Machine learning na segurança cibernética: como detectar atividade de DGA em dados de rede
Na Parte 1 desta série do blog, demos uma olhada em como poderíamos usar o machine learning do Elastic Stack para treinar um modelo de classificação supervisionado para detectar domínios maliciosos. Nesta segunda parte, veremos como podemos usar o modelo que treinamos para enriquecer os dados de rede com classificações no momento da ingestão. Isso será útil para quem quiser detectar uma possível atividade de DGA em seus dados de packetbeat.
Detecção de DGA com o Elastic Stack
Um programa malicioso que infecta uma máquina geralmente precisa de uma maneira de se comunicar de volta com um servidor controlado pelo invasor — o chamado servidor de comando e controle (C&C ou C2). Para impedir as medidas defensivas que bloqueiam endereços IP ou URLs codificados, os invasores usam algoritmos de geração de domínio (DGAs). Quando o malware precisa entrar em contato com um servidor de C&C, ele usa o DGA para gerar centenas ou milhares de domínios candidatos e tenta resolver um endereço IP para cada um. O invasor então precisa registrar apenas um ou alguns dos domínios gerados pelo DGA para poder se comunicar com a máquina infectada. Os DGAs são semeados e aleatorizados de maneiras diferentes para que seja ainda mais difícil bloqueá-los e detectá-los.
Como a atividade de DGA geralmente envolve consultas de DNS, muitas vezes ela se manifestará nas solicitações de DNS feitas de uma máquina infectada. O Packetbeat pode coletar o tráfego de DNS e enviá-lo ao Elasticsearch para análise. Neste post do blog, veremos como você pode enriquecer as informações da consulta de DNS nos dados do Packetbeat com uma pontuação para indicar o quanto o domínio é malicioso.

Processadores de inferência e o pipeline de ingestão
Para enriquecer os dados do Packetbeat com previsões de um modelo treinado para distinguir os domínios benignos dos maliciosos, precisaremos configurar um pipeline de ingestão com processadores de inferência adequados. Os processadores de inferência oferecem aos usuários uma maneira de usar um modelo treinado no Elastic Stack (ou um modelo treinado em uma de nossas bibliotecas externas compatíveis) para fazer previsões em novos documentos conforme são ingeridos no Elasticsearch. Para entender como todas essas peças móveis se encaixam e quais configurações são necessárias, vamos voltar brevemente à primeira parte deste post.
Na Parte 1, discutimos o processo de treinamento de um modelo de classificação para prever se um determinado domínio é malicioso ou não. Uma das etapas desse processo é executar a engenharia de recursos nos dados de treinamento — um conjunto de domínios maliciosos e benignos conhecidos que nosso modelo usará para aprender como atribuir pontuações a domínios novos e nunca vistos. Os domínios brutos devem ser manipulados para extrair recursos — unigramas, bigramas e trigramas — que sejam úteis para o modelo. O mesmo procedimento de engenharia de recursos também deve ser aplicado aos domínios nos nossos dados do Packetbeat cujo grau de risco queremos avaliar.
É por isso que, além de um processador de inferência, nosso pipeline de ingestão também incluirá processadores de script Painless para extrair unigramas, bigramas e trigramas de dados de DNS do packetbeat no momento da ingestão. Um diagrama com o pipeline completo é ilustrado na Figura 2.
