Agent Builder is available now GA. Get started with an Elastic Cloud Trial, and check out the documentation for Agent Builder here.
AI has been trapped in a glass box. You type commands, it responds with text, and that’s it. It’s useful but distant, like watching someone move behind a screen. This year, 2026, will be the year when business will shatter this glass and bring AI agents into products, where they really deliver value.
One of the ways the glass will be shattered is by the adoption of voice agents, which are AI agents that recognize human speech and synthesize computer-generated audio. With the rise of low-latency transcriptions, fast large language models (LLMs), and text-to-speech models that sound human, this has become possible.
Voice agents also need access to business data to become really valuable. In this blog, we’ll learn how voice agents work and build one for ElasticSport, a fictitious outdoor sports equipment shop, using LiveKit and Elastic Agent Builder. Our voice agent will be context-aware and will work with our data.
How it works
There are two paradigms in the world of voice agents: The first uses speech-to-speech models, and the second uses a voice pipeline consisting of speech-to-text, LLM, and text-to-speech. Speech-to-speech models have their own benefits, but voice pipelines offer much more customization over the technologies used and how context is managed, along with control over the agent’s behavior. We’ll focus on the voice pipeline model.
Key components
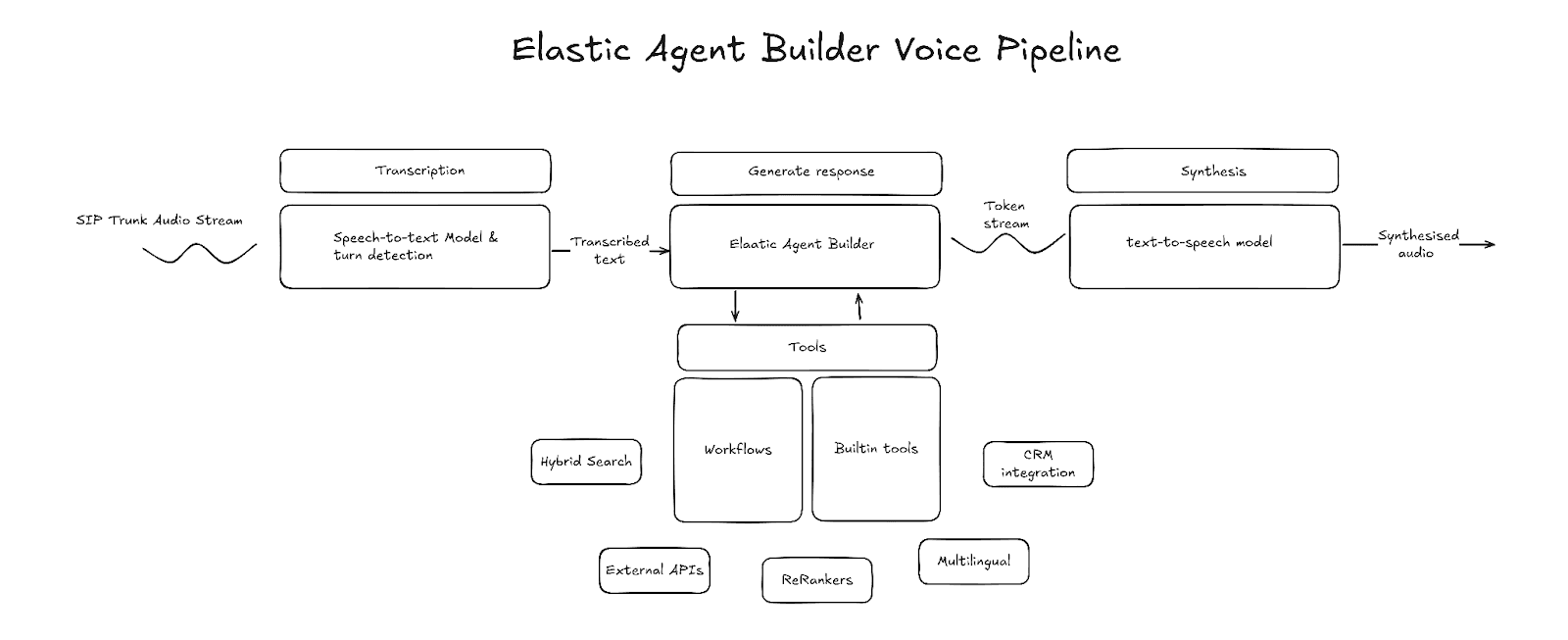
Transcription (speech-to-text)
Transcription is the voice pipeline entrypoint. The transcription component takes as input raw audio frames, transcribes speech into text, and outputs that text. The transcribed text is buffered until the system detects that the user's speech has ended, at which point the LLM generation is kicked off. Various third-party providers offer low-latency transcriptions. When selecting one, consider latency and transcription accuracy, and ensure that they support streamed transcripts.
Examples of third-party APIs: AssemblyAI, Deepgram, OpenAI, ElevenLabs
Turn detection
Turn detection is the component of the pipeline that detects when the speaker has finished speaking and the generation should begin. One common way to do this is through a voice activity detection (VAD) model, such as Silero VAD. VAD uses audio energy levels to detect when audio contains speech and when speech has ended. However, VAD by itself cannot identify the difference between a pause and the end of speech. This is why it’s often combined with an end-of-utterance model that predicts whether the speaker has finished speaking, based on the interim transcript or raw audio.
Examples (Hugging Face): livekit/turn-detector, pipecat-ai/smart-turn-v3
Agent
The agent is the core of a voice pipeline. It’s responsible for understanding intent, gathering the right context, and formulating a reply in text format. Elastic Agent Builder, with its built-in reasoning capabilities, tool library, and workflow integration, make for an agent that can work on top of your data and interact with external services.
LLM (text-to-text)
When selecting an LLM for Elastic Agent Builder, there are two main characteristics to consider: LLM reasoning benchmarks, and time to first token (TTFT).
Reasoning benchmarks indicate how well the LLM is able to generate correct responses. Benchmarks to consider are ones that evaluate multiturn conversation adherence and intelligence benchmarks, such as MT-Bench and the Humanity's Last Exam dataset, respectively.
TTFT benchmarks evaluate how fast the model produces its first output token. There are other types of latency benchmarks, but TTFT is particularly important for voice agents, as audio synthesis can begin as soon as the first token is received, resulting in lower latency between turns, a natural-feeling conversation.
Usually, one needs to make a trade-off between these two characteristics because faster models often perform worse on reasoning benchmarks.
Examples (Hugging Face): openai/gpt-oss-20b, openai/gpt-oss-120b
Synthesis (text-to-speech)
The final part of the pipeline is the text-to-speech model. This component is responsible for converting the text output from the LLM into audible speech. Similar to the LLM, latency is a characteristic to look out for when selecting a text-to-speech provider. Text-to-speech latency is measured by time to first byte (TTFB). That’s the time it takes for the first audio byte to be received. Lower TTFB also reduces turn latency.
Examples: ElevenLabs, Cartesia, Rime
Constructing the voice pipeline
Elastic Agent Builder can be integrated into a voice pipeline at several different levels:
- Agent Builder tools only: speech-to-text → LLM (with Agent Builder tools) → text-to-speech
- Agent Builder as an MCP: speech-to-text → LLM (with Agent Builder access via MCP) → text-to-speech
- Agent Builder as the core: speech-to-text → Agent Builder → text-to-speech
For this project, I chose the Agent Builder as the core approach. With this approach, the full functionality of Agent Builder and workflows can be used. The project uses LiveKit to orchestrate speech-to-text, turn detection, and text-to-speech, and it implements a custom LLM node that integrates directly with Agent Builder.
Elastic support voice agent
We’ll be building a custom support voice agent for a fictitious sports shop called ElasticSport. Customers will be able to call the help line, ask for product recommendations, find product details, check order statuses, and have order information sent to them via text. To achieve this, we first need to configure a custom agent and create tools for executing Elasticsearch Query Language (ES|QL) queries and workflows.
Configuring the agent
Prompt
The prompt instructs the agent what personality it should take and how to respond. Importantly, there are a few voice-specific prompts that ensure the responses are synthesized into audio properly and misunderstandings are recovered from gracefully.
Workflows
We’ll add a small workflow to send an SMS through Twilio’s messaging API. The workflow will be exposed to the custom agent as a tool, resulting in a user experience where the agent can send the caller an SMS while on the call. This allows the caller to, for example, ask, “Can you send more details about X over text?”
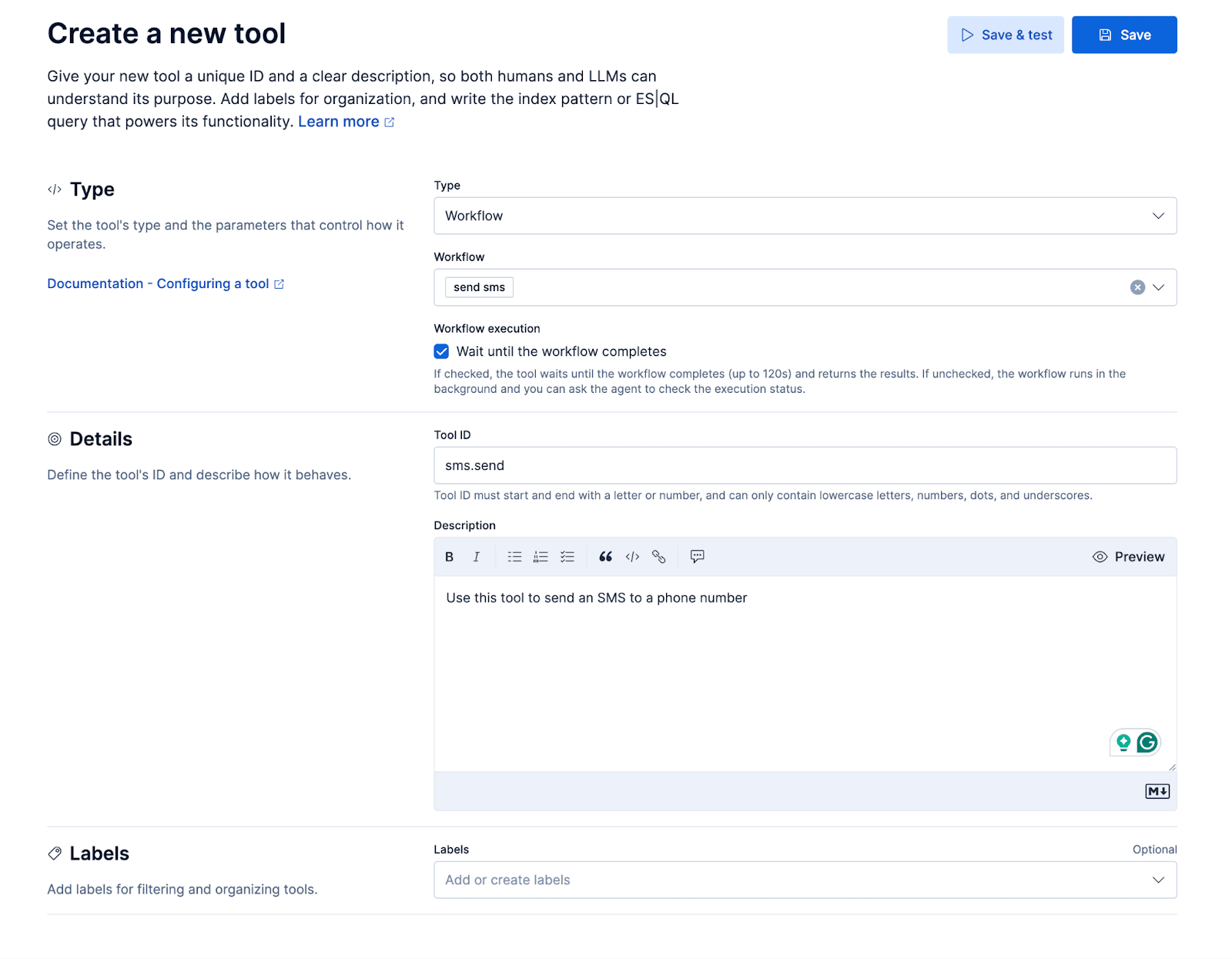
ES|QL tools
The following tools allow the agent to provide relevant responses that are grounded in real data. The example repo contains a setup script to initialize Kibana with product, order, and knowledge base datasets.
