Einleitung
Im Elastic Stack gibt es viele LLM-gestützte agentenbasierte Anwendungen, wie zum Beispiel den kommenden Elastic AI Agent im Agent Builder (derzeit in der technischen Vorschau) und Attack Discovery (GA in 8.18 und 9.0+), und weitere sind in Arbeit. Während der Entwicklung und auch nach der Bereitstellung ist es wichtig, diese Fragen zu beantworten:
- Wie schätzen wir die Qualität der Antworten dieser KI-Anwendungen ein?
- Wenn wir eine Änderung vornehmen, wie können wir garantieren, dass diese Änderung tatsächlich eine Verbesserung darstellt und keine Verschlechterung der Benutzererfahrung zur Folge hat?
- Wie können wir diese Ergebnisse auf einfache und reproduzierbare Weise testen?
Im Gegensatz zu herkömmlichen Softwaretests erfordert die Evaluierung von generativen KI-Anwendungen statistische Methoden, eine differenzierte qualitative Überprüfung und ein tiefes Verständnis der Ziele der Nutzer.
Dieser Artikel beschreibt detailliert den Prozess, den das Elastic-Entwicklerteam anwendet, um Evaluierungen durchzuführen, die Qualität der Änderungen vor der Bereitstellung sicherzustellen und die Systemleistung zu überwachen. Unser Ziel ist es, sicherzustellen, dass jede Änderung durch Beweise untermauert wird, was zu verlässlichen und nachvollziehbaren Ergebnissen führt. Ein Teil dieses Prozesses ist direkt in Kibana integriert und spiegelt damit unser Bekenntnis zu Transparenz als Teil unseres Open-Source-Ethos wider. Durch die offene Weitergabe von Teilen unserer Evaluierungsdaten und Kennzahlen wollen wir das Vertrauen der Community stärken und einen klaren Rahmen für alle bieten, die KI-Agenten entwickeln oder unsere Produkte nutzen.
Produktbeispiele
Die in diesem Dokument verwendeten Methoden bildeten die Grundlage für unsere iterative Weiterentwicklung und Verbesserung von Lösungen wie Attack Discovery und Elastic AI Agent. Eine kurze Vorstellung der beiden:
Angriffserkennung von Elastic Security
Attack Discovery verwendet LLMs, um Angriffssequenzen in Elastic zu identifizieren und zusammenzufassen. Anhand der Elastic Security-Warnmeldungen in einem bestimmten Zeitraum (standardmäßig 24 Stunden) ermittelt der agentenbasierte Workflow von Attack Discovery automatisch, ob ein oder mehrere Angriffe stattgefunden haben, sowie wichtige Informationen darüber, welcher Host oder welche Benutzer kompromittiert wurden und welche Warnmeldungen zu dieser Schlussfolgerung beigetragen haben.

Ziel ist es, dass die LLM-basierte Lösung ein Ergebnis liefert, das mindestens so gut ist wie das eines Menschen.
Elastischer KI-Agent
Der Elastic Agent Builder ist unsere neue Plattform zum Erstellen kontextsensitiver KI-Agenten, die alle unsere Suchfunktionen nutzen. Es beinhaltet den Elastic AI Agent, einen vorkonfigurierten, universell einsetzbaren Agenten, der Benutzern dabei hilft, ihre Daten durch dialogbasierte Interaktion zu verstehen und Antworten darauf zu erhalten.
Der Agent erreicht dies, indem er automatisch relevante Informationen innerhalb von Elasticsearch oder verbundenen Wissensdatenbanken identifiziert und eine Reihe vorgefertigter Tools nutzt, um mit diesen zu interagieren. Dies versetzt den Elastic AI Agent in die Lage, auf ein breites Spektrum von Benutzeranfragen zu reagieren, von einfachen Fragen und Antworten zu einem einzelnen Dokument bis hin zu komplexen Anfragen, die eine Aggregation und ein- oder mehrstufige Suchvorgänge über mehrere Indizes hinweg erfordern.
