Möchten Sie eine Elastic-Zertifizierung erwerben? Erfahren Sie, wann die nächste Elasticsearch-Engineer-Schulung stattfindet! Sie können jetzt eine kostenlose Cloud-Testversion starten oder Elastic auf Ihrem lokalen Rechner testen.
Sei vorbereitet:
Dieser Blog ist anders als üblich. Es handelt sich weder um die Erklärung einer neuen Funktion noch um ein Tutorial. Es geht hier um eine einzige Codezeile, deren Schreiben drei Tage gedauert hat. Wir werden eine mögliche Beschädigung des Apache Lucene-Index beheben. Einige Erkenntnisse, die Sie hoffentlich mitnehmen können:
- Alle unzuverlässigen Tests sind bei ausreichend Zeit und den richtigen Werkzeugen wiederholbar.
- Für robuste Systeme sind viele Testebenen unerlässlich. Höhere Testebenen werden jedoch zunehmend schwieriger zu debuggen und zu reproduzieren.
- Sleep ist ein ausgezeichneter Debugger.
Wie Elasticsearch testet
Bei Elastic verfügen wir über eine Vielzahl von Tests, die gegen die Elasticsearch-Codebasis ausgeführt werden. Manche sind einfache und fokussierte Funktionstests, andere sind Integrationstests für einen einzelnen Knoten im „Happy Path“-Modus, und wieder andere versuchen, den Cluster zum Absturz zu bringen, um sicherzustellen, dass sich in einem Fehlerszenario alles korrekt verhält. Wenn ein Test wiederholt fehlschlägt, erstellt ein Ingenieur oder die Tool-Automatisierung ein GitHub-Issue und kennzeichnet es zur Untersuchung durch ein bestimmtes Team. Dieser spezielle Fehler wurde bei einem Test der letztgenannten Art entdeckt. Diese Tests sind knifflig und manchmal erst nach vielen Durchläufen wiederholbar.
Was genau wird mit diesem Test geprüft?
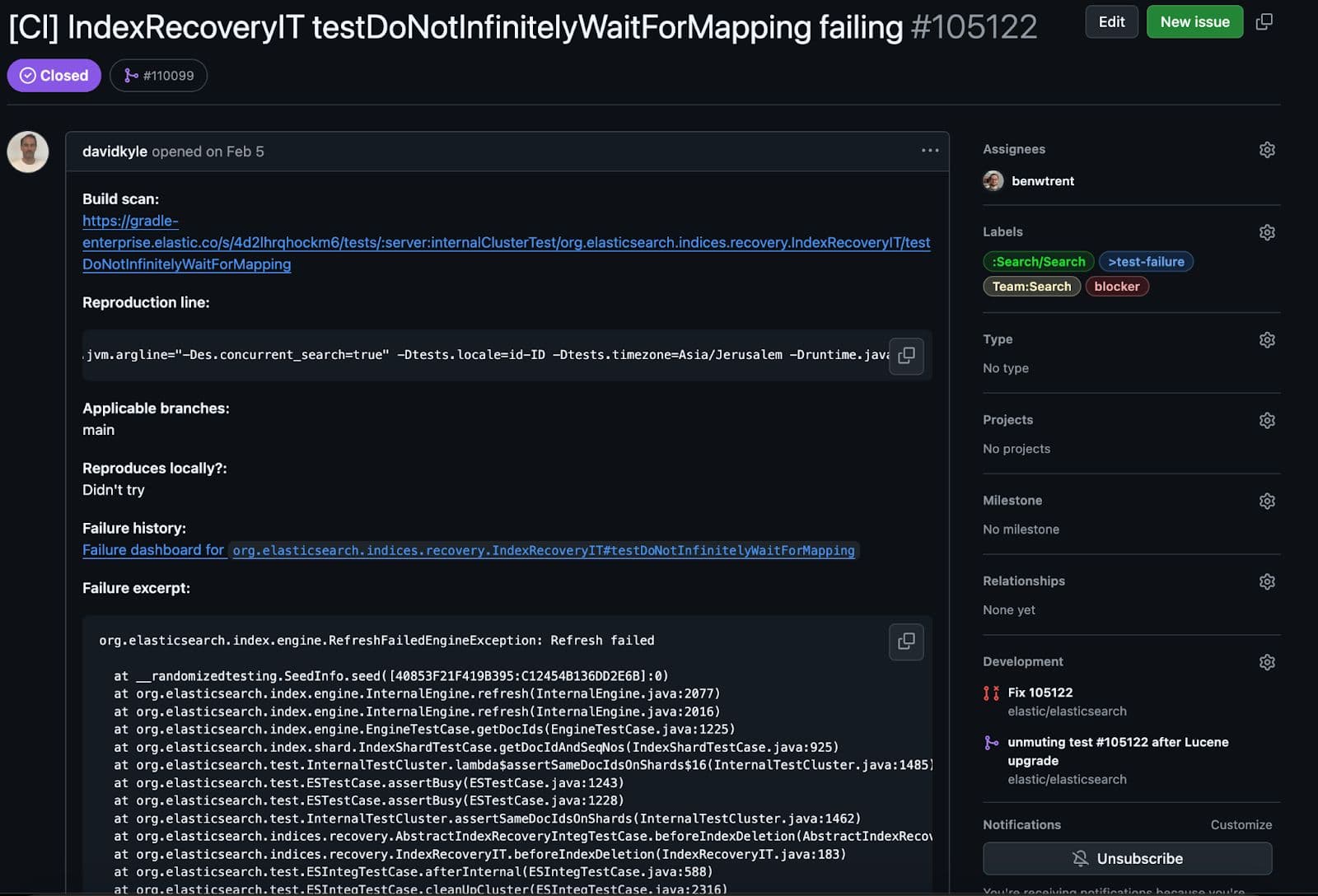
Dieser Test ist besonders interessant. Es wird eine bestimmte Zuordnung erstellen und diese auf einen primären Shard anwenden. Dann beim Versuch, eine Replik zu erstellen. Der entscheidende Unterschied besteht darin, dass beim Versuch der Replik, das Dokument zu parsen, der Test eine Ausnahme auslöst, was dazu führt, dass die Wiederherstellung auf eine überraschende (aber erwartete) Weise fehlschlägt.
Alles funktionierte wie erwartet, allerdings mit einem entscheidenden Haken. Bei der Bereinigung der Testergebnisse haben wir die Konsistenz überprüft, und dabei ist dieser Test auf ein Problem gestoßen.