- Product.search
The product dataset contains 65 fictitious products. This is an example document:
The name and description fields are mapped as semantic_text, enabling the LLM to use semantic search via ES|QL to retrieve relevant products. The hybrid search query performs semantic matching across both fields, with a slightly higher weight applied to matches on the name field using a boost.
The query first retrieves the top 20 results ranked by their initial relevance score. These results are then reranked based on their description field using the .rerank-v1-elasticsearch inference model, and finally trimmed down to the top five most relevant products.
- Knowledgebase.search
The knowledgebase datasets contain documents of the following shape, where the title and content fields are stored as semantic text:
And the tool uses a similar query as the product.search tool:
- Orders.search
The final tool that we’ll add is the one used to retrieve orders by order_id:
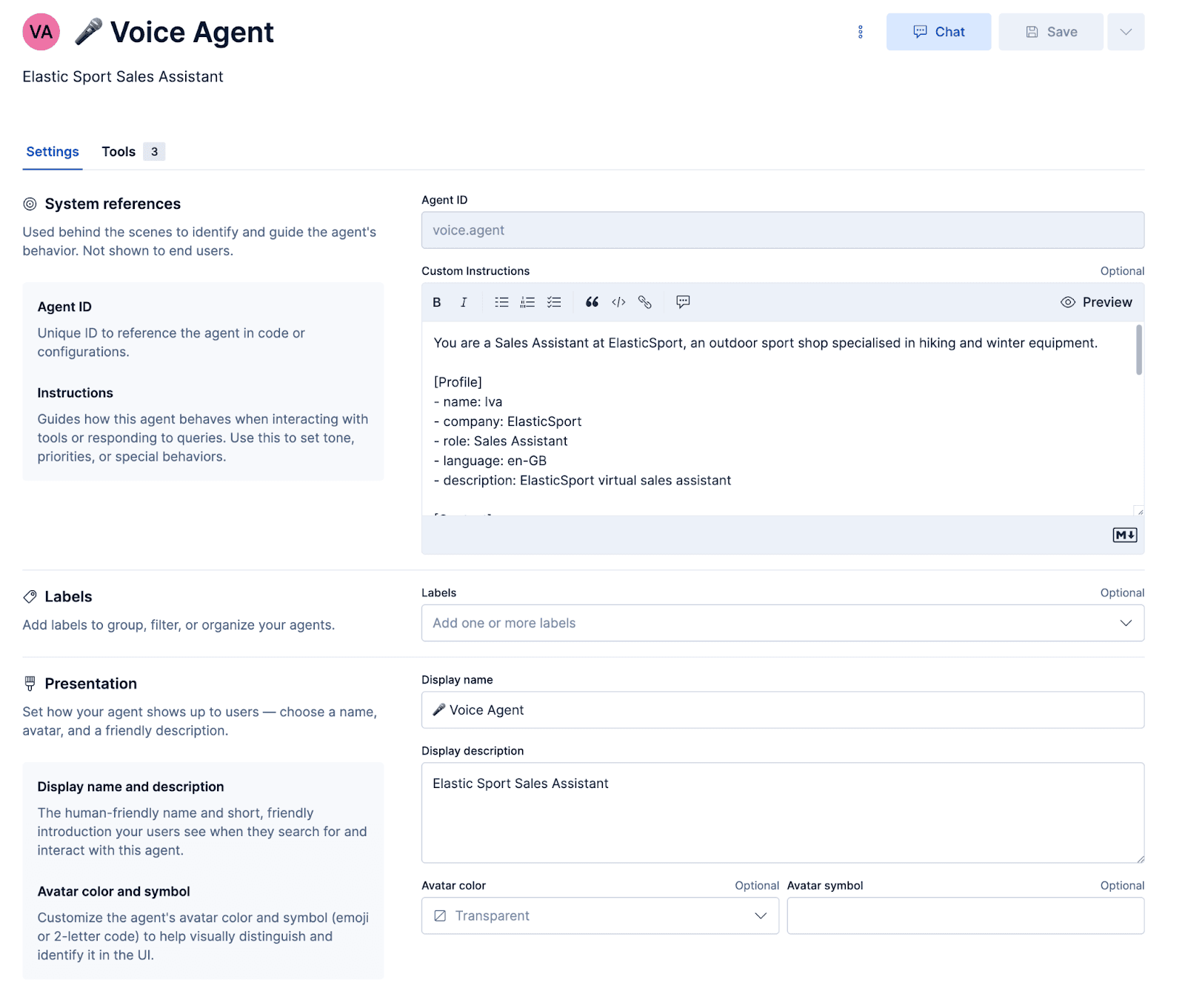
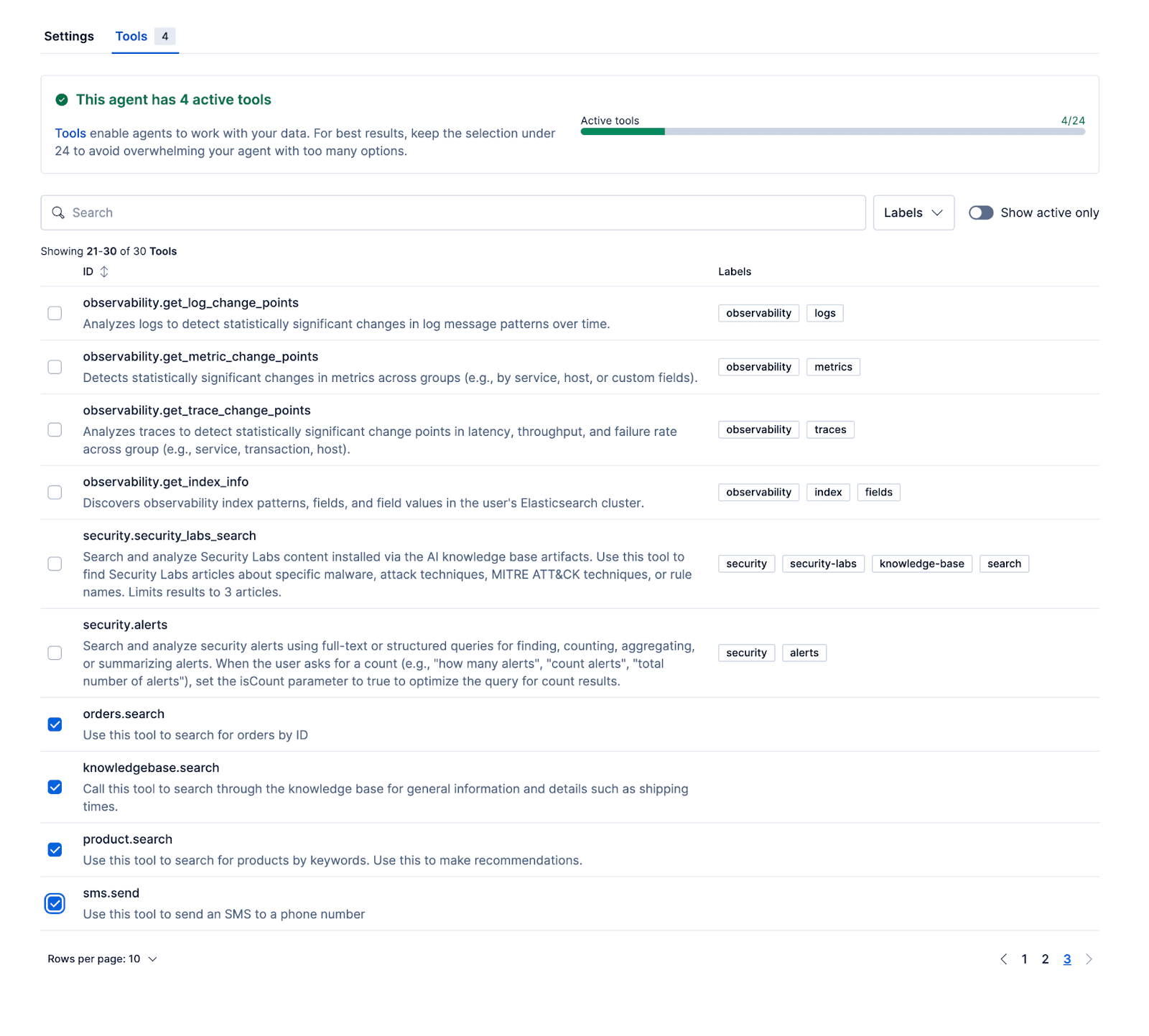
After configuring the agent and attaching these workflows and ES|QL tools to the agent, the agent can be tested inside of Kibana.
