Desde la búsqueda vectorial hasta las potentes API REST, Elasticsearch ofrece a los desarrolladores el conjunto de herramientas de búsqueda más completo. Explora nuestros cuadernos de muestra en el repositorio de Elasticsearch Labs para probar algo nuevo. También puedes iniciar tu prueba gratuita o ejecutar Elasticsearch localmente hoy mismo.
Esta es la Parte 1 de nuestra exploración sobre las Técnicas Avanzadas de RAG. ¡Haz clic aquí para la Parte 2!
El reciente artículo Searching for Best Practices in Retrieval-Augmented Generation evalúa empíricamente la eficacia de diversas técnicas de mejora del RAG, con el objetivo de converger en un conjunto de mejores prácticas para el RAG.

El gasoducto RAG recomendado por Wang y sus colegas.
Implementaremos algunas de estas mejores prácticas propuestas, concretamente aquellas que buscan mejorar la calidad de la búsqueda (fragmentación de oraciones, HyDE, empaquetado inverso).
Por brevedad, omitiremos aquellas técnicas centradas en mejorar la eficiencia (Clasificación de Consultas y Resumen).
También implementaremos algunas técnicas que no se trataron, pero que personalmente encuentro útiles e interesantes (Inclusión de Metadatos, Incrustaciones Compuestas Multi-Campo, Enriquecimiento de Consultas).
Finalmente, realizaremos una breve prueba para ver si la calidad de nuestros resultados de búsqueda y respuestas generadas mejoró respecto a la línea base. ¡Vamos a ello!
Resumen de RAG
RAG tiene como objetivo mejorar los LLMs recuperando información de bases de conocimiento externas para enriquecer las respuestas generadas. Al proporcionar información específica de dominio, los LLM pueden adaptar rápidamente a casos de uso fuera del alcance de sus datos de entrenamiento; Significativamente más barato que el ajuste fino y más fácil de mantener actualizado.
