Agentic RAG with Elasticsearch & Langchain
Discussing Agentic RAG and implementing an agentic flow where the LLM chooses to call an Elastic KB.
Agentic RAG introduction
Agents are the logical next step in the application of LLMs for real-world use-cases. This article aims to introduce the concept and usage of agents for RAG workflows. All in all, agents represent an extremely exciting area, with many possibilities for ambitious applications and use-cases.
I'm hoping to cover more of those ideas in future articles. For now, let's see how Agentic RAG can be implemented using Elasticsearch as our knowledge base, and langchain as our agentic framework.
Background
The use of LLMs began with simply prompting an LLM to perform tasks such as answering questions and simple calculations.
However, deficiencies in existing model knowledge meant that LLMs could not be applied to domains which required specialist skills, such as enterprise customer servicing and business intelligence.
Soon, prompting transitioned to Retrieval Augmented Generation (RAG), a natural sweet spot for Elasticsearch. RAG emerged as an effective and simple way to quickly provide contextual and factual information to an LLM at query time. The alternative is lengthy and very costly retraining processes where success is far from guaranteed.
The main operational advantage of RAG is allowing for an LLM app to be fed with updated information on a near real-time basis.
Implementation is a matter of procuring a vector database, such as Elasticsearch, deploying an embedding model such as ELSER, and making a call to the search API to retrieve relevant documents.
Once documents are retrieved, they can be inserted into the LLM's prompt, and answers generated based on the content. This provides context and factuality, both of which the LLM may lack on its own.
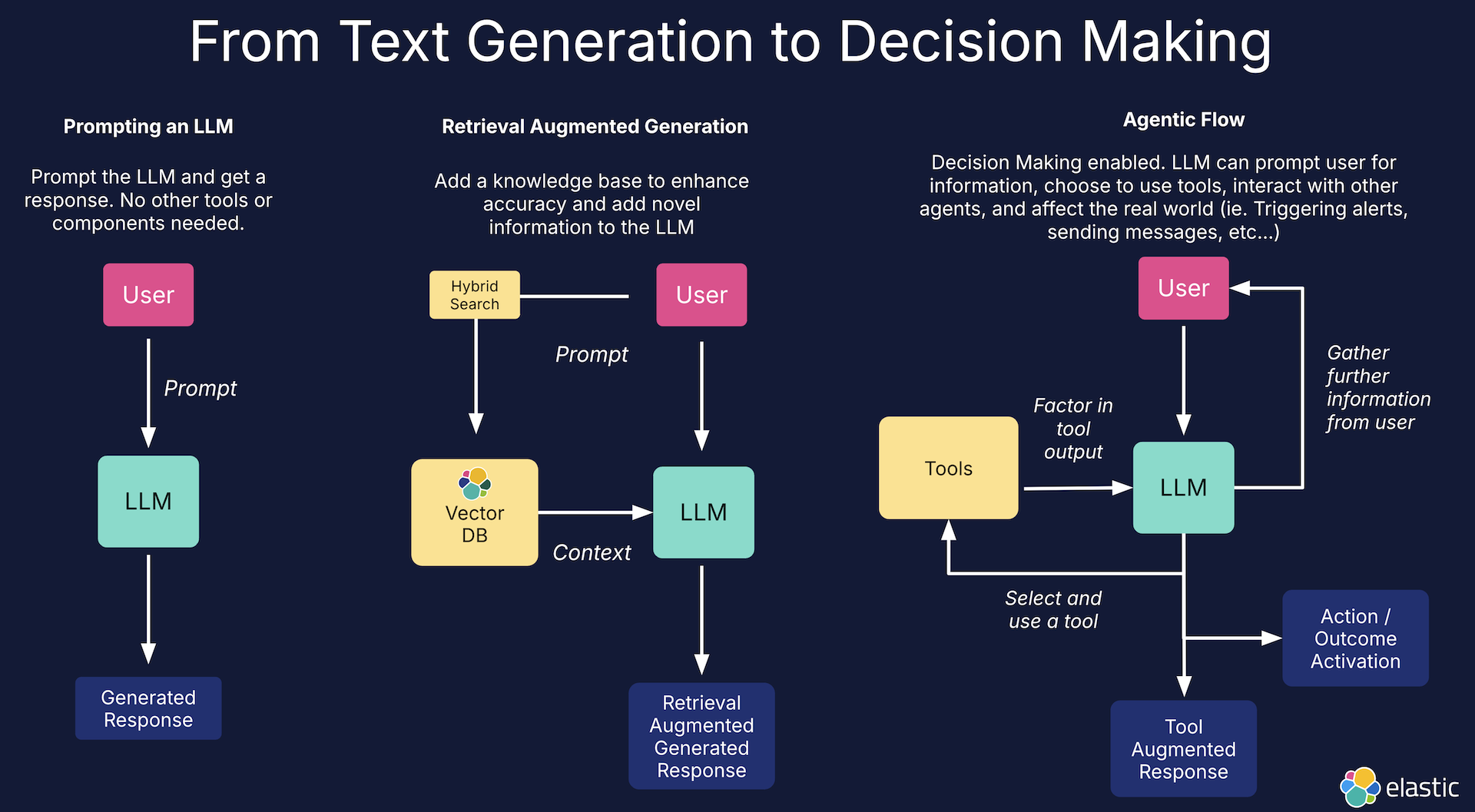
The difference between simply calling an LLM, using RAG, and using Agents
However, the standard RAG deployment model has a disadvantage - It is rigid. The LLM cannot choose which knowledge base it will draw information from. It also cannot choose to use additional tools, such as web search engine APIs like Google or Bing. It cannot check the current weather, or use a calculator, or factor in the output of any tool beyond the knowledge base it has been given.
