Logstash에 대한 실용적인 소개
Elastic Stack은 가능한 한 쉽게 Elasticsearch에 데이터를 수집할 수 있도록 해 드립니다. Filebeat는 파일을 집계하는 훌륭한 도구이며 가능한 경우, 최소한의 구성만으로도 광범위한 공통 로그 형식을 수집할 수 있게 해주는 모듈 집합을 제공합니다. 수집하려는 데이터가 이 모듈에서 다루어지지 않는 경우, Logstash 및 Elasticsearch 수집 노드는 대부분의 유형의 텍스트 기반 데이터를 구문 분석하고 처리할 수 있는 유연하고 강력한 방법을 제공합니다.
이 블로그 포스트에서는 Logstash에 대해 간단하게 소개해 드리고 일부 샘플 Squid 캐시 액세스 로그를 구문 분석하고 이를 Elasticsearch로 가져오는 구성을 개발할 때 어떻게 Lgostash를 사용할 수 있는지 설명해 드립니다.
Logstash의 간단한 개요
Logstash는 플러그인 기반의 데이터 수집 및 처리 엔진으로서, 광범위한 플러그인이 구비되어 다양한 수많은 아키텍처에서 손쉽게 데이터를 수집, 처리, 전달할 수 있게 해줍니다.
프로세싱은 하나 이상의 파이프라인으로 구성됩니다. 각 파이프라인에서 하나 이상의 입력 플러그인이 내부 대기열에 배치된 데이터를 수신하거나 수집합니다. 이것은 기본적으로 작고 메모리에 보관되지만 안정성과 복원력을 향상시키도록 디스크에서 더 크고 영구적으로 구성할 수 있습니다.
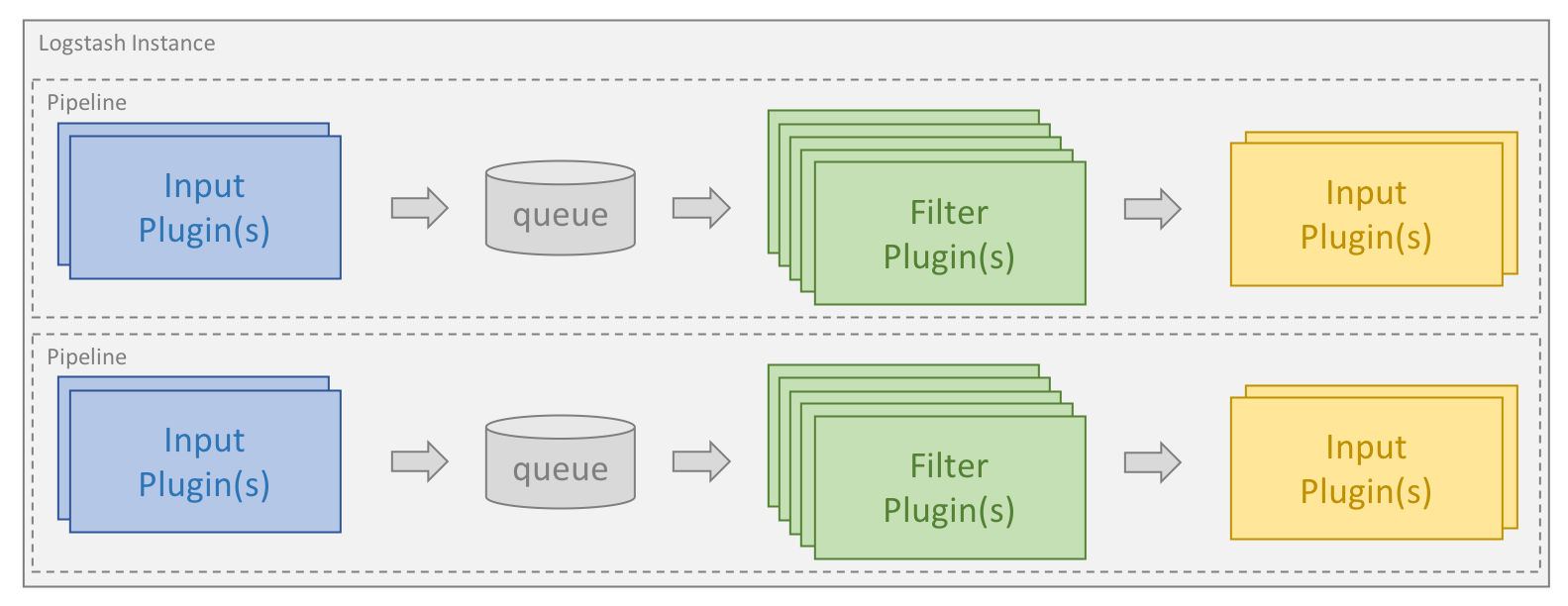
프로세싱 스레드는 대기열에서 데이터를 마이크로 배치로 읽은 다음, 구성된 필터 플러그인을 통해 순서대로 처리합니다. Logstash는 기본으로 특정 유형의 처리를 목표로 하는 많은 수의 플러그인과 함께 제공되며, 이렇게 해서 데이터가 구문 분석, 처리 및 강화됩니다.