Dieser Test schlug erwartungsgemäß fehl. Im Rahmen der Konsistenzprüfung würden wir überprüfen, ob alle replizierten und primären Lucene-Segmentdateien konsistent sind. Das heißt, unverfälscht und vollständig repliziert. Teilweise oder beschädigte Daten sind viel schlimmer als ein vollständiger Ausfall. Hier ist der beängstigende und abgekürzte Stacktrace des Fehlers.
Irgendwie wurde der replizierte Shard während des erzwungenen Replikationsfehlers beschädigt! Ich möchte Ihnen den Kern des Fehlers in einfachen Worten erklären.
Lucene ist eine segmentbasierte Architektur, das heißt, jedes Segment kennt und verwaltet seine eigenen schreibgeschützten Dateien. Dieses spezielle Segment wurde über seine SegmentCoreReaders validiert, um sicherzustellen, dass alles in Ordnung war. Jeder Core-Reader speichert Metadaten, die angeben, welche Feldtypen und Dateien für ein bestimmtes Segment vorhanden sind. Bei der Validierung des Lucene90PointsFormat fehlten jedoch bestimmte erwartete Dateien. Mit der Segmentdatei _0.cfs erwarteten wir eine Punktformatdatei namens kdi. cfs steht für "zusammengesetztes Dateisystem", in dem Lucene manchmal alle Feldtypen und alle kleinen Dateien zu einer einzigen größeren Datei kombiniert, um eine effizientere Replikation und Ressourcennutzung zu ermöglichen. Tatsächlich fehlten alle drei Punktdateierweiterungen: kdd, kdi, und kdm . Wie konnten wir an eine Stelle gelangen, an der ein Lucene-Segment eine Punktdatei erwartet, diese aber fehlt?! Das sieht nach einem schwerwiegenden Datenkorruptionsfehler aus!
Der erste Schritt bei jeder Fehlerbehebung: den Fehler reproduzieren.
Es war äußerst mühsam, den Fehler bei diesem speziellen Bug zu reproduzieren. Obwohl wir in Elasticsearch die Möglichkeit des randomisierten Wertetests nutzen, stellen wir sicher, dass jeder Fehler mit einem (hoffentlich) reproduzierbaren Zufallswert versehen wird, um zu gewährleisten, dass alle Fehler untersucht werden können. Das funktioniert hervorragend für alle Fehler, außer für solche, die durch eine Race Condition verursacht werden.
Egal wie oft ich es versucht habe, der Fehler konnte mit diesem speziellen Seed lokal nie reproduziert werden. Es gibt jedoch Möglichkeiten, die Tests durchzuführen und ein reproduzierbareres Scheitern zu erzielen.