What differentiates the Agentic model is Choice.
Note on terminology
Tool usage, which is the term used in a Langchain context is also known as function-calling. For all intents and purposes, the terms are interchangeable - Both refer to the LLM being given a set of functions or tools which it can use to complement its capabilities or affect the world. Please bear with me, as I use "Tool Usage" throughout the rest of this article.
Choice & agentic models
Give the LLM the ability to make decisions, and give it a set of tools. Based on the state and history of the conversation, the LLM will choose whether or not to use each tool, and it will factor in the output of the tool into its responses.
These tools may be knowledge bases, or calculators, or web search engines and crawlers - There is no limitation or end to the variety. The LLM becomes capable of complex actions and tasks, beyond just generating text.
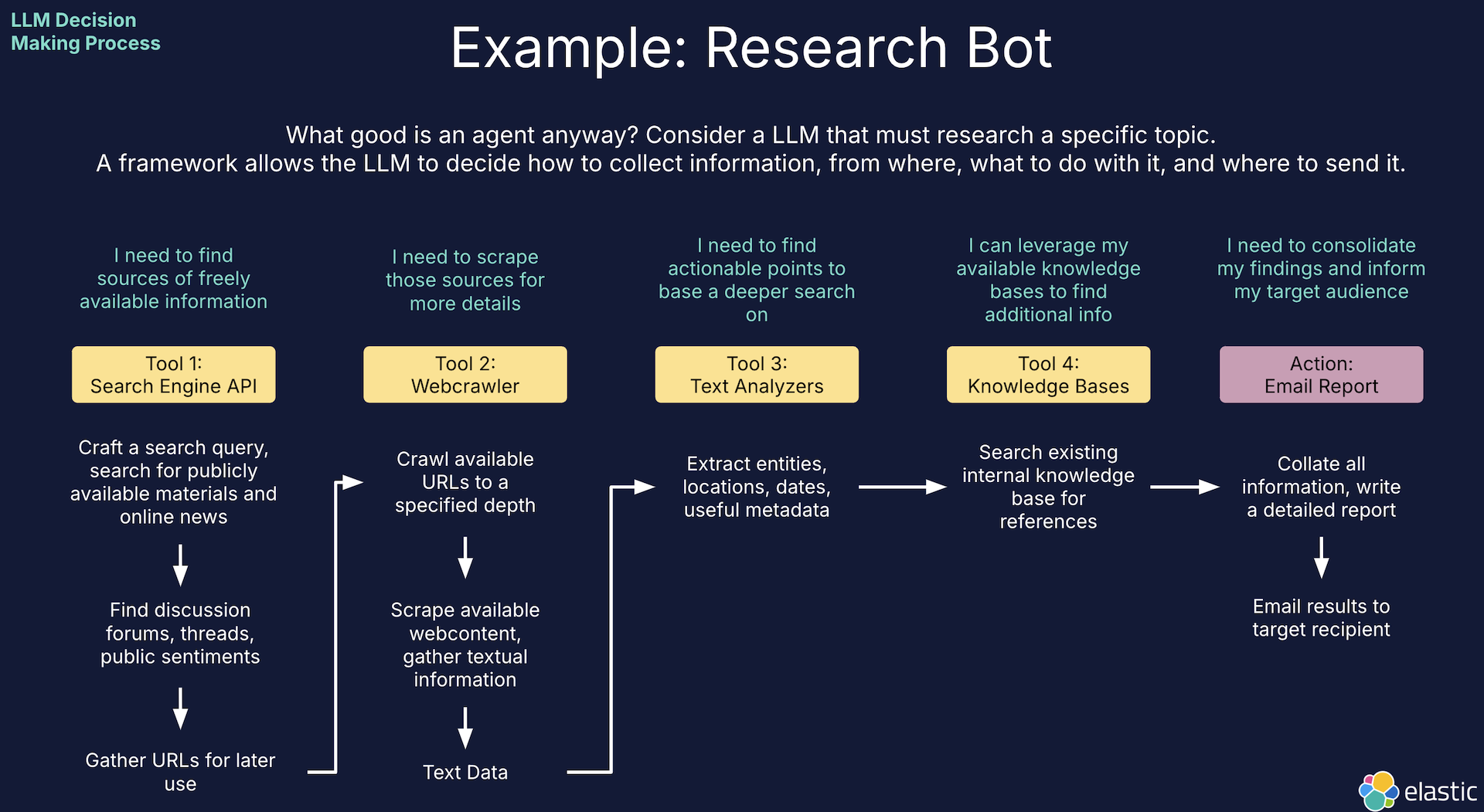
An example of an agentic flow for researching a specific topic
Let's implement a simple example of an agent. The core strength of Elastic is in our knowledge bases. So this example will focus on using a relatively large and complex knowledge base by crafting a more complicated query than just simple vector search.
Set-up
First, define a .env file in your project directory, and fill in these fields. I'm using an Azure OpenAI deployment with GPT-4o for my LLM, and an Elastic Cloud deployment for my knowledge base. My python version is python 3.12.4, and am working off my Macbook.
ELASTIC_ENDPOINT="YOUR ELASTIC ENDPOINT"
ELASTIC_API_KEY="YOUR ELASTIC API KEY"
OPENAI_API_TYPE="azure"
AZURE_OPENAI_ENDPOINT="YOUR AZURE ENDPOINT"
AZURE_OPENAI_API_VERSION="2024-06-01"
AZURE_OPENAI_API_KEY="YOUR AZURE API KEY"
AZURE_OPENAI_GPT4O_MODEL_NAME="gpt-4o"
AZURE_OPENAI_GPT4O_DEPLOYMENT_NAME="YOUR AZURE OPENAI GPT-4o DEPLOYMENT NAME"You may have to install the following dependencies in your terminal.
pip install langchain elasticsearchCreate a python file called chat.py in your project directory, and paste in this snippet to initalize your LLM and connection to Elastic Cloud:
import os
from dotenv import load_dotenv
load_dotenv()
from langchain.chat_models import AzureChatOpenAI
from langchain.agents import initialize_agent, AgentType, Tool
from langchain.tools import StructuredTool # Import StructuredTool
from langchain.memory import ConversationBufferMemory
from typing import Optional
from pydantic import BaseModel, Field
# LLM setup
llm = AzureChatOpenAI(
openai_api_version=os.getenv("AZURE_OPENAI_API_VERSION"),
azure_deployment=os.getenv("AZURE_OPENAI_GPT4O_DEPLOYMENT_NAME"),
temperature=0.5,
max_tokens=4096
)
from elasticsearch import Elasticsearch
# Elasticsearch Setup
try:
# Elasticsearch setup
es_endpoint = os.environ.get("ELASTIC_ENDPOINT")
es_client = Elasticsearch(
es_endpoint,
api_key=os.environ.get("ELASTIC_API_KEY")
)
except Exception as e:
es_client = NoneHello world! Our first tool
With our LLM and Elastic client initialized and defined, let's do an Elastic-fied version of Hello World. We'll define a function to check the status of our connection to Elastic Cloud, and a simple agent conversational chain to call it.
Define the following function as a langchain Tool. The name and description are a crucial part of your prompt engineering. The LLM rely on them to determine whether or not to make use of the tool during conversation.
# Define a function to check ES status
def es_ping(*args, **kwargs):
if es_client is None:
return "ES client is not initialized."
else:
try:
if es_client.ping():
return "ES ping returning True, ES is connected."
else:
return "ES is not connected."
except Exception as e:
return f"Error pinging ES: {e}"
es_status_tool = Tool(
name="ES Status",
func=es_ping,
description="Checks if Elasticsearch is connected.",
)
tools = [es_status_tool]Now, let's initialize a conversational memory component to keep track of the conversation, as well as our agent itself.
# Initialize memory to keep track of the conversation
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
# Initialize agent
agent_chain = initialize_agent(
tools,
llm,
agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION,
memory=memory,
verbose=True,
)Finally, let's run the conversation loop with this snippet:
# Interactive conversation with the agent
def main():
print("Welcome to the chat agent. Type 'exit' to quit.")
while True:
user_input = input("You: ")
if user_input.lower() in ['exit', 'quit']:
print("Goodbye!")
break
response = agent_chain.run(input=user_input)
print("Assistant:", response)
if __name__ == "__main__":
main()In your terminal, run python chat.py to initialize the conversation. Here's how mine went:
You: Hello
Assistant: Hello! How can I assist you today?
You: Is Elastic search connected?
> Entering new AgentExecutor chain...
Thought: Do I need to use a tool? Yes
Action: ES Status
Action Input:
Observation: ES ping returning True, ES is connected.
Thought:Do I need to use a tool? No
AI: Yes, Elasticsearch is connected. How can I assist you further?When I asked if Elasticsearch was connected, the LLM used the ES Status tool, pinged my Elastic Cloud deployment, got back True, and then confirmed that Elastic Cloud was indeed connected.
Congratulations! That is a successful Hello World :)
Note that the observation is the output of the es_ping function. The format and content of this observation is a key part of our prompt engineering, because this is what the LLM uses to decide its next step.
Let's see how this tool can be modified for RAG.
Agentic RAG
I recently built a large and complex knowledge base in my Elastic Cloud deployment, using the POLITICS dataset. This dataset contains roughly 2.46 Million political articles scraped from US news sources. I ingested it to Elastic Cloud and embedded it with an elser_v2 inference endpoint, following the process defined in this previous blog.
To deploy an elser_v2 inference endpoint, ensure that ML node autoscaling is enabled, and run the following command in your Elastic Cloud console.
PUT _inference/sparse_embedding/elser_v2
{
"service": "elser",
"service_settings": {
"num_allocations": 4,
"num_threads": 8
}
}Now, let's define a new tool that does a simple semantic_search on over our political knowledge base index. I called it bignews_embedded. This function takes a search query, adds it to a standard semantic_search query template, and runs the query with Elasticsearch. Once it has the search results, it concatenates the article contents into a single block of text, and returns it as an LLM observation.
We'll limit the number of search results to 3. One advantage of this style of Agentic RAG is that we can develop an answer over multiple conversation steps. In other words, more complex queries can be answered by using leading questions to set the stage and context. Question and Answer becomes a fact-based conversation rather than one-off answer generation.
Dates
In order to highlight an important advantage of using an agent, the RAG search function includes a dates argument in addition to a query. When searching for news articles, we probably want to constrain the search results to specific timeframe, like "In 2020" or "Between 2008 and 2012". By adding dates, along with a parser, we allow the LLM to specify a date range for the search.
In short, if I specify something like "California wildfires in 2020", I do not expect to see news from 2017 or any other year.
This rag_search function is a date parser (Extracting dates from the input and adding it to the query), and an Elastic semantic_search query.
# Define the RAG search function
def rag_search(query: str, dates: str):
if es_client is None:
return "ES client is not initialized."
else:
try:
# Build the Elasticsearch query
must_clauses = []
# If dates are provided, parse and include in query
if dates:
# Dates must be in format 'YYYY-MM-DD' or 'YYYY-MM-DD to YYYY-MM-DD'
date_parts = dates.strip().split(' to ')
if len(date_parts) == 1:
# Single date
start_date = date_parts[0]
end_date = date_parts[0]
elif len(date_parts) == 2:
start_date = date_parts[0]
end_date = date_parts[1]
else:
return "Invalid date format. Please use YYYY-MM-DD or YYYY-MM-DD to YYYY-MM-DD."
date_range = {
"range": {
"date": {
"gte": start_date,
"lte": end_date
}
}
}
must_clauses.append(date_range)
# Add the main query clause
main_query = {
"nested": {
"path": "text.inference.chunks",
"query": {
"sparse_vector": {
"inference_id": "elser_v2",
"field": "text.inference.chunks.embeddings",
"query": query
}
},
"inner_hits": {
"size": 2,
"name": "bignews_embedded.text",
"_source": False
}
}
}
must_clauses.append(main_query)
es_query = {
"_source": ["text.text", "title", "date"],
"query": {
"bool": {
"must": must_clauses
}
},
"size": 3
}
response = es_client.search(index="bignews_embedded", body=es_query)
hits = response["hits"]["hits"]
if not hits:
return "No articles found for your query."
result_docs = []
for hit in hits:
source = hit["_source"]
title = source.get("title", "No Title")
text_content = source.get("text", {}).get("text", "")
date = source.get("date", "No Date")
doc = f"Title: {title}\nDate: {date}\n{text_content}\n"
result_docs.append(doc)
return "\n".join(result_docs)
except Exception as e:
return f"Error during RAG search: {e}"After running the complete search query, the results are concatenated into a block of text and returned as an 'observation' for the LLM to use.
