実例: Machine LearningとElasticsearchをセキュリティ分析に利用する
編集者注(2021年8月3日):この投稿は廃止予定の機能を使用しています。現在の手順については、逆ジオコーディングを使用したカスタム地域のマッピングドキュメントを参照してください。
イントロダクション
これまで複数回にわたるリーズで、ElasticsearchをArcSight SIEMと共に使う方法を紹介しました。前回はX-PackのAlertingを使用してブルートフォースログイン攻撃を検出しましたが、Machine Learingについてはリリース前だったということもあり、もったいぶった部分があります。
そしてついにその時が来ました。X-PackのMachine Learningの登場です。今回はElasticsearch内のログデータにおいて、サイバー攻撃による異常を検知するのにMachine Learningを使用するというのがどういうことなのか、詳しく説明していきたいと思います。
数学です。魔法ではありません。
内容に入る前に、まず簡単な説明を加えておく方がいいかもしれません。サイバーセキュリティに関するよくある誤解は、機械学習が何かしら魔法のアルゴリズムが入った箱のようなもので、データを放り込めば自動的に素晴らしい情報の塊を出してくれる、と考えることです。
そうではなく、サイバーセキュリティにおける機械学習は「補助アルゴリズム」の兵器庫のようなもので、脅威となりうる異常やパターンを探すことでセキュリティ関連のログデータの解析を自動化してくれる(ただしセキュリティのベテランである人間の指揮の元で)、補助的な機能であると考える方が賢明です。
脅威のモニタリングかハンティングか - Machine Learningの役割
X-PackのMachine Learingは、脅威に係る異常をインタラクティブに調査するのに使用できます。Kibanaの「Anomaly Swimlane」のVisualizationはよく、脅威ハンティングのスタート地点として使用されますが、検出された異常の詳細には「なぜ」その挙動が異常として検知されたのか、どのくらい異常なのか、検出しようとした基本的な攻撃挙動にどう関連するのか、そしてデータのどのエンティティが攻撃挙動に影響しているのかが、セキュリティアナリストに示されます。
X-PackのMachine LearningはElastic Stackにしっかりと組み込まれているので、「Integrating Elasticsearch with ArcSight SIEM」(ElasticsearchとArcSight SIEMの統合)のパート2 と パート4 のブログで紹介したAlertingテクニックを新たにMachine Learningの実行結果のインデックスに適用することができるようになりました。このインデックスパターンはml-anomalies-*と呼ばれます。この方法により、これら補助的なアルゴリズムから導き出された結果を、脅威モニタリングのアラートトリガーとして使用することができるのです。
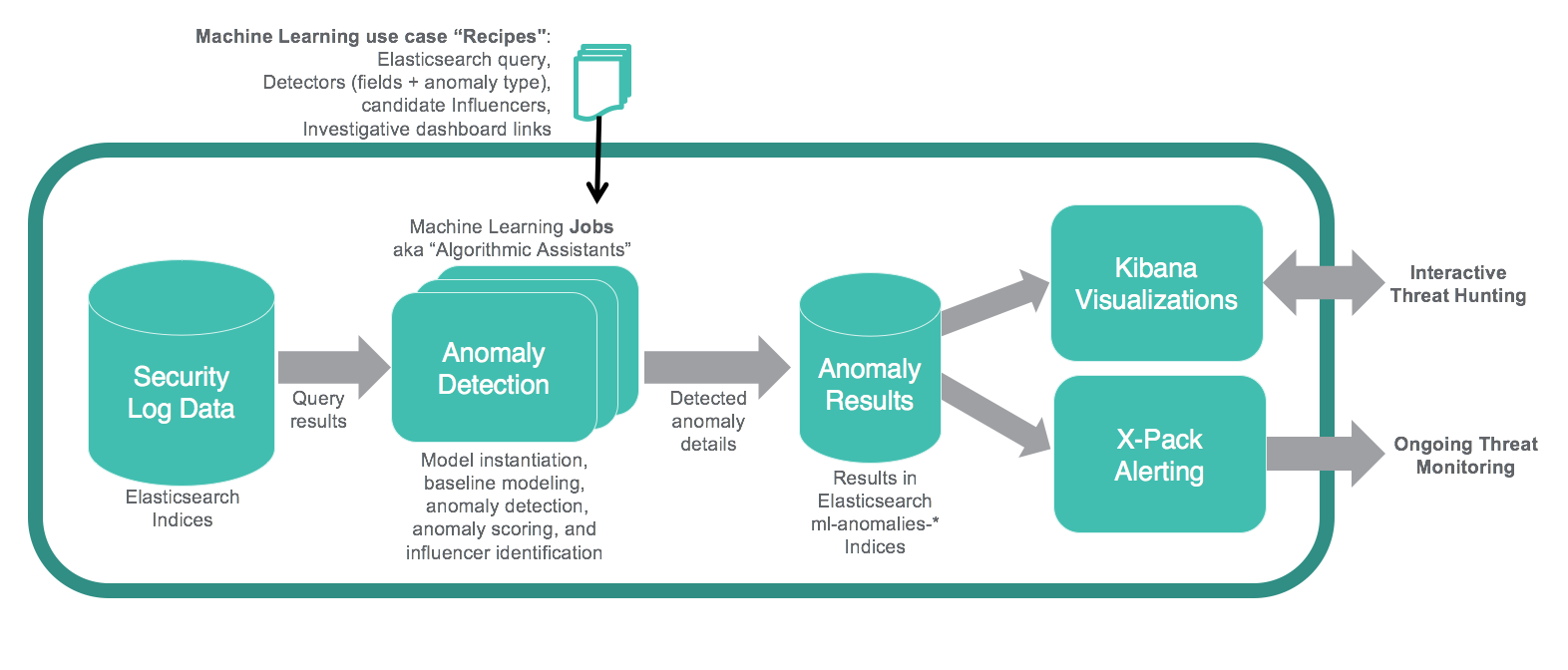