Unsere spezielle Testsuite ermöglicht es, einen bestimmten Test über den Parameter -Dtests.iters im selben Befehl mehr als einmal auszuführen. Das reichte mir aber nicht, ich musste sicherstellen, dass die Ausführungsthreads wechselten und dadurch die Wahrscheinlichkeit des Auftretens dieser Race Condition erhöht wurde. Ein weiteres Problem im System war, dass der Test am Ende so lange dauerte, dass der Test-Runner eine Zeitüberschreitung meldete. Am Ende verwendete ich den folgenden albtraumhaften Bash-Code, um den Test reproduzierbar auszuführen:
Und da kommt Stress ins Spiel. Dies ermöglicht es Ihnen, schnell einen Prozess zu starten, der die CPU-Kerne im Handumdrehen belegt. Durch wiederholtes, wahlloses Ausführen von stress-ng während zahlreicher Iterationen des fehlgeschlagenen Tests konnte ich den Fehler schließlich reproduzieren. Ein Schritt näher. Um das System zu belasten, öffnen Sie einfach ein weiteres Terminalfenster und führen Sie folgenden Befehl aus:
Aufdeckung des Fehlers
Da der Testfehler, der den Bug aufdeckt, nun größtenteils reproduzierbar ist, ist es an der Zeit, die Ursache zu finden. Das Merkwürdige an diesem speziellen Test ist, dass Lucene eine Ausnahme auslöst, weil es Punktwerte erwartet, aber vom Test direkt keine hinzugefügt werden. Nur Textwerte. Dies veranlasste mich, die jüngsten Änderungen an unseren optimistischen Parallelitätskontrollfeldern _seq_no und _primary_term genauer zu betrachten. Beide werden als Punkte indexiert und sind in jedem Elasticsearch-Dokument vorhanden.
Tatsächlich hat ein Commit unseren _seq_no Mapper verändert! JA! Das muss die Ursache sein! Doch meine Begeisterung war nur von kurzer Dauer. Dies änderte lediglich die Reihenfolge, in der Felder zum Dokument hinzugefügt wurden. Vor dieser Änderung wurden _seq_no Felder zuletzt zum Dokument hinzugefügt. Anschließend wurden sie zuerst hinzugefügt. Die Reihenfolge beim Hinzufügen von Feldern zu einem Lucene-Dokument kann unmöglich diesen Fehler verursachen...
Ja, die Änderung der Reihenfolge beim Hinzufügen der Felder hat den Fehler verursacht. Das war überraschend und entpuppte sich als Fehler in Lucene selbst! Die Änderung der Reihenfolge, in der die Felder analysiert werden, sollte das Verhalten beim Parsen eines Dokuments nicht verändern.
Der Fehler in Lucene
Der Fehler in Lucene bezog sich tatsächlich auf folgende Bedingungen:
- Indizieren eines Punktewertfeldes (z. B.
_seq_no) - Beim Versuch, ein Textfeld zu indizieren, trat während der Analyse ein Fehler auf.
- In diesem ungewöhnlichen Zustand öffnen wir einen Near Real Time Reader des Autors, der die Textindexanalyse-Ausnahme erlebt.
Aber egal, wie viele Wege ich auch versucht habe, ich konnte es nicht vollständig nachbilden. Ich habe direkt Haltepunkte zum Debuggen im gesamten Lucene-Quellcode eingefügt. Ich habe versucht, während des Ausnahmepfads zufällig Reader zu öffnen. Ich habe sogar Megabytes über Megabytes an Protokolldateien ausgedruckt, um den genauen Pfad zu finden, an dem dieser Fehler aufgetreten ist. Ich konnte es einfach nicht. Ich habe einen ganzen Tag lang gekämpft und verloren.
Dann habe ich geschlafen.
Am nächsten Tag las ich den ursprünglichen Stacktrace erneut und entdeckte die folgende Zeile:
Bei all meinen Nachbildungsversuchen habe ich die Aufbewahrungs- und Zusammenführungsrichtlinie nie explizit festgelegt. Die SoftDeletesRetentionMergePolicy wird von Elasticsearch verwendet, um Löschungen in Replikaten genau zu replizieren und sicherzustellen, dass alle unsere Parallelitätskontrollen dafür zuständig sind, wann Dokumente tatsächlich entfernt werden. Andernfalls hat Lucene die volle Kontrolle und entfernt sie bei jedem Merge.
Nachdem ich diese Richtlinie hinzugefügt und die oben genannten grundlegendsten Schritte wiederholt hatte, trat der Fehler sofort wieder auf.