To account for multiple possible arguments, use pydantic's BaseModel to define a valid input format:
class RagSearchInput(BaseModel):
query: str = Field(..., description="The search query for the knowledge base.")
dates: str = Field(
...,
description="Date or date range for filtering results. Specify in format YYYY-MM-DD or YYYY-MM-DD to YYYY-MM-DD."
)We also need to make use of StructuredTool to define a multi-input function, using the input format defined above:
# Define the RAG search tool using StructuredTool
rag_search_tool = StructuredTool(
name="RAG_Search",
func=rag_search,
description=(
"Use this tool to search for information about American politics from the knowledge base. "
"**Input must include a search query and a date or date range.** "
"Dates must be specified in this format YYYY-MM-DD or YYYY-MM-DD to YYYY-MM-DD."
),
args_schema=RagSearchInput
)The description is a critical element of the tool definition, and is part of your prompt engineering. It should be comprehensive and detailed, and provide sufficient context to the LLM, such that it knows when to use the tool, and for what purpose.
The description should also include the types of inputs that the LLM must provide in order to use the tool properly. Specifying the formats and expectations has a huge impact here.
Uninformative descriptions can have a serious impact on the LLM's ability to use the tool!
Remember to add the new tool to the list of tools for the agent to use:
tools = [es_status_tool, rag_search_tool]We also need to further modify the agent with a system prompt, providing additional control over the agent's behavior. The system prompt is crucial for ensuring that errors related to malformed outputs and function inputs do not occur. We need to explicitly state what each function expects, and what the model should output, because langchain will throw an error if it sees improperly formatted LLM responses.
We also need to set agent=AgentType.OPENAI_FUNCTIONS to use OpenAI's function callingt capability. This allows the LLM to interact with the function according to the structured templates we specified.
Note that the system prompt includes a prescription on the exact format of input that the LLM should generate, as well as a concrete example.
The LLM should detect not just which tool should be used, but also what input the tool expects! Langchain only takes care of function invocation/tool use, but it's up to the LLM to use it properly.
agent_chain = initialize_agent(
tools,
llm,
agent=AgentType.OPENAI_FUNCTIONS,
memory=memory,
verbose=True,
handle_parsing_errors=True,
system_message="""
You are an AI assistant that helps with questions about American politics using a knowledge base. Be concise, sharp, to the point, and respond in one paragraph.
You have access to the following tools:
- **ES_Status**: Checks if Elasticsearch is connected.
- **RAG_Search**: Use this to search for information in the knowledge base. **Input must include a search query and a date or date range.** Dates must be specified in this format YYYY-MM-DD or YYYY-MM-DD to YYYY-MM-DD.
**Important Instructions:**
- **Extract dates or date ranges from the user's question.**
- **If the user does not provide a date or date range, politely ask them to provide one before proceeding.**
When you decide to use a tool, use the following format *exactly*:
Thought: [Your thought process about what you need to do next]
Action: [The action to take, should be one of [ES_Status, RAG_Search]]
Action Input: {"query": "the search query", "dates": "the date or date range"}
If you receive an observation after an action, you should consider it and then decide your next step. If you have enough information to answer the user's question, respond with:
Thought: [Your thought process]
Assistant: [Your final answer to the user]
**Examples:**
- **User's Question:** "Tell me about the 2020 California wildfires."
Thought: I need to search for information about the 2020 California wildfires.
Action: RAG_Search
Action Input: {"query" : "California wildfires", "dates" : "2020-01-01 to 2020-12-31"}
- **User's Question:** "What happened during the presidential election?"
Thought: The user didn't specify a date. I should ask for a date range.
Assistant: Could you please specify the date or date range for the presidential election you're interested in?
Always ensure that your output strictly follows one of the above formats, and do not include any additional text or formatting.
Remember:
- **Do not** include any text before or after the specified format.
- **Do not** add extra explanations.
- **Do not** include markdown, bullet points, or numbered lists unless it is part of the Assistant's final answer.
Your goal is to assist the user by effectively using the tools when necessary and providing clear and concise answers.
"""
)Now, run python chat.py in your terminal and let's test it out!
Testing Agentic RAG
Let's test it by asking the following query:
Summarize the federal response to california wildfires in 2020Helpfully enough, langchain will output the intermediate steps, including the inputs to the RAG_Search function, the search results, and the final ouput.
> Entering new AgentExecutor chain...
Invoking: `RAG_Search` with `{'query': 'federal response to California wildfires', 'dates': '2020-01-01 to 2020-12-31'}`
Title: California federal wildfire aid: Newsom says Trump changed mind
Date: 2020-10-16T00:00:00.000Z
President Donald Trump abruptly changed course...