Verbesserungen durch Experimente messen
Im Kontext von KI-Agenten ist ein Experiment eine strukturierte, testbare Änderung des Systems, die darauf abzielt, die Leistung in genau definierten Dimensionen (z. B. Hilfreichkeit, Korrektheit, Latenz) zu verbessern. Ziel ist es, die folgende Frage endgültig zu beantworten: „Wenn wir diese Änderung umsetzen, können wir dann garantieren, dass es sich um eine echte Verbesserung handelt und die Benutzererfahrung nicht verschlechtert wird?“
Die meisten unserer Experimente umfassen im Allgemeinen Folgendes:
- Eine Hypothese: Eine spezifische und widerlegbare Behauptung. Beispiel: „Das Hinzufügen des Zugriffs auf ein Tool zur Angriffserkennung verbessert die Korrektheit sicherheitsrelevanter Abfragen.“
- Erfolgskriterien: Klare Schwellenwerte, die definieren, was „Erfolg“ bedeutet. Beispiel: „+5 % Verbesserung der Korrektheitsbewertung im Sicherheitsdatensatz, keine Verschlechterung in anderen Bereichen.“
- Evaluierungsplan: Wie wir den Erfolg messen (Kennzahlen, Datensätze, Vergleichsmethode)
Ein erfolgreiches Experiment ist ein systematischer Forschungsprozess. Jede Änderung, von einer kleinen, spontanen Anpassung bis hin zu einer grundlegenden architektonischen Umgestaltung, durchläuft diese sieben Schritte, um sicherzustellen, dass die Ergebnisse aussagekräftig und umsetzbar sind:
- Schritt 1: Identifizieren Sie das Problem
- Schritt 2: Kennzahlen definieren
- Schritt 3: Formulieren Sie eine klare Hypothese
- Schritt 4: Vorbereitung des Auswertungsdatensatzes
- Schritt 5: Führen Sie das Experiment durch.
- Schritt 6: Ergebnisse analysieren + wiederholen
- Schritt 7: Treffen Sie eine Entscheidung und dokumentieren Sie diese.
Ein Beispiel für diese Schritte ist in Abbildung 1 dargestellt. In den folgenden Unterabschnitten werden die einzelnen Schritte erläutert, und die technischen Details der einzelnen Schritte werden wir in den folgenden Dokumenten genauer ausführen.

Abbildung 1: Schritte im Lebenszyklus des Experiments
Schrittweise Anleitung mit echten Elastic-Beispielen
Schritt 1: Identifizieren Sie das Problem
Welches Problem soll durch diese Änderung genau gelöst werden?
Beispiel für die Angriffserkennung: Die Zusammenfassungen sind gelegentlich unvollständig, oder harmlose Aktivitäten werden fälschlicherweise als Angriff eingestuft (falsch positive Ergebnisse).
Beispiel für einen Elastic AI Agent: Die Werkzeugauswahl des Agenten, insbesondere bei analytischen Abfragen, ist suboptimal und inkonsistent, was häufig dazu führt, dass das falsche Werkzeug ausgewählt wird. Dies wiederum erhöht die Tokenkosten und die Latenz.
Schritt 2: Kennzahlen definieren
Das Problem muss messbar gemacht werden, damit wir eine Veränderung mit dem aktuellen Zustand vergleichen können.
Gängige Metriken sind Präzision und Trefferquote, semantische Ähnlichkeit, Faktentreue usw. Je nach Anwendungsfall verwenden wir Code-Checks, um die Metriken zu berechnen, wie z. B. übereinstimmende Alarm-IDs oder korrekt abgerufene URLs, oder wir verwenden Techniken wie LLM-as-judge für freiere Antworten.
