Elastic Stack과 Google Operations를 사용한 Google Cloud 모니터링
Google Operations 제품군(이전의 ‘Stackdriver’)은 Google Cloud 리소스로부터 로그, 메트릭, 애플리케이션 추적을 수신하는 중앙 리포지토리입니다. 이러한 리소스에는 컴퓨팅 엔진, 앱 엔진, 데이터 흐름, 데이터프로크는 물론 BigQuery와 같은 SaaS 제품도 포함될 수 있습니다. 이 데이터를 Elastic으로 전송하면 클라우드에서 온프레미스에 이르기까지 전체 인프라에서 리소스의 성능을 통합적으로 확인할 수 있습니다.
이 블로그에서는 Google Operations에서 Elastic Stack으로 데이터를 스트리밍하기 위한 파이프라인을 설정하여 다른 통합 가시성 데이터와 함께 Google Cloud 로그를 분석해 보겠습니다. 이 데모에서는 Filebeat Google Cloud 모듈을 사용하여 분석을 위해 Google Cloud 데이터를 Elastic Cloud 무료 체험판으로 전송하게 됩니다. 함께 살펴볼까요?
높은 수준의 데이터 흐름
이 데모에서는 Google Cloud 리소스의 감사, 방화벽 및 VPC 흐름 로그를 Google Cloud Operations로 전송하게 됩니다. 거기서 싱크, Pub/Sub 주제를 만들고, Filebeat로 구독하고, Elastic Cloud로 데이터를 전송해 ElasticSearch와 Kibana를 통해 추가 분석을 할 수 있습니다. 이 다이어그램은 데이터가 클러스터에 들어가는 경로를 보여 주는 높은 수준의 흐름을 제공합니다.
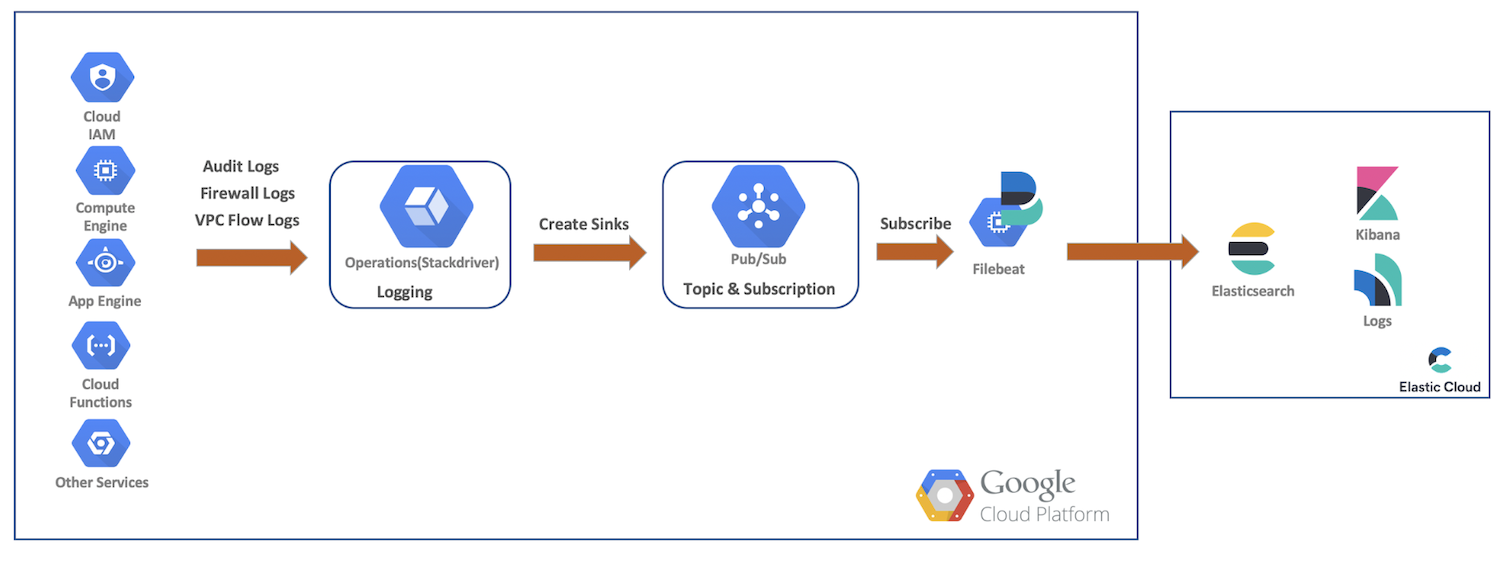
Google 클라우드 로깅 설정 및 구성
Google Cloud는 풍부한 UI를 제공하여 서비스에 대한 로그를 활성화하며, 로그는 각각의 콘솔에서 구성됩니다. 다음 단계에서는 여러 로그를 활성화하고 싱크와 주제를 만든 다음, 서비스 계정과 자격 증명을 설정해 보겠습니다.
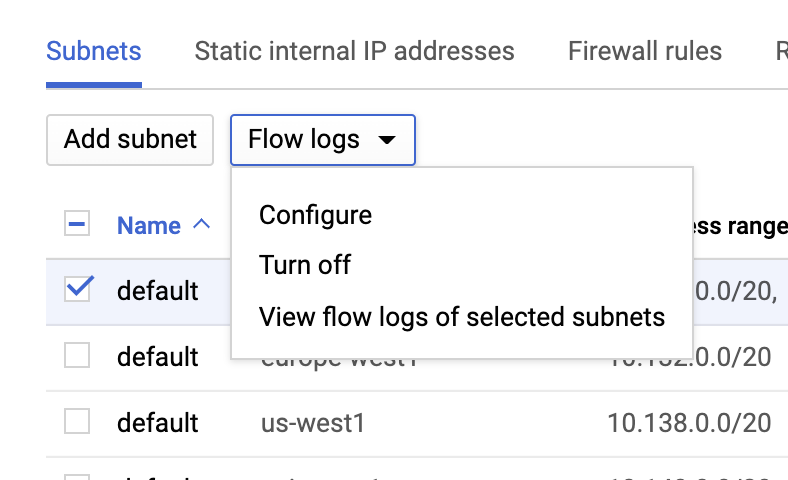
VPC 흐름 로그
VPC network(VPC 네트워크) 페이지로 이동하여 VPC를 선택하고 Flow logs(흐름 로그) 드롭다운에서 Configure(구성)를 클릭하여 VPC 흐름 로그를 활성화할 수 있습니다.
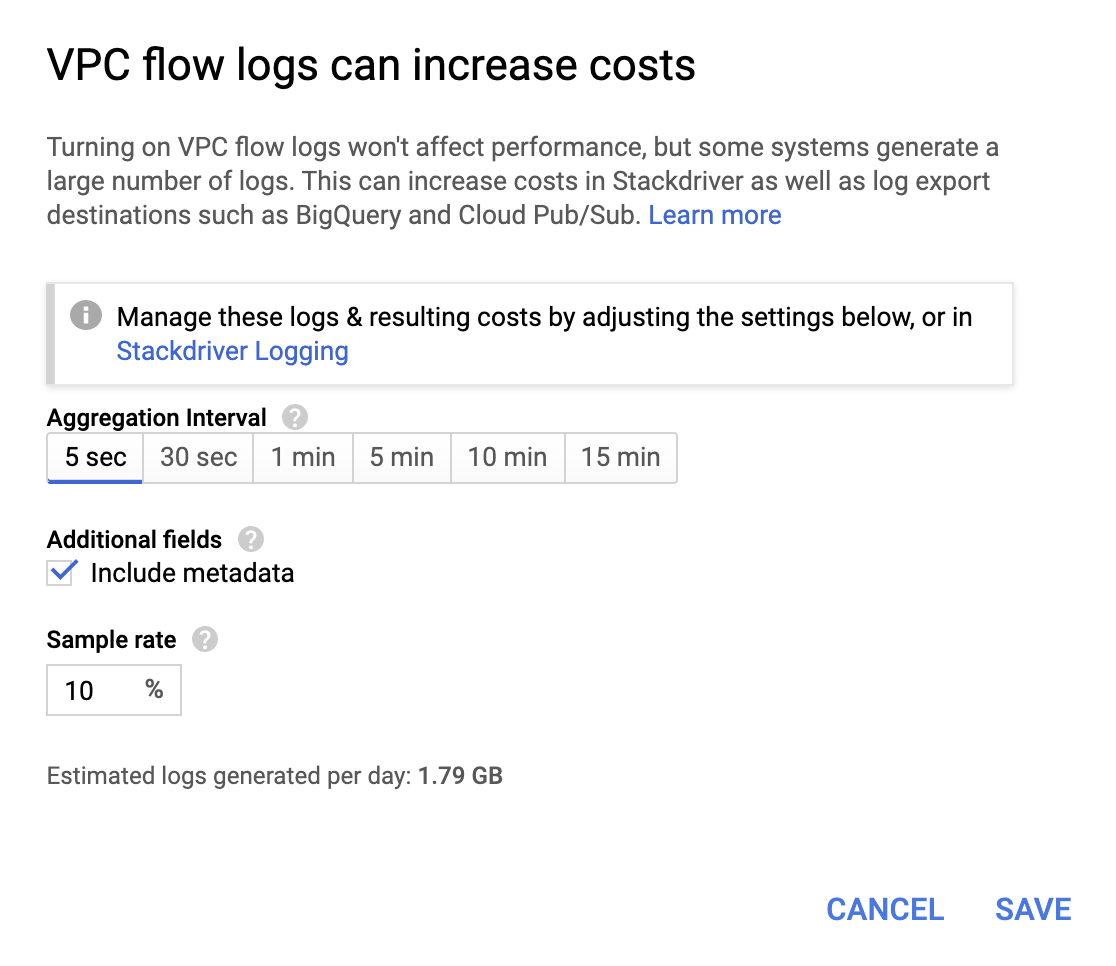
비용이 많이 들지는 않지만 운영 비용이 청구서에 추가되므로 요구 사항에 따라 집계 간격과 표본 비율을 선택합니다.