Las medidas para mejorar la calidad de RAG suelen centrar en dos pistas:
- Mejorar la calidad y claridad de la base de conocimiento.
- Mejorar la cobertura y especificidad de las consultas de búsqueda.
Estas dos medidas lograrán el objetivo de mejorar las probabilidades de que el LLM tenga acceso a hechos e información relevantes, y así sea menos probable que alucine o se base en su propio conocimiento, que puede estar desactualizado o irrelevante.
La diversidad de métodos es difícil de aclarar en solo unas pocas frases. Vamos directamente a la implementación para aclarar las cosas.
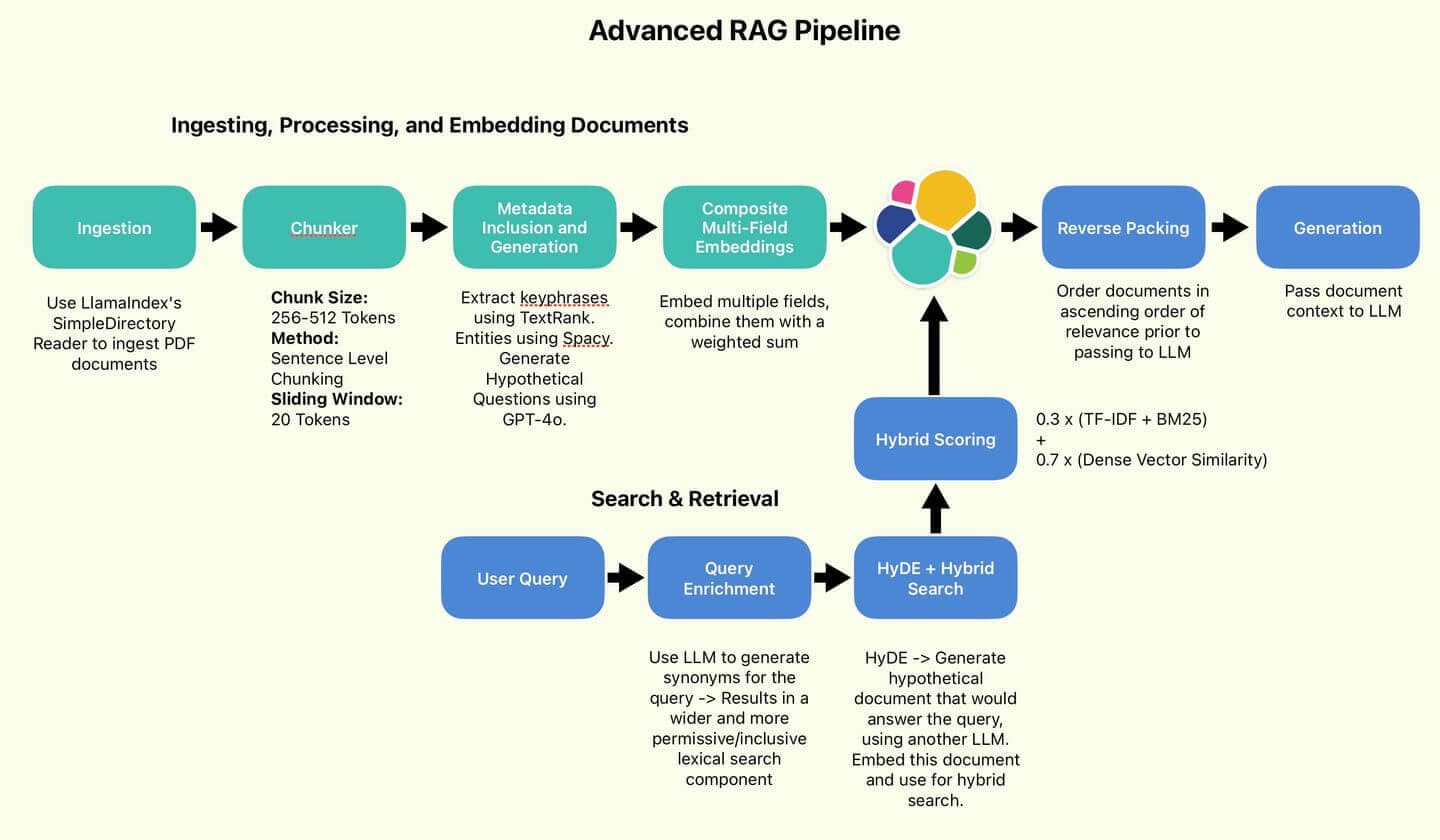
Figura 1: La tubería RAG empleada por el autor.
Índice
- Visión general
- Preparación
- Ingestión, procesamiento e incrustación de documentos
- Ruptura de gato
- Apéndice
Preparación
Todo el código puede encontrar en el repositorio de Searchlabs.
Primero lo primero. Necesitarás lo siguiente:
- Un despliegue de nube elástica
- Una API LLM - Estamos usando un despliegue GPT-4o en Azure OpenAI en este cuaderno
- Python Versión 3.12.4 o posterior
Ejecutaremos todo el código desde el cuaderno main.ipynb.
Adelante, clona el repositorio por git, navega a supporting-blog-content/advanced-rag-techniques y luego ejecuta los siguientes comandos:
Una vez hecho esto, crea un .env y rellenar los siguientes campos (Referenciado en .env.example). Créditos a mi coautor, Claude-3.5, por los comentarios útiles.
A continuación, elegimos el documento a ingerir y lo colocaremos en la carpeta de documentos. Para este artículo, emplearemos el Reporte Anual 2023 de Elastic N.V. Es un documento bastante exigente y denso, perfecto para poner a prueba nuestras técnicas RAG.

Reporte Anual de Elastic 2023
Ahora que estamos listos, vamos a ingestión. Abre main.ipynb y ejecuta las dos primeras celdas para importar todos los paquetes e iniciar todos los servicios.
