Test Elastic's leading-edge, out-of-the-box capabilities. Dive into our sample notebooks in the Elasticsearch Labs repo, start a free cloud trial, or try Elastic on your local machine now.
Replicas are essential to Elasticsearch: they provide high availability and help scale out search workloads. But like any distributed system, too much redundancy can become counterproductive. Excessive replica counts magnify write load, increase shard overhead, exhaust filesystem cache, elevate heap pressure, and can destabilize a cluster.
This article explains why excessive replica counts can cause severe performance degradation, how to diagnose the symptoms, and how right-sizing replica counts restored stability in a real large-scale customer deployment.
The role of replicas in Elasticsearch
Replicas in Elasticsearch serve two primary purposes:
- High availability: If a node fails, replicas ensure data remains available.
- Search scalability: Replicas allow Elasticsearch to distribute search load across multiple nodes.
However, each replica is a full physical copy of its primary shard, and every write must be applied to every replica. Replicas provide resilience, but they can also consume CPU, heap, filesystem cache, disk I/O, cluster state bandwidth, and recovery bandwidth. Replicas are powerful, but they are not free.
When high replica counts can make sense
There is a narrow set of scenarios where high replica counts genuinely improve performance:
- The cluster contains a small amount of extremely hot data where the working set fits into RAM on every node.
- The cluster is intentionally overprovisioned.
- The data is infrequently written or updated.
In this scenario, replicas help utilize all nodes effectively, maximizing CPU utilization and cache efficiency.
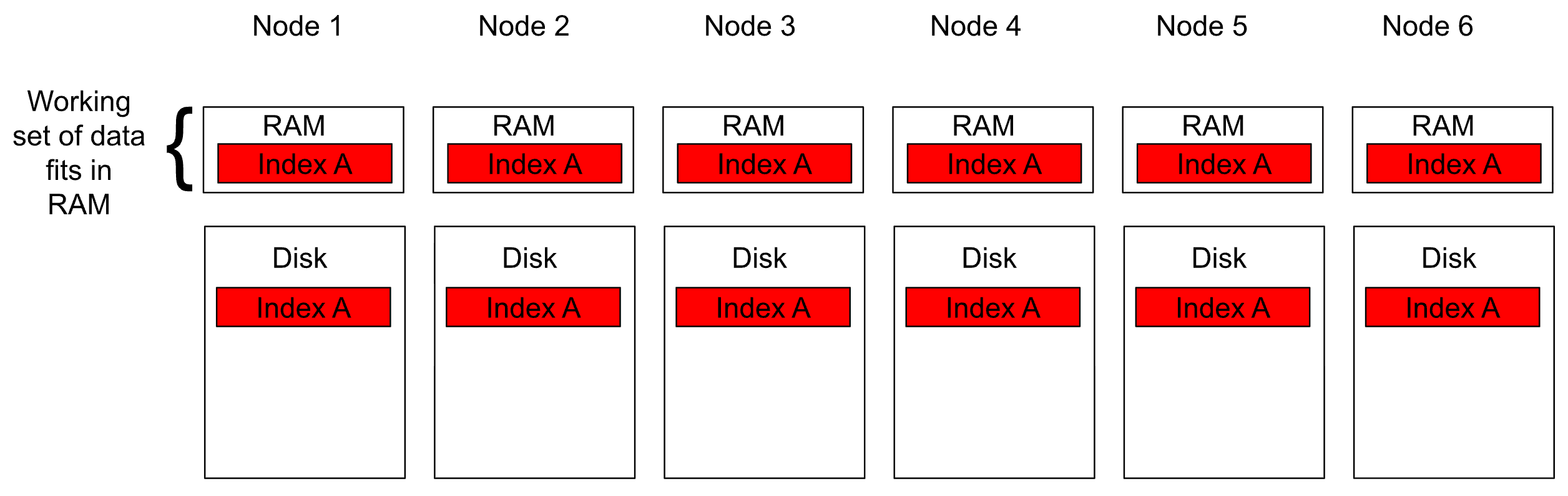
Diagram 1: High replica counts benefit a single, small, hot data set (one or more indices) that fits into RAM on all nodes. All queries hit cached data and throughput scales efficiently.
The reality in large, multi-index clusters
Most production environments contain many indices, diverse workloads, variable shard sizes, and mixed read/write patterns. In these settings, high replica counts introduce compounding issues that can severely degrade performance.
Cache thrashing and memory pressure
Every shard copy competes for limited filesystem cache. With excessive replicas:
- The working set grows beyond RAM capacity
- Nodes are forced to read from disk for routine queries
- Useful cached pages are constantly evicted, which causes “cache churn”. Cache hit rates collapse
- Latency becomes unpredictable
When multiple indices compete for the same finite memory, the cost of serving a single query increases dramatically because the shard data needed for that query is not in RAM.
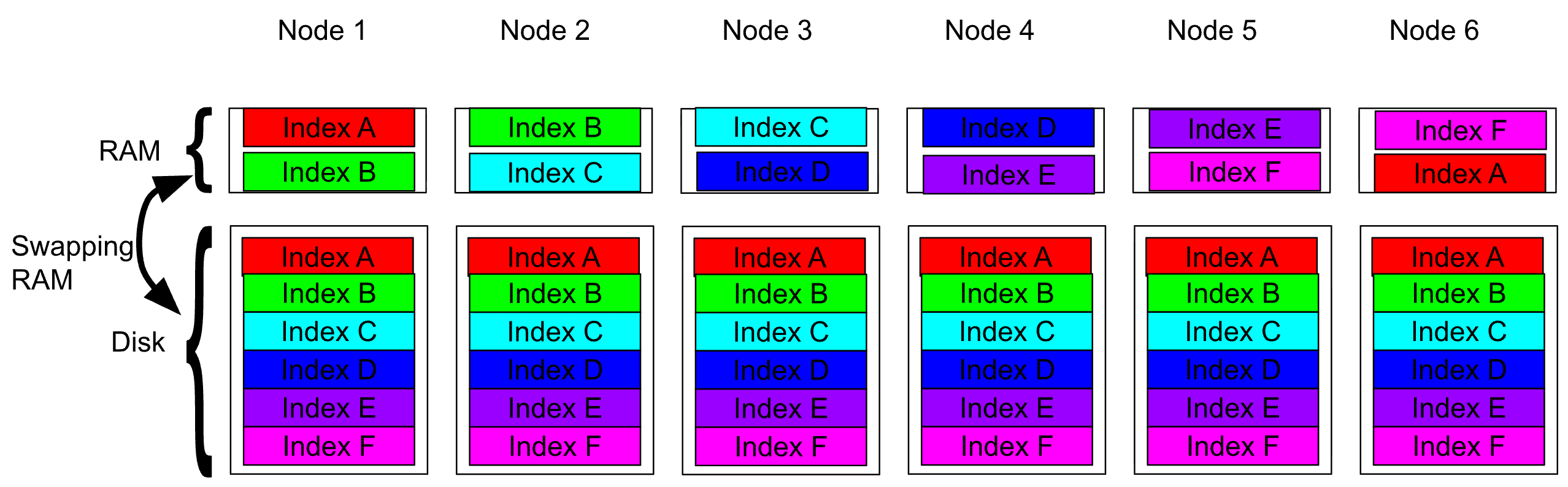
Diagram 2: In clusters with many indices and excessive replicas, shards compete for limited RAM and heap, causing frequent cache evictions and memory pressure.
Note: This diagram is conceptual. In practice, nodes hold interleaved fragments of many shards in filesystem cache, but the underlying principle remains the same as what is illustrated in the diagram.
Write amplification
If an index has 5 replicas, a single document write becomes 6 independent writes, each with its own merge cycles, segment management, and I/O cost. This directly increases:
- Disk utilization
- Indexing latency
- Merge pressure
- Threadpool saturation
- Backpressure and retry load
Indexing throughput may become unsustainable with high replica counts. The diagram illustrates how an update to a single index with 5 replicas results in a write operation on every node hosting a shard copy, in this example all six nodes in the cluster.