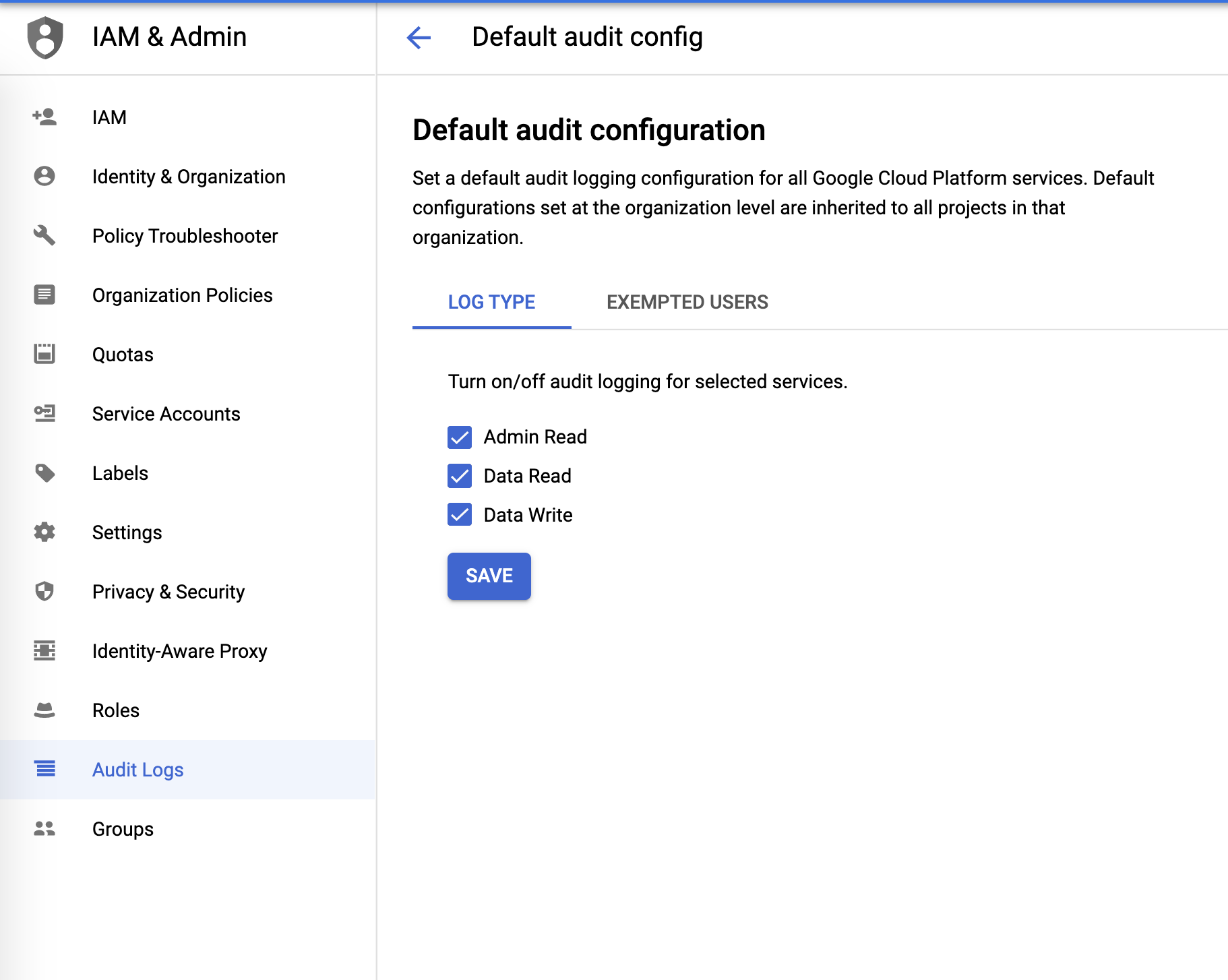
감사 로그
IAM & Admin 메뉴에서 다음과 같이 감사 로그를 구성할 수 있습니다.
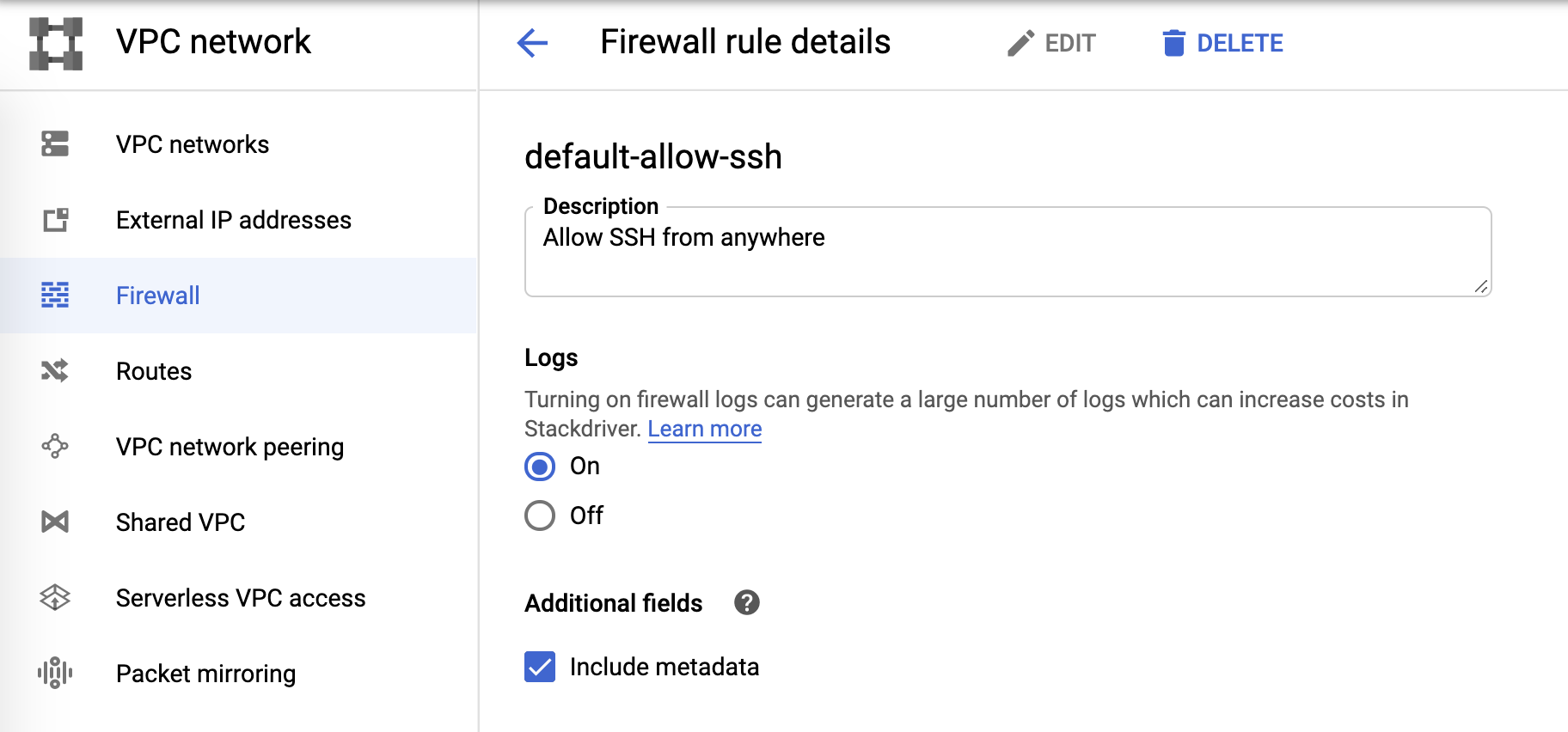
방화벽 로그
마지막으로, 방화벽 로그는 다음과 같이 방화벽 규칙에서 제어할 수 있습니다.
로그 싱크 및 Pub/Sub
개별 로깅 영역을 구성한 후에는 로그 뷰어에서 각 로그에 대해 싱크를 생성할 수 있습니다.