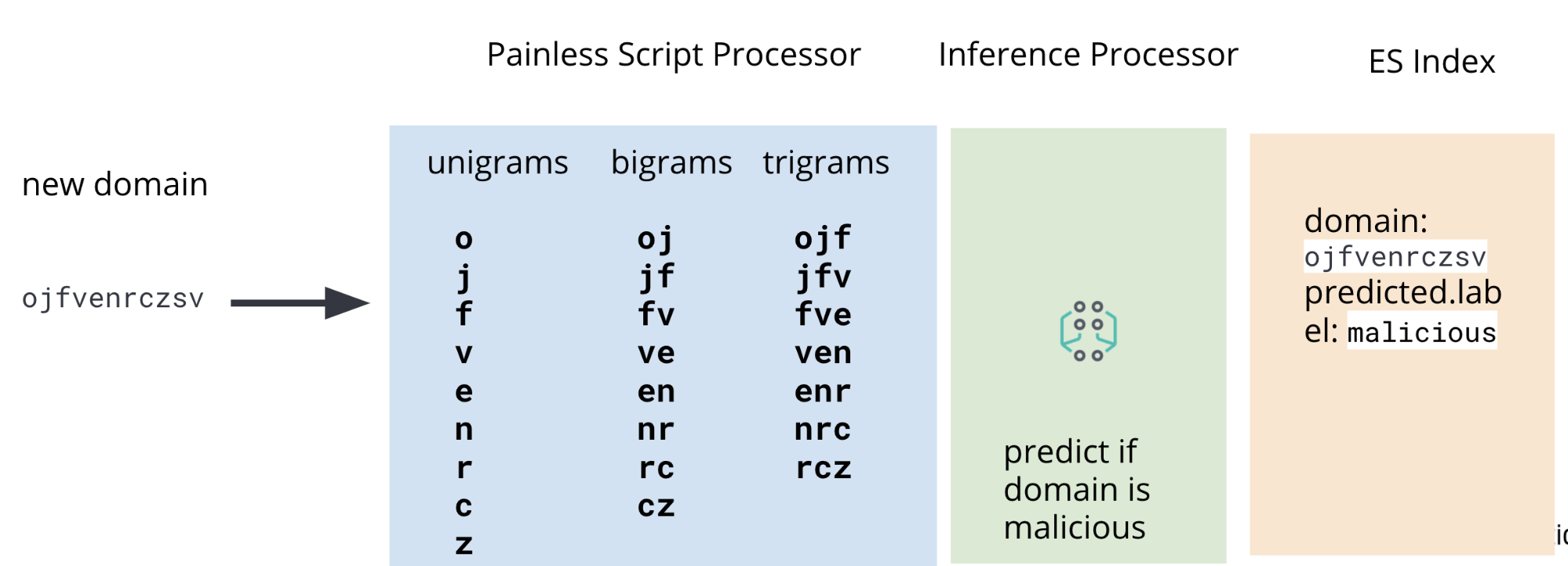
Dentro dos dados do Packetbeat, o campo no qual estamos interessados em operar é o domínio de DNS registrado. Embora existam alguns casos raros em que esse campo não conterá o domínio de interesse, ele será bom o suficiente para ilustrar o caso de uso para os fins deste post. A imagem na Figura 3 ilustra os campos de interesse em um documento de exemplo do Packetbeat.

dns.question.registered_domainPara extrair unigramas, bigramas e trigramas de dns.question.registered_domain, precisaremos usar um script Painless como o da Figura 4.
POST _scripts/ngram-extractor-packetbeat
{
"script": {
"lang": "painless",
"source": """
String nGramAtPosition(String fulldomain, int fieldcount, int n){
String domain = fulldomain.splitOnToken('.')[0];
if (fieldcount+n>=domain.length()){
return ''
}
else
{
return domain.substring(fieldcount, fieldcount+n)
}
}
for (int i=0;i<ctx['dns']['question']['registered_domain'].length();i++){
ctx['field_'+Integer.toString(params.ngram_count)+'_gram_'+Integer.toString(i)] = nGramAtPosition(ctx['dns']['question']['registered_domain'], i, params.ngram_count)
}
"""
}
}
Depois que os recursos necessários forem extraídos, o documento — ainda passando pelo pipeline de ingestão — passará pelo processador de inferência, onde o modelo de classificação que treinamos na parte anterior usará os recursos extraídos para fazer uma previsão. Finalmente, como não queremos sobrecarregar nosso índice com todos os recursos extras necessários ao modelo, adicionaremos uma série de processadores de script Painless para remover os campos que contenham os unigramas, bigramas e trigramas.
Assim, no final do pipeline de ingestão, o que ingeriremos será um documento do Packetbeat com os novos campos extras que contêm o resultado das predições de machine learning. Um exemplo de configuração de pipeline de ingestão é mostrado na Figura 5. Para obter todos os detalhes, consulte o repositório de exemplos.
