Try out vector search for yourself using this self-paced hands-on learning for Search AI. You can start a free cloud trial or try Elastic on your local machine now.
This guide explores strategies for using semantic reranking to boost the relevance of top search results, including as direct inference call, in the context of a search experience, or as part of a simplified search flow with retrievers. Before diving into the details, let's explain what semantic reranking is and why it is important.
What is semantic reranking?
Semantic reranking is a method that allows us to utilize the speed and efficiency of fast retrieval methods while layering semantic search on top of it. It also lets us immediately add semantic search capabilities to existing Elasticsearch installations out there.
With the advancement of machine learning-powered semantic search we have more and more tools at our disposal for finding matches quickly from millions of documents. However, like cramming for a final exam, optimizing for speed means making some tradeoffs, and that usually comes at a loss in fidelity.
To offset this, we see some tools emerging and becoming increasingly available on the other side of the gradient. These are much slower, but can tell how closely a document matches a query with much more accuracy.

To explain some key terms: reranking is the process of reordering a set of retrieved documents in order to improve search relevance. In semantic reranking this is done with the help of a reranker machine learning model, which calculates a relevance score between the input query and each document.
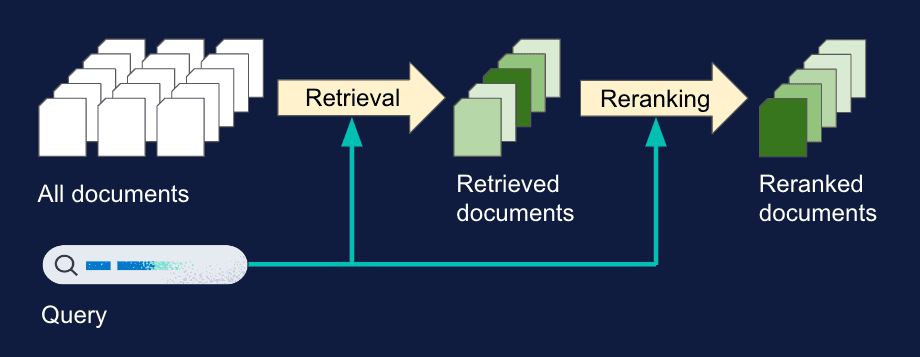
Rerankers typically operate on the top K results, a narrowed-down window of relevant candidates fulfilling the search query, since reranking a large list of documents would be extremely costly.
Why is semantic reranking important?
Semantic reranking is an important refinement layer for search users for a couple of reasons.
First, users are expecting more from their search, where the right result isn't in the top ten hits or in the first page, but is the top answer. It's like that old search joke - the best place to hide a secret is in the second page of search results. Except today it's even more narrow: anything below the top one, two, or maybe three results will likely get discarded.
This applies even more so for RAG (Retrieval Augmented Generation) - those Generative AI use cases need a tight context window. The best document could be the 4th result, but if you're only feeding in the top three, you aren't going to get the right answer, and the model could hallucinate.
On top of that, Generative AI use cases work best with an effective cutoff. You could define a minimum score or count up to which the results are considered "good", but this is hard to do without consistent scoring.
Semantic reranking solves these problems by reordering the documents so that the most relevant ones come out on top. It provides usable, normalized and well-calibrated scores, so you can measure how closely your results match your query. So you more reliably get much more accurate top results to feed to your large language model, and you can cut off results if there's a big dropoff in score in the top K hits to prevent hallucinations.
How do we perform semantic reranking?
The
Elastic recently introduced inference endpoints and related APIs. This feature allows us to use certain services, such as built-in or 3rd party machine learning models, to perform inference tasks. Supported inference tasks come in various shapes - for example a sparse_embedding task is where an ML model (such as ELSER) receives some text and generates a weighted set of terms, whereas a text_embedding task creates vector embeddings from the input.
Elastic Serverless - and the upcoming 8.14 release - adds a new task type: rerank. In the first iteration rerank supports integrating with Cohere's Rerank API. This means you can now create an inference endpoint in Elastic, supply your Cohere API key, and enjoy semantic reranking out of the box!
Let's see that in action with an example taken from the Cohere blog.
Assuming you have set up your rerank inference endpoint in Elastic with the Cohere Rerank v3 model, we can pass a query and an array of input text. As we can see, the short passages all relate to the word "capital", but not necessarily to the meaning of the location of the seat of government, which is what the query is looking for:
The rerank task responds with an array of scores and document indices:
The topmost entry tells us that the highest relevance score of 99.8% is the 4th document ("index": 3 with zero-based indexing) of the original list, a.k.a. "Washington, D.C. ...". The rest of the documents are semantically less relevant to the original query.
This reranking inference step is an important puzzle piece of an optimized search experience, and now we are ready to place it in the puzzle board!
Reranking search results today - through your application
One way of harnessing the power of semantic reranking is to implement a workflow like this in a search application:
- A user enters a query in your app's UI.
- The search engine component retrieves a set of documents that match this query. This can be done using any retrieval strategy: lexical (BM25), vector search (e.g. kNN) or a method that combines the two, such as RRF.
- The application takes the top K documents, extracts the text field we are querying against from each document, then sends this list of texts to the
rerankinference endpoint, which is configured to use Cohere. - The inference endpoint passes the documents and the query to Cohere.
- The result is a list of scores and indices to match each score. Your app takes these scores, assigns them to the documents, and reorders them by this score in a descending order. This effectively moves the semantically most relevant documents to the top.
- If this flow is used in RAG to provide some sources to a generative LLM (such as summarizing an answer), then you can rest assured it will work with the right context and provide answer.

This works great, but it involves many steps, data massaging, and a complex processing logic with many moving parts. Can we simplify this?
Reranking search results tomorrow - with retrievers
Let's spend a minute talking about retrievers. Retriever is a new type of abstraction in the _search API, which is more than just a simple query. It's a building block for an end-to-end search flow for fetching hits and potentially modifying the documents' scores and their order.
Retrievers can be used in a pipeline pattern, where each retriever unit does something different in the search process. For example we can configure a first-stage retriever to fetch documents, pass the results to a second-stage retriever to combine with other results, trim the number of candidates etc. As a final stage, a retriever can update the relevance score of documents.
Soon we'll be adding new reranking capabilities with retrievers, text similarity reranker retriever being the first one. This will perform reranking on top K hits by calling a rerank inference endpoint. The workflow will be simplified into a single API call that hides all the complexity!
This is what the previously described multi-stage workflow looks like as a single retriever query:

The text_similarity_reranker retriever is configured with the following details:
- Nested retriever
- Reranker inference configuration
- Additional controls, such as minimum score cutoff for eliminating irrelevant hits
Below is an example text_similarity_reranker query. Let's dissect it to understand each part better!
The request defines a retriever query as the root property. The outermost retriever will execute last, in this case it's a text_similarity_reranker. It specifies a standard first-stage retriever, which is responsible for fetching some documents. The standard retriever accepts an Elasticsearch query, which is a BM25 match in the example.
The text similarity reranker is pointed at the text document field that contains the text for semantic reranking. The top 100 documents will be sent for reranking to the cohere-rerank-v3-model rerank inference endpoint we have configured with Cohere. Only those documents will be returned that receive at least 60% relevance score in the reranking process.
The response is the exact same structure as that of a search query. The _score property is the semantic relevance score from the reranking process, and _rank refers to the ranking order of documents.
Semantic reranking with retrievers will be available shortly in a coming Elastic release.
Conclusion
Semantic reranking is an incredibly powerful tool for boosting the performance of a search experience or a RAG tool. It can be used as direct inference call, in context of a search experience, or as part of a simplified search flow with retrievers. Users can pick and choose the set of tools that work best for their use case and context.
Happy reranking! 😃
Frequently Asked Questions
What is semantic reranking in Elasticsearch?
Semantic reranking is a method that allows us to utilize the speed and efficiency of fast retrieval methods while layering semantic search on top of it. It also lets us immediately add semantic search capabilities to existing Elasticsearch installations.
Related Content
56% faster, up to 50% better retrieval performance: What's inside Jina's new 600 million parameter listwise reranker
Jina Reranker 3.5 beats v3 by 50%+ on case law, closes the gap with models 7x its size on legal, medical, and financial benchmarks, and beats them outright on structured data. It's a drop-in replacement for v3, with no API changes.
July 20, 2026
AI shopping agents: Why context comes before the query
AI shopping agents that guess at your vocabulary make expensive mistakes. Pre-computed catalog context stops the guessing before the first tool call.

July 16, 2026
A picture is worth 1.5x the words: What we learned benchmarking product search embeddings
We benchmarked two embedding models on 5,000 real products and found that combining image and text beats either alone by up to 50%. Here's the data and the model that won.

July 13, 2026
The disk that never woke up: what actually decided our Qdrant vector search benchmark rematch
On the same hardware, Elasticsearch and Qdrant land in the same range at 56 QPS. The io_uring disk scorer and memory claims turned out to be the two things that mattered least.

July 21, 2026
4 NVIDIA AI tasks, 1 Elasticsearch API: Embeddings, chat, completion, and rerank
Set up NVIDIA hosted models in Elasticsearch with one API key and a model ID. No custom integration code needed.