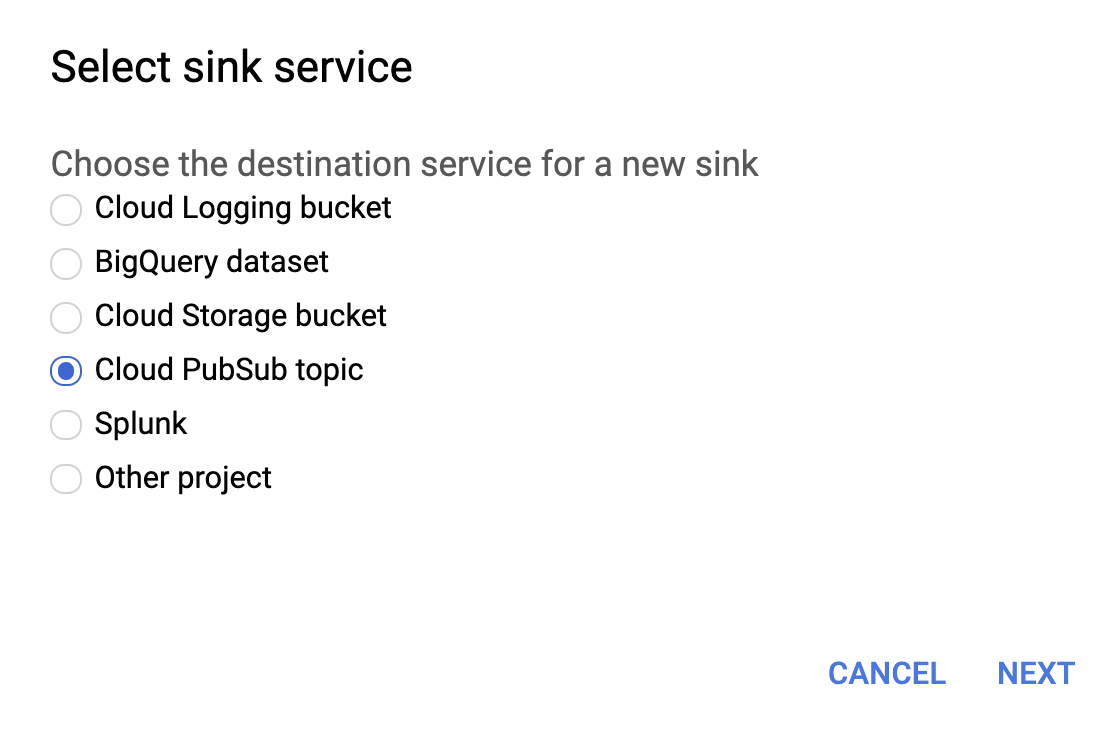
아래와 같이 싱크 서비스에 대한 Cloud PubSub 주제를 선택하세요.
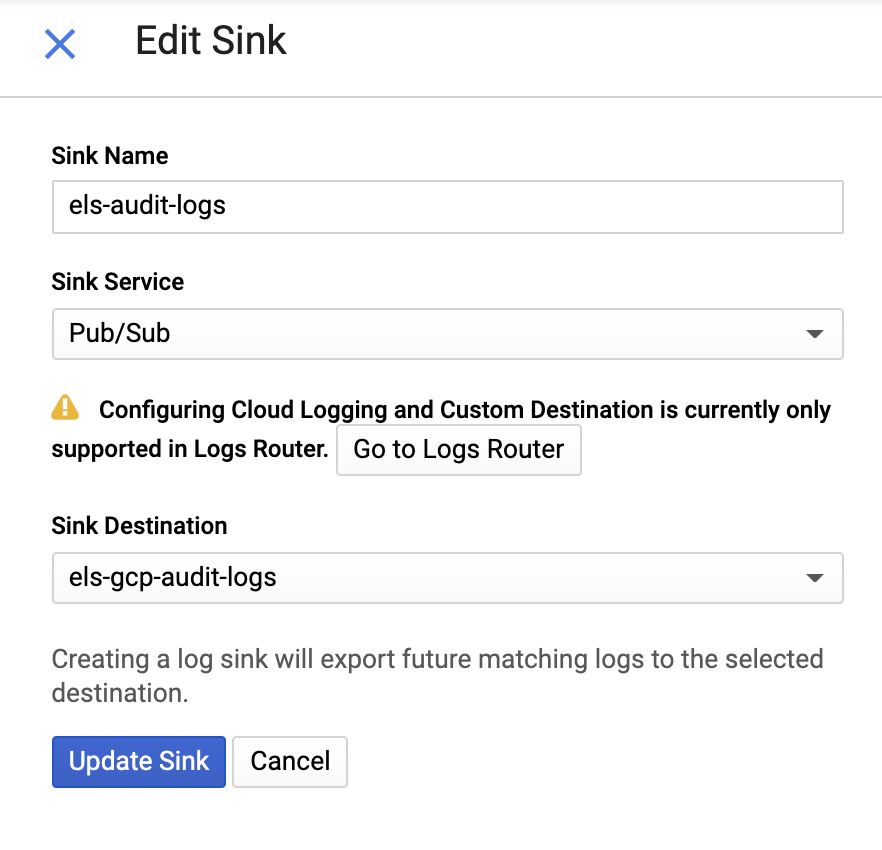
그런 다음 싱크 이름과 Pub/Sub 주제를 제공하세요. 기존 주제로 보내거나 새 주제를 만들 수 있습니다.
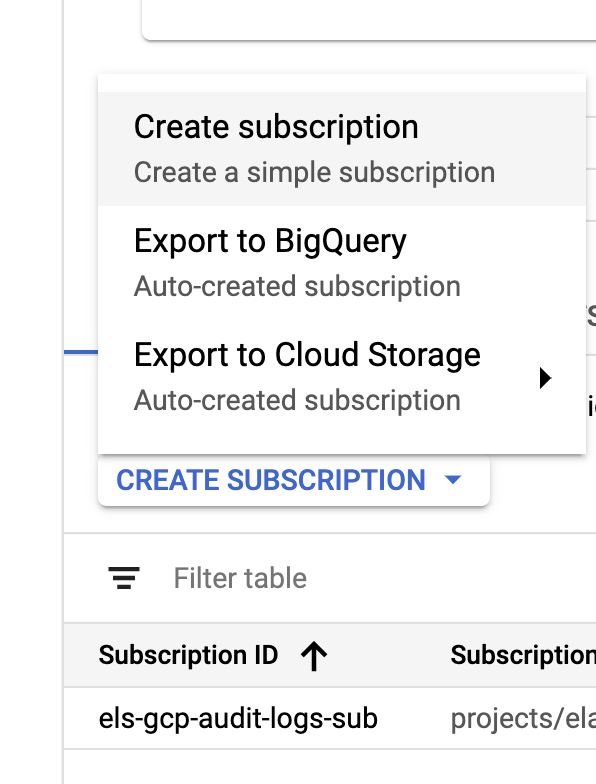
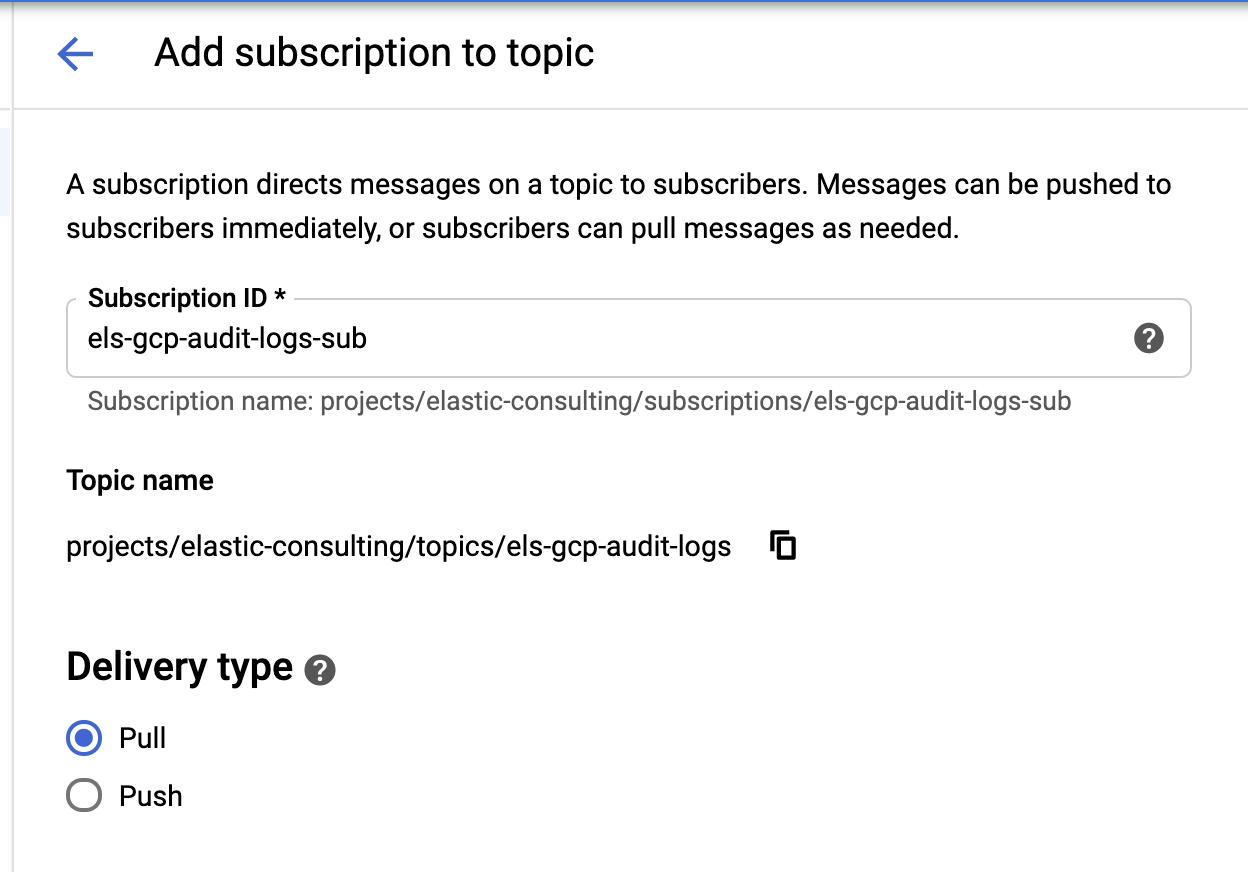
싱크와 주제가 생성되면 다음과 같이 Pub/Sub 주제 구독을 생성합니다.
| 
|
요구 사항에 따라 구독을 구성하세요.