Title: California governor declares state of emergency in multiple counties as wildfires rage
Date: 2020-09-07T00:00:00.000Z
In a statement, Newsom noted that tens...
Title: Trump approves disaster declaration for California, reversing course
Date: 2020-10-16T00:00:00.000Z
California secured a Major Disaster Declaration ...
> Finished chain.
Assistant: The federal response to the California wildfires in 2020 included several key actions and moments:
1. **Initial Denial and Reversal of Federal Aid**: President Trump initially denied California's request for federal aid for the wildfires. However, after Governor Gavin Newsom vowed to appeal the decision, Trump reversed course and approved the Major Disaster Declaration. This declaration allowed California to receive hundreds of millions of dollars in federal aid.
2. **Statewide Emergency Declarations**: Governor Newsom declared a statewide emergency due to the widespread fires and extreme weather conditions. The state worked closely with federal authorities to secure assistance, including Fire Management Assistance Grants from FEMA.
3. **Presidential Major Disaster Declarations**: Newsom secured a Presidential Major Disaster Declaration to bolster the state's emergency response to the Northern California wildfires. This declaration made people in impacted counties eligible for various forms of federal support, including crisis counseling, housing, unemployment assistance, and legal services.
4. **Federal and State Collaboration**: Despite ongoing tensions and disagreements between the state and the Trump administration, particularly over forest management and climate change, federal agencies such as the National Park Service, U.S. Forest Service, and Bureau of Land Management were involved in managing and supporting firefighting efforts in California.
5. **Impact and Scale of Wildfires**: The 2020 wildfire season in California was historically devastating, with more than 8,500 blazes scorching 6,400 square miles, destroying thousands of structures, and claiming lives. The federal aid and disaster declarations were crucial in supporting the state's response and recovery efforts.
Overall, the federal response involved a combination of initial resistance followed by critical support and collaboration to address the unprecedented wildfire crisis in California.The most notable thing is that the LLM created a search query, then added a date range from the beginning to the end of 2020. By constraining the search results to the specified year, we ensured that only relevant documents would be passed to the LLM.
There's a lot more that we can do with this, such as constraining based on category, or the appearance of certain entities, or relation to other events.
The possibilities are endless, and I think that's pretty cool!
Error handling in Agentic RAG
There may be situations where the LLM fails to use the proper tool/function when it needs to. For example, it may choose to answer a question about current events using its own knowledge rather than using an available knowledge base.
Careful testing and tuning of both the system prompt and the tool/function description is necessary.
Another option might be to increase the variety of available tools, to increase the probability that an answer is generated based on knowledge base content rather than the LLM's innate knowledge.
Do note that LLMs will have occasional failures, as a natural consequence of their probabilistic nature. Helpful error messages or disclaimers might also be an important part of the user experience.
Conclusion and future prospects
For me, the main takeaway is the possibility of creating much more advanced search applications. The LLM might be able to craft very complex search queries on the fly, and within the context of a natural language conversation. This opens the way to drastically improving the accuracy and relevancy of search applications, and is an area that I'm excited to explore.
The interaction of knowledge bases with other tools, such as web search engines and monitoring tool APIs, through the medium of LLMs, could also enable some exciting and complex use-cases. Search results from KBs might be supplemented with live information, allowing LLMs to perform effective and time-sensitive on-the-fly reasoning.
There is also the possibility of multi-agent workflows. In an Elastic context, this might be multiple agents exploring different sets of knowledge bases to collaboratively build a solution to a complex problem. Perhaps a federated model of search where multiple organizations build collaborative, shared applications, similar to the idea of federated learning?
