Logstash Dude, where's my chainsaw? I need to dissect my logs
Most Logstash users that want to extract structured fields from an unstructured event data use the popular Grok filter. This filter uses regular expressions under the hood and is versatile to many forms of text. Over time, users tend to use Grok for all of their structured extraction needs. This, in many cases, is analogous to using a sledgehammer to crack a nut. Regular expressions are sledgehammers. They are extremely powerful, but they can be unforgiving -- a poorly built regex can slow down the Logstash pipeline when run on certain lines of text. The pipeline is designed to recover, but the overall performance becomes unpredictable leading to unhappy users.
My colleague João Duarte, while investigating the performance characteristics of the Grok Filter noticed that match failures incur increasing performance penalties. Most of these issues boil down to ReDOS problems, which essentially means that the regex engine descends into excessive backtracking, leading to a slower Logstash pipeline.
Another colleague, PH Pellerin, has recently re-implemented the Beats Input to handle input data asynchronously that led to an impressive throughput increase. In Logstash processing, the slowest component slows down the entire pipeline, and typically filters are the heavy lifters. I thought it wouldn’t really help to have a couple of speedier inputs with a slow Grok filter for field extraction, and hence Dissect filter was born.
Design
Essentially, field extraction in Dissect is a kind of 'split' operation and normally a split is done with one delimiter that is expected to be repeated in the source text. In contrast to Grok, which asks you to specify the regex patterns for fields of interest, Dissect asks you to specify the patterns of delimiters between the fields of interest. Dissect queues up the delimiters and searches the source text once from left to right, finding each successive delimiter in the queue. Different search algorithms are used for 1, 2 and 3+ byte delimiters.
Dissect is written in Java with a very thin JRuby extension wrapper to expose the Java internals to Logstash's JRuby runtime environment. It also directly uses the rewritten Java Event code, released in Logstash 5.0. This is why Dissect is only compatible with Logstash 5.X.
Dissect uses the bytes behind the JRuby UTF-8 Ruby String directly without the expensive conversion to a Java String beforehand. The delimiter searching will only remember where in the source bytes each delimiter was found. The Event field and value setting uses the found indices and lengths only once to create the strings to set into the Event.
The format of the patterns of fields and delimiters is similar to Grok:
"<%{priority}>%{syslog_timestamp} %{+syslog_timestamp} %{+syslog_timestamp} %{logsource} %{rest}".
In the above example, the yellow highlight shows the delimiters and blue highlight the field names. I quickly realised that various field syntaxes were needed to differentiate fields of extraction. There are four at the time of writing: Normal, Skip, Append and Indirect.
Normal field type
This type simply adds the found value to the event using the specified text as the name of the field, e.g. %{priority}.
Skip field type
The pattern format requires you to specify each delimiter by putting them between } and %{ meaning there will be times when you need to specify fields but you don't need the values in the event - it should be ignored or skipped. To do this you can have an empty field e.g. %{} or a named skipped field which is prefixed with a question mark "?", e.g. %{?priority}. You might choose to name your skip fields to make the final dissect pattern more readable.
Append field type
For the same reason - needing to specify all delimiters, you might need to rebuild a split value. Taking the syslog date as an example, if the source text looks like this <1>Oct 26 20:21:22 alpha1 rest... - you will need to specify fields for the month, day and time. Maybe you want fields these as separate in your events but more likely you will want to rebuild these into one value. This is what an Append field does. For example, %{syslog_timestamp} %{+syslog_timestamp} %{+syslog_timestamp} will firstly have the month "Oct" value in the syslog_timestamp field but then the next +syslog_timestamp adds the day "26" value to "Oct" but with its prior delimiter in between - in this case a space, resulting in "Oct 26". This is repeated for last +syslog_timestamp so the final value for the field syslog_timestamp will be "Oct 26 20:21:22".
Sometimes, you will want to rebuild the value in a different order - this is supported with an ordinal suffix "/<int>", e.g. %{+syslog_timestamp/1}. There is more info and examples on this in the docs.
Indirect field type
Use the value of one field to be the key of another. This type is arguably the least useful type and the syntax looks strange because it leverages Skip fields. Please read up more on these in the docs.
Conversions
To reduce the need to use a Mutate filter to convert an obvious floating point or integer number string into a real Float or Integer value in the event, you can specify a conversion. Please read the docs for more information on this. This feature can be used on its own without a dissect directive.
Example: Replace a Grok + CSV combo with one Dissect filter
Extract fields for the Palo Alto Networks Firewall PAN OS 6 syslog output for "threat" type messages. See the generator input config below for an example of a log line. It's a Syslog preamble with a CSV body
Logstash Configs
Input
input {
generator {
message => "<1>Oct 16 20:21:22 www1 1,2016/10/16 20:21:20,3,THREAT,SCAN,6,2016/10/16 20:21:20,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54"
time => 120
}
}
The generator input has been modified to run for a fixed amount of time rather than a fixed amount of events.