脅威検出のためのMachine Learning「レシピ」
閾値ベースのイベント通知はパワフルですが、複数回のログインを失敗したの後に成功した、などというイベントに基づいて通知するような場合を考えると、これまでセキュリティアナリストの知見なしでは達成できなかったことが、簡単に行えるようになるかもしれません。
とは言え、既に記述した通りこれは数学的な話であって魔法の話ではありませんので、Machine Learningエンジンにはジョブ設定という名の命令を出す必要があります。エンジンは数値やカテゴリに関わらずどんなタイプの時系列データでも理解できますので、設定できるMachine Learningジョブの種類は無限です。柔軟性に富んではいますが、単に脅威だけを見つけたいセキュリティアナリストにとっては複雑すぎるかもしれませんね。
ここではセキュリティで使用する場合のMachine Learning「レシピ」のコンセプトをご紹介します。レシピにはMachine Learningジョブの設定方法が記載されています。これは他の方法では検出が難しい基本的な攻撃挙動を、自動化された異常検知で摘発できるようにするためのものです。基本的な攻撃挙動には、DNSトンネリング、ウェブデータ抜き出し、疑わしいエンドポイントプロセス実行などのアクティビティが含まれます。

図2 セキュリティユースケースでのMachine Learningレシピの例
各レシピは、処理理論、説明、および結果のモデル化と観察を行うための具体的なレシピステップなどの各セクションに分けられた短いドキュメントに含まれています。レシピステップには特徴選択、モデル化手法、検出ターゲット、比較セット、インフルエンサー候補、解析期間、および結果の解釈が含まれます。
バージョン5.4のリリースの際には、セキュリティのユースケースの例を紹介しましたが、 こちらのGitHubのリポジトリ, で、複数のレシピ、設定、データ、スクプトなど、すぐに試せるものを提供しています。
DNSトンネリングを検出するレシピ
例として、Machine Learningを利用してDNSトンネリングを発見する方法を見てみましょう。
まず前提として、DNSトンネリングとは、ドメイン・ネーム・サービス(DNS)のインターネットプロトコルを使って本来DNSに含まれないデータを組織のネットワークに入れる、または抜き出そうとする行為のことを言います。インターネットに接続されているITインフラ全体の要求から、DNSネットワークトラフィックは基本的にファイアウォールでブロックされておらず、このため組織のセキュリティを掻い潜った不正な、悪意のある通信に使用されやすいチャネルになってしまっています。たとえば FrameworkPOSマルウェア はこのテクニックを使って、小売店のPOS端末から盗んだカードの所有者情報を抜き出しています。
それでは、ElasticのセキュリティサークルではDNS-EAB02として知られる、セキュリティ・ユースケースでの機械学習レシピについてご説明しましょう。"DNS"は、このレシピで解析するログの種類が"DNS"であることを表しています。"EAB"はこのレシピで基本的な攻撃挙動(Elementary Attack Behaviors)を検出することを表しています。"02"は他のDNSレシピと区別するための識別番号です。レシピには以下の通り複数のセクションが含まれています。