Ich habe mich noch nie so sehr gefreut, einen Fehler in Lucene zu melden.
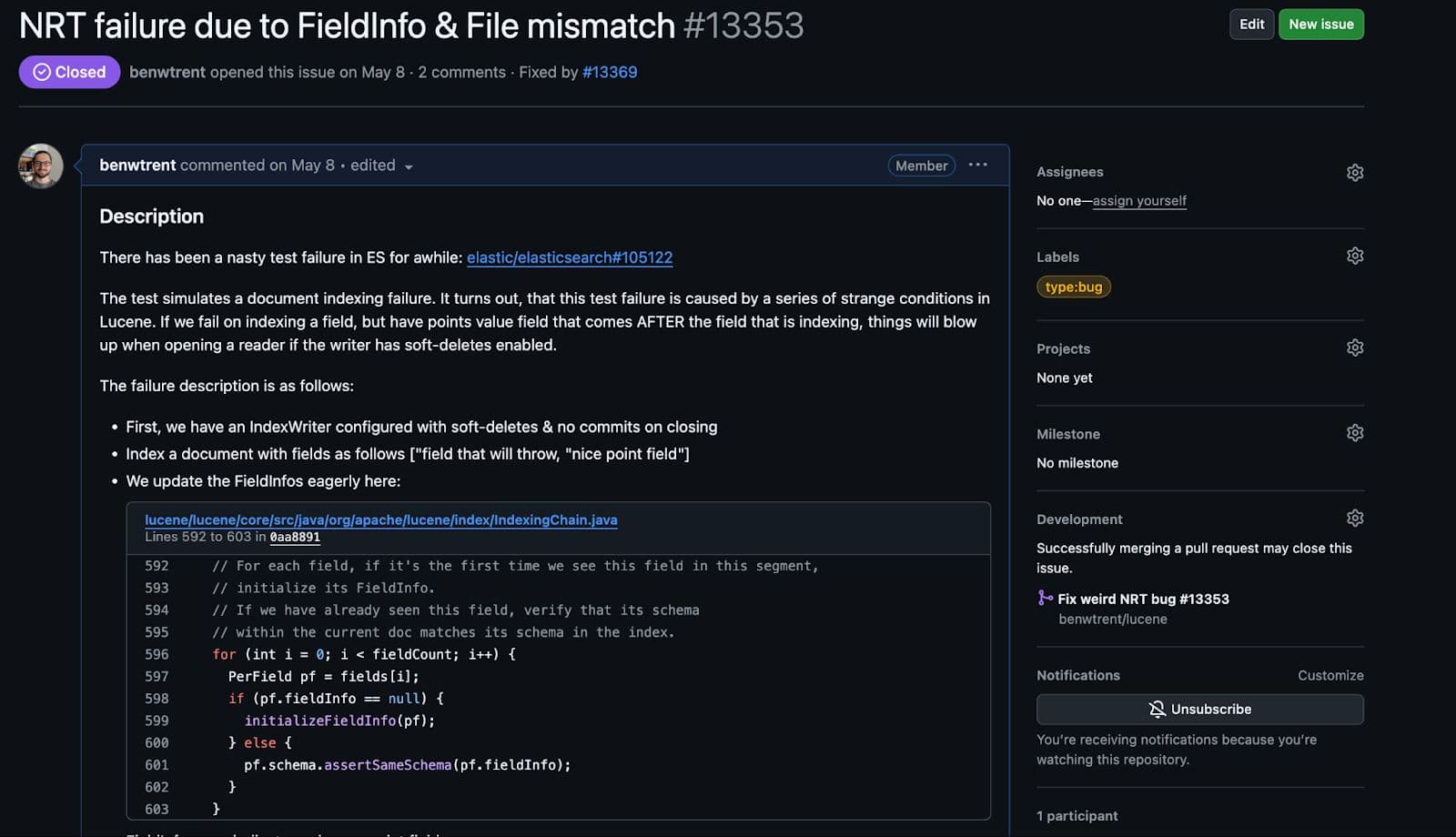
Während sich dies in Elasticsearch als Race Condition darstellte, war es einfach, in Lucene einen wiederholt fehlschlagenden Test zu schreiben, sobald alle Bedingungen erfüllt waren.
Am Ende wurde es, wie alle guten Bugs, mit nur einer einzigen Codezeile behoben. Mehrere Tage Arbeit für nur eine einzige Codezeile.
