Elasticsearch as a GenAI caching layer
Explore how integrating Elasticsearch as a caching layer optimizes Generative AI performance by reducing token costs and response times, demonstrated through real-world testing and practical examples.
As Generative AI (GenAI) continues to revolutionize various sectors, from customer service to data analytics, it comes with its own set of challenges, including computational costs and response times. By employing Elasticsearch as a caching layer, we can tackle these issues head-on, optimizing both efficiency and effectiveness. Let's journey through how this combination can offer real solutions to the inherent complexities of deploying generative AI models.
RAG overview
Retriever-Augmented Generation, commonly known as RAG, is a highly efficient mechanism in natural language processing. It operates by taking a given prompt or question and retrieving relevant information from a large dataset. With Elasticsearch, this result is most often retrieved using semantic search. The relevant document and prompt are then sent to a generative large language model (LLM) to create an easily human-consumable response. The ideal end result is a response that is more accurate but also rich in context, providing more depth than a simple keyword-based answer.
Challenges of generative AI at scale
Firstly, there's the issue of token cost for each generative call. Tokens are the inputs text is converted to for the model to understand. They can be as short as a single character or as long as a word. This is important because you're billed based on the number of tokens processed. Now, imagine a scenario where multiple users are asking the exact same question or giving similar prompts to the model. Each of these calls costs tokens, so if two identical prompts are processed, the cost is effectively doubled.
Then there's the matter of response time. Generative models need time to receive the data, process it, and then generate a response. Depending on the model size, complexity of the prompt, the location where it is being run, and other factors, this response time can grow to many seconds. It's like waiting for a web page to load; a few seconds can feel like an eternity and potentially deter users from engaging further.
These two problems—token cost and response time—are particularly significant because they not only affect operational efficiency but also have direct implications on user experience and overall system performance. As demands for newer real-time, intelligent responses continue to grow, these challenges cannot be ignored. So, we find ourselves at a juncture where finding a scalable and efficient solution becomes imperative.
Elastic as caching layer
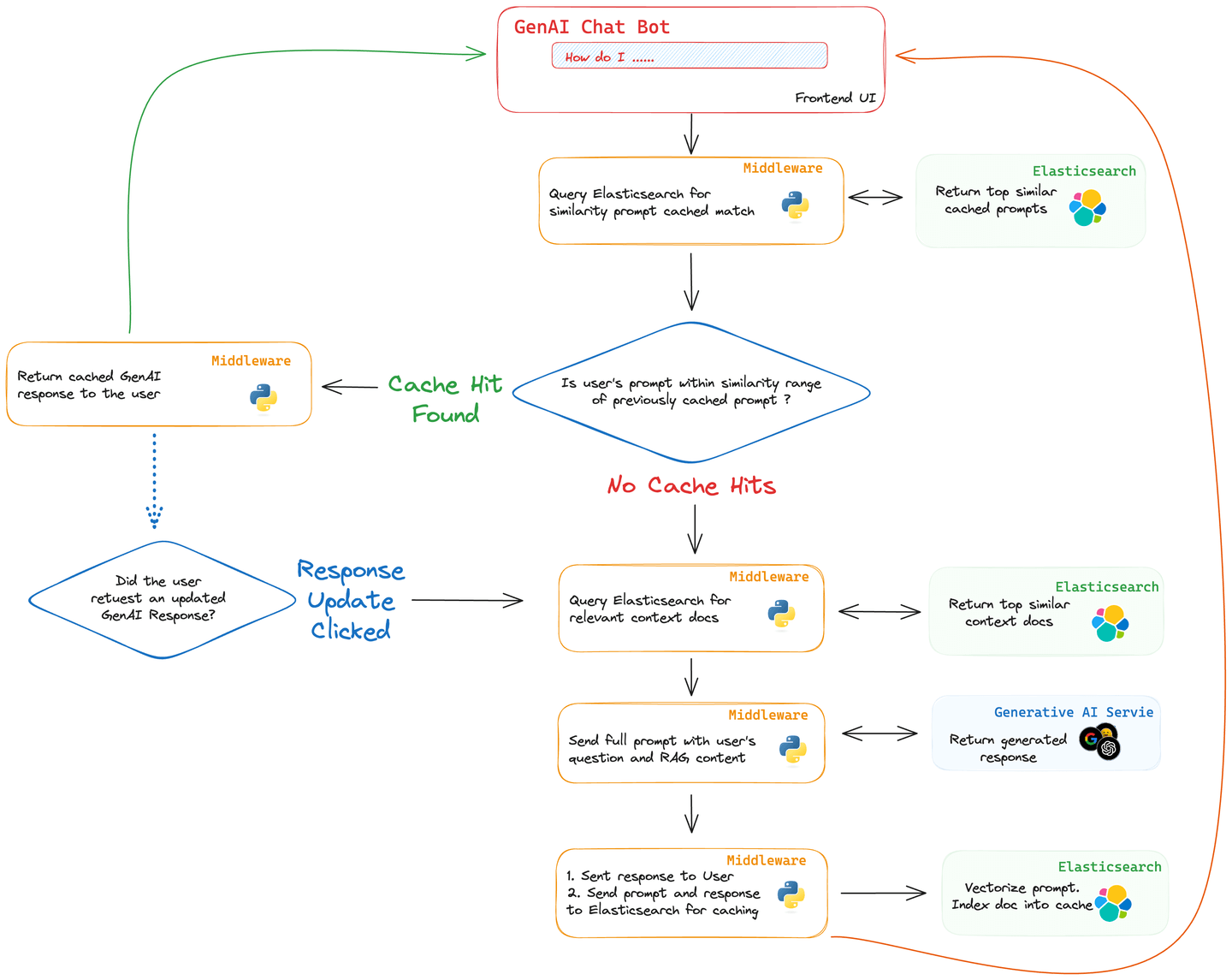
