Como otimizar as consultas de classificação no Elasticsearch para obter resultados mais rápidos


 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
No Elasticsearch, é comum haver solicitações de que os resultados sejam classificados por um determinado campo. Investimos muito tempo e esforço para otimizar as consultas de classificação a fim de torná-las mais rápidas para nossos usuários. Este post descreverá algumas das otimizações de classificação para campos numéricos e de data.
Como as consultas classificadas funcionam
Quando você quer encontrar documentos que correspondam a um filtro e solicita que os resultados sejam classificados por um determinado campo, o Elasticsearch examina os valores de documento desse campo para todos os documentos correspondentes ao filtro e escolhe os mil melhores documentos com os melhores valores. No pior caso de um filtro muito amplo (por exemplo, consulta match_all), temos de examinar e comparar os valores de todos os documentos em um índice. Para índices grandes, isso pode levar muito tempo.
Uma maneira de otimizar as consultas de classificação em um campo específico é usar a classificação do índice e classificar todo o índice nesse campo. Se o índice for classificado por um campo, seus valores de documento também serão classificados. Portanto, para classificar os mil melhores documentos por um campo, precisamos simplesmente pegar os primeiros mil documentos e nem precisamos examinar o restante, o que torna as consultas classificadas muito rápidas.
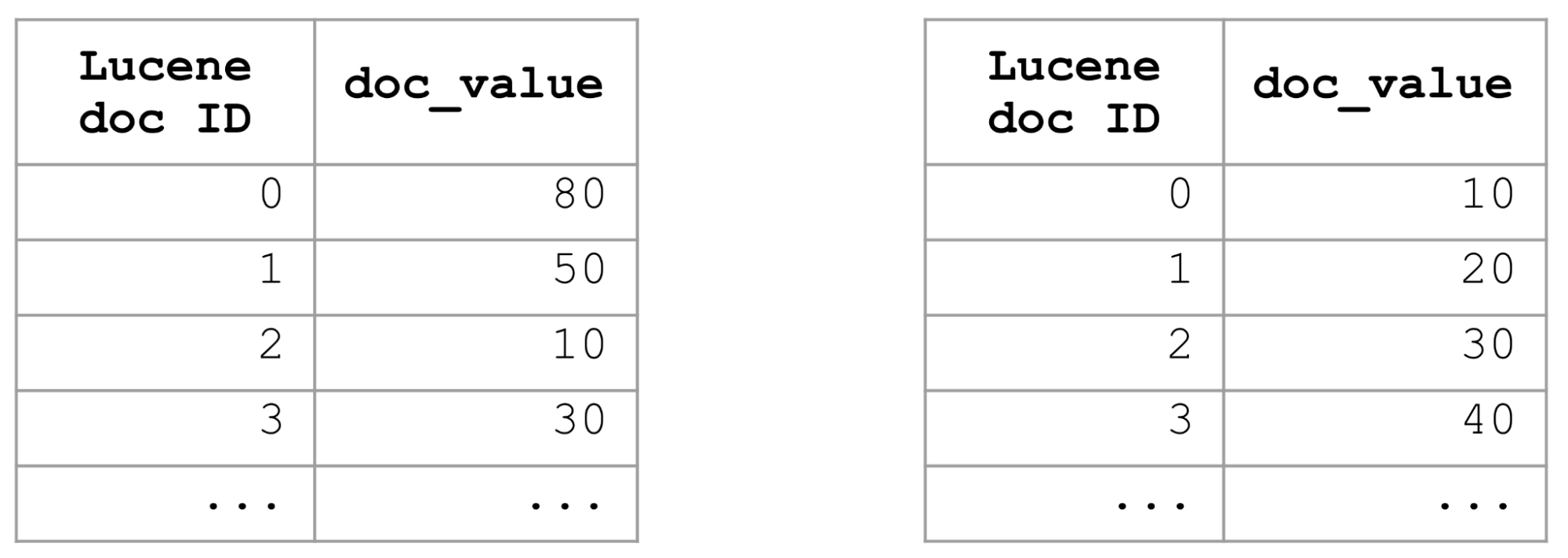
A classificação do índice é uma ótima solução, mas você só pode fazê-la de uma única maneira. A classificação do índice não é útil para consultas de classificação que usam critérios diferentes, como decrescente X crescente, campos diferentes ou combinações diferentes daquelas definidas em uma definição de classificação de índice. Portanto, precisávamos de outras abordagens mais flexíveis para acelerar as consultas de classificação.
Otimização de consultas de classificação numérica com a consulta distance_feature
No passado, obtivemos acelerações significativas em consultas baseadas em termos classificadas por _score, armazenando para cada bloco de documentos seu impacto máximo — uma combinação de frequência do termo e comprimento do documento. Durante o tempo de consulta, podemos avaliar rapidamente se um bloco de documentos é competitivo observando o seu impacto máximo. Caso um bloco não seja competitivo, podemos ignorar todo esse bloco de documentos, o que torna as consultas significativamente mais rápidas.