데이터가 처리되면 프로세싱 스레드는 데이터를 포맷하고 Elasticsearch에 전송을 담당하는 적절한 출력 플러그인에 데이터를 전송합니다.
입력 및 출력 플러그인에서 codec 플러그인을 구성할 수도 있습니다. 이렇게 하면 데이터를 내부 대기열에 넣거나 출력 플러그인에 보내기 전에 데이터의 구문 분석 및/또는 포맷을 지정할 수 있습니다.
Logstash 및 Elasticsearch 설치하기
이 블로그 포스트에서 예제를 실행하려면 먼저 Logstash 설치 및 Elasticsearch를 설치해야 합니다. 이 링크를 따라 사용하는 운영 체제에 대한 설치 지침을 알아보시기 바랍니다. 여기서는 Elastic Stack 버전 6.2.4를 사용할 것입니다.
파이프라인 지정
Logstash 파이프라인은 하나 이상의 구성 파일을 기반으로 생성됩니다. 시작하기 전에, 제공되는 다양한 옵션에 대해 간단히 안내해 드리겠습니다. 이 섹션에서 설명하는 디렉터리는 설치 모드 및 운영 체제에 따라 달라질 수 있으며 이 설명서에 정의되어 있습니다.
단일 구성 파일을 사용한 단일 파이프라인
Logstash를 시작하는 가장 쉬운 방법이자 이 블로그 포스트에서 사용할 방법은 Logstash가 -f 명령줄 매개변수를 통해 지정하는 단일 구성 파일을 기반으로 단일 파이프라인을 만들게 하는 것입니다.
여러 구성 파일을 사용한 단일 파이프라인
Logstash는 특정 디렉터리의 모든 파일을 구성 파일로 사용하도록 구성할 수도 있습니다. 이것은 logstash.yml 파일을 통해 설정하거나 -f 명령줄 매개변수를 사용하여 디렉터리 경로를 명령줄을 통해 전달하여 설정할 수 있습니다. Logstash를 서비스로 설치하는 경우 이것이 기본값입니다.
디렉터리가 주어지면, 그 디렉토리 내 모든 파일은 사전식 순서로 연결된 다음, 단일 구성 파일로 구문 분석됩니다. 따라서 모든 입력에서의 데이터는 모든 필터에 의해 처리되고 조건문을 사용하여 흐름을 제어하지 않는 한 모든 출력으로 전송됩니다.
여러 파이프라인 사용
Logstash 내에서 여러 파이프라인을 사용하려면 Logstash와 함께 제공되는 pipelines.yml 파일을 편집해야 합니다. 이 파일은 settings 디렉터리에 있으며 Logstash 인스턴스가 지원하는 모든 파이프라인에 대한 구성 파일과 구성 매개변수를 포함합니다.
여러 파이프라인을 사용하면 다른 논리 흐름을 분리할 수 있으므로 사용된 조건의 복잡성과 양을 크게 줄일 수 있습니다. 이렇게 하면 구성을 쉽게 조정하고 유지 관리할 수 있습니다. 동시에 파이프라인을 통해 흐르는 데이터가 보다 균일화되어 출력 플러그인을 더 효율적으로 사용할 수 있으므로 성능이 크게 향상될 수 있습니다.