Ingestión, procesamiento e incrustación de documentos
Ingesta de datos
- Nota personal: Me sorprende la comodidad de LlamaIndex. En la antigüedad, antes de los LLMs y LlamaIndex, ingerir documentos de varios formatos era un proceso doloroso de recopilar paquetes esotéricos de todas partes. Ahora se reduce a una sola llamada de función. Salvaje.
El SimpleDirectoryReader cargará todos los documentos del directory_path. Para .pdf archivos, devuelve una lista de objetos documento, que convierto a diccionarios de Python porque me resultan más fáciles de manejar.
Cada diccionario contiene el contenido clave en el campo text . También contiene metadatos útiles como número de página, nombre de archivo, tamaño y tipo.
Fragmentación a nivel de frase, por fichas
Lo primero que hay que hacer es reducir nuestros documentos a fragmentos de una longitud estándar (para garantizar la coherencia y la manejabilidad). Los modelos de incrustación tienen límites únicos de tokens (tamaño máximo de entrada que pueden procesar). Los tokens son las unidades básicas de texto que procesan los modelos. Para evitar la pérdida de información (truncamiento u omisión de contenido), deberíamos proporcionar texto que no exceda esos límites (dividiendo textos más largos en segmentos más pequeños).
El chunking tiene un impacto significativo en el rendimiento. Idealmente, cada fragmento representaría una pieza de información autónoma, capturando información contextual sobre un único tema. Los métodos de fragmentación incluyen el fragmento a nivel de palabra, donde los documentos se dividen por el recuento de palabras, y el fragmento semántico, que emplea un LLM para identificar puntos de interrupción lógicos.
El fragmento a nivel de palabra es barato, rápido y sencillo, pero corre el riesgo de fragmentar las frases y así romper el contexto. El fragmento semántico se vuelve lento y caro, especialmente si se trata de documentos como el Reporte Anual de Elastic de 116 páginas.
Elijamos un enfoque intermedio. El fragmento a nivel de oración sigue siendo sencillo, pero puede preservar el contexto de forma más eficaz que el fragmento a nivel de palabra, siendo significativamente más barato y rápido. Además, implementaremos una ventana deslizante para capturar parte del contexto circundante y aliviar el impacto de dividir los párrafos.
La clase Chunker incorpora el tokenizador del modelo de incrustación para codificar y decodificar texto. Ahora construiremos fragmentos de 512 tokens cada uno, con una superposición de 20 tokens. Para ello, dividiremos el texto en frases, tokenizaremos esas frases y luego agregaremos las frases tokenizadas a nuestro fragmento actual hasta que no podamos agregar más sin superar nuestro límite de tokens.
Finalmente, decodifica las frases de nuevo al texto original para incrustarlas, almacenándola en un campo llamado original_text. Los chunks se almacenan en un campo llamado chunk. Para reducir el ruido (es decir, documentos inútiles), descartaremos cualquier documento de menos de 50 tokens de longitud.
Vamos a repasarla por nuestros documentos:
Y que me devolvan fragmentos de texto que se parezcan a esto:
Inclusión y generación de metadatos
Dividimos nuestros documentos. Ahora es el momento de enriquecer los datos. Quiero generar o extraer metadatos adicionales. Estos metadatos adicionales pueden emplear para influir y mejorar el rendimiento en las búsquedas.
Definiremos una clase DocumentEnricher , cuyo papel es incluir una lista de documentos (diccionarios de Python) y una lista de funciones del procesador. Estas funciones se ejecutarán sobre la columna original_text de los documentos y almacenarán sus salidas en nuevos campos.
Primero, extraemos las frases clave usando TextRank. TextRank es un algoritmo basado en gráficos que extrae frases clave y oraciones del texto clasificando su importancia en función de las relaciones entre palabras.
A continuación, generaremos potential_questions usando GPT-4o.
Finalmente, extraeremos entidades usando Spacy.
Dado que el código de cada uno de estos es bastante extenso y complejo, me abstendré de reproducirlo aquí. Si te interesa, los archivos están marcados en los ejemplos de código que aparecen a continuación.