理論: DNS Query Requestのサブドメインフィールドに異常な数のエントロピー(情報量)がある場合、DNSプロトコルによるデータ抜き出しである可能性があります。
DNSデータ抜き出しを検出する方法は他にもあり、今回のジョブではその中の1つだけ使用しています。ちなみにこの手法は実際の企業環境で効果があると証明されたものです。他の手法を使ったり、手法を追加したりしたい場合はこのジョブをコピーしてお好みで書き換えていただけます。あるいは両方実行して結果を比べたり組み合わせたりしてもいいかもしれません。
説明: このユースケースレシピは、どのDNSクエリーリクエストが、異常に多くの情報が送られたか、どのIPアドレスで生成されたか明らかにします。
最初のうちは、フィールドのサブドメイン部分に異常な量のエントロピーが含まれるリクエストが送信されたドメインを特定するのが正しいやり方であるとは実感しにくいかもしれません。しかしデータのモデル化という観点から考えると、解析の過程で異常性を持つ確率が高いデータの特徴を特定する必要があります。今回の解析で私たちがモデル化したいのはDNSクエリログのドメインフィールドで、その特徴はサブドメインフィールドに含まれる情報量にあたります。
効果: このレシピはどのように自動的にDNSトンネリングを検出することができるか、例として提供されています。このほかにもより良い、もっと複雑な方法のレシピの方が、効果的な発見をもたらす可能性があります。
繰り返しになりますが、このレシピは単なる例です。ご自分のチームのノウハウを適用することで、より有効性を向上させることができるかもしれません。
ユースケースのタイプ: 基本的な攻撃挙動(EAB) - このユースケースでは基本的な攻撃挙動と関係する異常を検知します。検出された異常にはそれぞれ標準化されたAnomaly Score (異常度点数)が割り当てられ、異常に対して統計的な影響を与えるデータ内の別フィールドの値で注釈付けされます。共通のインフルエンサーを持つ基本的な攻撃挙動は往々にして共通の攻撃と関連しています。
このレシピはリスク因子のメタ解析を行っているわけではなく、サイバー攻撃を検出するため、X-Packのアラート機能を使って他の攻撃挙動に関連付けられる基本的な攻撃挙動を検出するものです。
ユースケースデータソース: DNSクエリログ(クライアントからDNSサーバー)
A reminder of what kind of data we'll need for this recipe
ユースケースレシピ:
For (対象): DNSクエリーリクエスト (filtered for question types: A, AAAA, TXT)
Model (モデル):サブドメイン文字列内の情報量
Detect (検出):異常に多い情報量
Compared to (比較対象)::登録されたドメインに対するクエリ結果の集団
Partition by (分割): None