Grok + CSV
filter {
if [message] =~ "THREAT," {
grok {
match => { "message" => "\A<%{POSINT:priority}>%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:sysloghost} %{DATA:pan_fut_use_01},%{DATA:pan_rec_time},%{DATA:pan_serial_number},%{DATA:pan_type},%{GREEDYDATA:message}\z" }
overwrite => [ "message" ]
}
csv {
separator => ","
columns => ["pan_subtype", "pan_fut_use_02", "pan_gen_time", "pan_src_ip", "pan_dst_ip", "pan_nat_src_ip", "pan_nat_dst_ip", "pan_rule_name", "pan_src_user", "pan_dst_user", "pan_app", "pan_vsys", "pan_src_zone", "pan_dst_zone", "pan_ingress_intf", "pan_egress_intf", "pan_log_fwd_profile", "pan_fut_use_03", "pan_session_id", "pan_repeat_cnt", "pan_src_port", "pan_dst_port", "pan_nat_src_port", "pan_nat_dst_port", "pan_flags", "pan_prot", "pan_action", "pan_misc", "pan_threat_id", "pan_cat", "pan_severity", "pan_direction", "pan_seq_number", "pan_action_flags", "pan_src_location", "pan_dst_location", "pan_content_type", "pan_pcap_id", "pan_filedigest", "pan_cloud", "pan_user_agent", "pan_file_type", "pan_xff", "pan_referer", "pan_sender", "pan_subject", "pan_recipient", "pan_report_id", "pan_threat_extra1", "pan_threat_extra2"]
}
}
}
Dissect
filter {
if [message] =~ "THREAT," {
dissect {
mapping => {
message => "<%{priority}>%{syslog_timestamp} %{+syslog_timestamp} %{+syslog_timestamp} %{logsource} %{pan_fut_use_01},%{pan_rec_time},%{pan_serial_number},%{pan_type},%{pan_subtype},%{pan_fut_use_02},%{pan_gen_time},%{pan_src_ip},%{pan_dst_ip},%{pan_nat_src_ip},%{pan_nat_dst_ip},%{pan_rule_name},%{pan_src_user},%{pan_dst_user},%{pan_app},%{pan_vsys},%{pan_src_zone},%{pan_dst_zone},%{pan_ingress_intf},%{pan_egress_intf},%{pan_log_fwd_profile},%{pan_fut_use_03},%{pan_session_id},%{pan_repeat_cnt},%{pan_src_port},%{pan_dst_port},%{pan_nat_src_port},%{pan_nat_dst_port},%{pan_flags},%{pan_prot},%{pan_action},%{pan_misc},%{pan_threat_id},%{pan_cat},%{pan_severity},%{pan_direction},%{pan_seq_number},%{pan_action_flags},%{pan_src_location},%{pan_dst_location},%{pan_content_type},%{pan_pcap_id},%{pan_filedigest},%{pan_cloud},%{pan_user_agent},%{pan_file_type},%{pan_xff},%{pan_referer},%{pan_sender},%{pan_subject},%{pan_recipient},%{pan_report_id},%{pan_anymore}"
}
}
}
}
Output
output {
counter { warmup => 60 }
}
The output is a new output that I built - it captures the number of events and the start time of receiving the first event and the end time of last event and prints out the event count, duration, events per second and the microseconds per event. It is written to be thread-safe and be as lightweight as possible. A warmup delay before data capture of 60 seconds was specified to allow JRuby and the JVM to stabilise.
Performance
In these configurations, maximum throughput is when the filter/output, while still doing some work, takes events as fast as the input can generate them. Please note that this applies to the synchronous queue that sits between the inputs and the filter/outputs. The synchronous operation means that the single generator input thread must wait until a filter/output worker thread takes the event it is offering. In the near future we will release an asynchronous queue where this lock-step synchronicity will no longer apply.
The filter sections were run on on Logstash 5.0.