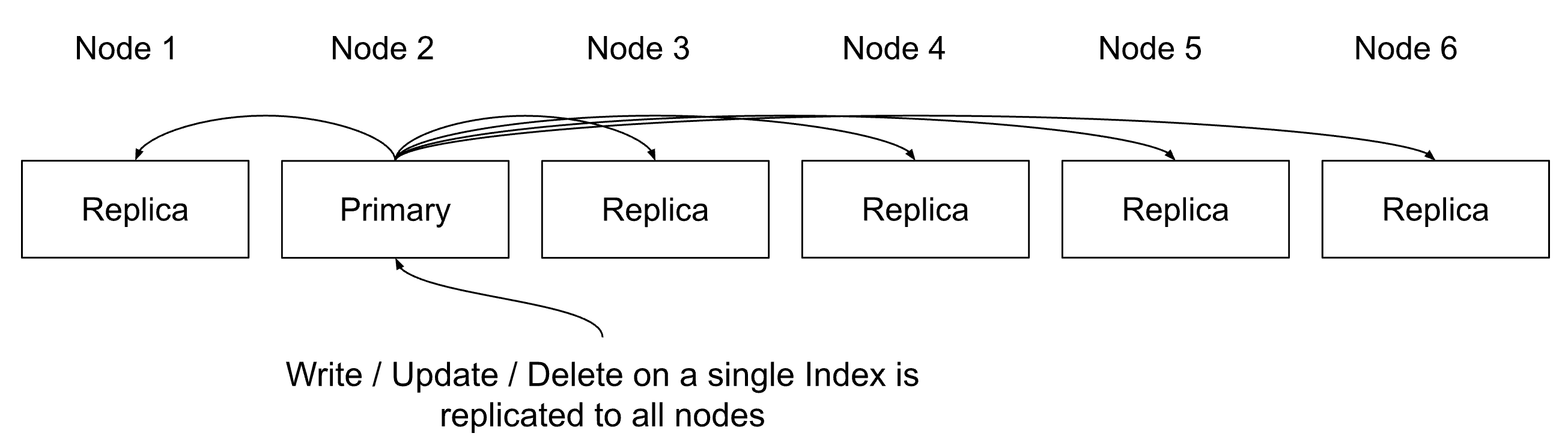
Diagram 3: Every write operation is multiplied by the number of replicas, dramatically increasing disk I/O and risking saturation in write-heavy environments.
Increased shard overhead
More replicas mean more:
- Shards
- Segment files
- File descriptors
- Cluster state updates
- Memory reserved for per-shard data structures
This expands JVM heap usage and increases GC frequency.
Diagnosing excessive replication: key symptoms
Clusters suffering from excessive replicas often exhibit the following operational symptoms:
- Frequent page faults and swapping: Working set cannot fit in RAM, leading to constant cache misses.
- Excessive garbage collection (GC): High heap usage and long GC pauses due to too many shards.
- Elevated disk I/O: Write amplification and cache churn drive up disk operations.
- Unassigned shards and node instability: Resource exhaustion can cause nodes to leave and shards to be reallocated.
- Search latency spikes: Queries frequently miss cache and hit disk, causing unpredictable response times.
If you observe these symptoms, review your replica counts and sharding strategy.
The solution: right-size your replicas
Best practices
- Set replicas based on failure tolerance, not guesswork. For most clusters, 1 replica is sufficient (2 if spanning 3 availability zones).
- Monitor cache hit rates and heap usage. Ensure your hot working set fits in RAM; otherwise, reduce replica count or re-architect your sharding strategy.
Using the earlier six-node example, reducing replicas from 5 to 1 dramatically reduces cache contention, improves cache locality, and lowers write amplification as shown in the following diagram.
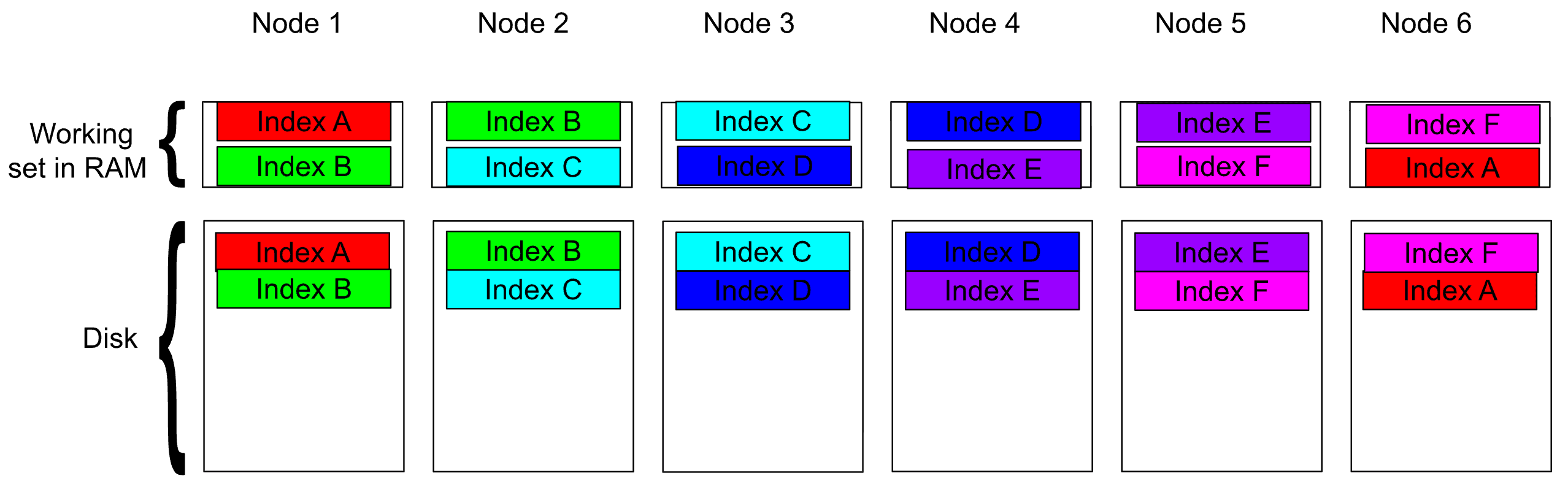
Diagram 4: Reducing replicas from 5 to 1 dramatically reduces the data hosted on each node and the overall memory contention.