Elasticsearch is a vector database. What this means is that Elasticsearch can store not just the raw text of questions and answers, but also their semantic or "meaning-based" representations in a numerical vector format. These vectors can then be quickly compared for similarity, providing a robust and efficient way to identify related questions that have already been answered.
One key aspect that enables this intelligent matching is the k-Nearest Neighbors (kNN) similarity parameter. With kNN, Elasticsearch can quickly identify prompts that are most similar to a new incoming prompt. The result is a swift and efficient retrieval process that can bypass the more resource-intensive generative model if a sufficiently similar question has already been answered. This leads to quicker response times without the token cost. Elasticsearch enables this capability in the knn query with the similarity parameter.
To integrate Elasticsearch as a caching layer, the workflow can go as follows: A new prompt comes in and Elasticsearch is queried, including vectorizing the prompt, to find any existing vectors that are close matches. If a match is found, the previously generated answer to that earlier prompt is returned. If not, the question goes through the usual RAG process, and the newly minted answer is stored back into Elasticsearch for future use. You can even provide users with the option to insist on a "fresh" answer, thereby bypassing the cache if they so desire.
Elasticsearch can be configured to age out old data like a TTL in other caching systems. This ensures that the cache remains up-to-date and useful. Similarly, a tiering approach can be used by incorporating Elasticsearch’s Frozen Searchable Snapshot functionality. This would allow you to develop a vast caching layer, at low cost, for data less frequently accessed while still being faster than generating new responses.
Quality assurance measures, like an "approved" flag for certain responses, can also be implemented. This allows a review by human moderators before a cached response is made available to end users, adding an extra layer of reliability.
By implementing Elasticsearch as a caching layer, you achieve a more scalable, efficient, and in many ways, smarter system that addresses the limitations commonly faced in deploying generative AI models like RAG.
Evaluating semantic similarity: tolerance vs. resistance
In leveraging Elasticsearch as a caching layer, a critical aspect lies in the evaluation of semantic similarity between the newly asked and previously stored questions. The effectiveness of our caching mechanism largely depends on how well we can match new queries to the existing ones. At the core of this evaluation, there are two contrasting notions: Semantic Tolerance and Semantic Resistance.