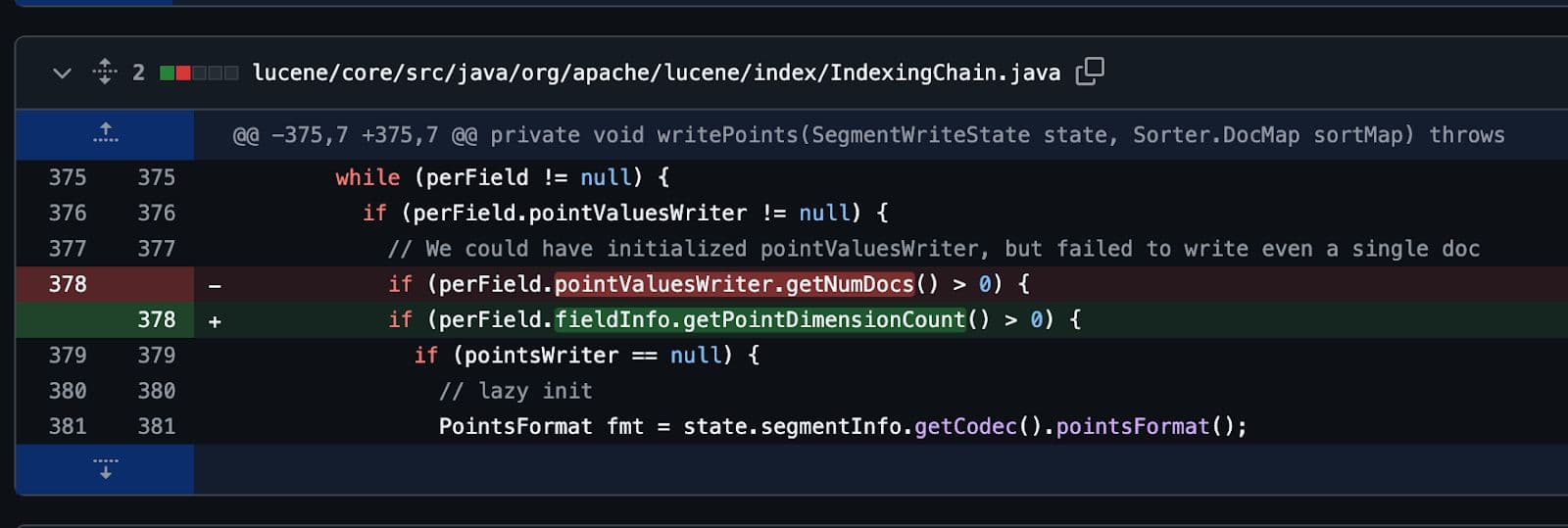
Aber es hat sich gelohnt.
Nicht das Ende
Ich hoffe, ihr hattet Spaß an dieser turbulenten Reise mit mir! Software zu entwickeln, insbesondere so weit verbreitete und komplexe Software wie Elasticsearch und Apache Lucene, ist sehr lohnend. Manchmal ist es jedoch außerordentlich frustrierend. Ich liebe und hasse Software gleichermaßen. Die Fehlerbehebung hört nie auf!
Zugehörige Inhalte

3. September 2025
Vektorsuchfilterung: Relevanz beibehalten
Es reicht nicht aus, eine Vektorsuche durchzuführen, um die ähnlichsten Ergebnisse zu einer Suchanfrage zu finden. Um die Suchergebnisse einzugrenzen, ist häufig das Filtern erforderlich. Dieser Artikel erklärt, wie die Filterung bei der Vektorsuche in Elasticsearch und Apache Lucene funktioniert.

7. April 2025
Beschleunigung der Zusammenführung von HNSW-Diagrammen
Informieren Sie sich über unsere Arbeit zur Reduzierung des Aufwands beim Erstellen mehrerer HNSW-Diagramme, insbesondere zur Reduzierung der Kosten für das Zusammenführen von Diagrammen.

7. Februar 2025
Parallelitätsfehler in Lucene: Wie man optimistische Parallelitätsfehler behebt
Dank Fray, einem Framework für deterministische Parallelitätstests aus dem PASTA Lab der Carnegie Mellon University, konnten wir einen kniffligen Lucene-Fehler aufspüren und beheben.

3. Januar 2025
Lucene Wrapped 2024
2024 war ein weiteres wichtiges Jahr für Apache Lucene. In diesem Blogbeitrag gehen wir auf die wichtigsten Punkte ein.

26. Juni 2024
Elasticsearch vs. OpenSearch: Vergleich der Leistung bei der Vektorsuche
Elasticsearch ist standardmäßig bei der Vektorsuche 2 bis 12 Mal schneller als OpenSearch