PUT _ingest/pipeline/dga_ngram_expansion_inference
{
"description": "Expande um domínio em unigramas, bigramas e trigramas para fazer uma previsão do grau de risco",
"processors": [
{
"script": {
"id": "ngram-extractor-packetbeat",
"params":{
"ngram_count":1
}
}
},
{
"script": {
"id": "ngram-extractor-packetbeat",
"params":{
"ngram_count":2
}
}
},
{
"script": {
"id": "ngram-extractor-packetbeat",
"params": {
"ngram_count":3
}
}
},
{
"inference": {
"model_id": "dga-ngram-job-1587729368929",
"target_field": "predicted_label",
"field_mappings":{},
"inference_config": { "classification": {"num_top_classes": 2} }
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params":{
"ngram_count":1
}
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params":{
"ngram_count":2
}
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params": {
"ngram_count":3
}
}
}
]
}
Como nem todo documento do Packetbeat registrará uma solicitação de DNS, precisaremos fazer o pipeline de ingestão ser executado condicionalmente apenas se os campos de DNS obrigatórios estiverem presentes e não forem vazios no documento ingerido. Podemos fazer isso usando um processador de pipeline (veja a configuração na Figura 6) para verificar se os campos desejados estão presentes e preenchidos e, em seguida, redirecionar o processamento do documento para o pipeline dga_ngram_expansion_inference que definimos na Figura 5. Embora a configuração abaixo seja adequada para um protótipo, para um caso de uso de produção, você precisará considerar a possibilidade de fazer um tratamento de erros no pipeline de ingestão. Para obter instruções e configurações completas, consulte o repositório de exemplos.
PUT _ingest/pipeline/dns_classification_pipeline
{
"description": "Um pipeline de pipelines para realizar a detecção de DGA",
"version": 1,
"processors": [
{
"pipeline": {
"if": "ctx.containsKey('dns') && ctx['dns'].containsKey('question') && ctx['dns']['question'].containsKey('registered_domain') && !ctx['dns']['question']['registered_domain'].empty",
"name": "dga_ngram_expansion_inference"
}
}
]
}