Semantic tolerance
Semantic Tolerance, mirroring Recall, is a concept where the similarity function is evaluated with a broader lens, allowing for a wider range of semantic similarities between questions. This leniency can result in more matches, potentially reducing the computational load on the LLM. However, it may also lead to less precise matches, affecting the accuracy and relevance of the generated responses.
Semantic resistance
On the flip side, Semantic Resistance, which resonates with Precision, employs a stricter similarity function, narrowing down the scope of what's considered a "match." This strictness tends to yield more accurate and relevant matches at the expense of potentially higher computational costs, as fewer stored questions may meet the stringent similarity criteria.
The balance between Semantic Tolerance and Semantic Resistance, much like the trade-off between Recall and Precision, is pivotal for optimizing the performance and effectiveness of the Elasticsearch caching layer. By fine-tuning the similarity parameter in the KNN search, one can navigate this trade-off to align the caching mechanism with specific operational requirements and user expectations.
Illustrating semantic similarity with an HR example
To better understand the nuances of semantic similarity, let's consider a common scenario in a corporate setting: employees inquiring about Paid Time Off (PTO) policies for family events, such as a child's wedding. Here are two such inquiries:
[A] : "I have a wedding in the family, my son is getting married. Am I eligible for some PTO?"
[B] : "My child is getting married soon, can I take some PTO for the event?"
At a glance, it's clear that both inquiries are seeking the same information, albeit phrased differently. Our goal is to ensure that the system can recognize the semantic closeness of these inquiries and provide a consistent and accurate response, regardless of the phrasing differences.
Impact of the similarity parameter on semantic tolerance and resistance
The effectiveness of semantic matching in this scenario is influenced by the choice of similarity parameter in the KNN search within Elasticsearch. This parameter determines the minimum similarity required for a vector to be considered a match. We can illustrate the impact of this parameter by examining two hypothetical scenarios with varying similarity thresholds:
Scenario A (High Threshold - Resistance): A stringent similarity parameter, say 0.95, is set, encapsulating Semantic Resistance. This allows only queries with a high degree of similarity to retrieve cached answers, promoting precision at the expense of recall.
Scenario B (Low Threshold - Tolerance): A more lenient similarity parameter, say 0.75, is set, encapsulating Semantic Tolerance. This allows a broader range of semantically related queries to retrieve cached answers, favoring recall over precision.
By comparing these scenarios, we can observe how the similarity parameter influences the balance between Semantic Resistance and Semantic Tolerance, and subsequently, the trade-off between recall and precision. The table below illustrates how different queries might be handled under these scenarios based on their hypothetical similarity scores to the original query about PTO for a child's wedding:
Query | Hypothetical Similarity Score | Retrieved in Scenario A (High Threshold - 0.95) | Retrieved in Scenario B (Low Threshold - 0.75) |
|---|---|---|---|
Can I take PTO for my son's wedding? | 0.94 | No | Yes |
Is there a leave policy for family events? | 0.80 | No | Yes |
I need time off for my daughter's marriage, is that possible? | 0.97 | Yes | Yes |
How do I apply for leave for personal family occasions? | 0.72 | No | No |
What's the process to get time off for family ceremonies? | 0.78 | No | Yes |
Can I get some days off for my sibling's wedding? | 0.85 | No | Yes |
The table demonstrates how varying the similarity threshold impacts the retrieval of cached answers, showing a trade-off between response accuracy (Scenario A) and computational efficiency (Scenario B).
Use cases
One of the most straightforward applications is storing questions and responses as new queries come in. As users interact with the AI model, their questions, along with the generated answers, are cached. Over time, this builds an organic cache that grows richer and more varied with each user interaction. It's a win-win situation. Not only do future user queries benefit from this pre-existing wealth of knowledge, but you also save on token costs and reduce latency.
Another compelling use case is preloading the system with answers to commonly asked questions. If you're already monitoring the types of queries your users are inputting, you can pre-generate responses for frequent questions and store them for immediate retrieval. This serves a dual purpose: it enables faster response times and provides a platform to assess the quality and consistency of the AI's responses. Think of it as having a frequently asked questions (FAQ) section, but one that's incredibly dynamic and continually optimized for user needs.