Impact of reducing replicas
A large enterprise customer experienced severe and persistent cluster instability. Symptoms included:
- High latency
- Nodes repeatedly leaving the cluster
- Excessive disk I/O
- Frequent GC interruptions
- Search throughput collapse
Upon escalation, the root cause was quickly identified: The 20-node cluster had 12 replicas configured across numerous indices. After reducing replica counts to a sane baseline (typically 1) and rebalancing shards:
- Search latency normalized almost immediately
- Disk I/O dropped dramatically
- GC returned to normal levels
- Nodes stabilized with no further drop-outs
Right-sizing replicas was the key intervention.
Common misconception: Will fewer replicas overload my nodes?
A common concern is that reducing the number of replicas will concentrate search traffic on fewer nodes, creating hotspots or bottlenecks. In reality, Elasticsearch distributes queries across all available shard copies (primaries and replicas) for each index. Reducing replicas does not change the total query volume handled by the cluster; it changes the memory dynamics on each node.
With fewer replicas, each node holds fewer shards, making it far more likely that the data required for a query is already resident in RAM. The overall QPS per node remains comparable, but the cost per query drops dramatically because far fewer lookups result in (expensive) disk I/O.

Diagram 5: Same query load, improved cache hits: Before and after reducing replicas
Recommendations
- Audit your cluster: Review replica counts across all indices to ensure that you are really benefitting from the number of replicas you have assigned.
- Avoid “one-size-fits-all” settings: Tune replicas and primaries per index based on workload.
- Educate your team: Replicas are a tool, not a universal solution. Understand the trade-offs.
- Modifying the number of replicas that can be done at any time. Test changes in a controlled environment and monitor performance before and after adjustments.
Conclusion
Replicas are essential for resilience and search scalability, but in many use cases high replica counts can silently undermine Elasticsearch cluster performance.
Excessive replicas amplify writes, increase shard overhead, fragment system memory and cache behavior, and destabilize large, multi-index workloads.
If your cluster exhibits unexplained latency, GC pressure, or instability, start by auditing replica settings. In Elasticsearch performance engineering, more is not always better—often, less is faster and more reliable.
Further reading
Related Content

July 9, 2026
Why Elasticsearch is becoming a columnar database
Elasticsearch is becoming a first-class columnar database. Columnar Mode ships in 9.5, storing data once alongside the existing modes and cutting storage footprints while speeding up analytical queries.

July 7, 2026
Your compliance posture just got an upgrade: Elasticsearch now supports FIPS 140-3
Elastic 9.4 brings FIPS 140-3 support for Elasticsearch and Kibana to GA. Here's what changes for federal, defense and regulated deployments, and how to migrate from 140-2.

July 2, 2026
A simdvec deep-dive: How Elasticsearch uses neural-net and video-codec CPU instructions for vector search
Four ways Elasticsearch's vector search engine reuses neural-network, video-codec and cryptography CPU instructions for up to 6x speedups; with the math, the failed attempts and the benchmarks.

June 29, 2026
Bringing it together: How we rebuilt Elasticsearch as a columnar metrics engine; 6.6x less storage, 160x faster queries
Elasticsearch metrics in version 9.4 run on a fully columnar engine: 6.6x less storage, 160x faster queries, native PromQL and OTel support.
The hash() Elasticsearch won't name and the 12 bytes that prove it's Murmur3
Elasticsearch's routing formula uses MurmurHash3, but the docs never say so. This post names the function, walks through the full shard calculation, and shows you how to reproduce it externally.