Uso de detecção de anomalia como analítica de segunda ordem nos resultados de inferência
O modelo que treinamos na primeira parte da série teve uma taxa de falsos positivos de 2%. Embora isso pareça muito baixo, é preciso ter em mente que o tráfego de DNS geralmente tem um volume alto. Portanto, mesmo com uma taxa de falsos positivos de 2%, um grande número de consultas pode ser classificado como malicioso. Uma maneira de reduzir o número de falsos positivos seria trabalhar em outros esquemas de engenharia de recursos. Outra seria usar a detecção de anomalia nos resultados da nossa classificação. Vamos explorar como fazer essa segunda opção no Elastic Stack.
A primeira coisa a observar é que, se pegarmos os documentos do Packetbeat enriquecidos e traçarmos a contagem de documentos do Packetbeat rotulados como maliciosos em relação ao tempo, obteremos uma série temporal (Figura 7).
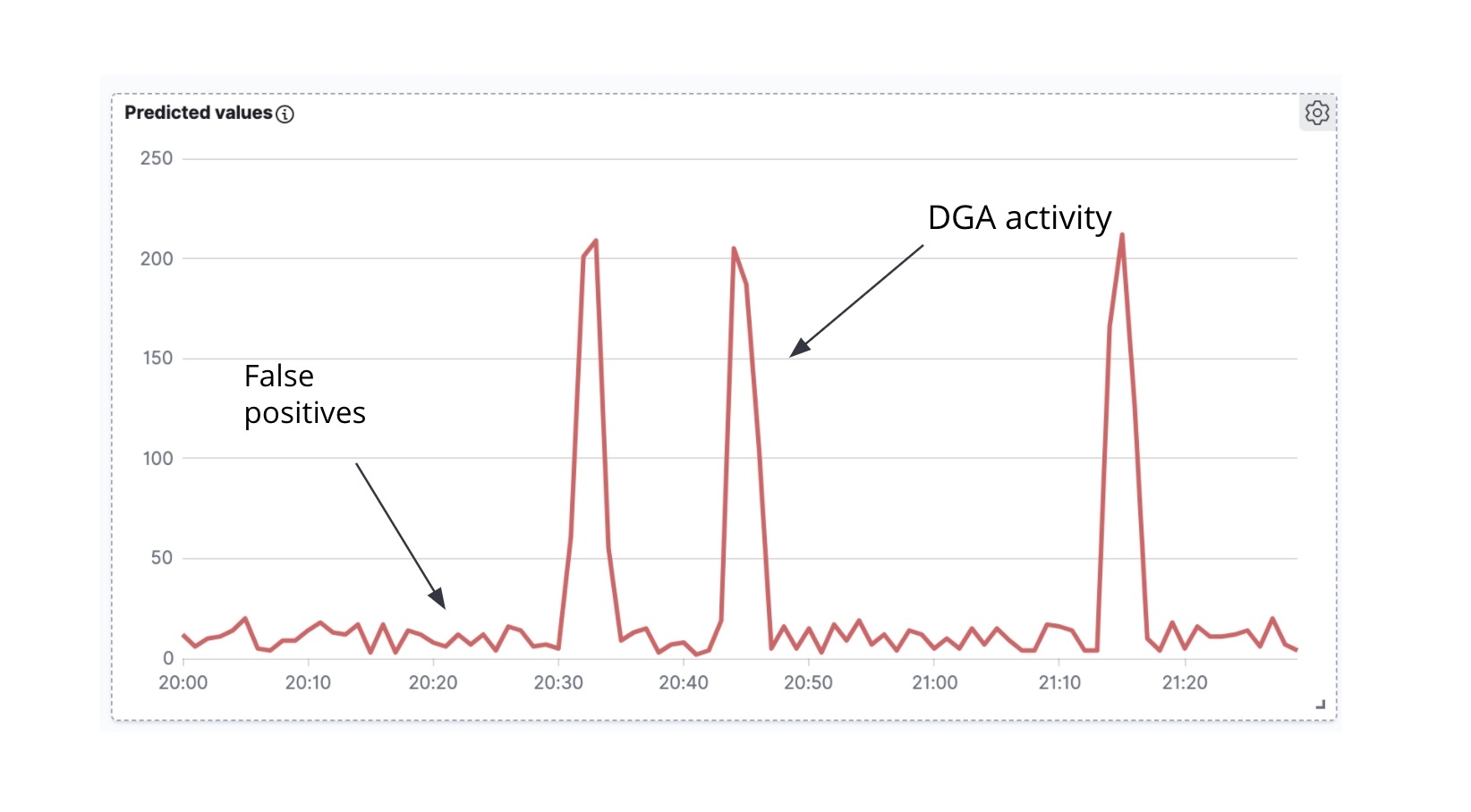
A segunda coisa a observar é que, muitas vezes (embora haja exceções), quando um malware de DGA está ativamente tentando se comunicar com o servidor de C&C, ele tende a gerar uma onda de solicitações de DNS de uma vez (ou seja, o malware percorre muitos dos domínios gerados pelo algoritmo, tentando resolver o endereço IP de cada um dos domínios). Na análise de série temporal dos domínios maliciosos previstos ao longo do tempo (Figura 6), podemos ver picos de atividade e pequenos ruídos entre os picos. Os picos indicam que nosso modelo classificou muitos domínios como maliciosos em um curto espaço de tempo e, portanto, provavelmente estamos lidando com um verdadeiro DGA. Em contraste, o ruído de fundo entre os picos é provavelmente o resultado de falsos positivos. É precisamente essa intuição que buscaremos codificar em um trabalho de detecção de anomalia high_count para essa série temporal.
Se sobrepusermos a raia de detecção de anomalia com a série temporal na Figura 7, veremos que obtemos alertas de anomalia correspondentes aos picos na série temporal (a verdadeira atividade de DGA) e nenhum alerta nos intervalos entre os picos (o ruído de fundo dos falsos positivos).
