Monitoramento do Google Cloud com o Elastic Stack e o Google Operations
O pacote Google Operations, antigo Stackdriver, é um repositório central que recebe logs, métricas e traces de aplicações dos recursos do Google Cloud. Esses recursos podem incluir mecanismo de computação, mecanismo de aplicação, fluxo de dados e processamento de dados, bem como soluções de SaaS, como o BigQuery. Ao enviar esses dados para a Elastic, você terá uma visão unificada do desempenho dos recursos em toda a sua infraestrutura, da nuvem ao local.
Neste post, vamos configurar um pipeline para transmitir dados do Google Operations para o Elastic Stack para que você possa analisar seus logs do Google Cloud junto com seus outros dados de observabilidade. Para esta demonstração, usaremos o módulo para Google Cloud do Filebeat e enviaremos seus dados do Google Cloud para uma avaliação gratuita do Elastic Cloud para análise. Recomendo que você me acompanhe!
Fluxo de dados geral
Para esta demonstração, enviaremos logs de auditoria, firewall e fluxo de VPC dos recursos do Google Cloud para as operações do Google Cloud. A partir daí, criaremos coletores, tópicos do Pub/Sub, faremos a assinatura como Filebeat e enviaremos nossos dados para o Elastic Cloud para análise posterior com o Elasticsearch e o Kibana. Este diagrama fornece um fluxo geral, mostrando o caminho que os dados percorrerão até o nosso cluster:
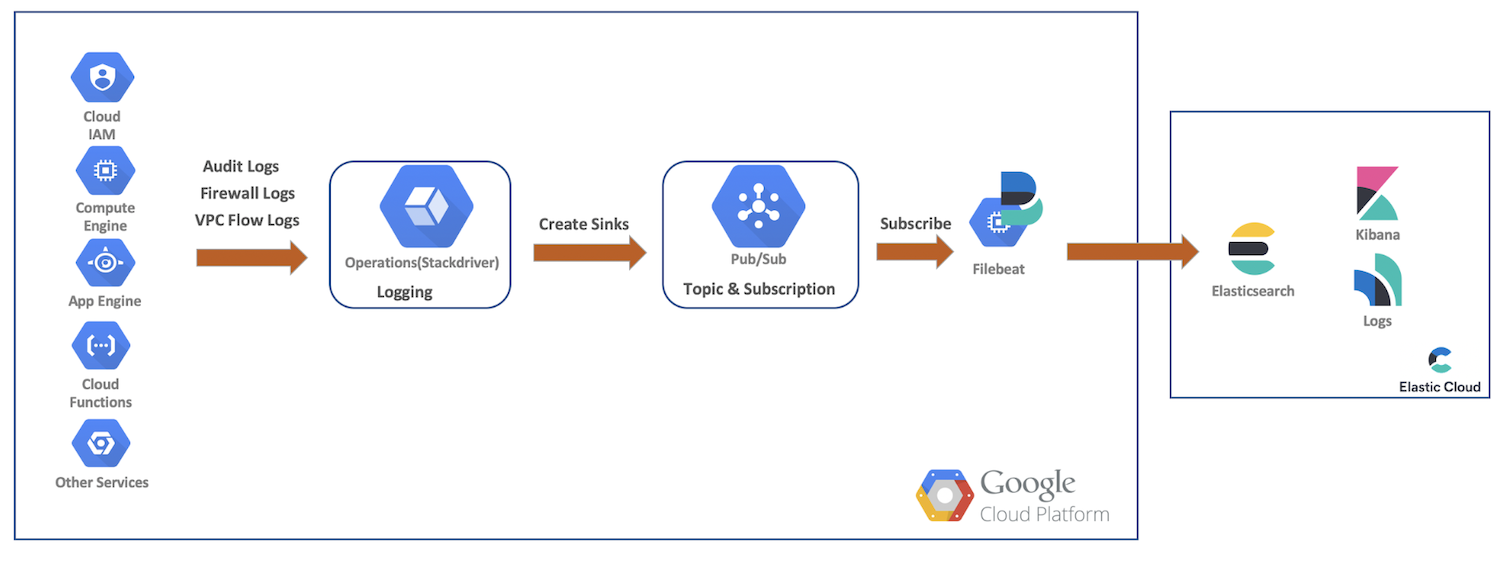
Instalação e configurações de logging do Google Cloud
O Google Cloud oferece uma rica UI para habilitar os logs de serviços, enquanto os logs são configurados em seus respectivos consoles. Nas próximas etapas, vamos habilitar vários logs, criar nossos coletores e tópicos e, em seguida, configurar nossa conta de serviço e as credenciais.
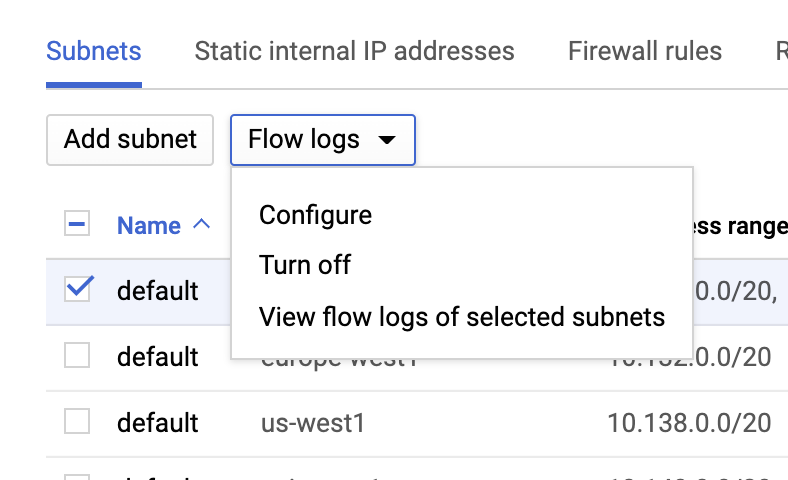
Logs do fluxo da VPC
Você pode habilitar os logs do fluxo da VPC indo para a página VPC network (Rede da VPC), selecionando uma VPC e clicando em Configure (Configurar) na lista suspensa Flow logs (Logs do fluxo):
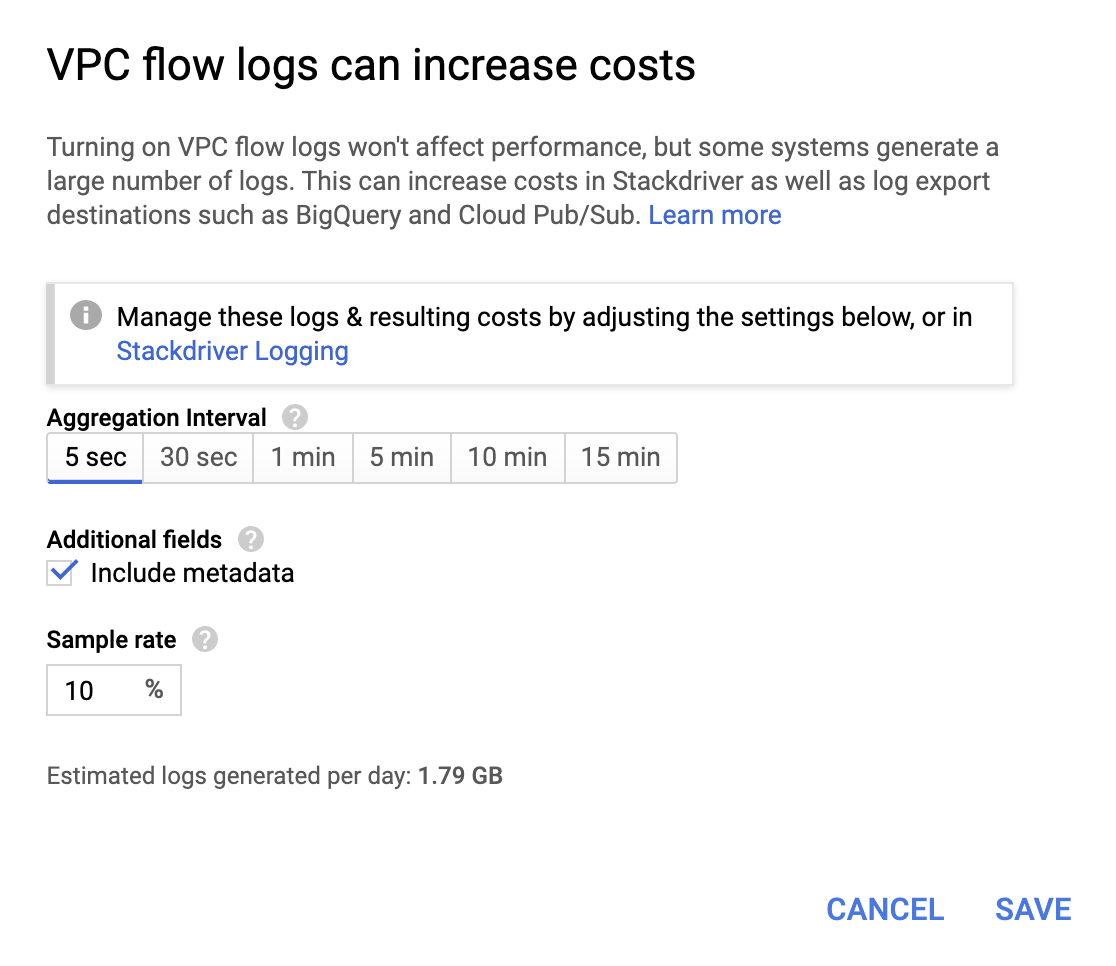
Embora não sejam muito caras, as operações não deixam de aumentar a conta; por isso, escolha um intervalo de agregação e uma taxa de amostra com base nos seus requisitos.
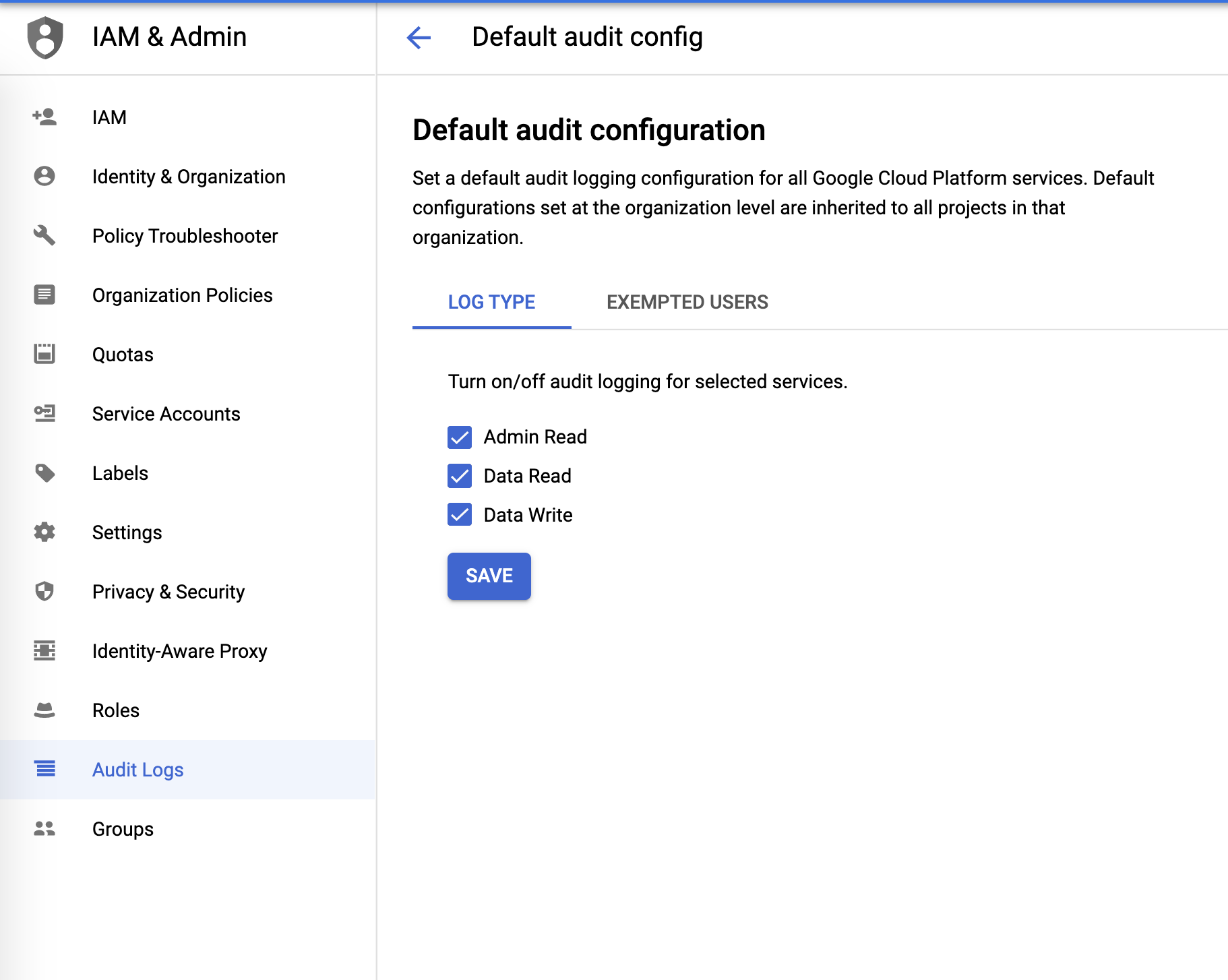
Logs de auditoria
Os logs de auditoria podem ser configurados no menu IAM & Admin (IAM e administrador):
Logs do firewall
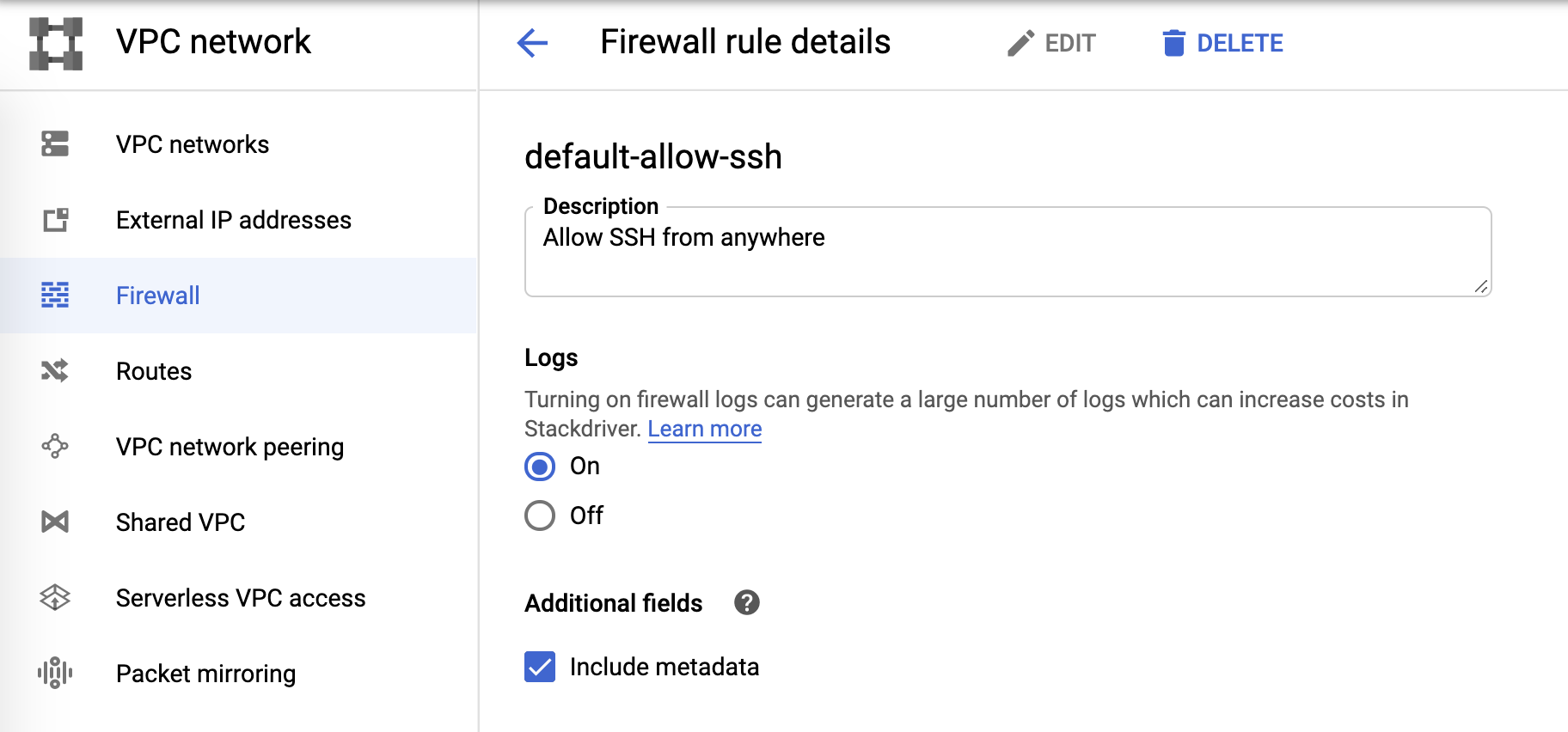
E, finalmente, os logs do firewall podem ser controlados a partir das regras do firewall:
Coletor de log e Pub/Sub
Depois de configurarmos as áreas de logging individuais, podemos criar coletores para cada um dos logs do Logs Viewer (Visualizador de logs):

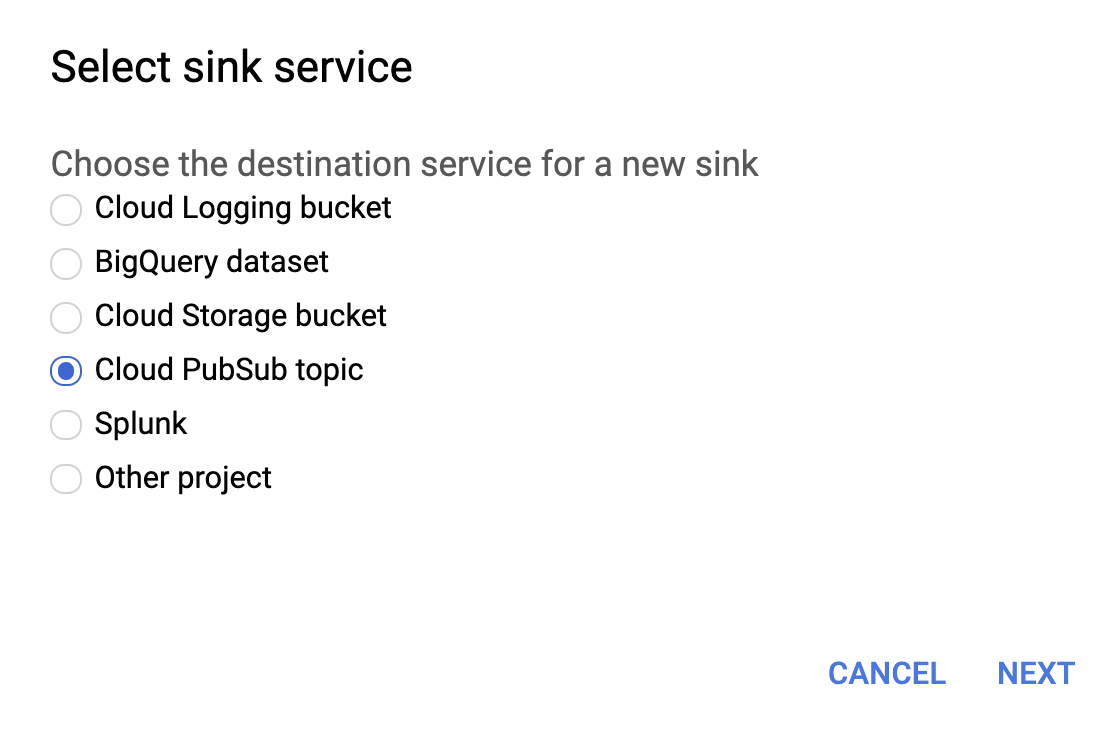
Selecione o tópico do Cloud PubSub do serviço do coletor conforme mostrado abaixo.
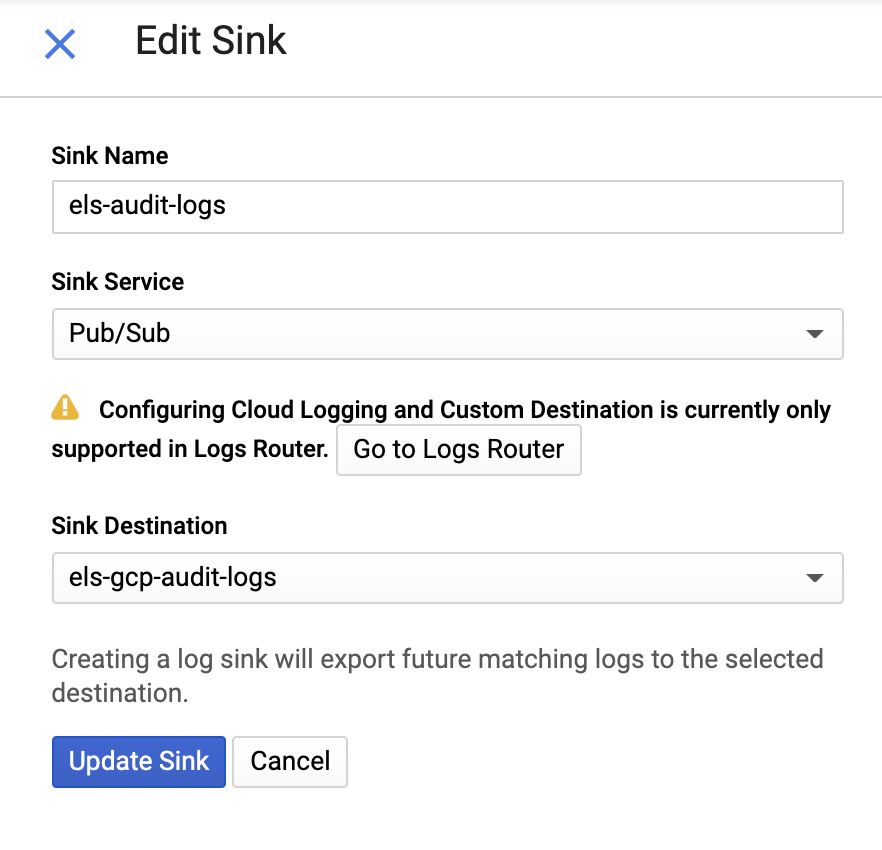
Em seguida, forneça um nome para o coletor e um tópico do Pub/Sub — você pode enviá-lo para um tópico existente ou criar um novo:
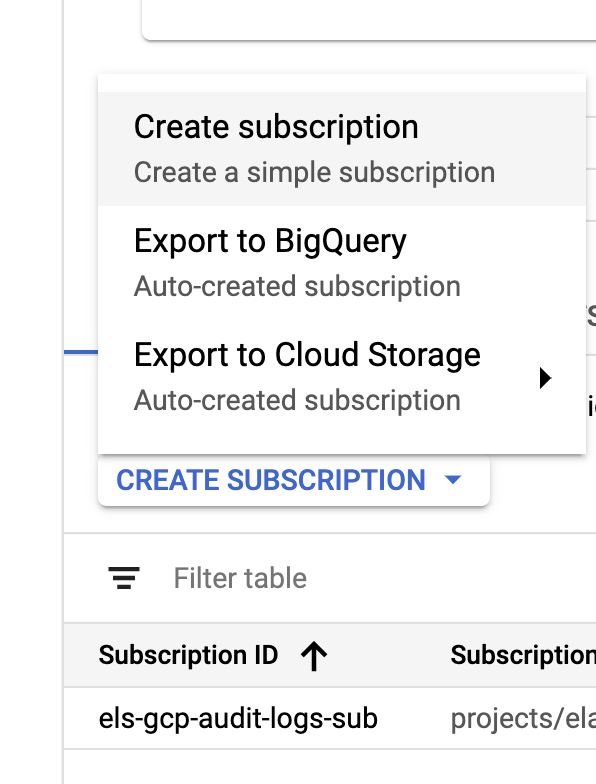
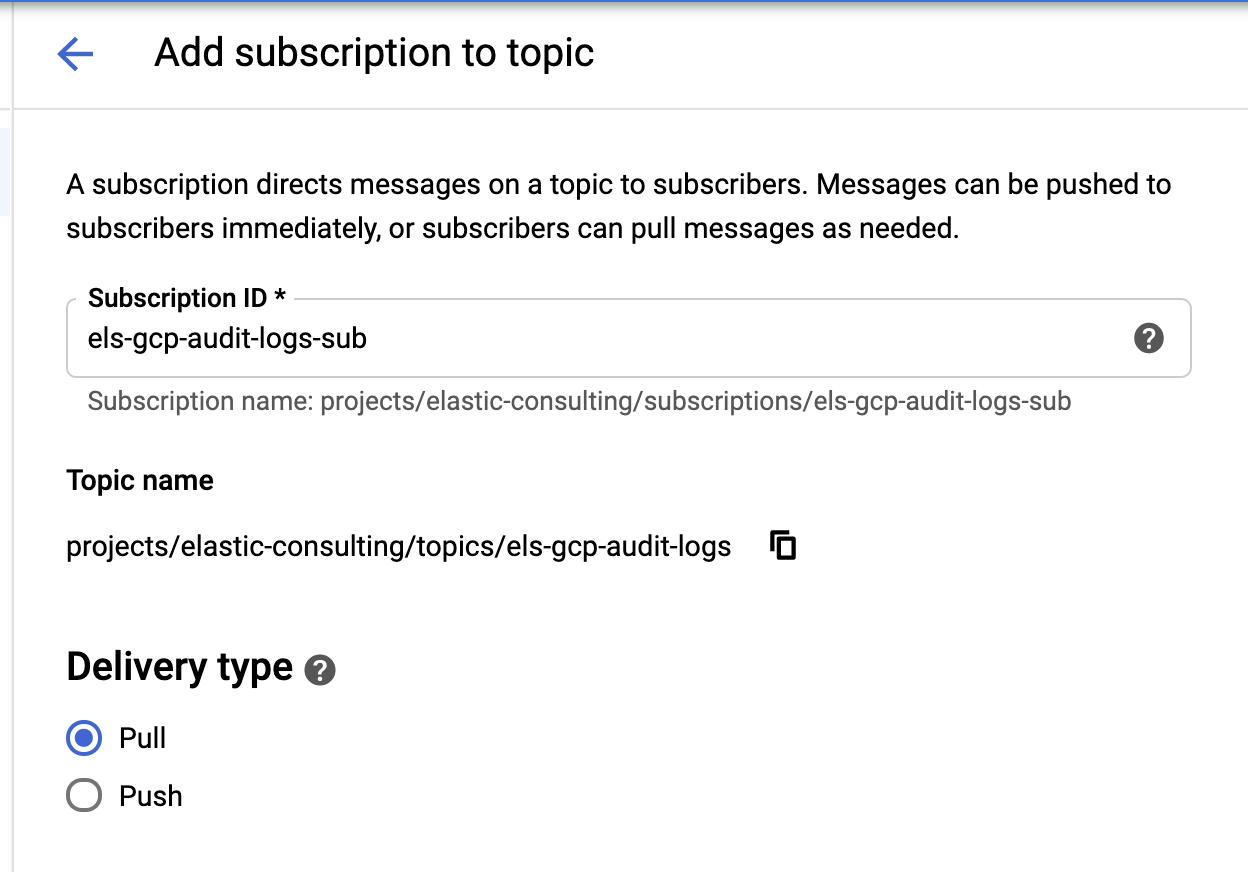
Depois que nosso coletor e os tópicos são criados, é hora de criar as assinaturas do tópico do Pub/Sub:
| 
|
Configure a assinatura com base nos seus requisitos.
Conta de serviço e credenciais
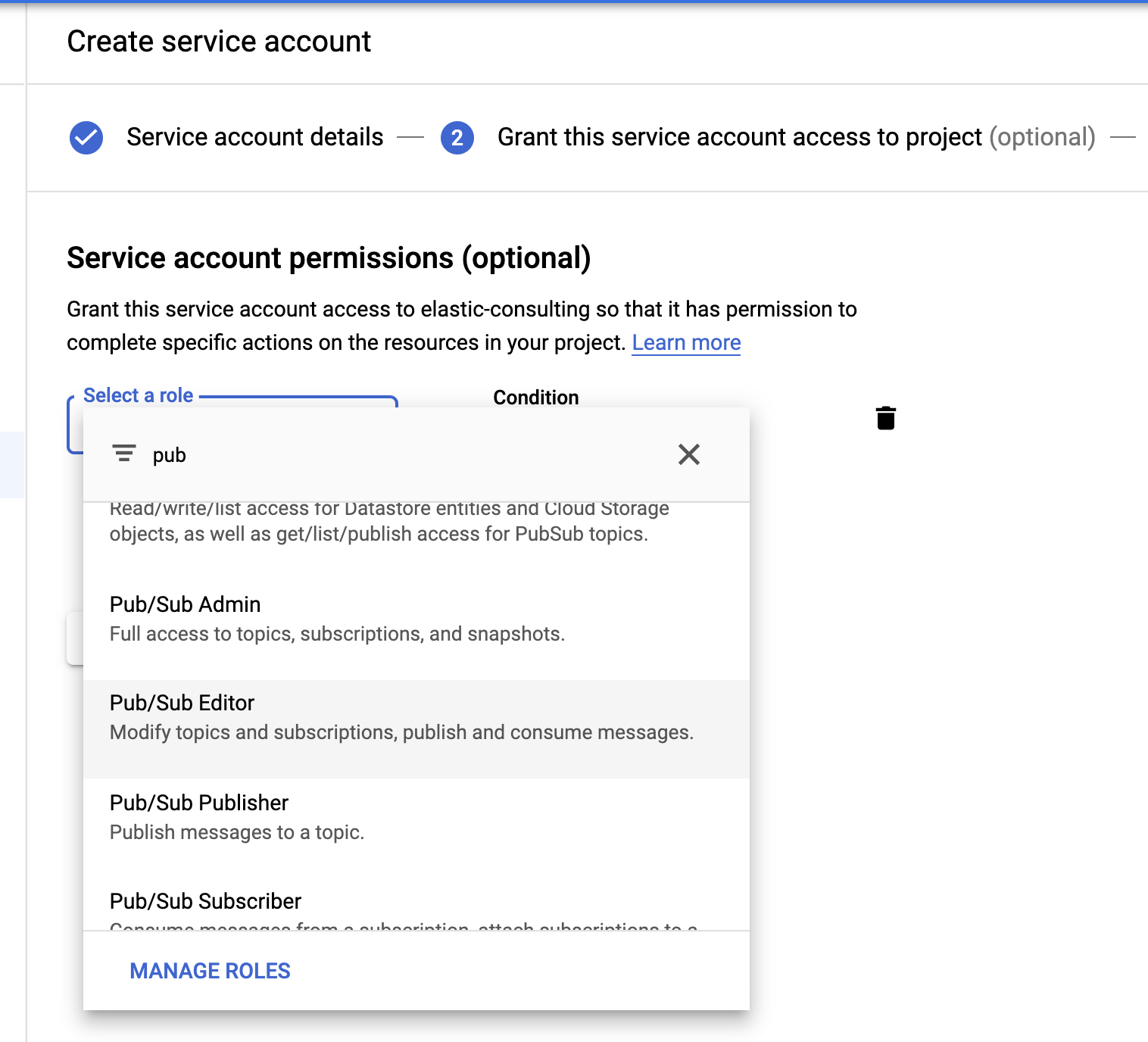
Por último, mas não menos importante, vamos criar uma conta de serviço e um arquivo de credenciais.
Selecione a função Pub/Sub Editor (Editor do Pub/Sub); a condição é opcional e pode ser usada para filtrar os tópicos.
Depois que a conta de serviço for criada, geraremos uma chave JSON que será carregada no host do Filebeat e armazenada no diretório de configuração do Filebeat, /etc/filebeat. Essa chave será usada pelo Filebeat para autenticar como a conta de serviço.

Agora a nossa configuração do Google Cloud está concluída.
Instalar e configurar o Filebeat
O Filebeat é usado para coletar os logs e enviá-los para o nosso cluster do Elasticsearch. Usaremos o CentOS para este post, mas o Filebeat pode ser instalado com base no seu sistema operacional seguindo estas etapas simples da nossa documentação do Filebeat.
Habilitar o módulo para Google Cloud
Assim que o Filebeat estiver instalado, precisaremos habilitar o módulo googlecloud:
filebeat modules enable googlecloud
Copie o arquivo de credenciais JSON que criamos anteriormente para /etc/filebeat/ e, em seguida, modifique o arquivo /etc/filebeat/modules.d/googlecloud.yml para que corresponda à sua configuração do Google Cloud.
Algumas das configurações já foram feitas para você; por exemplo, todos os três módulos estão listados, e todas as configurações necessárias foram fornecidas — você só precisa atualizá-las para os valores com base na sua instalação.
# Módulo: googlecloud
# Documentos: https://www.elastic.co/guide/en/beats/filebeat/7.9/filebeat-module-googlecloud.html
- module: googlecloud
vpcflow:
enabled: true
# ID do projeto do Google Cloud.
var.project_id: els-dummy
# Tópico do Google Pub/Sub contendo logs do fluxo da VPC. O Stackdriver deve ser
# configurado para usar esse tópico como um coletor dos logs do fluxo da VPC.
var.topic: els-gcp-vpc-flow-logs
# Assinatura do Google Pub/Sub para o tópico. O Filebeat criará essa
# assinatura se ela não existir.
var.subscription_name: els-gcp-vpc-flow-logs-sub
# Arquivo de credenciais da conta de serviço com autorização para ler da
# assinatura.
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
firewall:
enabled: true
# ID do projeto do Google Cloud.
var.project_id: els-dummy
# Tópico do Google Pub/Sub contendo logs do firewall. O Stackdriver deve ser
# configurado para usar esse tópico como um coletor dos logs do firewall.
var.topic: els-gcp-firewall-logs
# Assinatura do Google Pub/Sub para o tópico. O Filebeat criará essa
# assinatura se ela não existir.
var.subscription_name: els-gcp-firewall-logs-sub
# Arquivo de credenciais da conta de serviço com autorização para ler da
# assinatura.
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
audit:
enabled: true
# ID do projeto do Google Cloud.
var.project_id: els-dummy
# Tópico do Google Pub/Sub contendo logs de auditoria. O Stackdriver deve ser
# configurado para usar esse tópico como um coletor dos logs do firewall.
var.topic: els-gcp-audit-logs
# Assinatura do Google Pub/Sub para o tópico. O Filebeat criará essa
# assinatura se ela não existir.
var.subscription_name: els-gcp-audit-logs-sub
# Arquivo de credenciais da conta de serviço com autorização para ler da
# assinatura.
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
Por fim, configure o Filebeat para apontar para seus endpoints do Kibana e do Elasticsearch.
Você pode definir setup.dashboards.enabled: true no seu arquivo filebeat.yml para carregar um dashboard pré-criado para o Google Cloud, de acordo com a documentação de endpoint do Kibana e do Elasticsearch.
Apenas a título de observação, o Filebeat oferece uma ampla variedade de módulos com dashboards pré-criados. Neste post, estamos abordando apenas o módulo do Google Cloud, mas incentivo você a explorar os outros módulos do Filebeat disponíveis para ver o que pode ser útil.
Iniciar o Filebeat
Finalmente, podemos iniciar o Filebeat e adicionar o sinalizador -e para que ele simplesmente registre a saída no console:
sudo service filebeat start -e
Exploração dos seus dados no Kibana
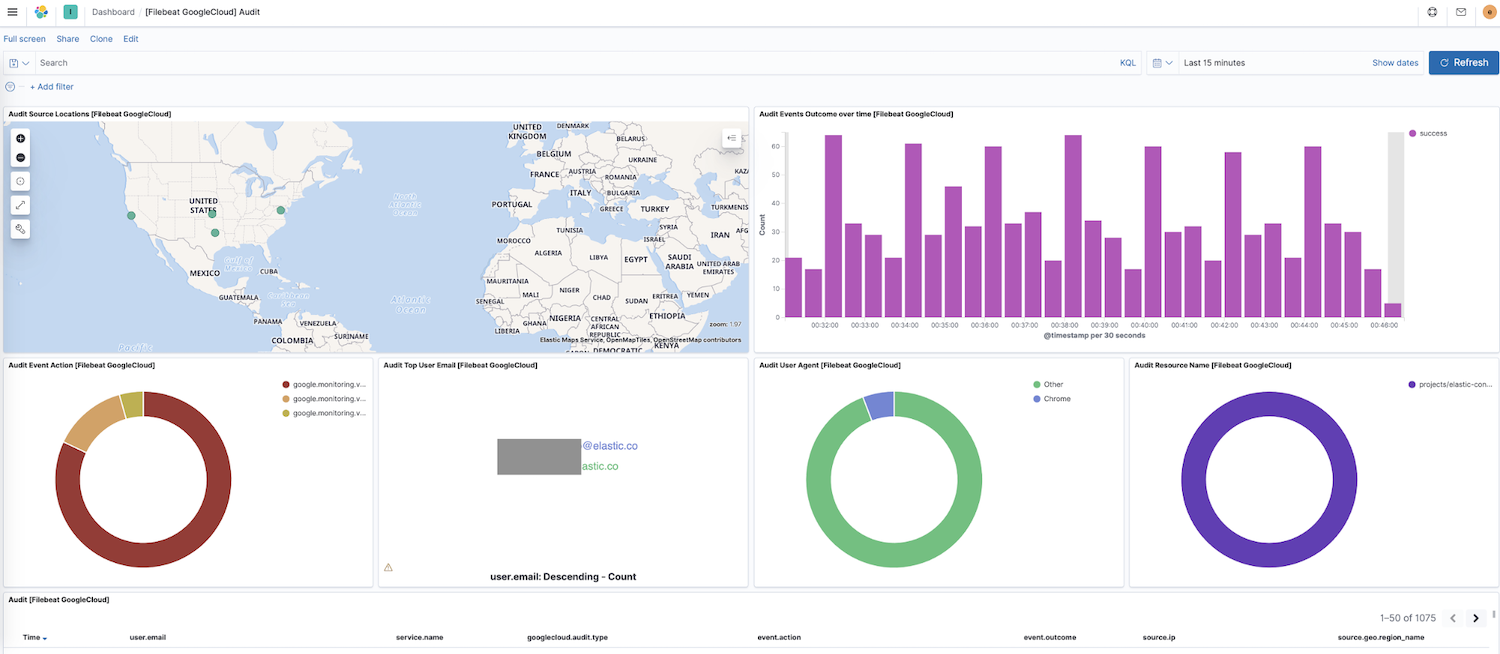
Agora que o Filebeat está enviando dados para o seu cluster, vamos navegar para Dashboard na navegação lateral do Kibana. Se você tiver dashboards de outros módulos, poderá pesquisar google para encontrar os dashboards do nosso módulo recém-habilitado. Neste caso, vemos o dashboard “Audit” (Auditoria) do Google Cloud.
Nesse dashboard, as visualizações serão exibidas como um mapa dinâmico de locais de origem, resultados de eventos ao longo do tempo, um detalhamento das ações dos eventos e muito mais. Explorar seus dados de log é intuitivo com essas visualizações interativas e pré-criadas. Se estiver configurando o Filebeat pela primeira vez ou estiver executando uma versão mais antiga do Elastic Stack (o módulo do Google Cloud entrou em disponibilidade geral na versão 7.7), você precisará carregar os dashboards seguindo estas instruções.
Além disso, a Elastic fornece uma solução de observabilidade com um app de monitoramento de log. Os índices de log podem ser configurados; os valores padrão são filebeat-* e logs-*.
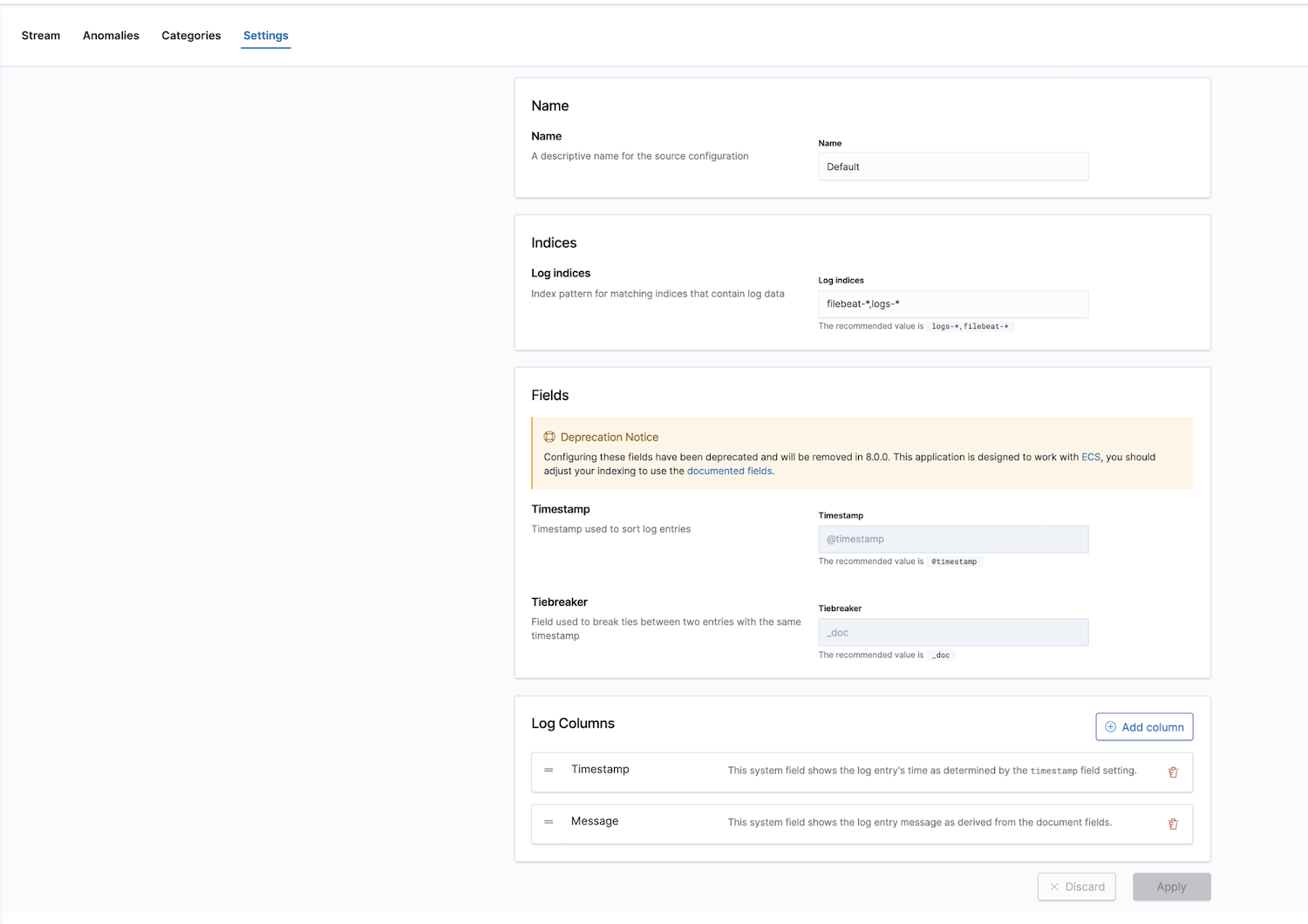
Depois de configurar os padrões de indexação corretos nas configurações, você pode explorar seus logs no app Logs, que permite visualizar detalhes e, mais importante, definir trabalhos de machine learning para comportamento anômalo, categorizar os dados e criar um alerta.
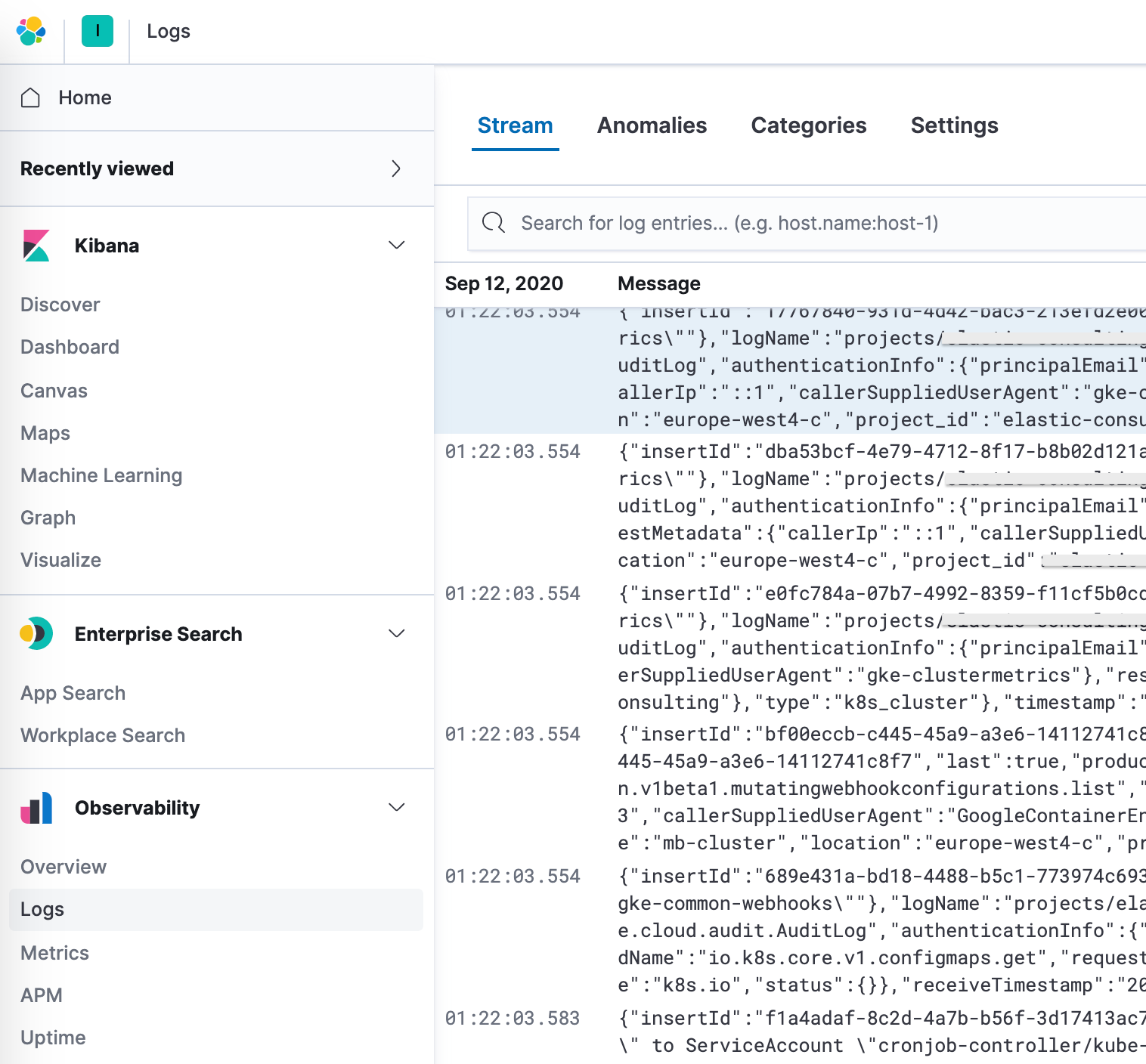
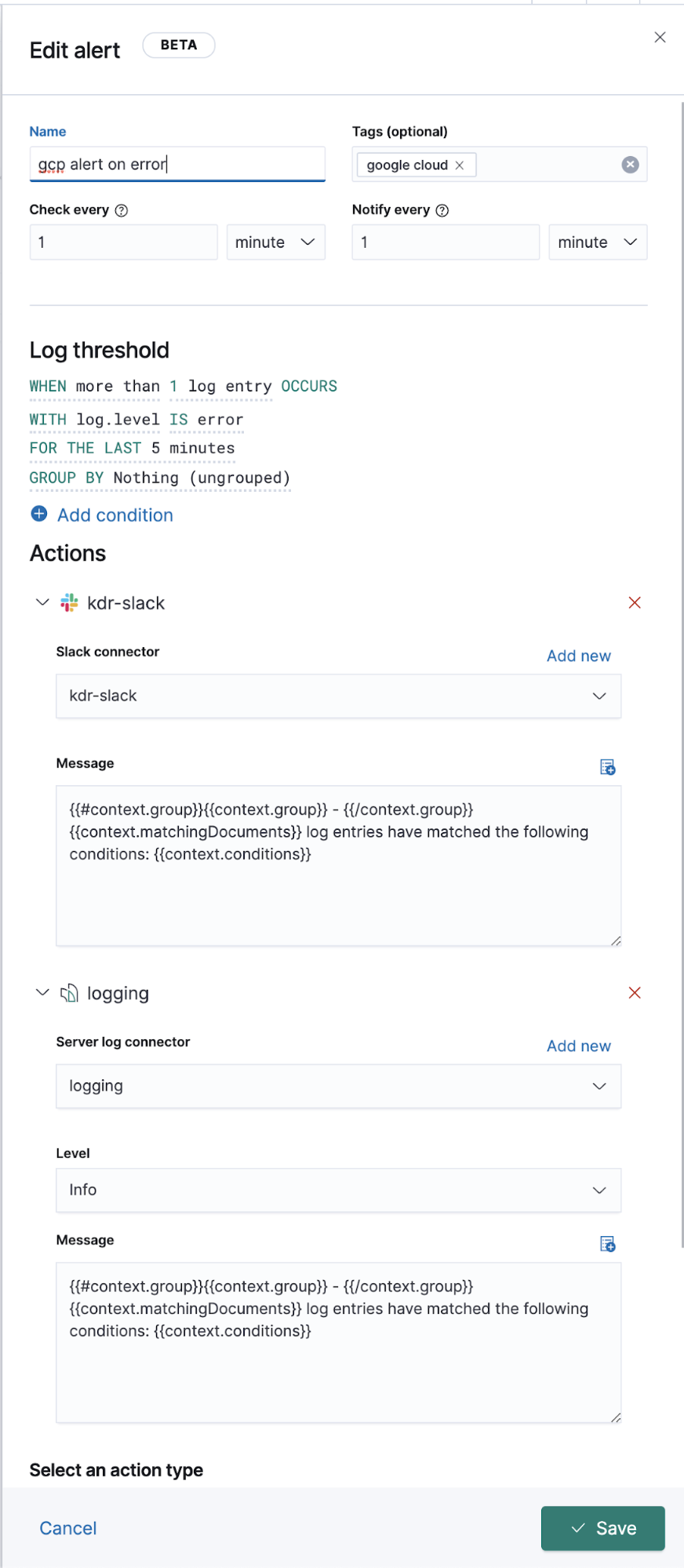
Logging estendido do Google Operations (Stackdriver)
Acima, discutimos como enviar logs de operações para os logs que têm módulos do Filebeat, mas e quanto aos outros sem um módulo do Filebeat dedicado? Abaixo, discutiremos como enviá-los para a Elastic também, para visualização junto com seus outros dados de log.
Do ponto de vista da instalação e configuração do Google Cloud, tudo, incluindo o fluxo, permanece igual. Criamos um coletor, um tópico, uma assinatura, um sa e uma chave JSON. A diferença está apenas na configuração do Filebeat.
Em segundo plano, os módulos trabalham com as entradas e com análise pré-configurada no nível da fonte, além de pipelines de ingestão em alguns casos. Os módulos do Filebeat simplificam a coleta, a análise e a visualização de formatos de log comuns; porém, para entradas do Filebeat, é necessária análise adicional em alguns casos.
O módulo googlecloud usa a entrada google-pubsub de forma subjacente e fornece alguns pipelines de ingestão específicos do módulo. Ele dá suporte a logs vpcflow, audit e firewall prontos para uso.
Configuração
Em vez de usar um módulo do Filebeat, assinaremos esses tópicos a partir de uma entrada do Filebeat.
Adicione ao seu arquivo filebeat.yml:
filebeat.inputs: - type: google-pubsub enabled: true pipeline: gcp-pubsub-parse-message-field tags: ["gcp-pubsub"] project_id: elastic-consulting topic: gcp-gke-container-logs subscription.name: gcp-gke-container-logs-sub credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
Nessa entrada, estamos especificando o tópico e qual assinatura será usada. Também estamos especificando o arquivo de credenciais e um pipeline de ingestão que definiremos a seguir.
Pipelines de ingestão
Um pipeline de ingestão é uma definição de uma série de processadores que devem ser executados na mesma ordem em que são declarados.
O Google Cloud Operations armazena logs e corpos de mensagens no formato JSON, o que significa que precisamos apenas adicionar um processador JSON no pipeline para extrair dados do campo da mensagem para campos individuais no Elasticsearch.
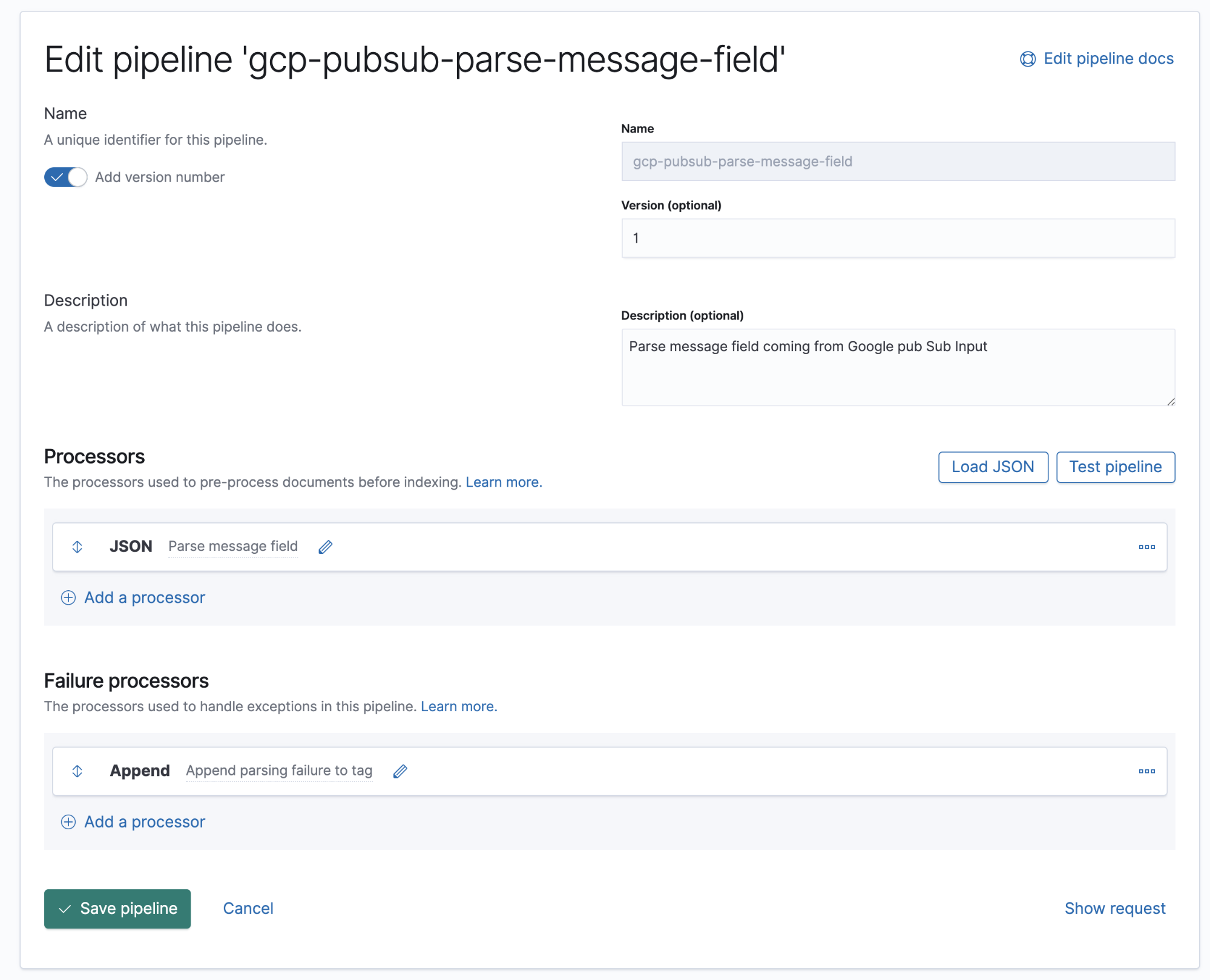
Neste pipeline, temos um processador JSON que fornece dados do campo message no documento e os extrai para um campo de destino chamado log.
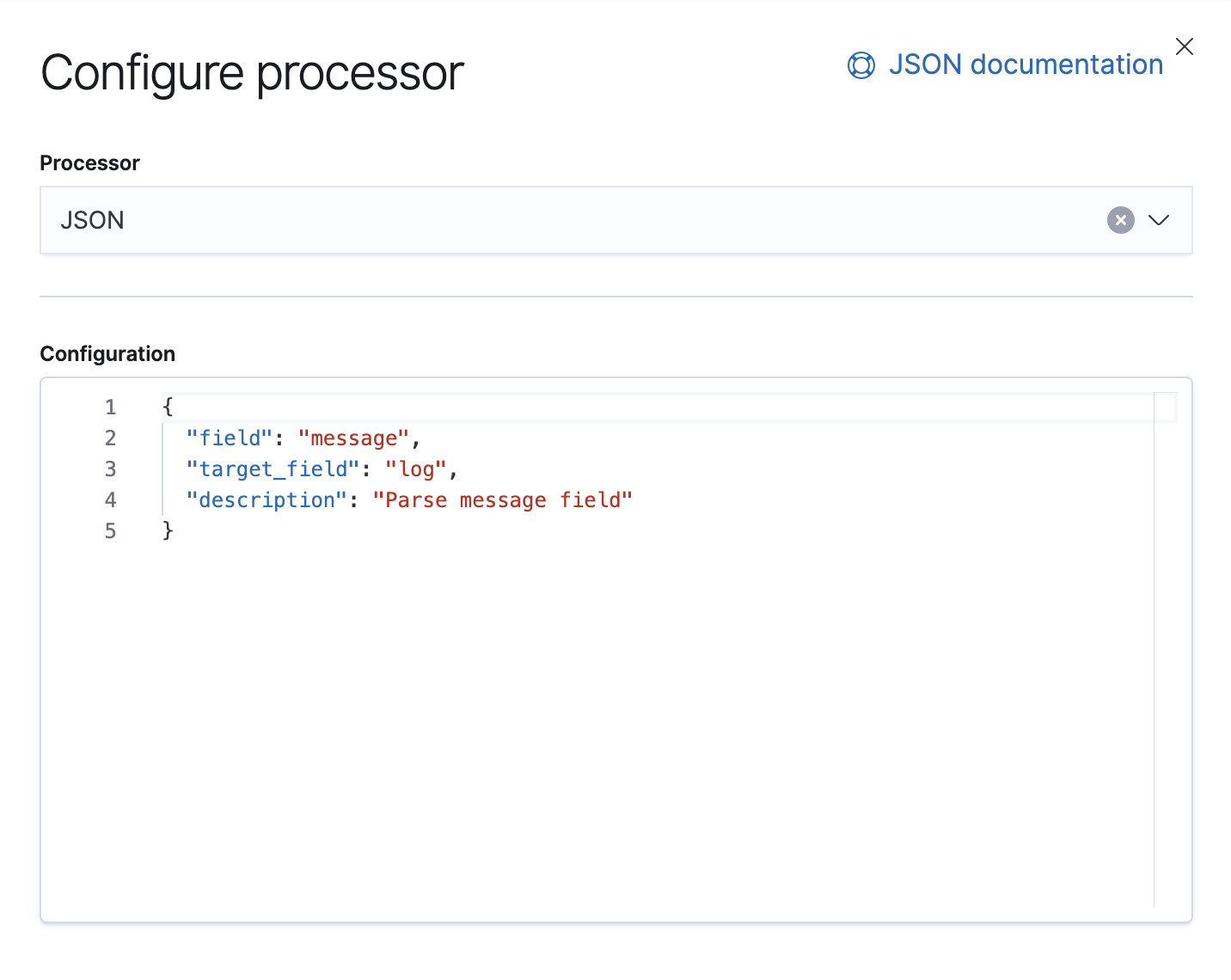
Também temos um processador de falha que está ali para lidar com exceções nesse pipeline; nesse caso, apenas anexaremos uma tag.
