu dans les fichiers directory_path. et .pdf. Elle renvoie une liste d'objets document, que je convertis en dictionnaires Python parce que je trouve qu'ils sont plus faciles à manipuler.
Chaque dictionnaire contient le contenu clé du champ text. Il contient également des métadonnées utiles telles que le numéro de page, le nom du fichier, sa taille et son type.
Chunking au niveau de la phrase, par jetons
La première chose à faire est de réduire nos documents en morceaux d'une longueur standard (pour assurer la cohérence et la maniabilité). Les modèles d'intégration ont des limites de jetons uniques (taille d'entrée maximale qu'ils peuvent traiter). Les jetons sont les unités de base du texte que les modèles traitent. Pour éviter la perte d'informations (tronquage ou omission de contenu), nous devrions fournir un texte qui ne dépasse pas ces limites (en divisant les textes plus longs en segments plus petits).
Le découpage a un impact significatif sur les performances. Idéalement, chaque morceau devrait représenter un élément d'information autonome, capturant des informations contextuelles sur un seul sujet. Les méthodes de découpage comprennent le découpage au niveau des mots, où les documents sont divisés en fonction du nombre de mots, et le découpage sémantique qui utilise un LLM pour identifier les points de rupture logiques.
Le découpage au niveau des mots est bon marché, rapide et facile, mais il risque de diviser les phrases et donc de briser le contexte. Le découpage sémantique devient lent et coûteux, surtout s'il s'agit de documents tels que le rapport annuel Elastic de 116 pages.
Choisissons une approche intermédiaire. Le découpage en phrases est encore simple, mais il permet de préserver le contexte plus efficacement que le découpage en mots, tout en étant nettement moins coûteux et plus rapide. En outre, nous mettrons en œuvre une fenêtre coulissante pour capturer une partie du contexte environnant et atténuer l'impact du découpage des paragraphes.
La classe Chunker utilise le tokenizer du modèle d'intégration pour encoder et décoder le texte. Nous allons maintenant construire des blocs de 512 jetons chacun, avec un chevauchement de 20 jetons. Pour ce faire, nous divisons le texte en phrases, nous tokenisons ces phrases, puis nous ajoutons les phrases tokenisées à notre morceau actuel jusqu'à ce que nous ne puissions plus en ajouter sans dépasser notre limite de tokens.
Enfin, nous décodons les phrases pour les ramener au texte d'origine afin de les intégrer, en les stockant dans un champ appelé original_text. Les morceaux sont stockés dans un champ appelé chunk. Pour réduire le bruit (c'est-à-dire les documents inutiles), nous éliminons tous les documents dont la longueur est inférieure à 50 tokens.
Passons-le en revue nos documents :
Et vous obtenez des morceaux de texte qui ressemblent à ceci :
Inclusion et génération de métadonnées
Nous avons découpé nos documents en morceaux. Il est maintenant temps d'enrichir les données. Je souhaite générer ou extraire des métadonnées supplémentaires. Ces métadonnées supplémentaires peuvent être utilisées pour influencer et améliorer les performances de recherche.
Nous allons définir une classe DocumentEnricher, dont le rôle est de recevoir une liste de documents (dictionnaires Python) et une liste de fonctions du processeur. Ces fonctions s'exécutent sur la colonne original_text des documents et stockent leurs résultats dans de nouveaux champs.
Tout d'abord, nous extrayons les phrases clés à l'aide de TextRank. TextRank est un algorithme basé sur un graphe qui permet d'extraire des phrases et des expressions clés d'un texte en classant leur importance sur la base des relations entre les mots.
Ensuite, nous allons générer des questions potentielles à l'aide de GPT-4o.
Enfin, nous extrairons les entités à l'aide de Spacy.
Le code de chacun d'entre eux étant assez long et complexe, je m'abstiendrai de le reproduire ici. Si vous êtes intéressé, les fichiers sont indiqués dans les exemples de code ci-dessous.
Lançons l'enrichissement des données :
Et regardez les résultats :
Phrases clés extraites par TextRank
Ces phrases clés sont des substituts des thèmes centraux de la rubrique. Si une requête a trait à la cybersécurité, le score de ce morceau sera augmenté.
Questions potentielles générées par le GPT-4o
Ces questions potentielles peuvent correspondre directement aux requêtes des utilisateurs, ce qui permet d'améliorer le score. Nous demandons à GPT-4o de générer des questions auxquelles il est possible de répondre en utilisant les informations trouvées dans le morceau actuel.
Entités extraites par Spacy
Ces entités ont un objectif similaire à celui des phrases clés, mais elles capturent les noms des organisations et des individus, ce que l'extraction des phrases clés peut ne pas faire.
Enchâssement composite de champs multiples
Maintenant que nous avons enrichi nos documents avec des métadonnées supplémentaires, nous pouvons exploiter ces informations pour créer des encastrements plus robustes et tenant compte du contexte.
Faisons le point sur l'état actuel du processus. Nous avons quatre champs d'intérêt dans chaque document.
Chaque champ représente une perspective différente sur le contexte du document, mettant potentiellement en évidence un domaine clé sur lequel le LLM devrait se concentrer.

Pipeline d'enrichissement des métadonnées
Il s'agit d'intégrer chacun de ces champs, puis de créer une somme pondérée des intégrations, appelée intégration composite.
Avec un peu de chance, cette intégration composite permettra au système de mieux tenir compte du contexte, tout en introduisant un autre hyperparamètre réglable pour contrôler le comportement de recherche.
Tout d'abord, intégrons chaque champ et mettons à jour chaque document en place, en utilisant notre modèle d'intégration défini localement et importé au début du bloc-notes main.ipynb.
Chaque fonction d'intégration renvoie le champ de l'intégration, qui est simplement le champ d'entrée original avec un postfixe _embedding.
Définissons maintenant les pondérations de notre encastrement composite :
Les pondérations vous permettent d'attribuer des priorités à chaque composant, en fonction de votre cas d'utilisation et de la qualité de vos données. Intuitivement, la taille de ces pondérations dépend de la valeur sémantique de chaque composant. Étant donné que le morceau de texte lui-même est de loin le plus riche, je lui attribue une pondération de 70%. Les entités étant les plus petites, puisqu'il s'agit simplement d'une liste de noms d'organisations ou de personnes, je leur attribue une pondération de 5%. Le réglage précis de ces valeurs doit être déterminé de manière empirique, au cas par cas.
Enfin, écrivons une fonction pour appliquer les pondérations et créer notre intégration composite. Pour gagner de la place, nous supprimerons également tous les composants intégrés.
Nous avons ainsi terminé le traitement des documents. Nous disposons à présent d'une liste d'objets documents qui se présente comme suit :
Indexation vers Elastic
Chargeons nos documents en vrac dans Elastic Search. À cette fin, j'ai défini il y a longtemps un ensemble de fonctions Elastic Helper dans elastic_helpers.py. Il s'agit d'un code très long, nous allons donc nous contenter d'examiner les appels de fonction.
es_bulk_indexer.bulk_upload_documents fonctionne avec n'importe quelle liste d'objets dictionnaires, en tirant parti des mappages dynamiques pratiques d'Elasticsearch.
Rendez-vous sur Kibana et vérifiez que tous les documents ont été indexés. Il devrait y en avoir 224. Pas mal pour un document aussi volumineux !