첫 번째 구성 만들기
모든 Logstash 구성에는 적어도 하나의 입력 플러그인과 하나의 출력 플러그인이 있어야 합니다. 필터는 선택 사항입니다. 간단한 구성 파일이 어떤 것인지 보여주는 첫 번째 예로, 파일에서 테스트 데이터 집합을 읽고 이를 구조화된 형식으로 콘솔에 출력하는 파일로 시작해 보겠습니다. 이것은 구성을 빨리 반복하고 구축할 수 있게 해 주므로 구성을 개발할 때 아주 유용한 구성입니다. 이 블로그 포스트는 구성 파일이test.conf라고 하고 테스트 데이터가 들어있는 파일과 함께 “/home/logstash”디렉토리에 저장된다고 가정합니다.
input {
file {
path => ["/home/logstash/testdata.log"]
sincedb_path => "/dev/null"
start_position => "beginning"
}
}
filter {
}
output {
stdout {
codec => rubydebug
}
}
여기서는 모든 Logstash 구성의 일부의 일부가 되는 입력, 필터 및 출력, 이 세 가지의 최상위 그룹을 보겠습니다. 입력 섹션에서 파일 입력 플러그인을 지정했고 경로 지시문을 통해 테스트 데이터 파일의 경로를 제공했습니다. start_position 지시문을 “beginning”으로 설정하여 새 파일이 발견될 때마다 처음부터 파일을 읽도록 플러그인에 지시합니다.
Logstash 파일 입력 플러그인은 처리된 각 입력 파일 내의 데이터를 추적하기 위해 sincedb라는 파일을 사용하여 현재 위치를 기록합니다. 설정이 개발을 위해 사용되기 때문에, 파일을 반복해서 읽기를 원하고, sincedb 파일을 사용하지 못하게 하고 싶습니다. Linux 기반 시스템에서 sincedb_path 지시문을 “/dev/null”로 설정하여 이 작업을 수행합니다. Windows에서 이것은 “nul”"로 설정됩니다.
Logstash 파일 입력 플러그인은 구성 개발을 시작하는 훌륭한 방법이지만 호스트 서버에서 로그를 수집하고 발송하는 용도로는 Filebeat가 권장 제품입니다. Filebeat는 Logstash에 로그를 출력할 수 있으며 Logstash는 Beats 입력을 통해 이러한 로그를 수신하고 처리할 수 있습니다. 이 블로그 포스트에 나와 있는 구문 분석 논리는 둘 중 어느 시나리오에도 여전히 적용되지만, Filebeat는 성능에 대해 더 최적화되어 있으며 낮은 리소스만 필요로 해서 에이전트로 실행하는데 이상적입니다.
stdout 출력 플러그인은 데이터를 콘솔에 쓰고 rubydebug 코덱은 구조를 보여줌으로써 구성 개발 중에 디버깅을 단순화합니다
Logstash 시작하기
Logstash와 구성 파일이 작동하는지 확인하도록 “/home/logstash” 디렉터리에 “testdata.log”라는 파일을 만듭니다. 이 파일에는 "Hello Logstash!"라는 문자열과 그 뒤에 따라오는 새로운 행이 포함됩니다.
경로에 logstash 바이너리가 있다고 가정하고, 다음 명령을 사용하여 Logstash를 시작할 수 있습니다.
logstash -r -f "/home/logstash/test.conf"
앞에서 설명한 -f 명령행 매개변수 외에 -r 플래그도 사용했습니다. 이렇게 하면 Logstash는 구성이 변경되었음을 식별할 때마다 자동으로 구성을 다시 로드합니다. 이것은 특히 개발 중 매우 유용합니다. sincedb 파일을 사용하지 않도록 설정했기 때문에 구성을 다시 로드할 때마다 입력 파일을 다시 읽게 되므로, 구성을 계속 개발하면서 구성 파일을 빨리 테스트할 수 있습니다.
Logstash로부터 콘솔로의 출력은 이와 관련된 일부 로그가 시작하는 것을 보여줍니다. 그 후 파일이 처리되고 다음과 같은 내용이 표시됩니다.
{
"message" => "Hello Logstash!",
"@version" => "1",
"path" => "/home/logstash/testdata.log",
"@timestamp" => 2018-04-24T12:40:09.105Z,
"host" => "localhost"
}
이것은 Logstash가 처리한 이벤트입니다. 데이터가 메시지 필드에 저장되고 Logstash가 이벤트에 대한 일부 메타 데이터를 처리된 타임스탬프의 형태로 원래의 위치에 추가했음을 알 수 있습니다.
이것은 모두 좋고 메커니즘이 제대로 작동하고 있음을 증명합니다. 이제 좀 더 실제적인 테스트 데이터를 추가해서 이것이 어떻게 구문 분석되는지 보겠습니다.
내 로그를 어떻게 구문 분석하나요?
로그가 JSON 형식인 경우 json filte와 같이, 때로는 데이터를 구문 분석하는 데 사용할 수 있는 완벽한 필터가 있습니다. 그러나 많은 경우, 다양한 유형의 텍스트 형식으로 로그를 구문 분석해야 합니다. 이 블로그 포스트에서 사용하는 예제는 다음과 같이 몇 줄의 Squid 캐시 액세스 로그입니다.
1524206424.034 19395 207.96.0.0 TCP_MISS/304 15363 GET /android-chrome-192x192.gif - DIRECT/10.0.5.120 - 1524206424.145 106 207.96.0.0 TCP_HIT/200 68247 GET /guide/en/logstash/current/images/logstash.gif - NONE/- image/gif
각 줄에는 Squid 캐시에 대한 요청 하나에 대한 정보가 포함되어 있으며 구문을 분석할 필요가 있는 여러 가지 distinct 필드로 나눌 수 있습니다.

텍스트 로그를 구문 분석할 때 특히 두 개의 필터가 일반적으로 사용됩니다. 해부(dissect)는 구분 문자를 기반으로 로그를 구문 분석하지만 grok은 정규 표현식 일치를 기반으로 작동합니다.
해부 필터는 데이터 구조가 잘 정의되어 있을 때 매우 잘 작동하며 아주빠르고 효율적일 수 있습니다. 또한 정규 표현식에 익숙하지 않은 사용자의 경우 시작하기가 더 쉽습니다.
Grok은 일반적으로 더 강력하고 다양한 데이터를 처리할 수 있습니다. 하지만 정규 표현식 일치는 더 많은 리소스를 사용할 수 있고, 특히 올바로 최적화되지 않은 경우 더 느려질 수 있습니다.
구문 분석을 하기 전에 testdata.log 파일의 내용을 이 두 로그 라인으로 대체하고 각 라인 뒤에 새로운 행이 따라오는지 확인합니다.
해부(dissect)로 로그 구문 분석하기
disssect 필터를 사용하여 작업할 때 추출할 필드의 시퀀스와 이 필드 사이의 구분 문자를 지정합니다. 필터는 데이터에 대해 단일 패스를 수행하고 패턴의 구분 문자를 일치시킵니다. 동시에 구분 문자 사이의 데이터는 지정된 필드에 지정됩니다. 필터는 추출 중인 데이터 형식의 유효성을 검사하지 않습니다.
dissect 필터를 사용하여 이 데이터를 구문 분석할 때 사용되는 구분 문자는 아래와 같이 분홍색으로 강조 표시됩니다.

첫 번째 필드는 타임 스탬프를 포함하며 다음 지속 기간 필드의 길이에 따라 하나 이상의 공백이 따릅니다. 타임 스탬프 필드를 %{timestamp}로 지정할 수 있습니다. 그러나 가변 공백 수를 구분 문자로 허용하려면, 필드에 -> 접미사를 추가해야 합니다. 로그 항목의 다른 모든 구분 문자는 단일 문자로만 구성됩니다. 따라서 패턴을 만들기 시작할 수 있으며 다음과 같은 필터 섹션이 생성됩니다.
{
"@version" => "1",
"message" => "1524206424.034 19395 207.96.0.0 TCP_MISS/304 15363 GET /android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"@timestamp" => 2018-04-24T12:42:23.003Z,
"path" => "/home/logstash/testdata.log",
"host" => "localhost",
"duration" => "19395",
"timestamp" => "1524206424.034",
"rest" => "TCP_MISS/304 15363 GET /android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"client_ip" => "207.96.0.0"
}
이제 패턴을 단계별로 계속해서 구축할 수 있습니다. 모든 필드를 성공적으로 구문 분석하면 동일한 필드를 두 번 보류하지 않도록 메시지 필드를 제거할 수 있습니다. 구문 분석이 성공적인 경우에만 실행되는 remove_field 지시문을 사용하여 이 작업을 수행하면 다음 필터 블록이 생성됩니다.
filter {
dissect {
mapping => {
"message" => "%{timestamp->} %{duration} %{client_address} %{cache_result}/%{status_code} %{bytes} %{request_method} %{url} %{user} %{hierarchy_code}/%{server} %{content_type}"
}
remove_field => ["message"]
}
}
샘플 데이터에 대해 실행하면 첫 번째 레코드는 다음과 같습니다.