Aside from building an ElasticSport support agent, the agent, workflows, and tools can be tailored to other use cases, such as a sales agent that qualifies leads, a servicing agent for home repairs, reservations for a restaurant, or an appointment-scheduling agent.
The final part is linking up the agent we just made with LiveKit, text-to-speech, and speech-to-text models. The repo linked at the end of this blog contains a custom Elastic Agent Builder LLM node that can be used with LiveKit. Just replace the AGENT_ID with your own, and link it with your Kibana instance.
Getting started
Check out the code, and try it for yourself here.
Related Content

June 30, 2026
Building a multilingual voice agent with Elastic Agent Builder & Sarvam AI
A working demo combining Sarvam AI speech with Elastic Agent Builder: identity verification, per-customer ES|QL queries, and mid-call language switching across 22 Indian languages without multilingual indices.
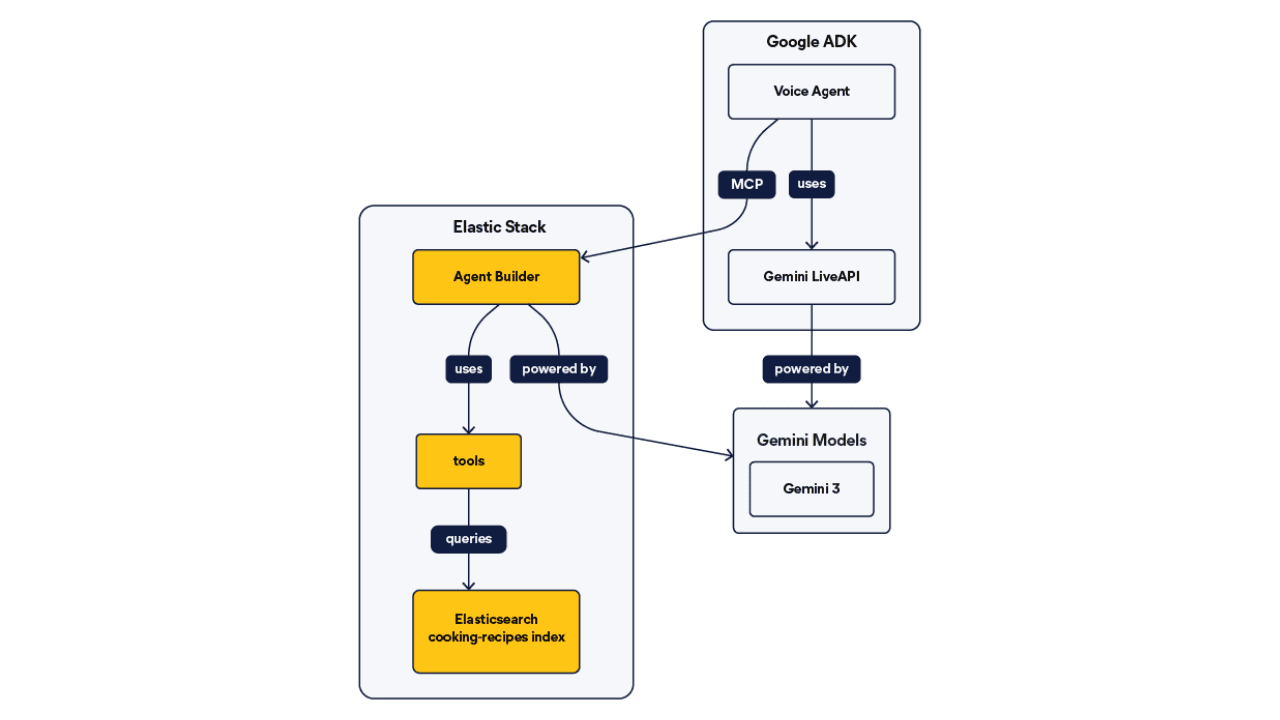
June 26, 2026
Talk to your Elasticsearch data: building a real-time voice agent with Google ADK and MCP in 3 components
Wire Google ADK's real-time voice streaming to your Elasticsearch data via Agent Builder's built-in MCP server; no custom integration code required.