Vamos a ejecutar el enriquecimiento de datos:
Y echa un vistazo a los resultados:
Frases clave extraídas por TextRank
Estas frases clave son un sustituto de los temas centrales del fragmento. Si una consulta tiene que ver con ciberseguridad, el puntaje de este segmento se incrementará.
Posibles preguntas generadas por GPT-4o
Estas posibles preguntas pueden coincidir directamente con las consultas de los usuarios, ofreciendo un aumento en el puntaje. Pedimos a GPT-4o que genere preguntas que pueden responder usando la información encontrada en el fragmento actual.
Entidades extraídas por Spacy
Estas entidades cumplen un propósito similar al de las frases clave, pero capturan los nombres de organizaciones e individuos, que la extracción de frases clave puede pasar por alto.
Incrustaciones compuestas multicampo
Ahora que enriquecimos nuestros documentos con metadatos adicionales, podemos aprovechar esta información para crear incrustaciones más robustas y conscientes del contexto.
Repasemos nuestro punto actual en el proceso. Tenemos cuatro campos de interés en cada documento.
Cada campo representa una perspectiva diferente sobre el contexto del documento, lo que puede destacar un área clave en la que el LLM debe centrar.

Pipeline de Enriquecimiento de Metadatos
El plan es incrustar cada uno de estos campos y luego crear una suma ponderada de las incrustaciones, conocida como Incrustación Compuesta.
Con suerte, esta Incrustación Compuesta permitirá que el sistema sea más consciente del contexto, además de introducir otro hiperparámetro ajustable que controla el comportamiento de búsqueda.
Primero, embebamos cada campo y actualicemos cada documento en su lugar, usando nuestro modelo de incrustación definido localmente importado al inicio del cuaderno main.ipynb.
Cada función de incrustación devuelve el campo de la incrustación, que es simplemente el campo de entrada original con un _embedding postfijo.
Ahora definamos las ponderaciones de nuestra incrustación compuesta:
Las ponderaciones te permiten asignar prioridades a cada componente, basándote en tu caso de uso y la calidad de tus datos. Intuitivamente, el tamaño de estos pesos depende del valor semántico de cada componente. Como el texto en fragmentos en sí es, con diferencia, el más rico, asigno un peso del 70%. Como las entidades son las más pequeñas, siendo solo una lista de nombres de organizaciones o personas, le asigno un peso del 5%. La configuración precisa de estos valores debe determinar empíricamente, caso de uso por caso.
Finalmente, escribamos una función para aplicar los pesos y creemos nuestra incrustación compuesta. También eliminaremos todas las incrustaciones de componentes para ahorrar espacio.
Con esto, completamos el procesamiento de los documentos. Ahora tenemos una lista de objetos documento que se ven así:
Indexación a Elastic
Subamos nuestros documentos en masa a Elastic Search. Para este propósito, hace mucho tiempo definí un conjunto de funciones auxiliares elásticas en elastic_helpers.py. Es un código muy largo, así que vamos a centrarnos en las llamadas a funciones.
es_bulk_indexer.bulk_upload_documents funciona con cualquier lista de objetos de diccionario, aprovechando los convenientes mapeos dinámicos de Elasticsearch.
Ve a Kibana y verifica que todos los documentos fueron indexados. Deberían ser 224. ¡No está mal para un documento tan extenso!
Documentos de Reportes Anuales Indexados en Kibana
Ruptura de gato
Vamos a hacer una pausa, el artículo es un poco pesado, lo sé. Mira a mi gato:

Mira lo enojada que está
Adorable. El sombrero desapareció y sospecho que lo robó y escondió en algún sitio :(
¡Enhorabuena por llegar hasta aquí :)
¡Únete a mí en la Parte 2 para probar y evaluar nuestra cadena RAG!
Apéndice
Definiciones
1. Fragmentación de frases
- Una técnica de preprocesamiento empleada en sistemas RAG para dividir el texto en unidades más pequeñas y significativas.