Nós pensamos que poderíamos aplicar uma abordagem semelhante para acelerar as consultas de classificação em campos numéricos ou de data. Acabou sendo possível substituir a classificação por uma consulta distance_feature. A consulta distance_feature é interessante porque retorna os mil melhores documentos mais próximos de uma determinada origem. Se usarmos o valor mínimo do campo como origem, obteremos os mil melhores documentos classificados em ordem crescente. Usar o valor máximo como origem nos renderá os mil melhores documentos em ordem decrescente.
A propriedade mais interessante da consulta distance_feature para nós é que ela pode ignorar com eficiência os blocos de documentos não competitivos. Isso é feito com base nas propriedades das árvores BKD que são usadas no Elasticsearch para indexar campos numéricos e de data. Semelhante à forma como um índice de postagens para um campo de texto é dividido em blocos de documentos, um índice BKD é dividido em células, com cada célula conhecendo seus valores mínimo e máximo. Assim, apenas examinando os valores mínimo e máximo das células, uma consulta distance_feature pode ignorar com eficiência as células de documentos não competitivas. Para que essa otimização de classificação funcione, um campo numérico ou de data precisa ser indexado e ter valores de documento.
Ao substituir a classificação nos valores de documento por uma consulta distance_feature, foi possível obter grandes acelerações (chegando até a ganhos de 35x em alguns conjuntos de dados). Introduzimos essa otimização de classificação em campos longos e de data no Elasticsearch 7.6.
Otimização de consultas de classificação com search_after
Ficamos felizes em ver essas acelerações, mas ainda não tínhamos uma boa solução para a classificação com um parâmetro search_after. A classificação com search_after é muito comum, pois os usuários geralmente estão interessados não apenas na primeira página de resultados, mas também nas páginas subsequentes. Decidimos que, em vez da nossa abordagem atual de reescrever as consultas de classificação no Elasticsearch, uma solução melhor seria fazer com que os comparadores e os coletores no Lucene fizessem essa otimização da classificação e ignorar documentos não competitivos. Como os comparadores e os coletores no Lucene já lidam com o search_after, isso nos permitiria ter uma solução para esse problema também. O mesmo código do Elasticsearch que a consulta distance_feature estava usando para ignorar blocos de documentos não competitivos foi adicionado aos comparadores numéricos do Lucene.
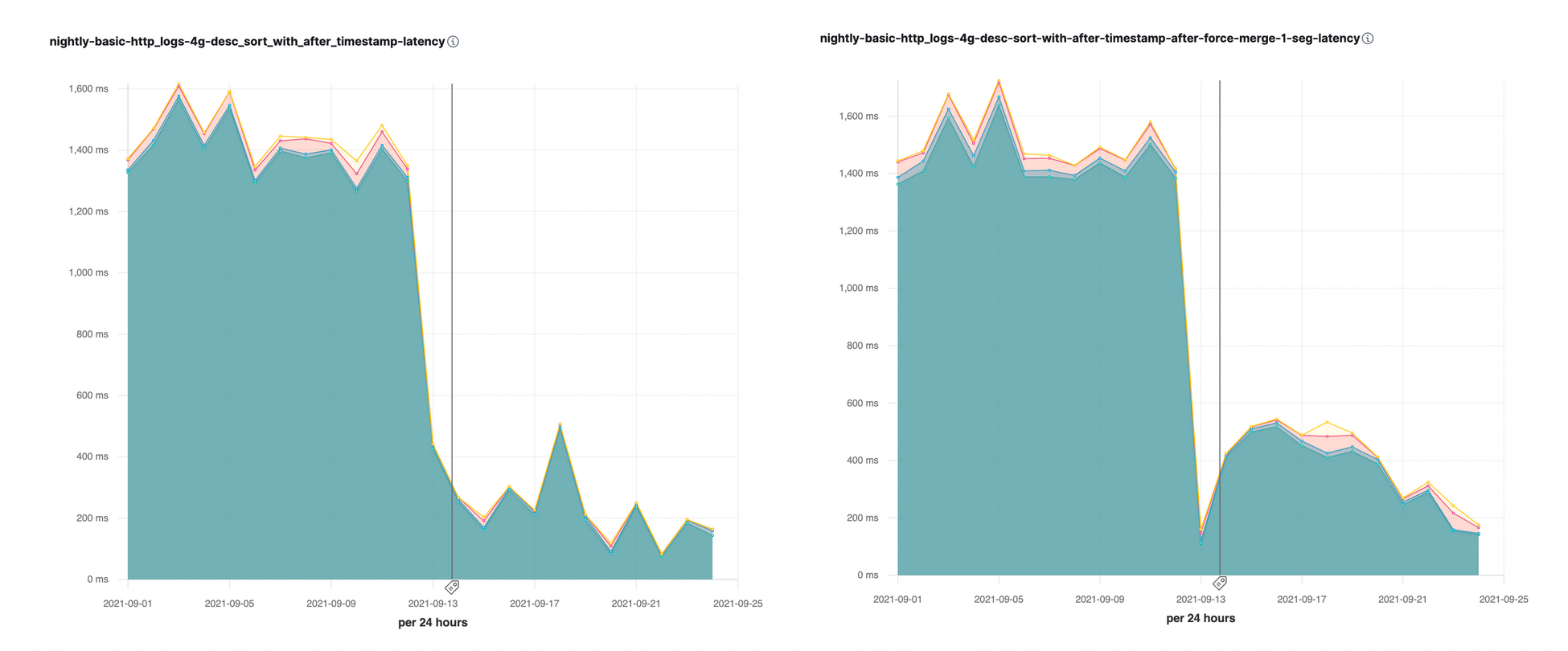
Introduzimos essa otimização de classificação com o parâmetro search_after no Elasticsearch 7.16. Vimos imediatamente grandes acelerações (até 10x) em alguns dos nossos comparativos de desempenho noturnos:
Otimização da classificação em vários segmentos
Um shard consiste em vários segmentos. Como o Elasticsearch examina os segmentos sequencialmente no momento da busca, seria muito benéfico iniciar o processamento com o segmento que é o melhor candidato para conter documentos com os mil melhores valores. Depois de coletarmos os documentos com os mil melhores valores, podemos ignorar rapidamente outros segmentos que contenham apenas valores piores.