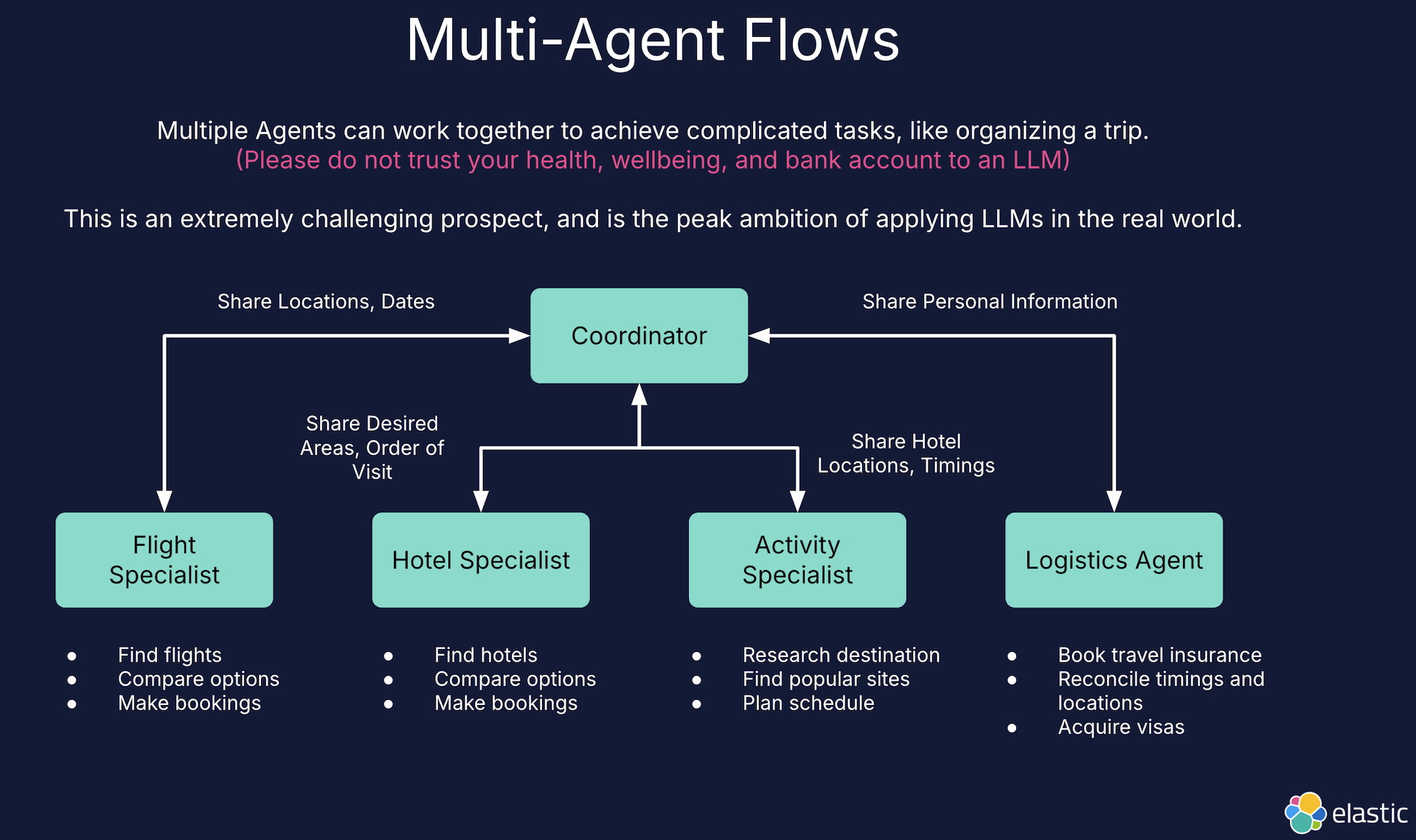
Example of a multi-agent flow
I'd like to explore some of these use-cases with Elasticsearch, and I hope you will as well.
Until next time!
Appendix: Full code for chat.py
import os
from dotenv import load_dotenv
load_dotenv()
from langchain.chat_models import AzureChatOpenAI
from langchain.agents import initialize_agent, AgentType, Tool
from langchain.tools import StructuredTool # Import StructuredTool
from langchain.memory import ConversationBufferMemory
from typing import Optional
from pydantic import BaseModel, Field
llm = AzureChatOpenAI(
openai_api_version=os.getenv("AZURE_OPENAI_API_VERSION"),
azure_deployment=os.getenv("AZURE_OPENAI_GPT4O_DEPLOYMENT_NAME"),
temperature=0.5,
max_tokens=4096
)
from elasticsearch import Elasticsearch
try:
# Elasticsearch setup
es_endpoint = os.environ.get("ELASTIC_ENDPOINT")
es_client = Elasticsearch(
es_endpoint,
api_key=os.environ.get("ELASTIC_API_KEY")
)
except Exception as e:
es_client = None
# Define a function to check ES status
def es_ping(_input):
if es_client is None:
return "ES client is not initialized."
else:
try:
if es_client.ping():
return "ES is connected."
else:
return "ES is not connected."
except Exception as e:
return f"Error pinging ES: {e}"
# Define the ES status tool
es_status_tool = Tool(
name="ES_Status",
func=es_ping,
description="Checks if Elasticsearch is connected.",
)
# Define the RAG search function
def rag_search(query: str, dates: str):
if es_client is None:
return "ES client is not initialized."
else:
try:
# Build the Elasticsearch query
must_clauses = []
# If dates are provided, parse and include in query
if dates:
# Dates must be in format 'YYYY-MM-DD' or 'YYYY-MM-DD to YYYY-MM-DD'
date_parts = dates.strip().split(' to ')
if len(date_parts) == 1:
# Single date
start_date = date_parts[0]
end_date = date_parts[0]
elif len(date_parts) == 2:
start_date = date_parts[0]
end_date = date_parts[1]
else:
return "Invalid date format. Please use YYYY-MM-DD or YYYY-MM-DD to YYYY-MM-DD."