{
"user" => "-",
"content_type" => "-",
"host" => "localhost",
"cache_result" => "TCP_MISS",
"@timestamp" => 2018-04-24T12:43:07.406Z,
"duration" => "19395",
"request_method" => "GET",
"url" => "/android-chrome-192x192.gif",
"timestamp" => "1524206424.034",
"status_code" => "304",
"server" => "10.0.5.120",
"@version" => "1",
"client_address" => "207.96.0.0",
"bytes" => "15363",
"path" => "/home/logstash/testdata.log",
"hierarchy_code" => "DIRECT"
}
문서에는 몇 가지 좋은 예가 포함되어 있으며, 이 블로그 포스트는 필터의 설계와 목적에 대한 좋은 토론 내용을 제공합니다.
이 작업이 꽤 쉬웠습니다, 그렇죠? 나중에 좀 더 처리를 해 보겠지만 먼저 grok을 사용하여 동일한 작업을 수행할 수 있는 방법을 살펴보겠습니다.
grok으로 가장 잘 작업하는 방법은 무엇입니까?
Grok은 일반 표현식 패턴을 사용하여 필드와 구분 문자를 모두 일치시킵니다. 아래 그림은 파란색으로 캡처할 필드와 빨간색의 구분 문자를 보여 줍니다.

Grok은 처음부터 구성된 패턴을 일치하기 시작하고 전체 이벤트가 매핑되거나 일치 항목을 찾을 수 없다고 판단할 때까지 계속합니다. 사용된 유형의 패턴에 따라 grok이 데이터의 일부를 여러 번 처리해야 할 수도 있습니다.
Grok은 미리 만들어진 다양한 패턴을 제공합니다. 좀 더 일반적인 패턴을 여기서 찾을 수 있지만, 이 리포지토리는 또한 일반적인 데이터 유형을 위한 많은 수의 특수한 패턴을 포함합니다. 사실 Squid 액세스 로그 구문 분석용으로 하나가 있지만, 이 튜토리얼에서는 이것을 바로 사용하기보다는 처음부터 다시 구성하는 방법을 보여 드리겠습니다. 그러나 사용자 지정 패턴 생성을 시작하기 전에 적합한 패턴이 이미 존재하는지 여부를 이 리포지토리에서 확인할 가치가 있음을 나타냅니다.
grok config를 만들 때 일반적으로 사용되는 표준 패턴이 여러 가지 있습니다.
- WORD - 단일 단어에 일치하는 패턴
- NUMBER - 양이나 음의 정수 또는 부동 소수점에 일치하는 패턴.
- POSINT - 양의 정수와 일치하는 패턴
- IP - IPv4 또는 IPv6 IP 주소와 일치하는 패턴
- NOTSPACE - 스페이스가 아닌 모든 것과 일치하는 패턴
- SPACE - 모든 수의 연속적 스페이스와 일치하는 패턴
- DATA - 제한된 양의 모든 종류의 데이터와 일치하는 패턴
- GREEDYDATA - 모든 남아 있는 데이터와 일치하는 패턴
이것들은 grok 필터 설정을 만들 때 사용할 패턴입니다. grok 설정을 만드는 방법은 일반적으로 왼쪽부터 시작하여 GREEDYDATA 패턴을 사용하여 나머지 데이터를 캡처하는 패턴을 단계적으로 작성하는 것입니다. 다음과 같은 패턴 및 필터 블록을 사용해서 시작할 수 있습니다.
filter {
grok {
match => {
"message" => "%{NUMBER:timestamp}%{SPACE}%{GREEDYDATA:rest}"
}
}
}
이 패턴은 grok이 문자열의 시작 부분에서 숫자를 찾아 timestamp라는 이름의 필드에 저장하도록 지시합니다. 그런 다음 rest라는 필드에 나머지 데이터를 저장하기 전에 여러 스페이스를 일치시킵니다. 이것에 대한 dissect 필터 블록을 전환하면, 첫 번째 레코드가 다음과 같이 나옵니다.