Events per second
Filters \ Workers | 1 | 2 | 3 | 4 | 5 | 6 |
Grok + CSV | 5003 | 8769 | 12697 | 15615 | 12467 | 12895 |
CSV | 7351 | 12719 | 18921 | 21492 | 21053 | 16549 |
Grok | 14255 | 27263 | 40241 | 45977 | 46104 | 46882 |
Dissect | 16396 | 32510 | 50025 | 53619 | 53050 | 52493 |
Date | 19759 | 40290 | 62775 | 65445 | 62854 | 59488 |
Mutate (rename) | 29248 | 59630 | 79114 | 83195 | 79745 | 82988 |
Noop | 32031 | 65574 | 80645 | 85616 | 85397 | 86881 |
 |
Comparison
Filters \ Workers | 1 | 2 | 3 | 4 | 5 | 6 |
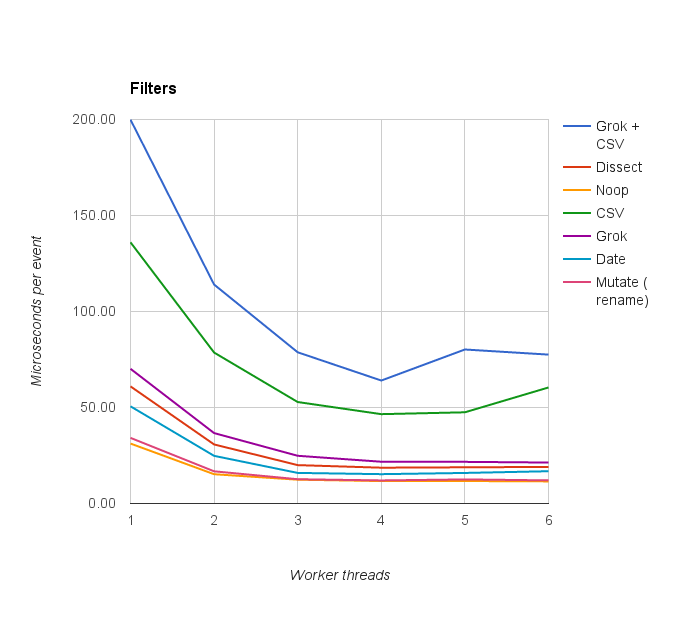
Grok + CSV | 199.89 | 114.04 | 78.76 | 64.04 | 80.21 | 77.55 |
Dissect | 60.99 | 30.76 | 19.99 | 18.65 | 18.85 | 19.05 |
Noop | 31.22 | 15.25 | 12.40 | 11.68 | 11.71 | 11.51 |
From Table 2, it can be seen that Dissect out-performs Grok + CSV by some margin but with less certainty. See the important note below.
Breakdown
Filters \ Workers | 1 | 2 | 3 | 4 | 5 | 6 |
CSV | 136.03 | 78.62 | 52.85 | 46.53 | 47.50 | 60.43 |
Grok | 70.15 | 36.68 | 24.85 | 21.75 | 21.69 | 21.33 |
From the above tables and chart one can see that the CSV filter is responsible for the lower performance of the Grok + CSV configuration and that Grok when configured optimally, performs just fine for this data set.
Other filters
Filters \ Workers | 1 | 2 | 3 | 4 | 5 | 6 |
Date | 50.61 | 24.82 | 15.93 | 15.28 | 15.91 | 16.81 |
Mutate (rename) | 34.19 | 16.77 | 12.64 | 12.02 | 12.54 | 12.05 |
Practical configurations might use other filters like the Mutate filter and the Date filter. Tables 3 and 4 show performance for these filters so you can get a feel for how latencies might build on each other.
Also note that the performance for the Date filter above is for a single pattern that always matches and that latency will increase with multiple patterns when some dates in your data do not match the first pattern.
Important: Be sure to guard a Dissect filter with an if field regex match condition to apply the correct dissection to the incoming text. It is more performant than two partial dissections with an “if field equals value” from a previous dissection. Without a conditional guard, Dissect will try to apply a mapping to a field and it may add some fields to an event but they would probably be not what was intended. Grok on the other hand inherently matches or fails. You should therefore be aware that, by using Dissect, you get better performance but less certainty of correct field extraction.
Is Dissect a replacement for Grok?
Yes and no. In some cases yes, but remember that Dissect is not as flexible as Grok. In cases where Dissect cannot entirely solve the problem, it can be used first to extract the more predictable fields and then the remaining irregular text is passed along to the Grok filter. As the reduced Grok patterns are more focussed and are being applied to smaller texts, Grok’s performance should be less variable.
Is Dissect a replacement for CSV?
Yes if performance is paramount. However, you may find the config syntax of the CSV filter more intuitive. In the near future, we will leverage some of the techniques from Dissect in the CSV filter to put its performance on a par with Dissect.
Dissect is a new filter plugin for Logstash. It is performant enough to keep up with the fastest inputs and outputs. If you are using Logstash 5.X or planning to, evaluate Dissect to see for yourself whether it can improve your throughput and simplify your configs. You can simply install dissect by using bin/logstash-plugin install logstash-filter-dissect. We love feedback from our users, so please reach out to us on twitter or on our forums. Happy dissecting!
Image - Chainsaw Art, by Arboriculturalist and chainsaw carver Jonny Stableford (JonnyChainsaw) By Mike Smith [CC BY 2.0 (http://creativecommons.org/licenses/by/2.0)], via Wikimedia Commons