서비스 계정 및 자격 증명
마지막으로 서비스 계정과 자격 증명 파일을 생성해 보겠습니다.
Pub/Sub 편집기 역할을 선택합니다. 조건은 선택 사항이며 주제를 필터링하는 데 사용할 수 있습니다.
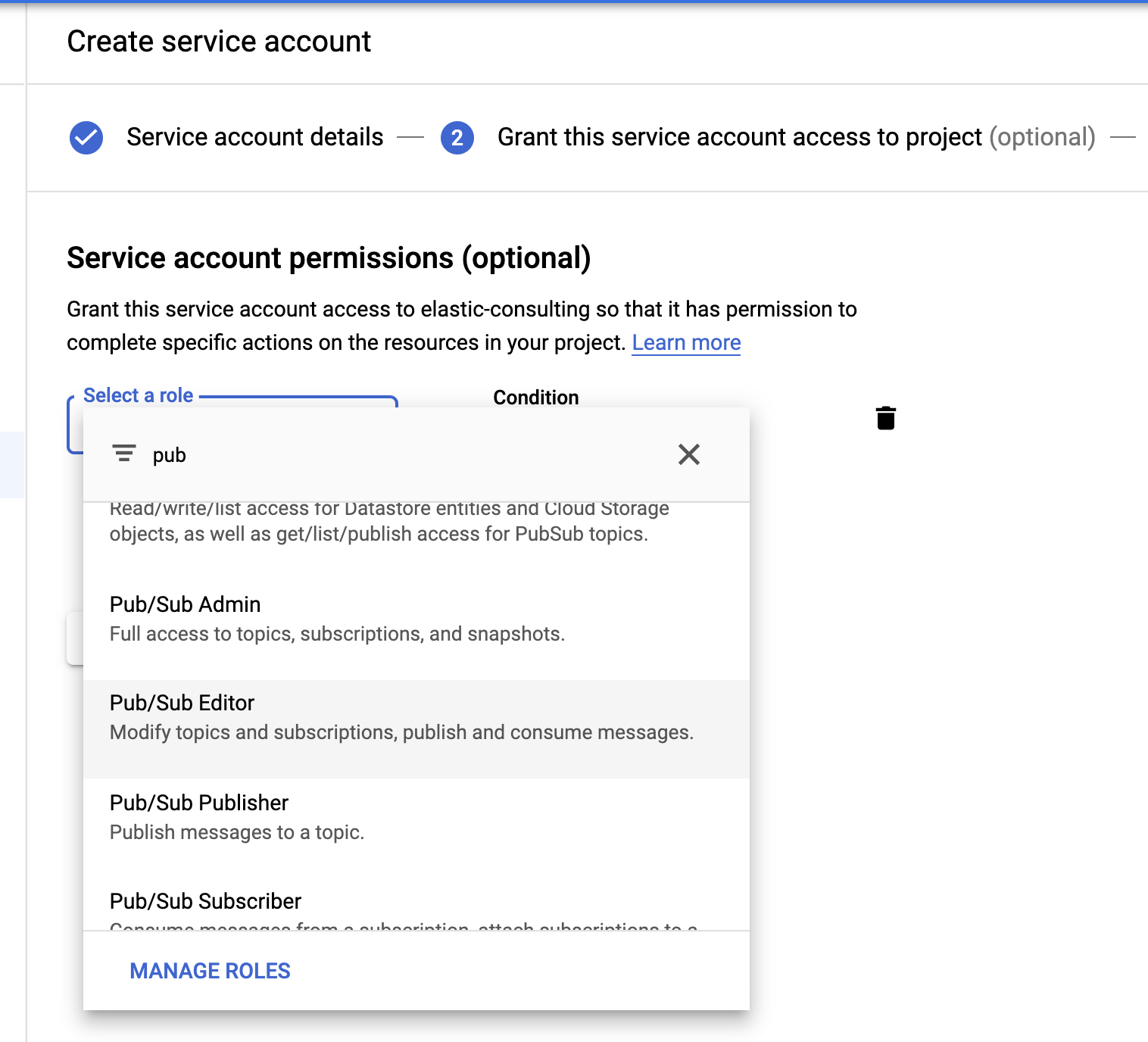
서비스 계정이 생성되면 Filebeat 호스트에 업로드되어 Filebeat 구성 디렉토리 /etc/filebeat에 저장되는 JSON 키를 생성합니다. 이 키는 Filebeat가 서비스 계정으로 인증하는 데 사용됩니다.

이제 Google Cloud 구성이 완료되었습니다.
Filebeat 설치 및 구성
Filebeat는 로그를 수집하여 Elasticsearch 클러스터로 전송하는 데 사용됩니다. 이 블로그에서는 CentOS를 사용할 예정이지만, 다음 Filebeat 설명서의 간단한 단계를 따라 각 운영 체제를 기반으로 Filebeat를 설치할 수 있습니다.
Google Cloud 모듈 사용
Filebeat가 설치되면 googlecloud 모듈을 활성화해야 합니다.
filebeat modules enable googlecloud
앞에서 생성한 JSON 자격 증명 파일을 /etc/filebeat/에 복사한 다음 Google Cloud 설정과 일치하도록 /etc/filebeat/modules.d/googlecloud.yml 파일을 수정합니다.
예를 들어, 세 개의 모듈이 모두 나열되고 필요한 모든 구성이 키로 입력되는 등 구성의 일부는 완료된 상태이므로, 설정을 기준으로 그 값만 업데이트하면 됩니다.
# 모듈: googlecloud
# 설명서: https://www.elastic.co/guide/en/beats/filebeat/7.9/filebeat-module-googlecloud.html
- module: googlecloud
vpcflow:
enabled: true
# Google Cloud 프로젝트 ID.
var.project_id: els-dummy
# VPC 흐름 로그를 포함하는 Google Pub/Sub 주제. Stackdriver는
# 이 주제를 VPC 흐름 로그의 싱크로 사용하도록 구성되어야 함.
var.topic: els-gcp-vpc-flow-logs
# 해당 주제에 대한 Google Pub/Sub 구독. 이 구독이 없는 경우
# Filebeat가 이 구독을 생성하게 됨.
var.subscription_name: els-gcp-vpc-flow-logs-sub
# 이 구독에서 읽기 권한이 있는 서비스 계정의
# 자격 증명 파일
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
firewall:
enabled: true
# Google Cloud 프로젝트 ID.
var.project_id: els-dummy
# 방화벽 로그를 포함하는 Google Pub/Sub 주제. Stackdriver는
# 이 주제를 방화벽 로그의 싱크로 사용하도록 구성되어야 함.
var.topic: els-gcp-firewall-logs
# 해당 주제에 대한 Google Pub/Sub 구독. 이 구독이 없는 경우
# Filebeat가 이 구독을 생성하게 됨.
var.subscription_name: els-gcp-firewall-logs-sub
# 이 구독에서 읽기 권한이 있는 서비스 계정의
# 자격 증명 파일
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
audit:
enabled: true
# Google Cloud 프로젝트 ID.
var.project_id: els-dummy
# 감사 로그를 포함하는 Google Pub/Sub 주제. Stackdriver는
# 이 주제를 방화벽 로그의 싱크로 사용하도록 구성되어야 함.
var.topic: els-gcp-audit-logs
# 해당 주제에 대한 Google Pub/Sub 구독. 이 구독이 없는 경우
# Filebeat가 이 구독을 생성하게 됨.
var.subscription_name: els-gcp-audit-logs-sub
# 이 구독에서 읽기 권한이 있는 서비스 계정의
# 자격 증명 파일
var.credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
마지막으로 Kibana 및 Elasticsearch 엔드포인트를 가리키도록 Filebeat를 구성합니다.
Kibana 및 Elasticsearch 엔드포인트 설명서에 따라 filebeat.yml 파일에서 setup.dashboards.enabled: true를 설정하여 Google Cloud를 위해 미리 빌드된 대시보드를 로드합니다.