{
"timestamp" => "1524206424.034",
"rest" => "19395 207.96.0.0 TCP_MISS/304 15363 GET /android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"path" => "/home/logstash/testdata.log",
"message" => "1524206424.034 19395 207.96.0.0 TCP_MISS/304 15363 GET /android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"@timestamp" => 2018-04-24T12:45:11.026Z,
"@version" => "1",
"host" => "localhost"
}
grok debugger 사용하기
전체 패턴을 이런 방식으로 개발할 수 있지만, Kibana에 Grok Debugger라고 하는, grok 패턴 생성을 단순화하는 데 도움이 되는 도구가 있습니다. 아래 동영상에서는 이 도구를 사용하여 이 블로그 포스트에 사용된 예제 로그에 대한 패턴을 구축하는 방법을 보여줍니다.
일단 구성이 구축되면, 구문 분석이 성공적으로 끝난 후 메시지 필드를 삭제할 수 있습니다. 그러면 필터 블록이 다음과 같이 나타납니다.
filter {
grok {
match => {
"message" => "%{NUMBER:timestamp}%{SPACE}%{NUMBER:duration}\s%{IP:client_address}\s%{WORD:cache_result}/%{POSINT:status_code}\s%{NUMBER:bytes}\s%{WORD:request_method}\s%{NOTSPACE:url}\s%{NOTSPACE:user}\s%{WORD:hierarchy_code}/%{NOTSPACE:server}\s%{NOTSPACE:content_type}"
}
remove_field => ["message"]
}
}
이것은 미리 만들어진 패턴과 유사하지만 동일하지는 않습니다. 샘플 데이터에 대해 실행하면 첫 번째 레코드는 dissect 필터를 사용했을 때와 같은 방식으로 구문 분석됩니다.
{
"request_method" => "GET",
"cache_result" => "TCP_MISS",
"@timestamp" => 2018-04-24T12:48:15.123Z,
"timestamp" => "1524206424.034",
"user" => "-",
"bytes" => "15363",
"path" => "/home/logstash/testdata.log",
"hierarchy_code" => "DIRECT",
"duration" => "19395",
"client_address" => "207.96.0.0",
"@version" => "1",
"status_code" => "304",
"url" => "/android-chrome-192x192.gif",
"content_type" => "-",
"host" => "localhost",
"server" => "10.0.5.120"
}
성능 향상을 위한 Grok 조정
Grok은 데이터를 구문 분석하는 데 매우 강력하고 유연한 도구이지만 패턴을 비효율적으로 사용하면 예상보다 낮은 성능의 결과를 낳을 수 있습니다. 따라서 grok을 본격적으로 사용하기 전에 grok 성능 조정에 대한 이 블로그 포스트를 읽어 볼 것을 권장합니다.
필드가 올바른 유형인지 확인
위의 예제에서 보았듯이 모든 필드는 문자열 필드로 구문 분석되었습니다. 이것을 JSON 문서의 형태로 Elasticsearch에 보내기 전에 byte, duration 및 status_code필드를 정수로, 타임 스탬프를 float로 변경하고자 합니다.
이렇게 하는 한 가지 방법은 mutate 필터와 convert 옵션을 사용하는 것입니다.
mutate {
convert => {
"bytes" => "integer"
"duration" => "integer"
"status_code" => "integer"
"timestamp" => "float"
}
}
dissect 및 grok 필터에서 이를 직접 수행할 수도 있습니다. dissect 필터에서는 convert_datatype 지시문을 통해 이 작업을 수행합니다.
filter {
dissect {
mapping => {
"message" => "%{timestamp->} %{duration} %{client_address} %{cache_result}/%{status_code} %{bytes} %{request_method} %{url} %{user} %{hierarchy_code}/%{server} %{content_type}"
}
remove_field => ["message"]
convert_datatype => {
"bytes" => "int"
"duration" => "int"
"status_code" => "int"
"timestamp" => "float"
}
}
}
grok을 사용할 때 패턴의 필드 이름 바로 뒤에 유형을 지정할 수 있습니다.