Exclude (除外):解析で頻発するドメイン
Duration (期間):DNSクエリに対して、2週間以上の分析を実行する
Reated recipes (関連レシピ):このEABユースケースのみで実行、またはDNS-EAB01 DNS DGA Activityと一緒に実行
Results (結果):インフルエンサー・ホストはDNSトンネリングの活動元である可能性が高い
レシピを分かりやすい言葉で言い換えましょう。このセクションでは、データを引っ張ってくる元となるログメッセージ、モデル化するデータの特性、検出しようとしている異常な挙動、それが何と比較して異常なのか、この解析を区分化したいのか、結果を占有する可能性がある頻出値は除外するのか、適切な結果を生成するのに必要なデータ量はどれくらいか、このジョブと組み合わせたほうがいいジョブはあるのか、そして解析結果のどの部分を見てどのように解釈するのか、を指定しています。
Additional configuration parameters:
これらのセクション(Example Elasticsearch Index Patterns, Example Elasticsearch Query, and Machine Learning Analysis / Detector Config)は、Machine Learningジョブが意図した動きをするよう設定する、詳細技術設定になります。これらの詳細項目は、ジョブ設定ビューの設定に直結しています。
Machine Learninのジョブ設定が終われば、随時インデックスされるクライアントから行われるDNSリクエストログに対して分析を行なって通常の性質から正常なベースラインを作成し、異なった特徴を見つけることができます。
先に言及したように、発見した以上はElasticsearchのインデックスに記録されています。初期値では、ml-anomalies-*という名前で、KIbanaのDashboardで検索したり、Machine Learninのプラグインで探索したり、Alertingによって通知を行うことができます。
X-PackのMachine Learningが実際に動く様子をお見せする短い動画をいくつかご用意していますが、ここにも、V5.4 (ベータ版)のX-PackのMachine LearningのAnomaly ExplorerでDNSトンネリングジョブの結果を表示している画面イメージを載せておきます。
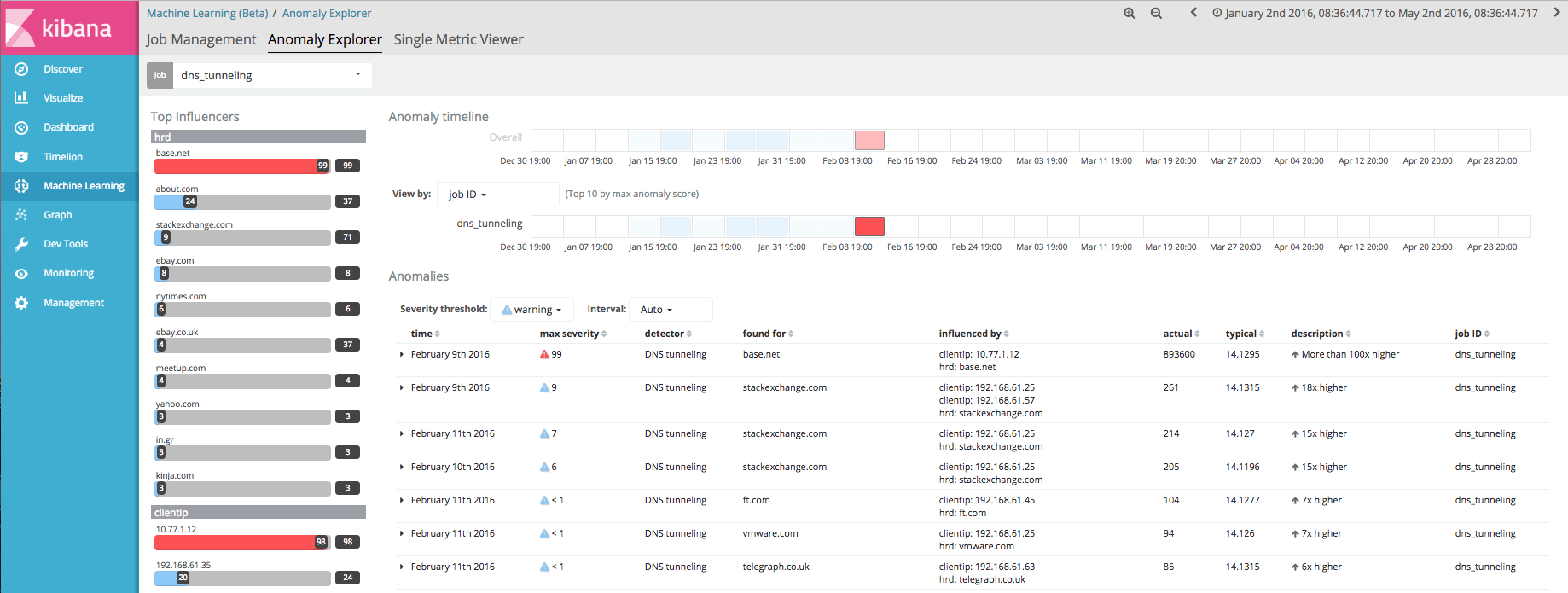
まとめ
X-PackのMachine Learningにより、Elasticsearch内にセキュリティ関連のログデータを持っているセキュリティアナリストやエンジニアも機械学習技術にアクセスできるようになります。X-PackのMachine Learningの基本要素は、異常検知ジョブです。セキュリティ解析のユースケースのレシピは、攻撃挙動を検知するジョブの設定方法を表してくれます。プログラミング無しでも、補助的なアルゴリズムの軍隊を率いるリーダーとなって脅威を検出し、セキュリティを強化することができるのです。