참고로 Filebeat는 미리 빌드된 대시보드와 함께 다양한 모듈을 제공합니다. 이 포스팅에서는 Google Cloud 모듈만 보게 되지만, 사용 가능한 다른 Filebeat 모듈도 살펴보고 어떤 것들이 유용할 것인지 확인해 보시기 바랍니다.
Filebeat 시작
마지막으로 다음과 같이 Filebeat를 시작하고 -e 플래그를 추가하면 간단하게 출력을 콘솔에 기록할 수 있습니다.
sudo service filebeat start -e
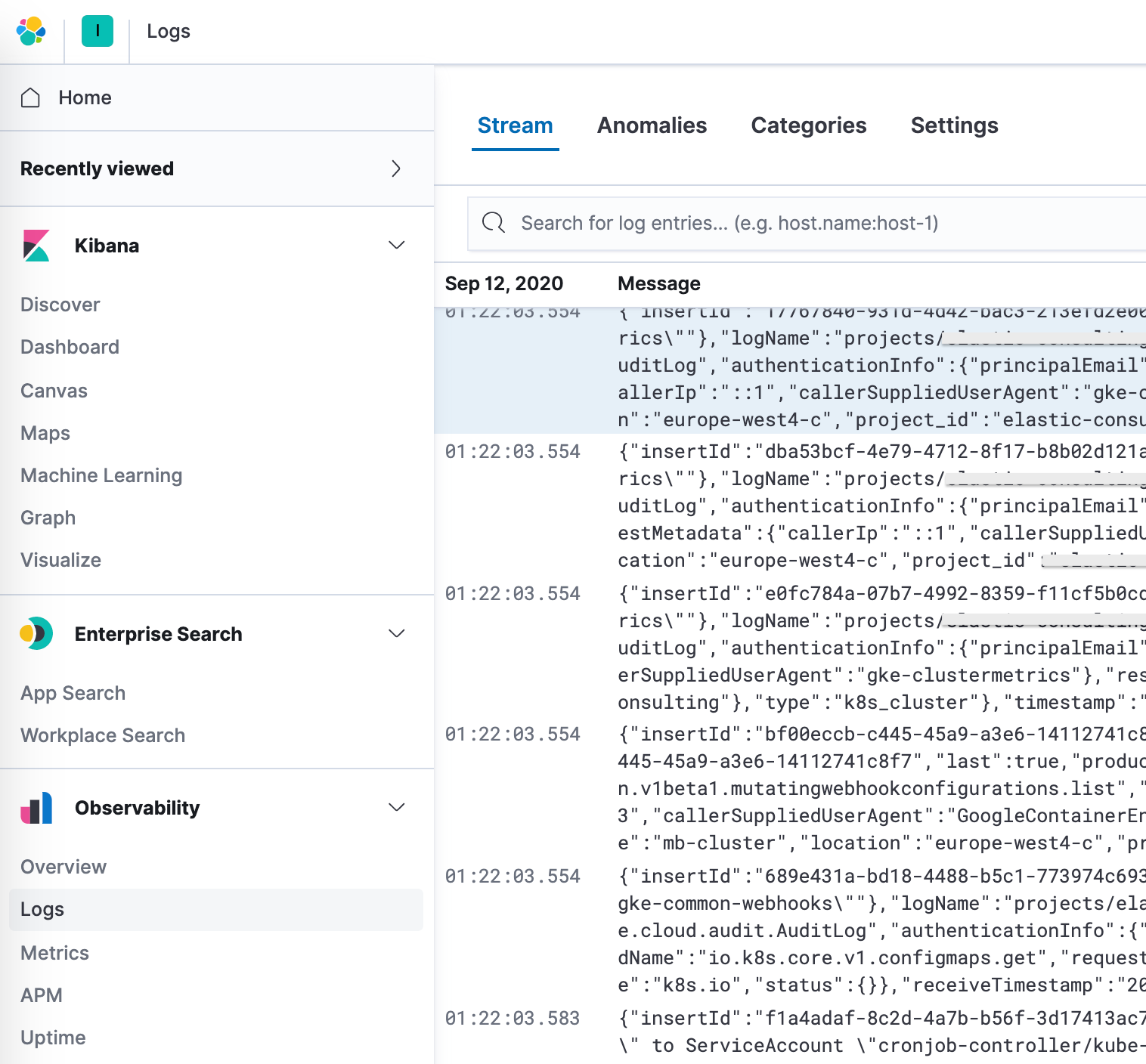
Kibana에서 데이터 탐색
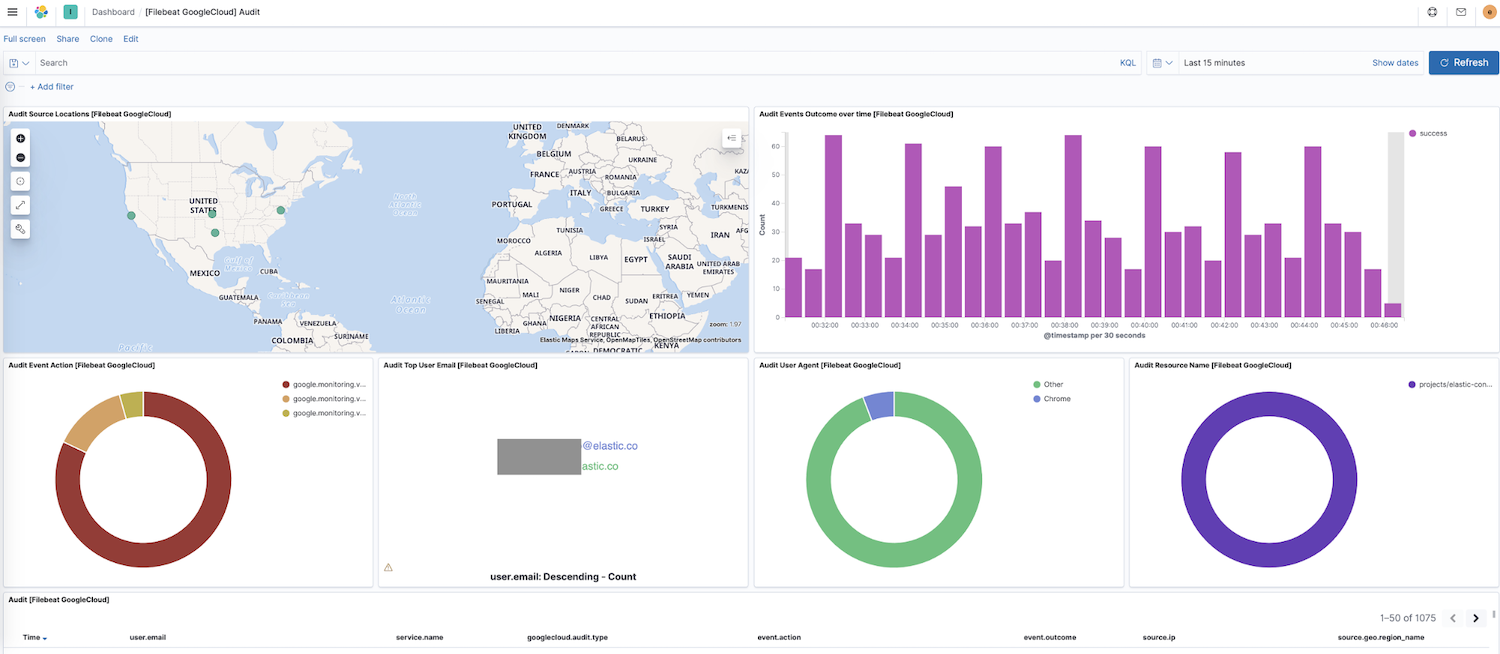
이제 Filebeat가 클러스터로 데이터를 전송하고 있으므로 Kibana의 탐색 대시보드로 이동하겠습니다. 다른 모듈에 대한 대시보드가 있는 경우 google을 검색하여 새로 활성화된 모듈의 대시보드를 찾을 수 있습니다. 이 경우에는, Google Cloud "감사" 대시보드가 표시됩니다.
이 대시보드에서 소스 위치의 동적 맵, 시간 경과에 따른 이벤트 결과, 이벤트 작업의 분석 등과 같은 시각화를 볼 수 있습니다. 이러한 미리 빌드된 대화형 시각화를 통해 로그 데이터를 탐색하는 것은 직관적입니다. Filebeat를 처음 설정하거나 Elastic Stack의 이전 버전을 실행 중인 경우(Google Cloud 모듈은 7.7에서 정식 버전으로 출시), 다음 지침에 따라 대시보드를 로드해야 합니다.
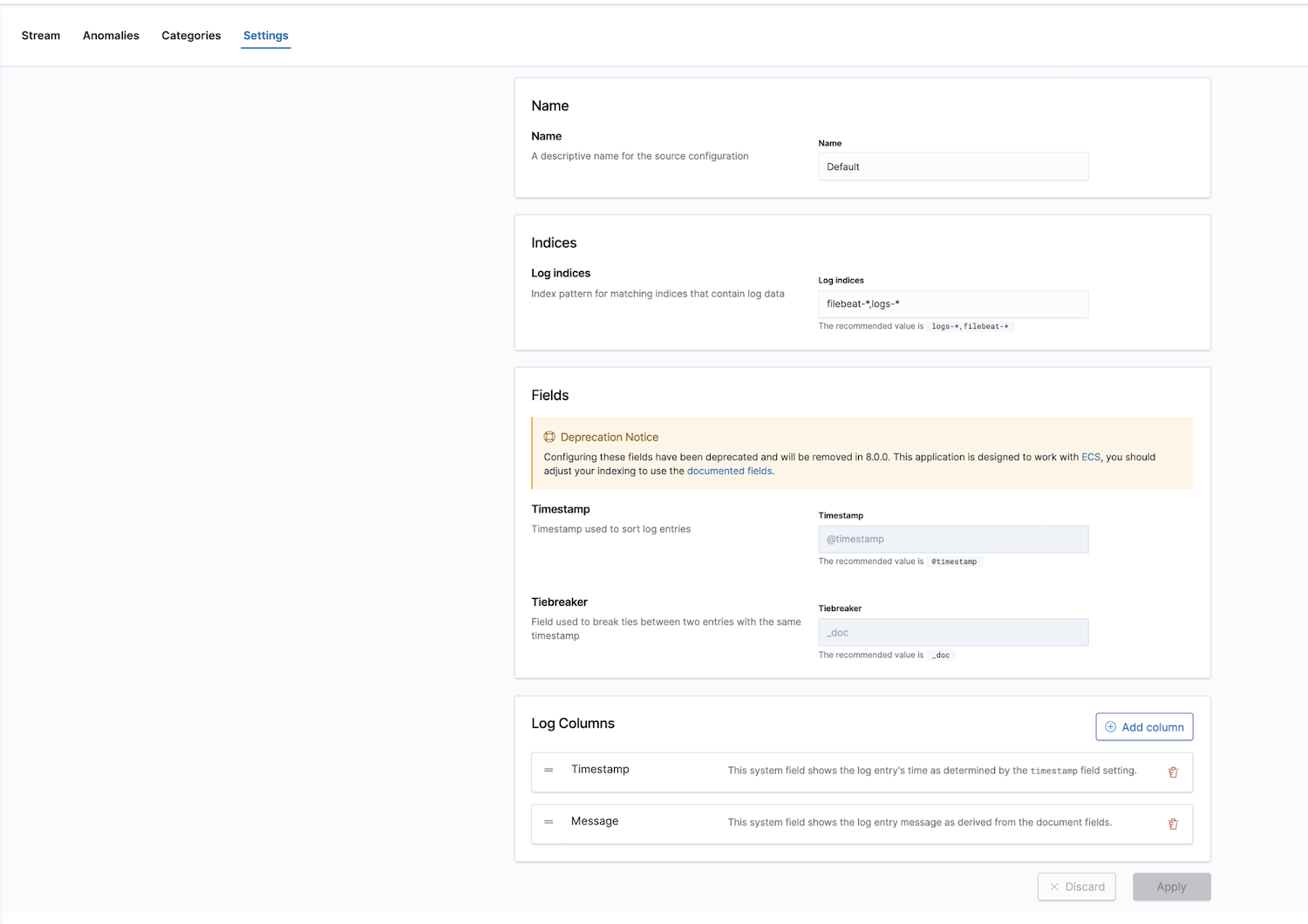
또한 Elastic은 로그 모니터링 앱과 함께 통합 가시성 솔루션을 제공합니다. 로그 인덱스를 구성할 수 있으며, 기본값은 filebeat-* 및 logs-*입니다.
설정에서 정확한 인덱스 패턴을 구성한 후, Logs 앱에서 로그를 탐색하면 로그의 상세 내역을 볼 수 있으며, 보다 중요한 것은 이상 징후를 보이는 동작에 대한 머신 러닝 작업을 정의하고, 데이터를 분류하고, 경보를 생성할 수 있다는 점입니다.
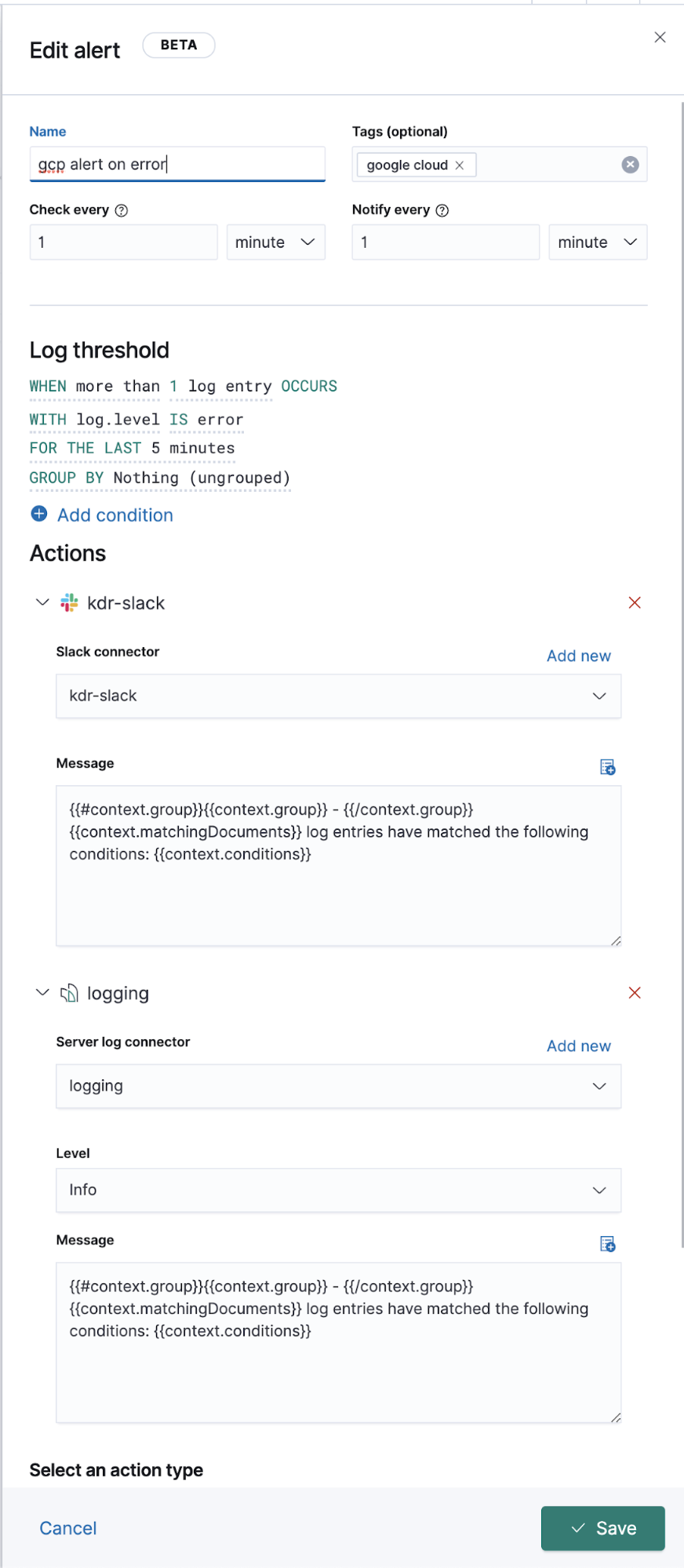
확장된 Google Operations(Stackdriver) 로깅
위에서 Filebeat 모듈이 있는 로그에 대한 작업 로그를 전송하는 방법에 대해 논의했지만, 전용 Filebeat 모듈이 없는 다른 로그는 어떻게 해야 할까요? 아래에서 이러한 로그를 Elastic으로 전송하는 방법과 아울러 다른 로그 데이터와 함께 보는 방법에 대해 얘기해보겠습니다.
Google Cloud 설정과 구성의 관점에서는 흐름을 포함한 모든 것이 그대로 유지됩니다. 싱크, 주제, 구독, sa, 그리고 JSON 키를 만들게 되며, Filebeat 구성만 다릅니다.
백그라운드에서 모듈은 입력 및 미리 구성된 소스 레벨 구문 분석에서 실행되며, 경우에 따라 수집 파이프라인을 실행하기도 합니다. Filebeat 모듈은 일반적인 로그 형식의 수집, 구문 분석 및 시각화를 단순화하지만 Filebeat 입력의 경우 추가 구문 분석이 필요한 경우도 있습니다.
googlecloud 모듈은 기본적으로 google-pubsub 입력을 사용하며, 일부 모듈별 수집 파이프라인을 제공합니다. 그리고 vpcflow, audit, firewall 로그를 즉시 사용할 수 있도록 지원합니다.
구성
Filebeat 모듈을 사용하는 대신, Filebeat 입력에서 이러한 주제를 구독해 보겠습니다.
filebeat.yml 파일에 다음을 추가합니다.
filebeat.inputs: - type: google-pubsub enabled: true pipeline: gcp-pubsub-parse-message-field tags: ["gcp-pubsub"] project_id: elastic-consulting topic: gcp-gke-container-logs subscription.name: gcp-gke-container-logs-sub credentials_file: /etc/filebeat/kdr-gcp-logs-sa-editor-only.json
이 입력에서는 가져올 주제와 사용할 구독을 지정하고 있습니다. 또한 다음에 정의할 자격 증명 파일과 수집 파이프라인을 지정하고 있습니다.
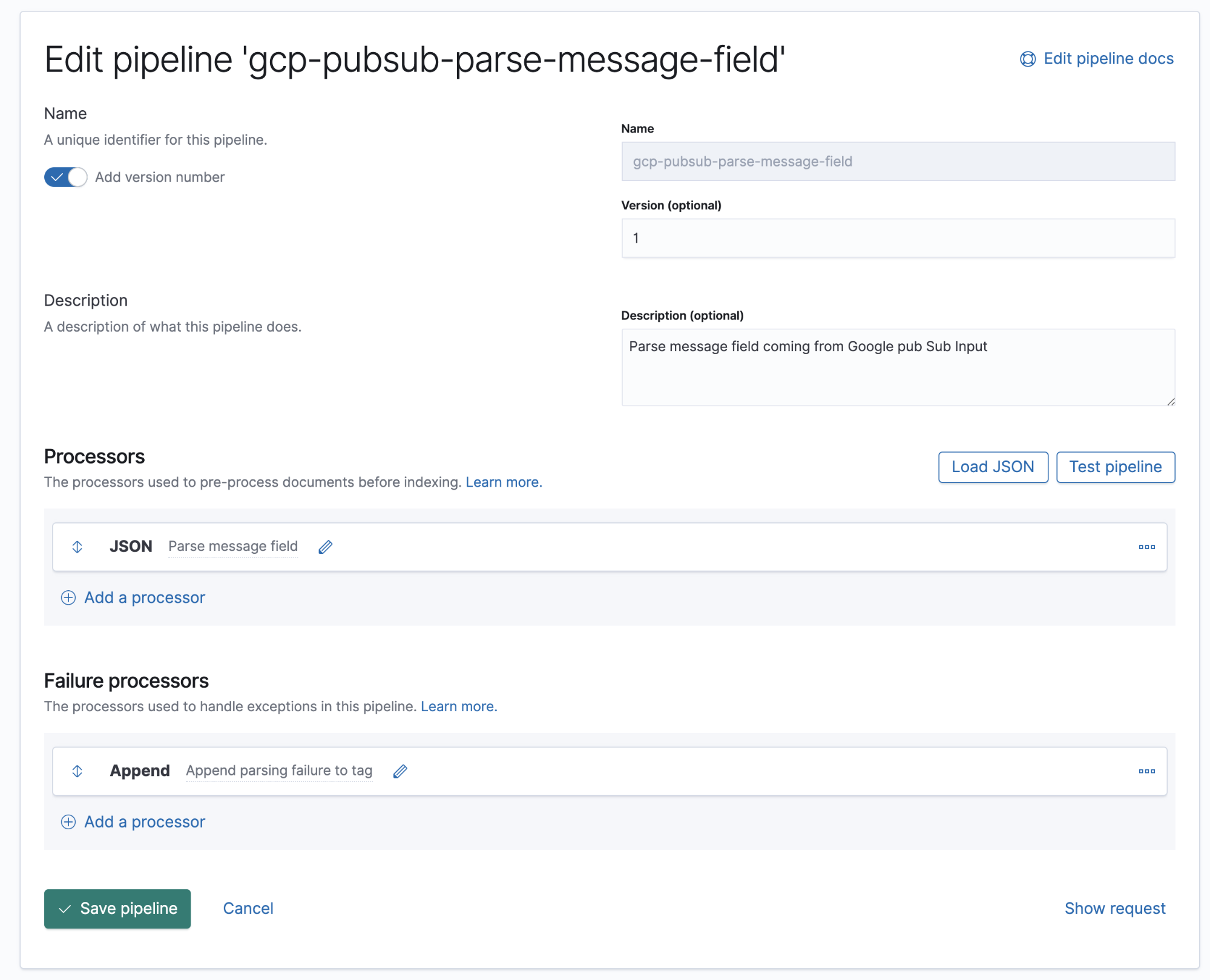
수집 파이프라인
수집 파이프라인은 선언된 것과 동일한 순서로 실행되어야 하는 일련의 프로세서를 정의한 것입니다.
Google Cloud Operations는 로그와 메시지 본문을 JSON 형식으로 저장하는데, 이는 메시지 필드의 데이터를 Elastsearch의 개별 필드에 추출하려면 파이프라인에 JSON 프로세서를 추가하기만 하면 된다는 뜻입니다.
이 파이프라인에는 문서의 message 필드에서 데이터를 소싱하여 log라는 대상 필드에 추출하는 JSON 프로세서가 하나 있습니다.
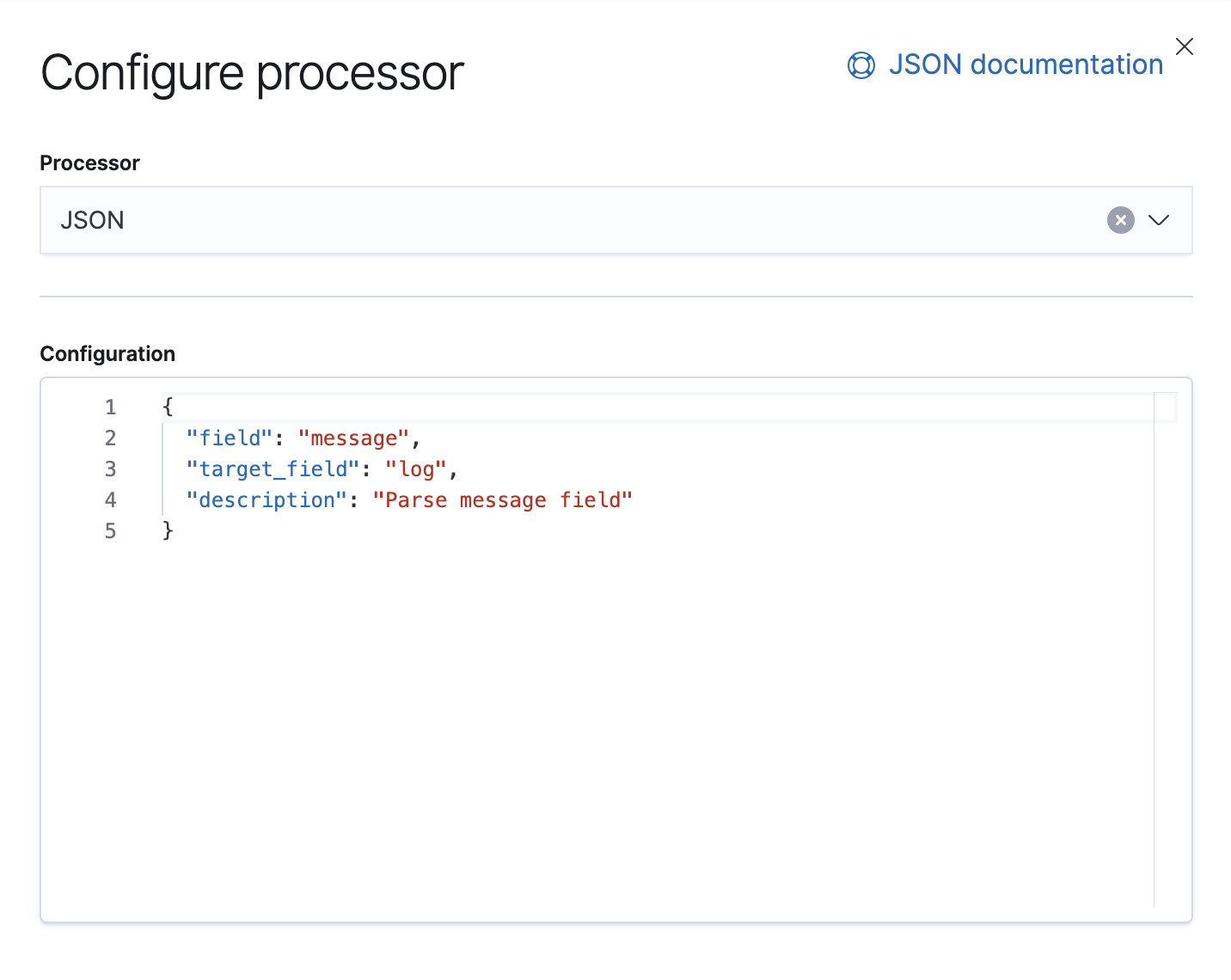
또한 이 파이프라인에는 예외를 처리할 수 있는 실패 프로세서가 있는데, 그런 경우에는 구문 분석 실패를 식별하는 태그를 추가하기만 하면 됩니다.