filter {
grok {
match => {
"message" => "%{NUMBER:timestamp:float}%{SPACE}%{NUMBER:duration:int}\s%{IP:client_address}\s%{WORD:cache_result}/%{POSINT:status_code:int}\s%{NUMBER:bytes:int}\s%{WORD:request_method}\s%{NOTSPACE:url}\s%{NOTSPACE:user}\s%{WORD:hierarchy_code}/%{NOTSPACE:server}\s%{NOTSPACE:content_type}"
}
remove_field => ["message"]
}
}
날짜 필터 사용하기
로그에서 추출된 타임스탬프는 시작후 초 및 밀리 초의 단위로 되어 있습니다. 이것을 @timestamp 필드에 저장할 수 있는 표준 타임스탬프 형식으로 변환하고자 합니다. 이를 위해, 보유한 데이터와 일치하는 UNIX 패턴과 함께 날짜 플러그인을 사용합니다.
date {
match => [ "timestamp", "UNIX" ]
}
Elasticsearch에 저장된 모든 표준 타임스탬프는 UTC 시간대입니다. 이것이 추출된 타임스탬프에도 적용되므로 시간대를 지정할 필요가 없습니다. 다른 형식의 타임스탬프가 있는 경우, 미리 정의된 UNIX 패턴 대신 이 형식을 지정할 수 있습니다.
일단 이것과 유형 전환을 설정에 추가하면, 첫 번째 이벤트는 다음과 같이 보입니다.
{
"duration" => 19395,
"host" => "localhost",
"@timestamp" => 2018-04-20T06:40:24.034Z,
"bytes" => 15363,
"user" => "-",
"path" => "/home/logstash/testdata.log",
"content_type" => "-",
"@version" => "1",
"url" => "/android-chrome-192x192.gif",
"server" => "10.0.5.120",
"client_address" => "207.96.0.0",
"timestamp" => 1524206424.034,
"status_code" => 304,
"cache_result" => "TCP_MISS",
"request_method" => "GET",
"hierarchy_code" => "DIRECT"
}
이제 원하는 형식을 가지게 되었으며 Elasticsearch에 데이터를 보낼 준비가 된 것 같습니다.
Elasticsearch에 데이터를 보내려면 어떻게 해야 합니까?
elasticsearch 출력 플러그인을 사용하여 Elasticsearch에 데이터를 보내기 전에 맵핑의 역할과 매핑이 Logstash에서의 변환될 대상의 유형과 어떻게 다른지 살펴보아야 합니다.
Elasticsearch에는 문자열 및 숫자 필드를 자동으로 감지하는 기능이 있으며 선택한 매핑은 새로운 필드가 있는 첫 번째 문서를 기반으로 합니다. 데이터의 모양에 따라 올바른 매핑이 제공되거나 제공되지 않을 수 있습니다. 예를 들어 일반적으로 float이지만 일부 레코드의 경우 '0'일 수 있는 필드가 있는 경우, 이것은 어떤 문서가 먼저 처리되었는지에 따라 float 대신 정수로 매핑될 수 있습니다.
Elasticsearch에는 날짜 필터가 만드는 표준 형식으로 되어 있는 한, 날짜 필드를 자동으로 탐지하는 기능도 있습니다.
다른 유형의 필드, 예를 들어 geo_point 및 ip는 자동으로 탐지될 수 없고 인덱스 템플릿을 통해 명시적으로 정의되어야 합니다. 인덱스 템플릿은 API를 통해 Elasticsearch에서 직접 관리할 수 있지만 Logstash에서 elasticsearch 출력 플러그인을 통해 적절한 템플릿이 로드되게 하는 것도 가능합니다.
데이터의 경우 기본 매핑에 일반적으로 만족합니다. server 필드에는 대시 또는 유효한 IP 주소가 포함될 수 있으므로 이것을 IP 필드로 매핑하지 않을 것입니다. 수동 매핑을 필요로 하는 한 필드는 client_address 필드인데 이 필드가 ip 유형이기를 바랍니다. 또한 집계할 수 있는 몇 개의 문자열 필드를 가지고 있지만 이에 대해 자유 텍스트 검색을 수행할 필요는 없습니다. keyword 필드로 명시적으로 매핑할 것입니다. 이러한 필드는 user, path, content_type, cache_result, request_method, server 및 hierarchy_code입니다.
