Try out vector search for yourself using this self-paced hands-on learning for Search AI. You can start a free cloud trial or try Elastic on your local machine now.
Ever wondered how to make years of collected documents searchable by meaning, not just keywords? Dealing with PDFs full of valuable information can be challenging, especially when it comes to chunking and creating searchable data across multiple languages.
This blog post will guide you through transforming your PDF document collection into an AI-powered semantic search system. We'll explore how Elastic offers an end-to-end solution for RAG: ingesting PDFs, processing them into chunks, vectorizing the content, and providing an interactive playground to query and interact with your data. Discover how to make your information not just more accessible, but truly conversational. You will be able to test how to easily create summaries of relevant information, understand the relevance score for each answer given and gain a maximum of transparency on why exactly an answer has been created.
semantic_text field type
Semantic search enhances data discovery by understanding word meanings and context. Elastic's semantic_text field type simplifies semantic search implementation by handling complexities behind the scenes, including inference, chunking, and continuous improvements. It's particularly effective with paragraph-based texts, automatically handling chunking strategies, with customizable options planned for the future.
For complex documents requiring different chunking strategies - such as those with intricate layouts, embedded images, or unique formatting - consider using tools like Apache Tika, Unstructured, or Tesseract OCR to pre-process the content.
Prerequisites
To implement the techniques described in this blog, you'll need:
- An Elastic cloud deployment optimized for Vector Search
OR
An on-premise Elasticsearch Cluster with:- Data nodes configured for search (1:15 ratio)
- ML nodes with at least 8 GB RAM
- Elastic Release 8.15
- Access to a Generative AI service:
- OpenAI or AWS Bedrock (used in this example)
OR - For on-premise setups: An OpenAI-compatible SDK (e.g., localai.io or LM Studio) to access a locally hosted LLM
- OpenAI or AWS Bedrock (used in this example)
- PDF files you would like to access with Generative AI powered search:
- If you would like to follow the example with BSI Grundschutz you can find the PDFs on the official BSI website: https://www.bsi.bund.de/DE/Themen/Unternehmen-und-Organisationen/Standards-und-Zertifizierung/IT-Grundschutz/IT-Grundschutz-Kompendium/it-grundschutz-kompendium_node.html
- Alternatively you can test with your individual PDF collection. The files have to be organized in one single folder.
This setup will provide the necessary infrastructure to process and interact with your data effectively.
Configurations in Elastic
To begin, we'll load and start our multi-language Embedding Model. For this blog, we're using the compact E5 model, which is readily available for download and deployment in your Elastic Cloud environment.
Follow these steps:
- Open Kibana
- Navigate to Analytics > Machine Learning > Trained Models
- Select "Model Management" and click on the "Add Trained Models" button

Select the E5-small model (ID: .multilingual-e5-small) from the list and click "Download". After a few minutes, when the model is loaded, deploy it by clicking the start/deploy symbol.
Next, navigate to the Dev Console to set up the inference service:
- Open the Dev Console
- Create an inference service pointing to our embedding model with the following command:
With the inference service running, let's create a mapping for our destination index, incorporating the semantic_text field type:
Finally we create an ingest pipeline to deal with the binary content of the PDF documents:
The pipeline incorporates the attachment processor, which utilizes Apache Tika to extract textual information from binary content such as PDFs and other document formats. With the combination of the index mapping including the semantic_text field and the pipeline we will be able to index PDFs, create chunks and embeddings in one step (see next chapter).
With this setup in place, we're now ready to begin indexing documents.
Pushing and indexing PDFs to Elastic
For this example, we'll use PDFs from the German Federal Office for Information Security (BSI)'s IT Baseline Protection ("Grundschutz Kompendium").
German critical infrastructure (KRITIS) organizations and federal authorities are required to build their security environments based on these BSI standards. However, the structure of these PDFs often makes it challenging to align existing measures with the guidelines. Traditional keyword searches often fall short when trying to find specific explanations or topics within these documents.
These documents offer an ideal test case for semantic search capabilities, challenging the system with technical content in a non-English language.
The earlier mapping handles PDF content extraction, while Elastic manages inference and chunking automatically.
Data loading can be done in various ways. Elastic’s Python Client simplifies the process and integrates smoothly.
For classic Elastic deployments either on premise or managed by Elastic the package can be installed with:
The Python code required to transform and load your PDFs can look like this:
The index is set up for semantic, full-text, or hybrid search. Chunks break down large PDFs into manageable pieces, which simplifies indexing and allows for more precise searches of specific sections or topics within the document. By storing these chunks as nested objects, all related information from a single PDF is kept together within one document, ensuring comprehensive and contextually relevant search results. Everything is now ready to search:

Prototyping search with Playground
In this step, the aim is to see if what's been created meets practical standards. This involves using Elastic's new “Playground” functionality, described in this Blog in more detail.
To get started with Playground, first set up connectors to one or more LLMs. You can choose from public options like OpenAI, AWS Bedrock, or Google Gemini, or use an LLM hosted privately. Testing with multiple connectors can help compare performance and pick the best one for the job.
In our use case, the information is publicly available, so using public LLM APIs doesn't pose a risk. In this example, connectors have been set up for OpenAI and AWS Bedrock:

Navigate to the playground and select the index created earlier by clicking on “Add data sources” and “Save and continue”:

Now we are ready to start asking questions (In this case - in German ) and select one of the LLMs available through the connectors:
Review the answers to your questions and the documents added to the context window.
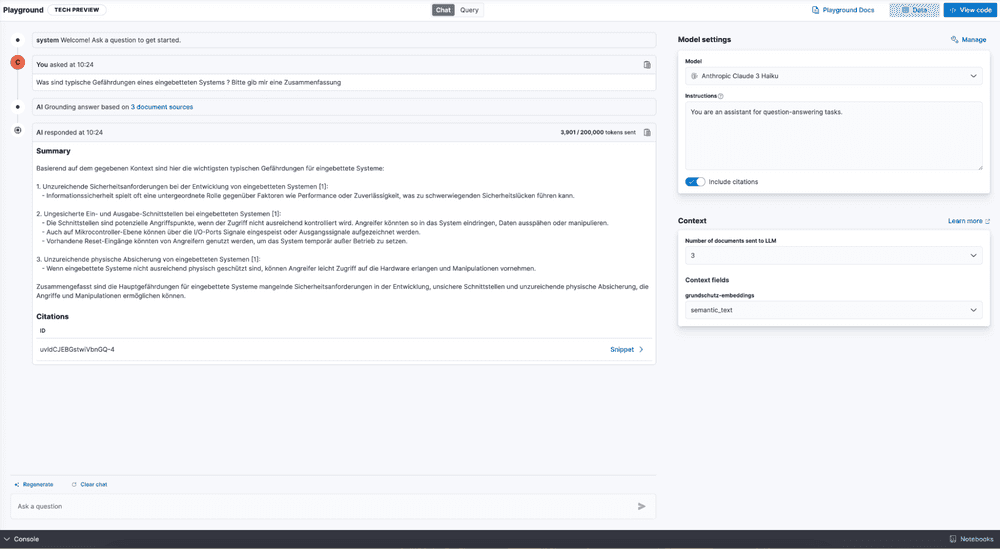
Since we used a multilingual embedding model to create the content, it's a good idea to try interacting with the information in different languages.

The code example in the Playground can be leveraged further for building the Search Application for your users.
Summary and conclusions
So finally we have found a straightforward approach to test the quality of a possible use case and develop a prototype in a reasonable amount of time. You've uncovered how Elastic's capabilities work and how to apply them effectively.
- Flexibility: Easily load and use embedding models without getting bogged down in chunking and structure.
- Speed and performance: Elastic allows for rapid development and deployment, making it easy to iterate and refine solutions efficiently. The technology is designed for speed, enabling exceptionally fast processing and quick turnaround times.
- Transparency: See exactly how answers are derived using Playground.

- Unified Document Storage: Store structured and unstructured information together in one document, allowing easy access to key details like the original document name or author for your search application.

So, dive in, start building your own search experience and understand how RAG might help you to gain more relevance and transparency in your Chatbot. Stay updated on the latest from Elastic by following our Search Labs.
Related Content

July 2, 2026
A simdvec deep-dive: How Elasticsearch uses neural-net and video-codec CPU instructions for vector search
Four ways Elasticsearch's vector search engine reuses neural-network, video-codec and cryptography CPU instructions for up to 6x speedups; with the math, the failed attempts and the benchmarks.