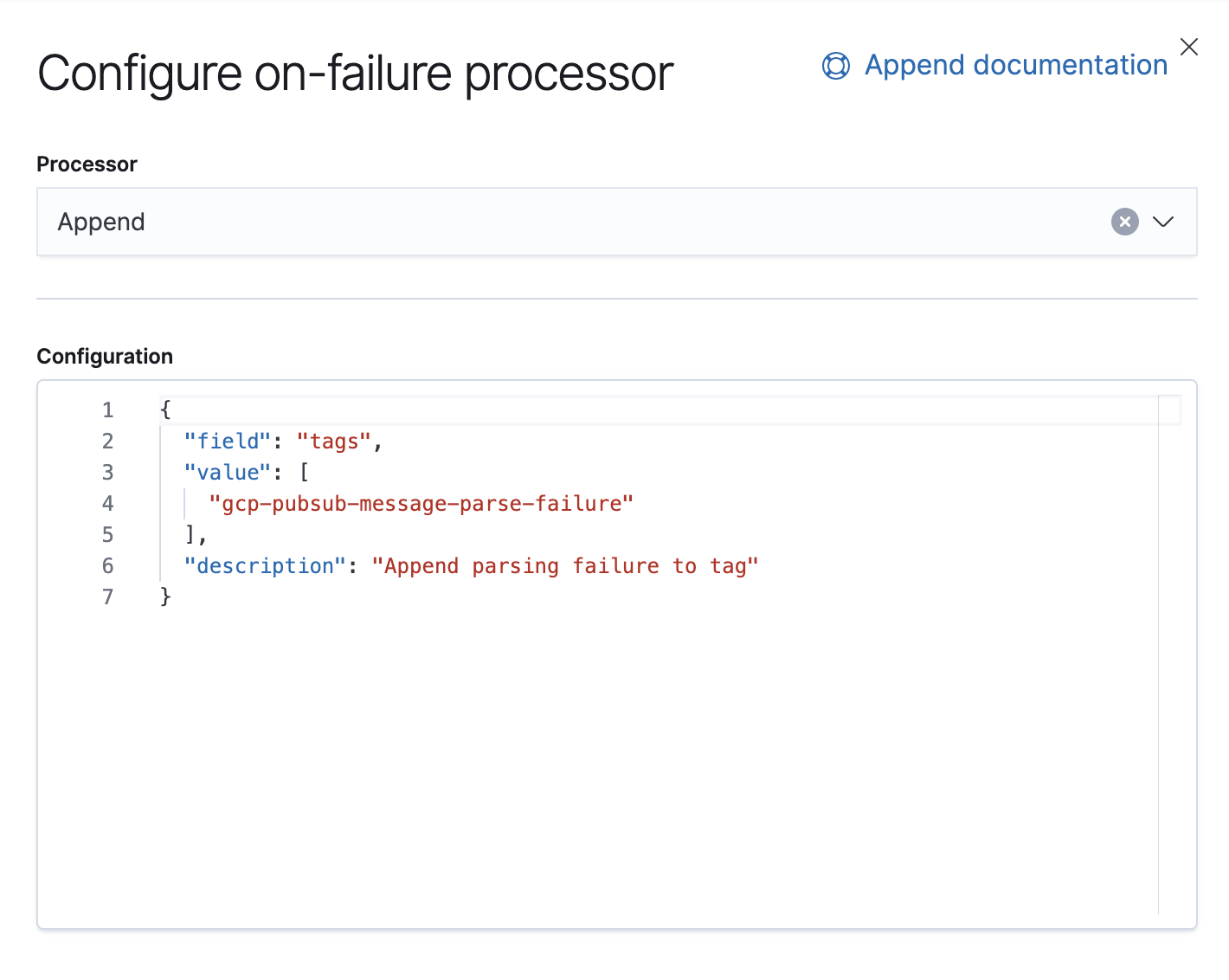
7.8부터, Stack Management → Ingest Node Pipelines에 있는 Kibana의 UI로 수집 파이프라인을 구축할 수 있습니다. 이전 버전을 사용 중인 경우에는 API를 사용할 수 있습니다. 다음은 이 파이프라인에 상응하는 API입니다.
PUT _ingest/pipeline/gcp-pubsub-parse-message-field
{
"version": 1,
"description": "Parse message field coming from Google pub Sub Input",
"processors": [
{
"json": {
"field": "message",
"target_field": "log",
"description": "Parse message field"
}
}
],
"on_failure": [
{
"append": {
"field": "tags",
"value": [
"gcp-pubsub-message-parse-failure"
],
"description": "Append parsing failure to tag"
}
}
]
}
이 파이프라인을 저장하겠습니다. google-pubsub 입력에서 구성된 동일한 파이프라인이 있는 한, Kibana에서 구문 분석된 로그를 보기 시작해야 합니다.
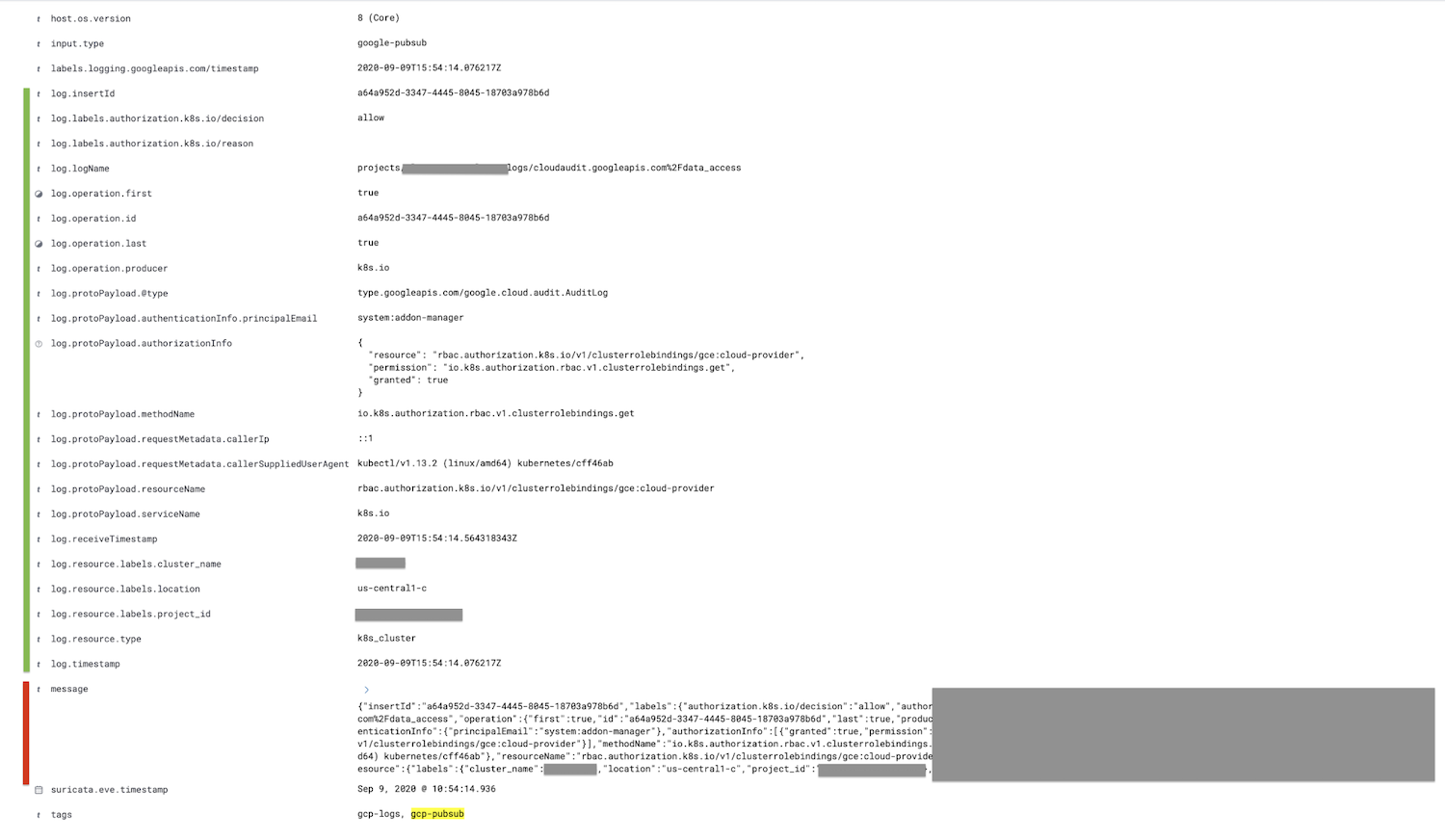
메시지 필드인 빨간색으로 표시된 필드는 로그 필드로 구문 분석되며 모든 하위 필드는 녹색으로 표시되고 더 중첩됩니다.
선택에 따라, 메시지 필드는 제거 프로세서를 사용하여 수집 파이프라인에서 JSON 프로세서 다음에 제거될 수 있습니다. 이렇게 하면 문서의 크기가 줄어듭니다.
결론
이 블로그를 위해 준비된 내용은 여기까지입니다. 함께 봐주셔서 감사합니다. 질문이 있으시면 토론 포럼에서 대화를 시작해 주세요. 여러분의 의견을 듣고 싶습니다. 또는 주문형 웨비나에서 Elastic을 사용한 로깅 및 통합 가시성에 대해 자세히 알아보세요.
이 데모를 직접 해보고 싶으시면, Elastic Cloud의 ElasticSearch Service 무료 체험판에 등록하거나 최신 버전을 다운로드하여 직접 관리해 보세요.