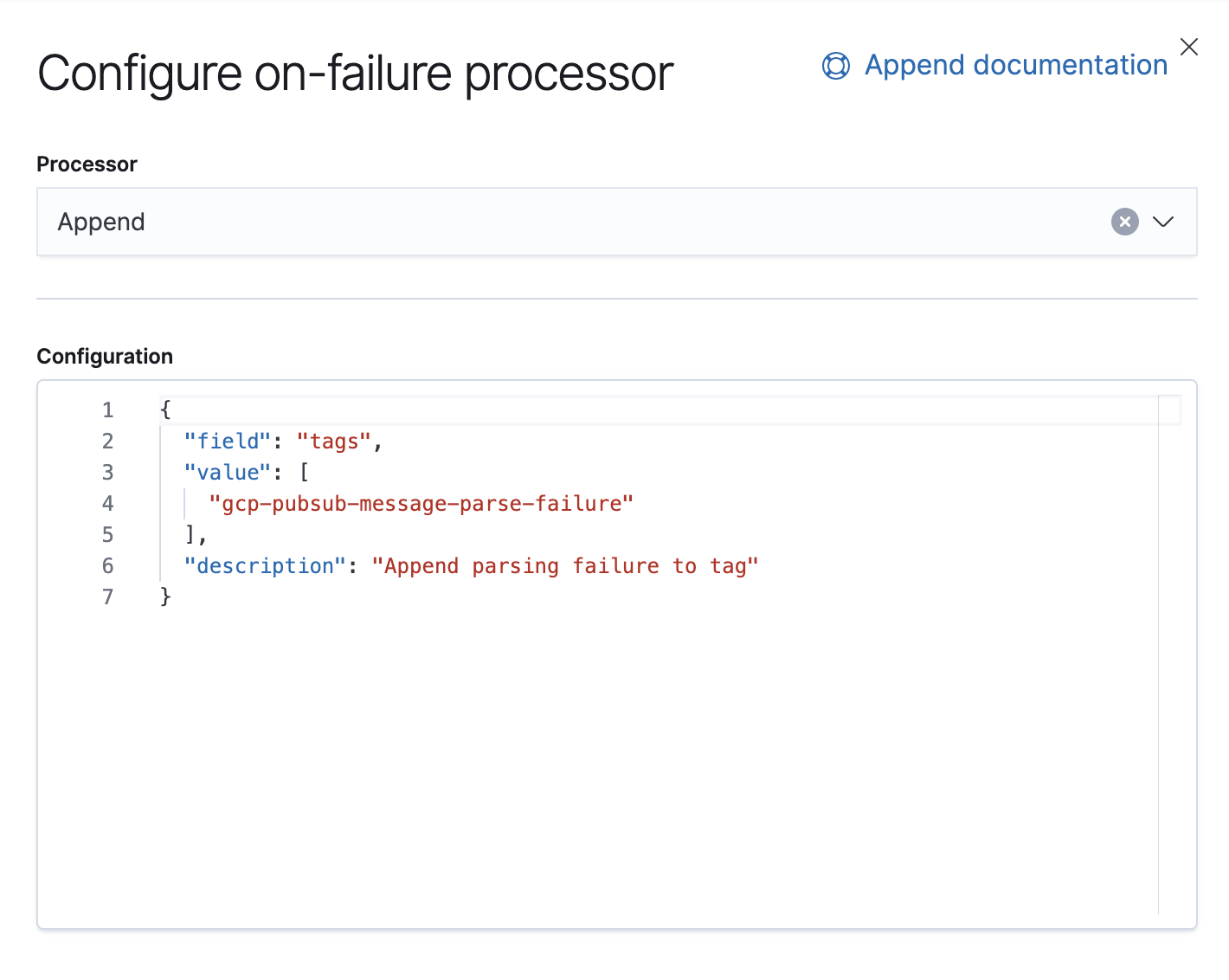
A partir da versão 7.8, os pipelines de ingestão podem ser construídos a partir de uma UI no Kibana, em Stack Management (Gerenciamento da stack) → Ingest Node Pipelines (Pipelines do nó de ingestão). Caso você esteja com uma versão anterior, poderá usar APIs. Aqui está a API equivalente para esse pipeline.
PUT _ingest/pipeline/gcp-pubsub-parse-message-field
{
"version": 1,
"description": "Parse message field coming from Google pub Sub Input",
"processors": [
{
"json": {
"field": "message",
"target_field": "log",
"description": "Parse message field"
}
}
],
"on_failure": [
{
"append": {
"field": "tags",
"value": [
"gcp-pubsub-message-parse-failure"
],
"description": "Append parsing failure to tag"
}
}
]
}
Salvaremos esse pipeline e, contanto que tenhamos esse mesmo pipeline configurado na entrada google-pubsub, deveremos começar a ver os logs analisados no Kibana.
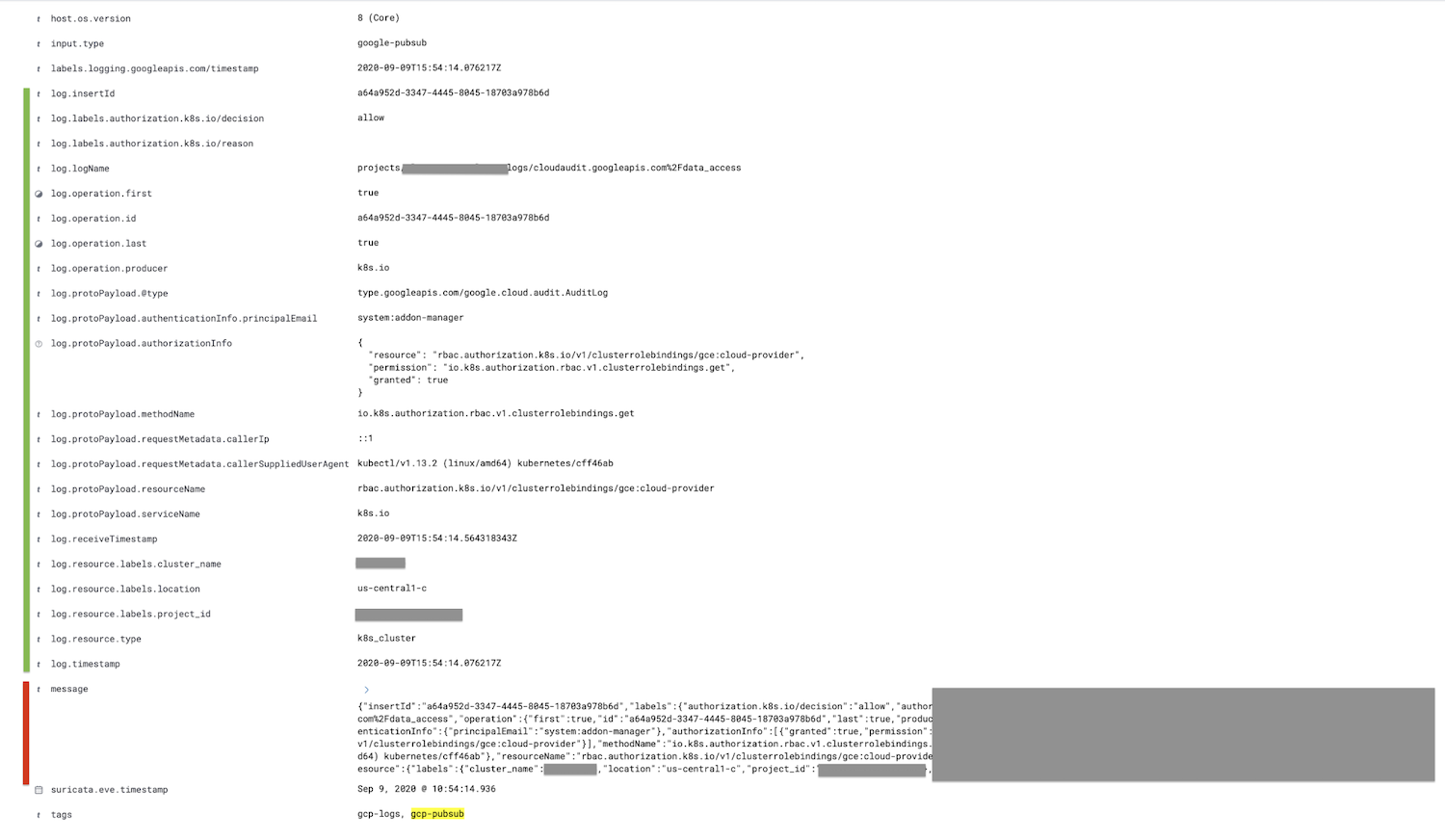
O campo marcado em vermelho, que é o campo de mensagem, é analisado no campo de log, e todos os campos filho são aninhados, sendo mostrados em verde.
Opcionalmente, o campo de mensagem pode ser removido após o processador JSON no pipeline de ingestão usando o processador de remoção; isso reduzirá o tamanho do documento.
Resumo
Isso é tudo neste post — agradecemos a sua atenção. Se tiver dúvidas, inicie uma conversa nos nossos fóruns de discussão; teremos o maior prazer em ajudar. Ou saiba mais sobre logging e observabilidade com a Elastic no nosso webinar sob demanda.
Se quiser experimentar esta demonstração, inscreva-se para fazer uma avaliação gratuita do Elasticsearch Service no Elastic Cloud ou baixe a versão mais recente para gerenciá-la você mesmo.