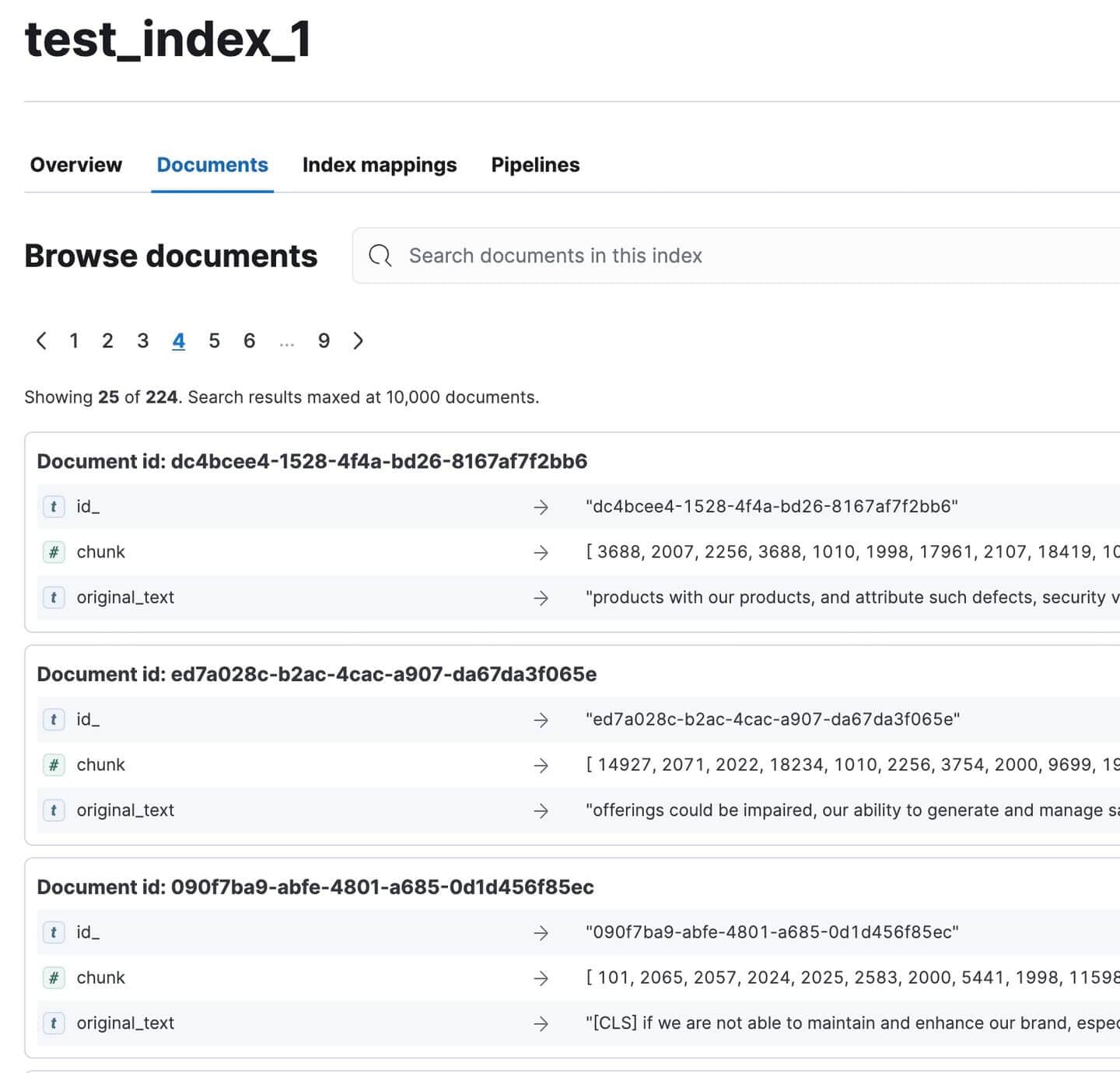
Documents du rapport annuel indexés dans Kibana
Pause-catalogues
Faisons une pause, l'article est un peu lourd, je sais. Jetez un coup d'œil à mon chat :

Regardez comme elle est furieuse
Adorable. Le chapeau a disparu et je soupçonne à moitié qu'elle l'a volé et caché quelque part :(
Félicitations pour avoir réussi à aller aussi loin :)
Rejoignez-moi dans la deuxième partie pour tester et évaluer notre pipeline RAG !
Annexe
Définitions
1. Découpage des phrases
- Technique de prétraitement utilisée dans les systèmes RAG pour diviser le texte en unités plus petites et significatives.
- Processus :
- Entrée : Grand bloc de texte (par exemple, document, paragraphe)
- Sortie : Segments de texte plus petits (généralement des phrases ou des petits groupes de phrases)
- Objet :
- Création de segments de texte granulaires et spécifiques au contexte
- Permet une indexation et une recherche plus précises
- Améliore la pertinence des informations recherchées dans les systèmes RAG
- Caractéristiques :
- Les segments sont sémantiquement significatifs
- Peuvent être indexés et récupérés de manière indépendante
- Souvent, le contexte est préservé afin de garantir la compréhensibilité autonome.
- Avantages :
- Améliore la précision de la recherche
- Permet une augmentation plus ciblée des pipelines RAG
2. HyDE (Hypothetical Document Embedding)
- Une technique qui utilise un LLM pour générer un document hypothétique pour l'expansion des requêtes dans les systèmes RAG.
- Processus :
- Requête d'entrée à un LLM
- LLM génère un document hypothétique répondant à la requête
- Intégrer le document généré
- Utiliser l'intégration pour la recherche vectorielle
- Différence essentielle :
- RAG traditionnel : Correspondance entre la requête et les documents
- HyDE : fait correspondre des documents à d'autres documents
- Objet :
- Améliorer les performances de recherche, en particulier pour les requêtes complexes ou ambiguës
- Saisir un contexte sémantique plus riche qu'une requête courte
- Avantages :
- Exploite les connaissances du LLM pour élargir les requêtes
- Peut potentiellement améliorer la pertinence des documents retrouvés
- Défis :
- Nécessite une inférence LLM supplémentaire, ce qui augmente le temps de latence et le coût.
- La performance dépend de la qualité du document hypothétique généré
3. Emballage inversé
- Technique utilisée dans les systèmes RAG pour réorganiser les résultats de la recherche avant de les transmettre au LLM.
- Processus :
- Le moteur de recherche (par exemple, Elasticsearch) renvoie les documents par ordre décroissant de pertinence.
- L'ordre est inversé, le document le plus pertinent étant placé en dernier.
- Objet :
- Exploite le biais de récence des LLM, qui ont tendance à se concentrer sur les informations les plus récentes dans leur contexte.
- Veille à ce que les informations les plus pertinentes soient "les plus récentes" dans la fenêtre contextuelle du LLM.
- Exemple : Ordre original : [Plus pertinent, Deuxième plus important, Troisième plus important, ...] Ordre inversé : [..., Troisième plus important, Deuxième plus important, Plus important]
4. Classification des requêtes
- Technique permettant d'optimiser l'efficacité du système RAG en déterminant si une requête nécessite un RAG ou si elle peut être traitée directement par le LLM.
- Processus :
- Développer un ensemble de données personnalisé spécifique au programme d'éducation et de formation tout au long de la vie utilisé
- Former un modèle de classification spécialisé
- Utiliser le modèle pour catégoriser les requêtes entrantes
- Objet :
- Améliorer l'efficacité du système en évitant le traitement inutile des RAG
- Diriger les demandes vers le mécanisme de réponse le plus approprié
- Exigences :
- Ensemble de données et modèle spécifiques au LLM
- Amélioration continue pour maintenir la précision
- Avantages :
- Réduction de la charge de calcul pour les requêtes simples
- Amélioration potentielle du temps de réponse pour les requêtes non RAG
5. Résumé
- Une technique pour condenser les documents récupérés dans les systèmes RAG.
- Processus :
- Récupérer les documents pertinents
- Générer des résumés concis de chaque document
- Utiliser des résumés plutôt que des documents complets dans le pipeline RAG
- Objet :
- Améliorer la performance du RAG en se concentrant sur les informations essentielles
- Réduire le bruit et les interférences provenant de contenus moins pertinents
- Avantages :
- Amélioration potentielle de la pertinence des réponses au programme d'éducation et de formation tout au long de la vie
- Permet d'inclure un plus grand nombre de documents dans les limites du contexte
- Défis :
- Risque de perdre des détails importants dans le résumé
- Frais de calcul supplémentaires pour la génération du résumé
6. Inclusion de métadonnées
- Une technique pour enrichir les documents avec des informations contextuelles supplémentaires.
- Types de métadonnées :
- Mots clés
- Titres
- Dates
- Coordonnées de l'auteur
- Les commentaires
- Objet :
- Augmenter les informations contextuelles disponibles pour le système RAG
- Fournir aux gestionnaires du droit d'auteur une meilleure compréhension du contenu et de la pertinence des documents
- Avantages :
- Amélioration potentielle de la précision de la recherche
- Améliore la capacité du LLM à évaluer l'utilité des documents
- Mise en œuvre :
- Peut être effectué lors du prétraitement des documents
- Peut nécessiter des étapes supplémentaires d'extraction ou de génération de données
7. Intégrations composites multi-champs
- Une technique d'intégration avancée pour les systèmes RAG qui crée des intégrations distinctes pour les différents composants du document.
- Processus :
- Identifier les champs pertinents (par exemple, le titre, les phrases clés, le résumé, le contenu principal)
- Générer des embeddings distincts pour chaque champ
- Combiner ou stocker ces encastrements pour les utiliser lors de la recherche.
- Différence par rapport à l'approche standard :
- Traditionnel : Intégration unique pour l'ensemble du document
- Composite : Plusieurs encastrements pour différents aspects du document
- Objet :
- Créer des représentations de documents plus nuancées et tenant compte du contexte
- Saisir des informations provenant d'une plus grande variété de sources dans un document
- Avantages :
- Amélioration potentielle des performances sur les requêtes ambiguës ou à multiples facettes
- Permet une pondération plus souple des différents aspects du document dans la recherche.
- Défis :
- Complexité accrue de l'intégration des processus de stockage et d'extraction
- Peut nécessiter des algorithmes d'appariement plus sophistiqués
8. Enrichissement des requêtes
- Une technique qui consiste à ajouter des termes connexes à la requête initiale afin d'améliorer la couverture de la recherche.
- Processus :
- Analyser la requête originale
- Générer des synonymes et des phrases sémantiquement proches
- Complétez la requête avec ces termes supplémentaires
- Objet :
- Augmenter l'éventail des correspondances potentielles dans le corpus de documents
- Améliorer les performances de recherche pour les requêtes formulées dans un langage spécifique ou technique
- Avantages :
- Possibilité de retrouver des documents pertinents qui ne correspondent pas exactement aux termes de la requête initiale.
- Peut aider à surmonter l'inadéquation du vocabulaire entre les requêtes et les documents
- Défis :
- Risque de dérive des requêtes en l'absence d'une mise en œuvre rigoureuse
- Peut augmenter la charge de calcul dans le processus de recherche.
Pour aller plus loin

Décrivez, ne dessinez pas : tableaux de bord Kibana IA natifs via MCP et ES|QL
Du prompt au tableau de bord. Apprenez à créer des tableaux de bord Kibana en langage naturel grâce à example-mcp-dashbuilder : une application MCP open source qui écrit des requêtes ES|QL, crée des graphiques interactifs et exporte des tableaux de bord entièrement fonctionnels directement vers Kibana.

23 avril 2026
Comment nous avons construit Elasticsearch simdvec pour faire de la recherche vectorielle l'une des plus rapides au monde
Comment nous avons conçu Elasticsearch simdvec, la bibliothèque de noyaux SIMD optimisée manuellement qui alimente chaque requête de recherche vectorielle dans Elasticsearch.

4 mai 2026
Comment mesurer et améliorer le rappel de recherche Elasticsearch : de 0,43 à 0,75 avec la recherche hybride
Découvrez comment mesurer et améliorer le rappel de recherche dans Elasticsearch en combinant la recherche lexicale BM25 avec les embeddings vectoriels de Jina AI, en utilisant l’API rank_eval pour valider l’amélioration avec des données chiffrées.

10 avril 2026
Clustering de documents non supervisé avec Elasticsearch + Jina embeddings
Une approche pratique et reproductible pour le clustering non supervisé de documents avec Elasticsearch et les embeddings Jina.

2 avril 2026
Quand les TSDS rencontrent l'ILM : Concevoir des flux de données temporelles qui ne rejettent pas les données en retard
Comment les limites temporelles des TSDS interagissent avec les phases de l'ILM ; et comment concevoir des politiques qui tolèrent les métriques arrivant en retard.