June 24, 2026
Elasticsearch DiskBBQ delivers 7x faster vector search than Qdrant on network-attached storage
Elasticsearch DiskBBQ achieves up to 7x higher vector search throughput than Qdrant at comparable recall on network-attached storage. Explore the benchmark methodology and full results.

June 18, 2026
Jingra: A Reproducible Framework for Vector Search Benchmarking
Jingra is an open source benchmarking framework that runs the same vector search workload across Elasticsearch, OpenSearch and Qdrant so you can compare engines under identical, reproducible conditions.
June 16, 2026
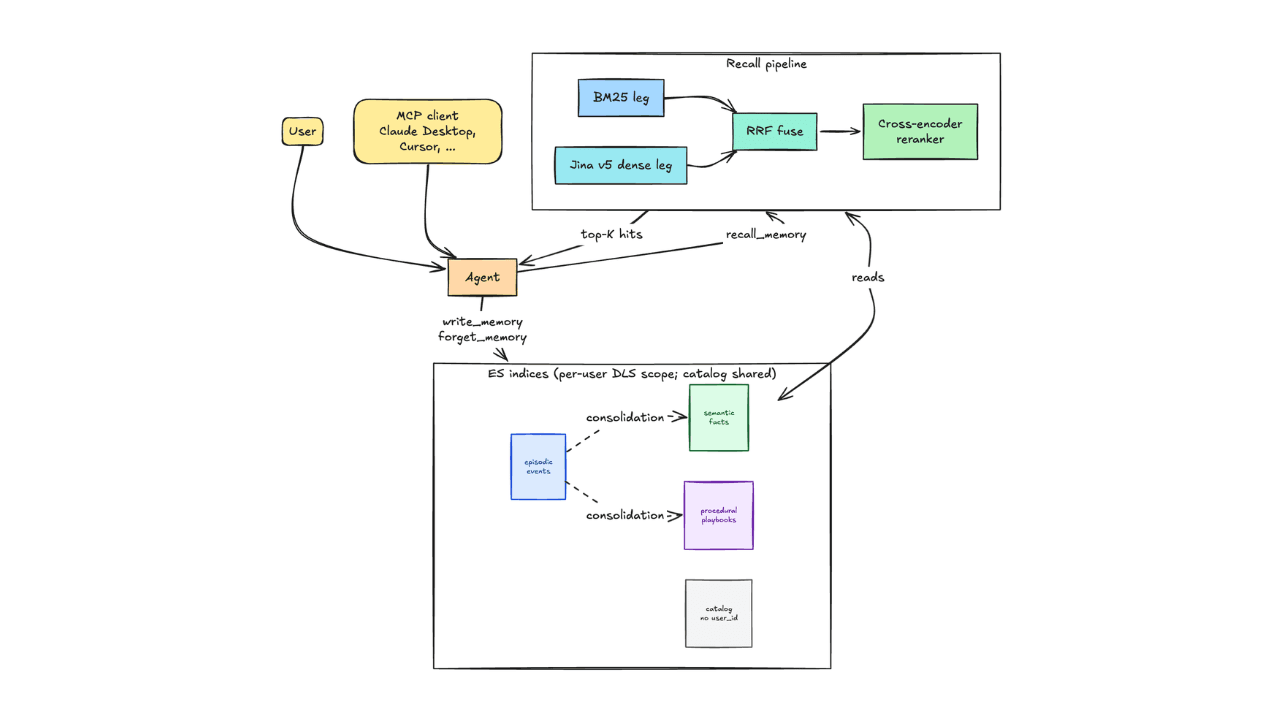
How we built a persistent agent memory layer on Elasticsearch with 0.89 recall and zero tenant leaks
Discover the architecture behind a persistent, multi-tenant agent memory layer on Elasticsearch: three indices, hybrid retrieval with RRF and a reranker, supersession, decay, and per-user DLS isolation. R@10 0.89 across 168 questions. Full open-source implementation included.

June 15, 2026
Your search index is already an agent memory system: Persistent agent memory for Claude Code with Elasticsearch
Give your AI agent persistent cross-session memory using Elasticsearch: Hybrid recall, a knowledge graph, and cross-device handoffs. Three commands to install.