Identifying trends and common topics from user questions opens yet another avenue of utility. By analyzing the questions and their corresponding responses, you can feed this data back into the generative model for summary reports or even for topic-based grouping. You can also use sentiment analysis on the stored prompts to evaluate the tone and mood of user interactions. This provides a valuable layer of analytics that could inform product development, customer service improvements, or even marketing strategies.
Testing it out
While the particular application will depend on your end use case, an example setup can be copied from this GH repo.
Consider a scenario involving timing metrics for query response. In the first run without a cache, let's say a user query takes 300 milliseconds to receive a generated answer from RAG. Now, after storing that response in Elasticsearch, a second similar query comes in. This time, thanks to our intelligent caching layer, the response time drops to a mere 50 milliseconds. This demonstrates a tangible improvement in system responsiveness—a boon for any real-time application, and also a testament to the cost and time efficiencies gained.
In the example project, you will find two main files.
The elasticsearch_llm_cache.py is the example repo containing the Python class ElasticsearchLLMCache which your application will instantiate on startup. This class contains the following methods:
create_indexThis will create a new caching index in Elasticsearch if one does not existqueryperforms a kNN search, including vectorizing the prompt. It will return the top k similar documents that fall within the similarity range.addvectorizes a prompt by calling_generate_vectorand indexes the prompt and generative response in text form as well as the vectorized prompt
The elasticRAG_with_cache.py is an example Streamlit application that utilizes elasticsearch_llm_cache.
But it's not all about speed; it's also about insights. If you're using Elasticsearch's Application Performance Monitoring (APM) library for Python, you can obtain rich metrics on query timings, resource utilization, and even error rates. This data is invaluable for ongoing system optimization and can be a treasure trove for data scientists and engineers looking to fine-tune performance. Monitoring these metrics allows you to not only improve the user experience but also manage your resources more effectively.
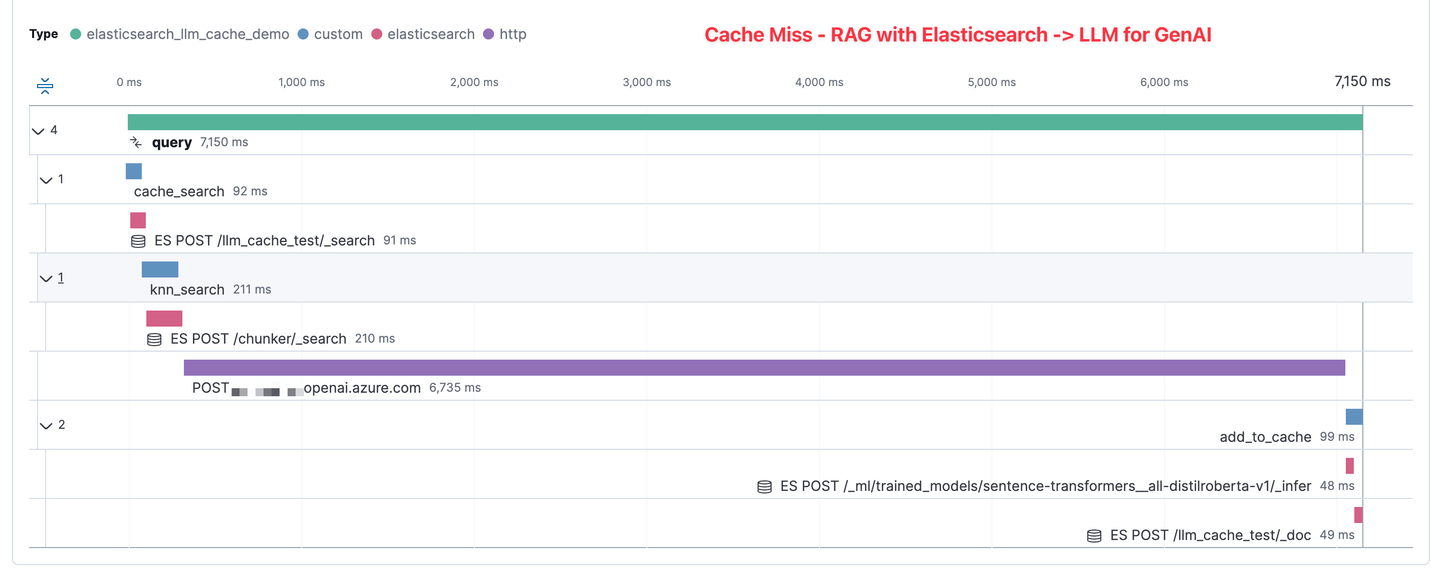
This is an APM trace showing the time taken when a new prompt is entered, one that does not have a matching cache. We can see that in this example, the total time in our sample application, from the user hitting submit, to our application returning a response from the GenAI mode, took 7,150 milliseconds, or about 7 seconds.