Nachfolgend sind einige (nicht vollständige) Beispielmetriken aufgeführt, die in den Experimenten verwendet wurden:
Angriffserkennung
| Metrisch | Beschreibung |
|---|---|
| Präzision und Rückruf | Vergleichen Sie die Alarm-IDs zwischen tatsächlichen und erwarteten Ausgaben, um die Erkennungsgenauigkeit zu messen. |
| Ähnlichkeit | Verwenden Sie BERTScore, um die semantische Ähnlichkeit des Antworttextes zu vergleichen. |
| Faktentreue | Sind wichtige IOCs (Indikatoren für eine Kompromittierung) vorhanden? Werden die MITRE-Taktiken (Branchenklassifizierung von Angriffen) korrekt abgebildet? |
| Konsistenz der Angriffskette | Vergleichen Sie die Anzahl der Entdeckungen, um festzustellen, ob der Angriff über- oder untererfasst gemeldet wurde. |
Elastischer KI-Agent
| Metrisch | Beschreibung |
|---|---|
| Präzision und Rückruf | Um die Genauigkeit des Informationsabrufs zu messen, werden die vom Agenten abgerufenen Dokumente/Informationen mit den tatsächlich benötigten Informationen oder Dokumenten abgeglichen, die zur Beantwortung der Anfrage erforderlich sind. |
| Faktentreue | Sind die zur Beantwortung der Benutzeranfrage erforderlichen Schlüsselinformationen vorhanden? Sind die Fakten in der richtigen Reihenfolge für verfahrenstechnische Anfragen? |
| Relevanz der Antwort | Enthält die Antwort Informationen, die für die Benutzeranfrage nebensächlich oder nicht relevant sind? |
| Vollständigkeit der Antwort | Beantwortet die Antwort alle Teile der Benutzeranfrage? Enthält die Antwort alle Informationen, die auch in den Referenzdaten vorhanden sind? |
| ES|QL-Validierung | Ist der generierte ES|QL-Code syntaktisch korrekt? Ist es funktional identisch mit dem tatsächlichen ES|QL-Standard? |
Schritt 3: Formulieren Sie eine klare Hypothese
Legen Sie anhand des Problems und der oben definierten Kennzahlen klare Erfolgskriterien fest.
Beispiel für einen elastischen KI-Agenten:
- Nehmen Sie Änderungen an den Beschreibungen der Tools relevance_search und nl_search vor, um deren spezifische Funktionen und Anwendungsfälle klar zu definieren.
- Wir gehen davon aus, dass wir die Genauigkeit unserer Tool-Aufrufe um 25 % verbessern werden.
- Wir werden überprüfen, ob dies insgesamt positiv ist, indem wir sicherstellen, dass es keine negativen Auswirkungen auf andere Kennzahlen gibt, z. B. Faktentreue und Vollständigkeit.
- Wir glauben, dass dies funktionieren wird, da präzise Werkzeugbeschreibungen dem Agenten helfen, das am besten geeignete Suchwerkzeug für verschiedene Anfragetypen genauer auszuwählen und anzuwenden, wodurch Fehlanwendungen reduziert und die Gesamteffektivität der Suche verbessert wird.
Schritt 4: Vorbereitung des Auswertungsdatensatzes
Um die Leistungsfähigkeit des Systems zu messen, verwenden wir Datensätze, die realweltliche Szenarien abbilden.
Je nach Art der durchgeführten Evaluierung benötigen wir möglicherweise unterschiedliche Datenformate, wie z. B. Rohdaten, die einem LLM zugeführt werden (z. B. Angriffsszenarien für die Angriffserkennung) und erwartete Ergebnisse. Wenn es sich bei der Anwendung um einen Chatbot handelt, dann können die Eingaben Benutzeranfragen sein und die Ausgaben korrekte Chatbot-Antworten, korrekte Links, die er hätte abrufen sollen, und so weiter.
Beispiel für Angriffserkennung:
| 10 neuartige Angriffsszenarien |
|---|
| 8 Folgen von Oh My Malware (ohmymalware.com) |
| 4 Szenarien mit mehreren Angriffen (entstanden durch die Kombination von Angriffen aus den ersten beiden Kategorien) |
| 3 harmlose Szenarien |
Beispiel eines Evaluierungsdatensatzes für Elastic AI-Agenten (Kibana-Datensatzlink):
| 14 Indizes, die Open-Source-Datensätze verwenden, um mehrere Quellen in KB zu simulieren. |
|---|
| 5 Abfragetypen (analytisch, Textabfrage, hybrid…) |
| 7 Arten von Abfrageabsichten (prozedural, faktisch - Klassifizierung, investigativ; …) |
Schritt 5: Führen Sie das Experiment durch.
Führen Sie das Experiment durch, indem Sie Antworten sowohl vom bestehenden Agenten als auch von der modifizierten Version gegen den Evaluierungsdatensatz generieren. Berechnen Sie Kennzahlen wie Faktentreue (siehe Schritt 2).