- Proceso:
- Entrada: Gran bloque de texto (por ejemplo, documento, párrafo)
- Salida: Segmentos de texto más pequeños (normalmente oraciones o pequeños grupos de oraciones)
- Propósito:
- Crea segmentos de texto granulares y específicos de contexto
- Permite una indexación y recuperación más precisas
- Mejora la relevancia de la información recuperada en sistemas RAG
- Características:
- Los segmentos tienen significado semántico
- Puede ser indexado y recuperado de forma independiente
- A menudo preserva cierto contexto para garantizar la comprensibilidad independiente
- Beneficios:
- Mejora la precisión de la recuperación
- Permite una ampliación más enfocada en las canalizaciones RAG
2. HyDE (Embedding de Documentos Hipotéticos)
- Una técnica que emplea un LLM para generar un documento hipotético para la expansión de consultas en sistemas RAG.
- Proceso:
- Consulta de entrada a un LLM
- El LLM genera un documento hipotético que responde a la consulta
- Incrustar el documento generado
- Emplea la incrustación para búsqueda vectorial
- Diferencia clave:
- RAG tradicional: Empareja la consulta con documentos
- HyDE: Empareja documentos con documentos
- Propósito:
- Mejorar el rendimiento de la recuperación, especialmente para consultas complejas o ambiguas
- Captura un contexto semántico más rico que una consulta corta
- Beneficios:
- Aprovecha el conocimiento de LLM para ampliar las consultas
- Puede mejorar potencialmente la relevancia de los documentos recuperados
- Desafíos:
- Requiere inferencia adicional de LLM, aumentando la latencia y el costo
- El rendimiento depende de la calidad del documento hipotético generado
3. Empaquetado inverso
- Una técnica empleada en sistemas RAG para reordenar los resultados de búsqueda antes de pasarlos al LLM.
- Proceso:
- El motor de búsqueda (por ejemplo, Elasticsearch) devuelve los documentos en orden descendente de relevancia.
- El orden se invierte, colocando el documento más relevante al final.
- Propósito:
- Aprovecha el sesgo de actualidad de los LLM, que tienden a centrar más en la información más reciente en su contexto.
- Garantiza que la información más relevante esté "más fresca" en la ventana de contexto del LLM.
- Ejemplo: Orden original: [Más relevante, Segundo más, Tercero más, ...] Orden invertido: [..., Tercero más, segundo más relevante]
4. Clasificación de consultas
- Una técnica para optimizar la eficiencia del sistema RAG determinando si una consulta requiere RAG o puede ser respondida directamente por el LLM.
- Proceso:
- Desarrollar un conjunto de datos personalizado específico para el LLM en uso
- Capacitar un modelo de clasificación especializado
- Emplea el modelo para categorizar las consultas entrantes
- Propósito:
- Mejorar la eficiencia del sistema evitando el procesamiento innecesario de RAG
- Consulta directa al mecanismo de respuesta más adecuado
- Requisitos:
- Conjunto de datos y modelo específicos de LLM
- Refinamiento continuo para mantener la precisión
- Beneficios:
- Reduce la sobrecarga computacional para consultas simples
- Potencialmente mejora el tiempo de respuesta para consultas que no son RAG
5. Resumen
- Una técnica para condensar documentos recuperados en sistemas RAG.
- Proceso:
- Recuperar documentos relevantes
- Genera resúmenes concisos de cada documento
- Emplea resúmenes en lugar de documentos completos en la tubería RAG
- Propósito:
- Mejora el rendimiento de RAG centrándote en la información esencial
- Reducir el ruido y las interferencias de contenido menos relevante
- Beneficios:
- Potencialmente mejora la relevancia de las respuestas de los LLM
- Permite incluir más documentos dentro de los límites del contexto
- Desafíos:
- Riesgo de perder detalles importantes en la resumen
- Sobrecarga computacional adicional para la generación de resúmenes
6. Inclusión de metadatos
- Una técnica para enriquecer documentos con información contextual adicional.