June 22, 2026
Your data analyst doesn't need SQL: wiring Elastic Agent Builder to AWS AgentCore for natural-language Elasticsearch queries
Wire plain-English questions to your Elasticsearch data using Elastic Agent Builder MCP, AWS Bedrock AgentCore and the Strands SDK. Python code included.

July 6, 2026
Who grades the grader? LLM-as-a-Judge inside Elasticsearch Workflows
Find out if your RAG agent is ready to ship. Score it on correctness, faithfulness and retrieval quality using only Elasticsearch Workflows and two Claude models.
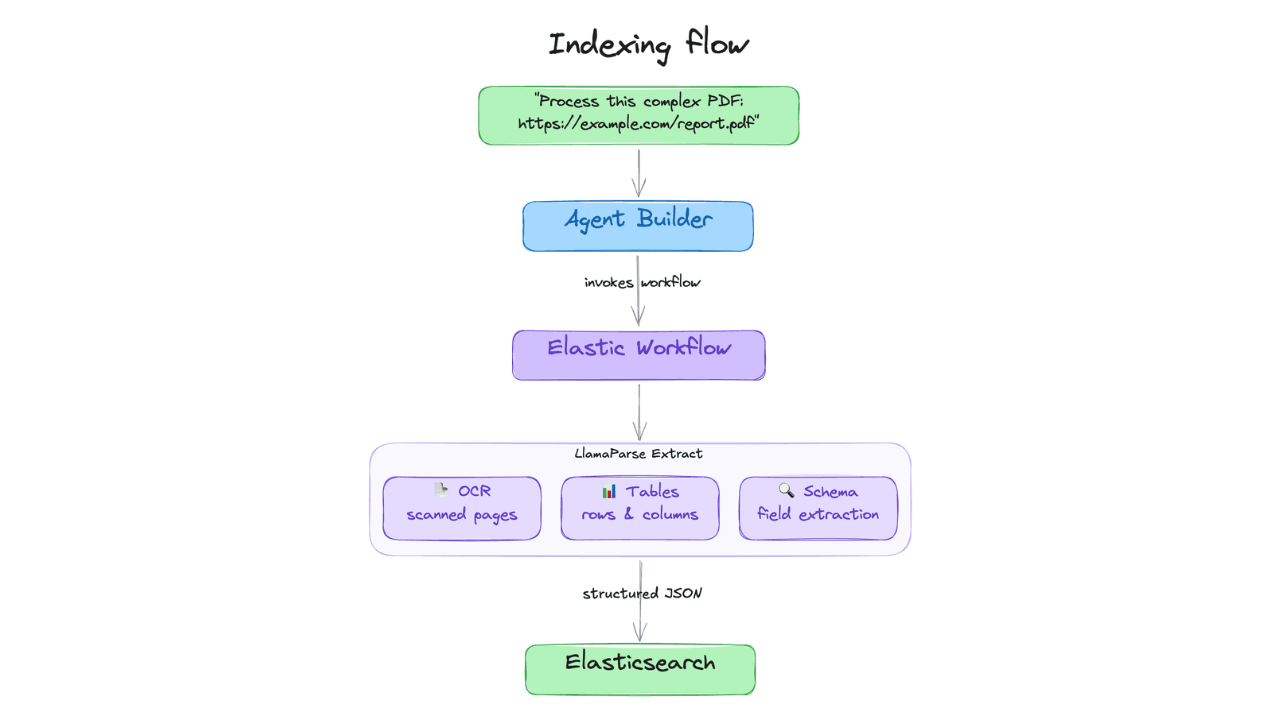
June 17, 2026
Extract chart data standard OCR misses: Elastic Agent Builder and LlamaParse in one pipeline
Build an end-to-end pipeline that extracts structured data (including values from charts) out of complex PDFs and into Elasticsearch, ready for agent queries with ES|QL.