Wir kombinieren verschiedene Auswertungen auf Basis der in Schritt 2 geforderten Kennzahlen:
- Regelbasierte Auswertung (z. B. (mit Python/TypeScript prüfen, ob die .json-Datei gültig ist)
- LLM als Richter (Befragung eines anderen LLM, ob eine Antwort sachlich mit einem Quelldokument übereinstimmt)
- Menschliche Beteiligung an der Qualitätsprüfung zur Feinabstimmung

Dies ist ein Beispiel für ein Auswertungsergebnis, das von unserem internen Framework generiert wurde. Es werden verschiedene Kennzahlen aus einem Experiment vorgestellt, das mit unterschiedlichen Datensätzen durchgeführt wurde.
Schritt 6: Ergebnisse analysieren + wiederholen
Nachdem wir nun die Kennzahlen haben, analysieren wir die Ergebnisse. Auch wenn die Ergebnisse die in Schritt 3 definierten Erfolgskriterien erfüllen, werden wir vor der Übernahme der Änderung in die Produktionsumgebung noch eine manuelle Überprüfung durchführen; wenn die Ergebnisse die Kriterien nicht erfüllen, werden die Probleme behoben und anschließend die Auswertungen der neuen Änderung durchgeführt.
Wir gehen davon aus, dass einige Iterationen nötig sein werden, um die beste Änderung vor dem Zusammenführen zu finden. Ähnlich wie bei der Durchführung lokaler Softwaretests vor dem Pushen eines Commits können Offline-Evaluierungen mit lokalen Änderungen oder mehreren vorgeschlagenen Änderungen durchgeführt werden. Es ist hilfreich, das Speichern von Experimentergebnissen, Gesamtergebnissen und Visualisierungen zu automatisieren, um die Analyse zu optimieren.
Schritt 7: Treffen Sie eine Entscheidung und dokumentieren Sie diese.
Auf Basis eines Entscheidungsrahmens und Akzeptanzkriterien wird über die Übernahme der Änderung entschieden und das Experiment dokumentiert. Die Entscheidungsfindung ist vielschichtig und kann Faktoren berücksichtigen, die über den Auswertungsdatensatz hinausgehen, wie z. B. die Prüfung auf Regressionsszenarien in anderen Datensätzen oder die Abwägung des Kosten-Nutzen-Verhältnisses einer vorgeschlagenen Änderung.
Beispiel: Nach dem Testen und Vergleichen einiger Iterationen wählen Sie die Änderung mit der höchsten Punktzahl aus und senden sie zur Genehmigung an Produktmanager und andere relevante Stakeholder. Fügen Sie die Ergebnisse der vorherigen Schritte bei, um die Entscheidungsfindung zu erleichtern. Weitere Beispiele zum Thema Angriffserkennung finden Sie unter Hinter den Kulissen der generativen KI-Funktionen von Elastic Security.
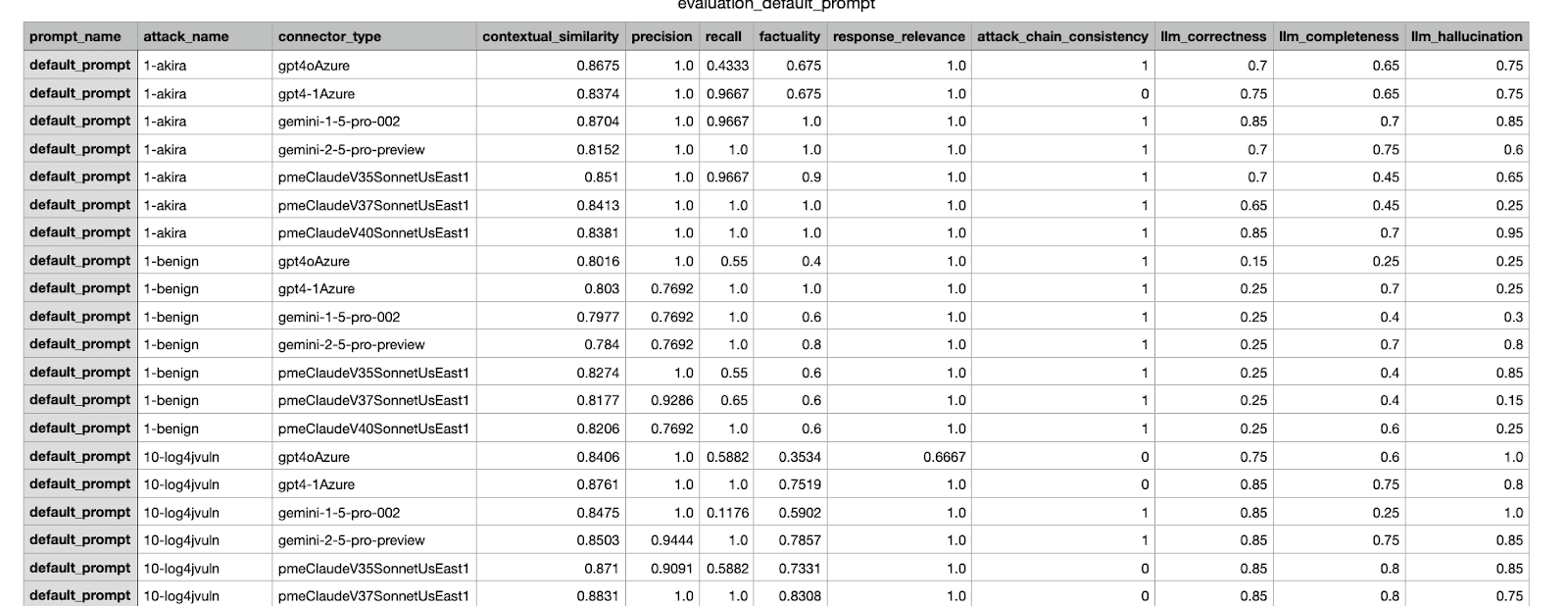
Beispiel eines an die Stakeholder versandten CSV-Berichts; das Experiment mit der höchsten Punktzahl wurde zur Zusammenführung ausgewählt.
Fazit
In diesem Blog haben wir den gesamten Ablauf eines Experiment-Workflows durchlaufen und veranschaulicht, wie wir Änderungen an einem agentenbasierten System bewerten und testen, bevor wir sie für Elastic-Benutzer freigeben. Wir haben auch einige Beispiele für die Verbesserung agentenbasierter Arbeitsabläufe in Elastic vorgestellt. In nachfolgenden Blogbeiträgen werden wir die Details verschiedener Schritte genauer erläutern, beispielsweise wie man einen guten Datensatz erstellt, wie man zuverlässige Metriken entwirft und wie man Entscheidungen trifft, wenn mehrere Metriken involviert sind.
Zugehörige Inhalte

Beschreiben statt zeichnen: KI-native Kibana-Dashboards über MCP und ES|QL
Vom Prompt zum Dashboard. Erfahren Sie, wie Sie Kibana-Dashboards in natürlicher Sprache mit example-mcp-dashbuilder erstellen: eine Open-Source-MCP-Anwendung, die ES|QL-Abfragen schreibt, interaktive Diagramme erstellt und voll funktionsfähige Dashboards direkt in Kibana exportiert.

8. April 2026
So erstellen Sie agentische KI-Anwendungen mit Mastra und Elasticsearch
Lernen Sie anhand eines praktischen Beispiels, wie Sie agentische KI-Anwendungen mit Mastra und Elasticsearch erstellen.

25. März 2026
Das Shell-Tool ist kein Allheilmittel für Kontext-Engineering
Erfahren Sie, welche Tools zur Kontextsuche für das Kontext-Engineering existieren, wie sie funktionieren und welche Nachteile sie mit sich bringen.

23. März 2026
Die Verwendung der Elasticsearch Inference API zusammen mit Hugging Face-Modellen
Erfahren Sie, wie Sie Elasticsearch mithilfe von Inferenz-Endpoints mit Hugging Face Modellen verbinden und ein mehrsprachiges Blog-Empfehlungssystem mit semantischer Suche und Chat-Abschlüssen erstellen.

27. März 2026
Erstellung eines Elasticsearch MCP-Servers mit TypeScript
Erfahren Sie, wie Sie mit TypeScript und Claude Desktop einen Elasticsearch MCP-Server erstellen.