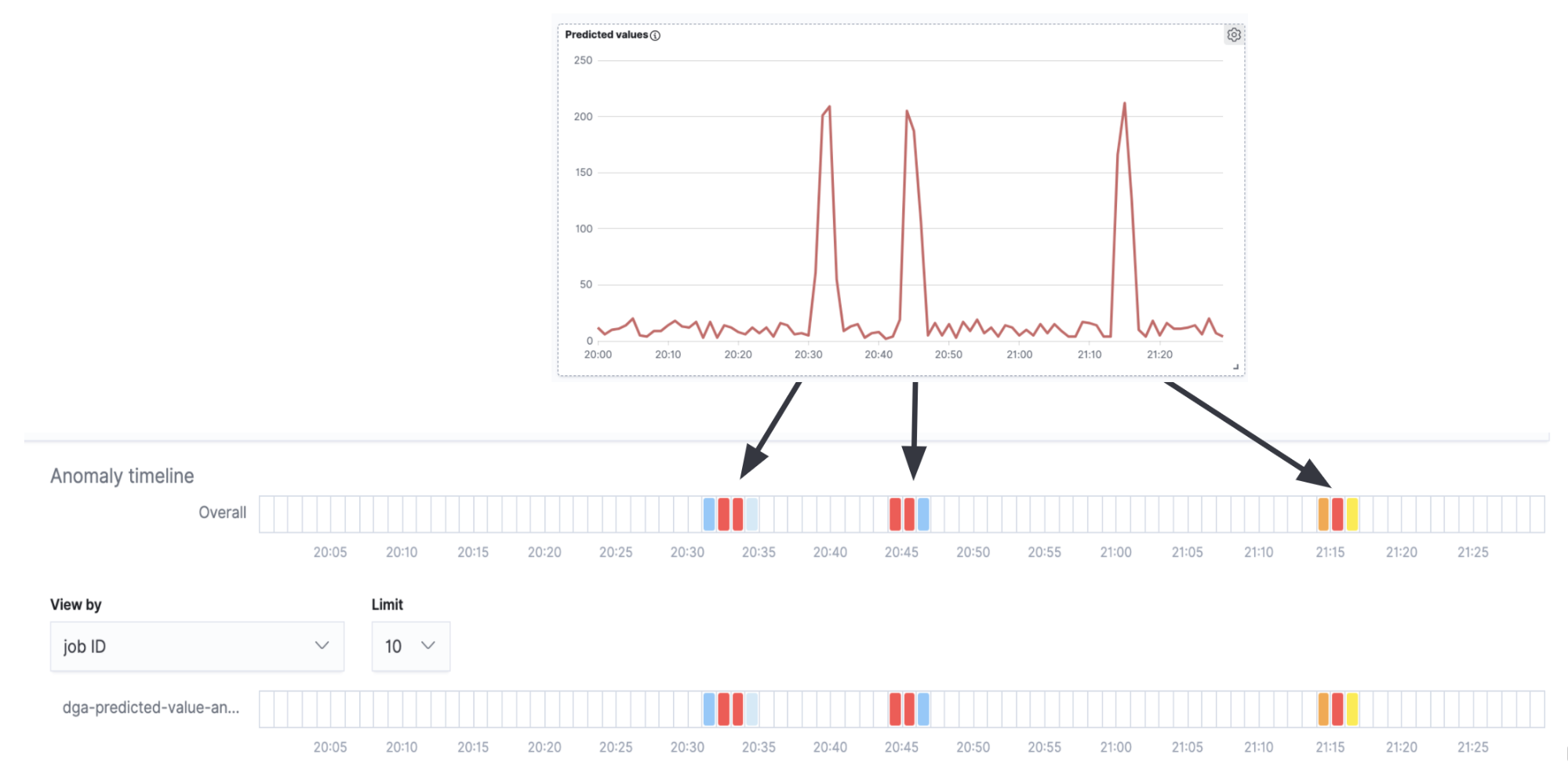
Embora esse seja um exemplo muito simples e, para um caso de uso de produção, provavelmente exigisse mais ajustes e configurações, ele mostra que é possível usar trabalhos de detecção de anomalia com eficácia como uma análise de segunda ordem nos resultados de inferência.
Conclusão
Neste post, usamos um modelo de classificação treinado para enriquecer os dados de rede (documentos do Packetbeat) no momento da ingestão. O processo de enriquecimento, que é facilitado pelo processador de inferência e pelos pipelines de ingestão, adiciona um rótulo previsto a cada domínio consultado durante uma solicitação de DNS. Isso mostra a probabilidade de o domínio ser malicioso. Além disso, para reduzir alertas de falsos positivos, também examinamos como usar um trabalho de detecção de anomalia nos resultados de inferência. Também estamos planejando fornecer uma seleção de configuração e modelos para detecção de DGA no Elastic SIEM.
Se quiser experimentar com seus próprios dados de rede, você poderá iniciar uma avaliação gratuita do Elasticsearch Service de 14 dias para começar a fazer a ingestão e a análise. Você também poderá experimentar o machine learning gratuitamente por 30 dias baixando o Elastic Stack localmente e iniciando uma licença de avaliação. Ou iniciar com o Elastic SIEM gratuito e aberto para começar a proteger seus dados hoje mesmo.