date_range = {
"range": {
"date": {
"gte": start_date,
"lte": end_date
}
}
}
must_clauses.append(date_range)
# Add the main query clause
main_query = {
"nested": {
"path": "text.inference.chunks",
"query": {
"sparse_vector": {
"inference_id": "elser_v2",
"field": "text.inference.chunks.embeddings",
"query": query
}
},
"inner_hits": {
"size": 2,
"name": "bignews_embedded.text",
"_source": False
}
}
}
must_clauses.append(main_query)
es_query = {
"_source": ["text.text", "title", "date"],
"query": {
"bool": {
"must": must_clauses
}
},
"size": 3
}
response = es_client.search(index="bignews_embedded", body=es_query)
hits = response["hits"]["hits"]
if not hits:
return "No articles found for your query."
result_docs = []
for hit in hits:
source = hit["_source"]
title = source.get("title", "No Title")
text_content = source.get("text", {}).get("text", "")
date = source.get("date", "No Date")
doc = f"Title: {title}\nDate: {date}\n{text_content}\n"
result_docs.append(doc)
return "\n".join(result_docs)
except Exception as e:
return f"Error during RAG search: {e}"
class RagSearchInput(BaseModel):
query: str = Field(..., description="The search query for the knowledge base.")
dates: str = Field(
...,
description="Date or date range for filtering results. Specify in format YYYY-MM-DD or YYYY-MM-DD to YYYY-MM-DD."
)
# Define the RAG search tool using StructuredTool
rag_search_tool = StructuredTool(
name="RAG_Search",
func=rag_search,
description=(
"Use this tool to search for information about American politics from the knowledge base. "
"**Input must include a search query and a date or date range.** "
"Dates must be specified in this format YYYY-MM-DD or YYYY-MM-DD to YYYY-MM-DD."
),
args_schema=RagSearchInput
)
# List of tools
tools = [es_status_tool, rag_search_tool]
# Initialize memory to keep track of the conversation
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
agent_chain = initialize_agent(
tools,
llm,
agent=AgentType.OPENAI_FUNCTIONS,
memory=memory,
verbose=True,
handle_parsing_errors=True,
system_message="""
You are an AI assistant that helps with questions about American politics using a knowledge base. Be concise, sharp, to the point, and respond in one paragraph.
You have access to the following tools:
- **ES_Status**: Checks if Elasticsearch is connected.
- **RAG_Search**: Use this to search for information in the knowledge base. **Input must include a search query and a date or date range.** Dates must be specified in this format YYYY-MM-DD or YYYY-MM-DD to YYYY-MM-DD.
**Important Instructions:**
- **Extract dates or date ranges from the user's question.**
- **If the user does not provide a date or date range, politely ask them to provide one before proceeding.**
When you decide to use a tool, use the following format *exactly*:
Thought: [Your thought process about what you need to do next]
Action: [The action to take, should be one of [ES_Status, RAG_Search]]
Action Input: {"query": "the search query", "dates": "the date or date range"}
If you receive an observation after an action, you should consider it and then decide your next step. If you have enough information to answer the user's question, respond with:
Thought: [Your thought process]
Assistant: [Your final answer to the user]
**Examples:**
- **User's Question:** "Tell me about the 2020 California wildfires."
Thought: I need to search for information about the 2020 California wildfires.
Action: RAG_Search
Action Input: {"query": "California wildfires", "dates": "2020-01-01 to 2020-12-31"}
- **User's Question:** "What happened during the presidential election?"
Thought: The user didn't specify a date. I should ask for a date range.
Assistant: Could you please specify the date or date range for the presidential election you're interested in?
Always ensure that your output strictly follows one of the above formats, and do not include any additional text or formatting.
Remember:
- **Do not** include any text before or after the specified format.
- **Do not** add extra explanations.
- **Do not** include markdown, bullet points, or numbered lists unless it is part of the Assistant's final answer.
Your goal is to assist the user by effectively using the tools when necessary and providing clear and concise answers.
"""
)
# Interactive conversation with the agent
def main():
print("Welcome to the chat agent. Type 'exit' to quit.")
while True:
user_input = input("You: ")
if user_input.lower() in ['exit', 'quit']:
print("Goodbye!")
break
# Update method call to address deprecation warning
response = agent_chain.invoke(input=user_input)
print("Assistant:", response['output'])
if __name__ == "__main__":
main()Related Content