- Tipos de metadatos:
- Frases clave
- Títulos
- Fechas
- Detalles de la autoría
- Resumen
- Propósito:
- Aumentar la información contextual disponible para el sistema RAG
- Proporcionar a los LLMs una comprensión más clara del contenido y la relevancia del documento
- Beneficios:
- Potencialmente mejora la precisión de la recuperación
- Mejora la capacidad del LLM para evaluar la utilidad de los documentos
- Implementación:
- Se puede hacer durante el preprocesamiento de documentos
- Puede requerir pasos adicionales de extracción de datos o generación
7. Incrustaciones compuestas multicampo
- Una técnica avanzada de incrustación para sistemas RAG que crea incrustaciones separadas para diferentes componentes del documento.
- Proceso:
- Identificar campos relevantes (por ejemplo, título, frases clave, resúmenes, contenido principal)
- Genera incrustaciones separadas para cada campo
- Combina o almacena estos embeddings para su uso en la recuperación
- Diferencia con el enfoque estándar:
- Tradicional: Embedding único para todo el documento
- Compuesto: Múltiples incrustaciones para diferentes aspectos del documento
- Propósito:
- Crear representaciones documentales más matizadas y conscientes del contexto
- Captura información de una mayor variedad de fuentes dentro de un documento
- Beneficios:
- Potencialmente mejora el rendimiento en consultas ambiguas o multifacéticas
- Permite una ponderación más flexible de los diferentes aspectos del documento en la recuperación
- Desafíos:
- Mayor complejidad en los procesos de incrustación, almacenamiento y recuperación
- Puede requerir algoritmos de emparejamiento más sofisticados
8. Enriquecimiento de consultas
- Una técnica para ampliar la consulta original con términos relacionados para mejorar la cobertura de búsqueda.
- Proceso:
- Analizar la consulta original
- Generar sinónimos y frases semánticamente relacionadas
- Complementa la consulta con estos términos adicionales
- Propósito:
- Ampliar el rango de posibles coincidencias en el corpus documental
- Mejorar el rendimiento de recuperación para consultas con lenguaje específico o técnico
- Beneficios:
- Potencialmente recupera documentos relevantes que no coinciden exactamente con los términos originales de la consulta
- Puede ayudar a superar la discrepancia de vocabulario entre consultas y documentos
- Desafíos:
- Riesgo de deriva de consulta si no se implementa cuidadosamente
- Puede aumentar la sobrecarga computacional en el proceso de recuperación
Contenido relacionado

Descríbelo, no lo dibujes: dashboard de Kibana con IA integrada a través de MCP y ES|QL
De la indicación al dashboard. Aprende a construir dashboards de Kibana con lenguaje natural a través de example-mcp-dashbuilder: una aplicación MCP open source que escribe consultas ES|QL, crea gráficos interactivos y exporta dashboards completamente funcionales directamente a Kibana.

23 de abril de 2026
Cómo creamos Elasticsearch simdvec para hacer una de las búsquedas vectoriales más rápidas del mundo
Cómo construimos Elasticsearch SIMDvec, la biblioteca del kernel SIMD ajustada a mano detrás de cada consulta de búsqueda vectorial en Elasticsearch.

4 de mayo de 2026
Cómo medir y mejorar la recuperación de búsqueda de Elasticsearch: de 0,43 a 0,75 con búsqueda híbrida
Aprende a medir y mejorar la recuperación de búsqueda en Elasticsearch combinando la búsqueda léxica BM25 con incrustaciones vectoriales de Jina AI, usando la API rank_eval para validar la mejora con cifras reales.

10 de abril de 2026
Agrupación no supervisada de documentos con Elasticsearch + incrustaciones de Jina
Un enfoque práctico y reproducible para la agrupación no supervisada de documentos con Elasticsearch y embeddings de Jina.

2 de abril de 2026
Cuando TSDS se une a ILM: diseñar flujos de datos temporales que no rechazan los datos tardíos
Cómo los límites de tiempo de TSDS interactúan con las fases de ILM; y cómo diseñar políticas que toleren métricas tardías.