접두사 squid-로 시작하는 시간 기반 인덱스에 데이터를 저장하려고 합니다. 이 예에서는 Elasticsearch가 Logstash와 동일한 호스트에서 기본 구성으로 실행되고 있다고 가정합니다.
그 후 squid_mapping.json 파일에 저장된 다음 템플릿을 작성할 수 있습니다.
{
"index_patterns": ["squid-*"],
"mappings": {
"doc": {
"properties": {
"client_address": { "type": "ip" },
"user": { "type": "keyword" },
"path": { "type": "keyword" },
"content_type": { "type": "keyword" },
"cache_result": { "type": "keyword" },
"request_method": { "type": "keyword" },
"server": { "type": "keyword" },
"hierarchy_code": { "type": "keyword" }
}
}
}
}
이 템플릿은 인덱스 패턴 squid-*와 일치하는 모든 인덱스에 적용되도록 구성됩니다. 문서 유형 doc(기본값은 Elasticsearch 6.x)의 경우, client_address 필드에 대한 매핑을 ip로 지정하고 지정된 다른 필드는 keyword에 매핑되도록 지정합니다.
이것을 Elasticsearch에 직접 업로드할 수 있지만, 대신elasticsearch 출력 플러그인을 구성하는 방법을 보여 드리겠습니다. Logstash 구성의 출력 섹션에서 다음과 같은 블록을 추가합니다.
elasticsearch {
hosts => ["localhost:9200"]
index => "squid-%{+YYYY.MM.dd}"
manage_template => true
template => "/home/logstash/squid_mapping.json"
template_name => "squid_template"
}
이제 이 구성을 실행하고 샘플 문서를 Elasticsearch로 인덱스합니다. 매핑 API 얻기를 통해 인덱스에 대한 결과 매핑을 검색할 때 다음을 얻게 됩니다.
{
"squid-2018.04.20" : {
"mappings" : {
"doc" : {
"properties" : {
"@timestamp" : {
"type" : "date"
},
"@version" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"bytes" : {
"type" : "long"
},
"cache_result" : {
"type" : "keyword"
},
"client_address" : {
"type" : "ip"
},
"content_type" : {
"type" : "keyword"
},
"duration" : {
"type" : "long"
},
"hierarchy_code" : {
"type" : "keyword"
},
"host" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"path" : {
"type" : "keyword"
},
"request_method" : {
"type" : "keyword"
},
"server" : {
"type" : "keyword"
},
"status_code" : {
"type" : "long"
},
"timestamp" : {
"type" : "float"
},
"url" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"user" : {
"type" : "keyword"
}
}
}
}
}
}
템플릿이 적용되었고 지정한 필드가 올바르게 매핑된 것을 볼 수 있습니다. 이 블로그 포스트의 주된 초점은 Logstash이므로 매핑 작업을 피상적으로만 다루었다고 하겠습니다. 이 중요 주제에 대한 자세한 내용은 문서를 참조하세요.
결론
이 블로그 포스트에서는 샘플, 사용자 지정 구성을 개발하는 동안 Logstash와 어떻게 가장 효과적으로 작업하는 방법을 설명했고 이것이 Elasticsearch에 성공적으로 쓰여지도록 했습니다. 하지만 이것은 Logstash로 무엇을 달성할 수 있는지에 대해 수박 겉핥기 식으로 피상적으로 다루었을 뿐입니다. 이 블로그 포스트 전체에서 링크를 제공한 문서 및 블로그 포스트를 살펴보고, 또 공식 시작하기 가이드, 사용 가능한 모든 input, output 및 filter플러그인을 살펴보세요. 일단 무엇이 제공되는지 이해하면 Logstash는 신속하게 데이터 처리의 다용도 도구가 됩니다.
문제가 발생하거나 추가 질문이 있으시면, 토론 포럼의 Logstash 카테고리에서 언제든지 문의해 주세요. 다른 샘플 데이터와 logstash 구성을 보고 싶다면 https://github.com/elastic/examples/에 더 많은 예제가 나와 있습니다.
즐겁게 구문 분석하세요!