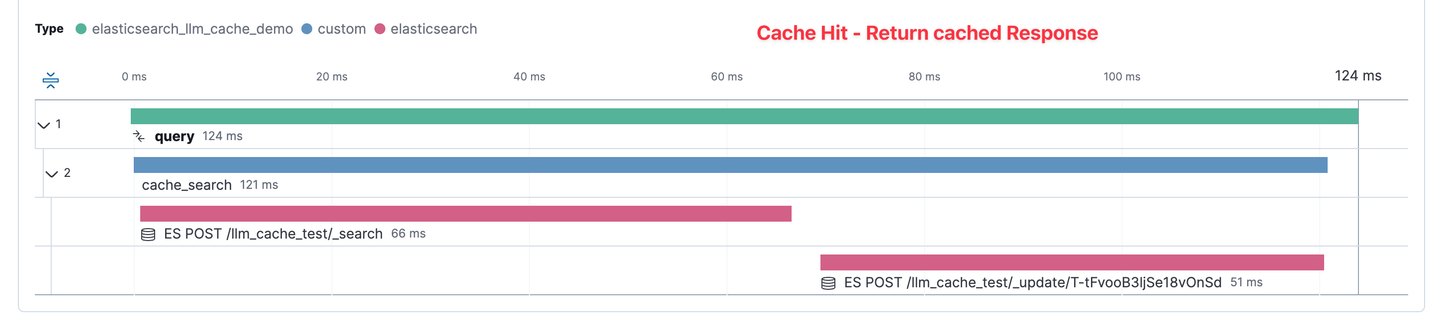
With that prompt and response now cached in Elasticsearch for future use, the below APM trace shows when a similar prompt is answered. Here we see because a close enough prompt was found, we can directly return the previously generated response. This shortcut now results in a total time of 124 milliseconds.
By looking at these example use cases, it becomes clear that implementing Elasticsearch as a caching layer is not just an academic exercise; it has real-world implications for performance, cost, and user experience.
Wrap-up
By leveraging Elasticsearch's capabilities as a vector database with its similarity parameters, we've opened the door to a more responsive, cost-efficient, and scalable Generative AI system. Whether it's improving query timings, enabling nuanced matching, or even adding another layer of reliability through human oversight, the benefits are clear.
Ready to get started? Check the Python library and example code and begin a free trial of Elastic Cloud.
Frequently Asked Questions
What is Retriever-Augmented Generation (RAG)?
RAG is a highly efficient mechanism in natural language processing. It operates by taking a given prompt or question and retrieving relevant information from a large dataset.
What is Semantic Tolerance in the context of Elasticsearch?
Semantic Tolerance, mirroring Recall, is a concept where the similarity function is evaluated with a broader lens, allowing for a wider range of semantic similarities between questions. This leniency can result in more matches, potentially reducing the computational load on the LLM. However, it may also lead to less precise matches.
Related Content


Retrieval Augmented Generation (RAG) using Cohere Command model through Amazon Bedrock and domain data in Elasticsearch