A escolha dos segmentos pelos quais iniciar o processamento depende muito do caso de uso. Para índices de séries temporais, a solicitação mais comum é classificar os resultados no campo do registro de data/hora em ordem decrescente, pois os eventos mais recentes são os mais interessantes para serem observados. Para otimizar esse tipo de classificação para índices de séries temporais, começamos a classificar os segmentos no campo @timestamp em ordem decrescente, para que pudéssemos começar o processamento com um segmento contendo os dados mais recentes, de preferência coletando no primeiro segmento os documentos mais recentes por registro de data/hora e ignorando todos os outros segmentos. Isso resultou em acelerações muito boas para as consultas de classificação no campo de registro de data/hora em ordem decrescente.
Como os segmentos menores são fundidos em segmentos maiores, não queremos acabar ficando com novos segmentos nos quais os documentos mais recentes estejam no final. Para ter segmentos mesclados mais equilibrados, introduzimos uma nova política de mesclagem que intercala segmentos novos e antigos, ou seja, documentos de segmentos novos e antigos são organizados em ordem mista em um novo segmento combinado. Isso também nos permite encontrar com eficiência os documentos mais recentes.
Otimização da classificação em vários shards
O poder do Elasticsearch está em sua busca distribuída, e qualquer otimização seria incompleta sem pensar em um aspecto distribuído. Como algumas buscas podem abranger centenas de shards (por exemplo, buscas em índices de séries temporais), seria muito benéfico começar com os conjuntos “certos” de shards e evitar os com menor probabilidade de conter resultados competitivos. Nós implementamos exatamente essa abordagem. No Elasticsearch 7.6, pré-classificamos os shards com base no valor máximo/mínimo do campo de classificação principal, o que nos permite iniciar uma busca distribuída com um conjunto de shards que sejam os melhores candidatos para conter os melhores valores. A partir do Elasticsearch 7.7, cortamos caminho na fase de consulta usando os resultados de outros shards, ou seja, uma vez que coletamos os melhores valores do primeiro conjunto de shards, podemos ignorar completamente o restante deles, pois todos os seus valores possíveis serão piores do que os piores valores de classificação computados nos shards anteriores. Em muitos índices de série temporal gerados por máquina, os documentos seguem uma política de ciclo de vida do índice, começando em hardware otimizado para desempenho e terminando em hardware otimizado para custo antes de serem excluídos. Esse mecanismo para ignorar os shards geralmente significa que os usuários podem enviar uma consulta ampla e aproveitar o desempenho da consulta definido pelo hardware otimizado para desempenho, porque os shards no hardware mais lento e econômico são ignorados (tornando o uso dos snapshots buscáveis particularmente eficiente).
Implicações para os usuários
Como você, como usuário do Elasticsearch, pode aproveitar essas otimizações da classificação? Essas otimizações da classificação só funcionam se você não precisa rastrear o número exato de ocorrências totais de uma solicitação e se a solicitação não contém agregações. Se você precisa saber o número exato de ocorrências totais, não podemos ignorar nada, pois precisamos contar todos os documentos que correspondem a um filtro. O valor padrão de track_total_hits é definido como 10.000, o que significa que a otimização da classificação só começa quando coletamos 10 mil documentos. Se você definir esse valor como um número menor ou como “false”, o Elasticsearch iniciará a otimização da classificação muito mais cedo, o que significa respostas mais rápidas para você.
Recentemente, o Kibana também começou a enviar solicitações nas quais track_total_hits estava desabilitado, portanto, as consultas de classificação no Kibana também devem ser mais rápidas.
Experimente
Quem já trabalha com o Elastic Cloud pode acessar muitos desses recursos diretamente no console Elastic Cloud. Se você está começando agora no Elastic Cloud, dê uma olhada em nossos guias Quick Start (pequenos vídeos de treinamento para você começar rapidamente) ou nossos cursos gratuitos de treinamento sobre fundamentos. Você pode começar gratuitamente com uma avaliação gratuita do Elastic Enterprise Search por 14 dias. Ou baixe a versão autogerenciada do Elastic Stack também gratuitamente.
Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir