サイバーセキュリティと機械学習 ― ネットワークデータ中のDGAアクティビティを検知する
このブログシリーズのパート1では、Elastic Stackの機械学習を使った教師あり学習モデルを構築し、悪意のあるドメインを検知する方法をご紹介しました。パート2となる今回は、教育済みのモデルを使い、インジェスト時に分類を行ってネットワークデータをエンリッチする方法を解説します。この方法は、Packetbeatデータに潜在するDGAアクティビティを検知するのに役立ちます。
Elastic Stackを使ったDGA検知
マシンに侵入した悪意あるプログラムの多くは、攻撃者が制御するサーバー(一般に、コマンド&コントロール、C&CまたはC2サーバーと呼ばれます)との通信を必要とします。この際、ハードコーティングされたIPアドレスやURLをブロックするタイプの防衛策を回避する目的で使われている手口が、DGA(ドメイン生成アルゴリズム)です。C&Cサーバーと通信する必要があるとき、マルウェアはDGAを使って数百、数千ものドメイン候補を生成し、各IPアドレスの解決を試みます。攻撃者は次に、DGAが生成した1つ、または少数のドメインを登録し、感染させたマシンと通信できるようにしなければなりません。DGAは多数存在しますが、防御側によって容易にブロック・検知されないよう、それぞれ独自の方法でシード値を設定し、ランダム化しています。
DGAのアクティビティには通常、DNSクエリが含まれます。しばしば、このDNSクエリは感染したマシンで行われるDNSリクエスト内に現れます。Packetbeatを使えばDNSトラフィックを収集し、分析のためにElasticsearchに送ることができます。今回は、ドメインの悪意度を示すスコアを使い、Packetbeatデータに含まれるDNSクエリ情報をエンリッチする方法を解説します。

推論プロセッサーとインジェストパイプライン
悪意と善意のドメインを区別する教育済みモデルの予測に基づいてPacketbeatデータをエンリッチするには、適切な推論プロセッサーを用いてインジェストパイプラインを設定する必要があります。推論プロセッサーを使うと、新規のドキュメントをElasticsearchにインジェストする際、Elastic Stackで教育されたモデル(および、サポートされる外部ライブラリで教育されモデル)で予測を行うことができます。各ピースをどう組み合わせ、どのように設定すべきか理解するために、前回の内容を簡単に振り返ってみましょう。
ブログシリーズのパート1では、所与のドメインの悪意の有無を予測する分類モデルを教育するプロセスを説明しました。このプロセスに登場した手順の1つに、教育用データで特徴エンジニアリングを実施するというものがありました。(教育用データは既知の悪意のあるドメインと無害なドメインからなるセットで、モデルが新しい、初見のドメインをスコアリングする方法を学習するために使用します。)モデルに有用なユニグラム、バイグラム、トライグラムの形式で生のドメインから特徴を抽出するために、その処理が必要だったということです。つまり、Packetbeatデータに含まれるドメインを悪意度でスコア付けするには、そのドメインに特徴エンジニアリングと同じ手順を適用する必要があります。
それが、今回のインジェストパイプラインに推定プロセッサーだけでなく、painless scriptプロセッサーが使われている理由です。この2つを備えたインジェストパイプラインで、Packetbeat DNSデータからユニグラム、バイグラム、トライグラムをインジェストと同時に抽出してゆきます。図2は、パイプライン全体の見取り図を示しています。
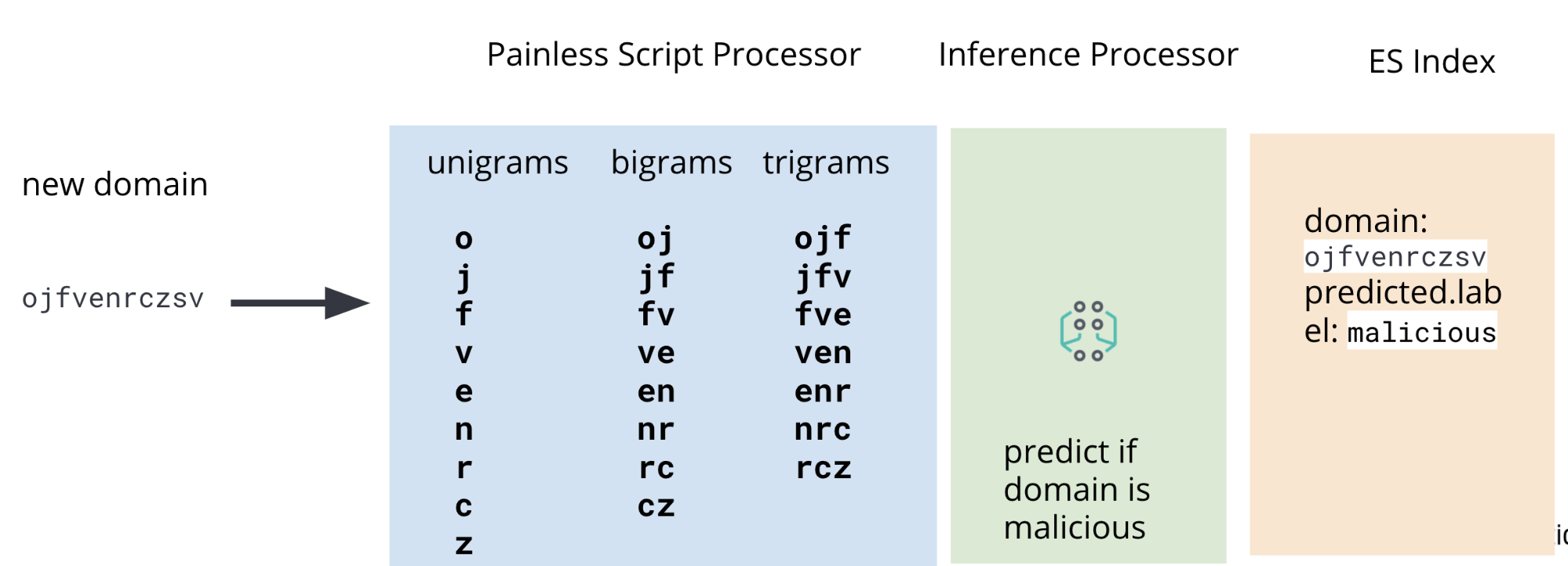
Packetbeatデータの中で、今回作業対象となるフィールドは、DNS登録ドメインです。このフィールドに目的のドメインが含まれないというエッジケースもないわけではありませんが、ブログでユースケースを実演する目的では十分です。図3の画像は、サンプルのPacketbeatドキュメント内で、作業対象となるフィールドを示しています。
 登録ドメイン
登録ドメイン
dns.question.registered_domainが対象のPacketbeatフィールドとなるフィールドdns.question.registered_domainからユニグラム、バイグラム、トライグラムを抽出するには、図4のようなPainless scriptが必要となります。
POST _scripts/ngram-extractor-packetbeat
{
"script": {
"lang": "painless",
"source": """
String nGramAtPosition(String fulldomain, int fieldcount, int n){
String domain = fulldomain.splitOnToken('.')[0];
if (fieldcount+n>=domain.length()){
return ''
}
else
{
return domain.substring(fieldcount, fieldcount+n)
}
}
for (int i=0;i<ctx['dns']['question']['registered_domain'].length();i++){
ctx['field_'+Integer.toString(params.ngram_count)+'_gram_'+Integer.toString(i)] = nGramAtPosition(ctx['dns']['question']['registered_domain'], i, params.ngram_count)
}
"""
}
}
インジェストパイプラインを通過するドキュメントは最初に特徴を抽出する工程を通り、次に推論プロセッサーに向かいます。推論プロセッサー内では、前回の記事で特徴を抽出するために教育した分類モデルを使った予測が行われます。最後に、インデックス内にモデルにとって必要のない特徴が散乱することのないよう、Painless scriptプロセッサーを追加します。この一連のプロセッサーで、ユニグラム、バイグラム、トライグラムを含むフィールドを削除します。
つまり、このインジェストパイプラインを通過させることで、インジェストに用いるPacketbeatドキュメントに新しいフィールドが追加され、そのフィールドに機械学習による予測結果が入っているという状態になります。インジェストパイプラインの設定例を、図5に示します。設定の詳細は、事例レポジトリをご参照ください。
PUT _ingest/pipeline/dga_ngram_expansion_inference
{
"description":"Expands a domain into unigrams, bigrams and trigrams and make a prediction of maliciousness",
"processors": [
{
"script": {
"id": "ngram-extractor-packetbeat",
"params":{
"ngram_count":1
}
}
},
{
"script": {
"id": "ngram-extractor-packetbeat",
"params":{
"ngram_count":2
}
}
},
{
"script": {
"id": "ngram-extractor-packetbeat",
"params": {
"ngram_count":3
}
}
},
{
"inference": {
"model_id": "dga-ngram-job-1587729368929",
"target_field": "predicted_label",
"field_mappings":{},
"inference_config": { "classification": {"num_top_classes":2} }
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params":{
"ngram_count":1
}
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params":{
"ngram_count":2
}
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params": {
"ngram_count":3
}
}
}
]
}
すべてのPacketbeatにDNSリクエストが記録されているとは限らないことから、インジェストパイプラインは条件的に実行する必要があります。すなわち、インジェストされたドキュメントに対象のDNSフィールドが存在し、かつ非空である場合に限る、という条件で実行します。これは、パイプラインプロセッサー(図6の設定参照)を使って、目的のフィールドが存在し、かつポピュレートされていることを確認した後、ドキュメントの処理を図5で定義したdga_ngram_expansion_inferenceパイプラインにリダイレクトすることで実行できます。以下に示す設定はプロトタイプとしては十分ですが、ユースケースで運用する場合には、インジェストパイプライン内のエラー処理も考慮する必要があります。詳細な設定と説明は、事例のレポジトリをご覧ください。
PUT _ingest/pipeline/dns_classification_pipeline
{
"description":"A pipeline of pipelines for performing DGA detection",
"version":1,
"processors": [
{
"pipeline": {
"if": "ctx.containsKey('dns') && ctx['dns'].containsKey('question') && ctx['dns']['question'].containsKey('registered_domain') && !ctx['dns']['question']['registered_domain'].empty",
"name": "dga_ngram_expansion_inference"
}
}
]
}
異常検知を推論結果の二次分析として活用する
さて、ブログシリーズのパート1で教育したモデルの偽陽性率は2%でした。一見すると低い数字のようですが、通常、DNSトラフィックは大量のデータであることを考慮しなければなりません。つまり、わずか2%の偽陽性率でも、非常に多くのクエリに“悪意がある”というスコアが付く可能性があります。偽陽性の数を減らす手法の1つに、特徴エンジニアリングスキームをさらに工夫するやり方があります。もう1つ、分類結果に異常検知を用いるという手法もあります。この記事では、後者をElastic Stackで実行する方法を実演してみたいと思います。
まずはじめに、エンリッチ済みのPacketbeatドキュメントを用いて、悪意があると分類されたPacketbeatドキュメントの数を時間経過に応じてプロッティングすると、時系列データ(図7)が得られるかを確認します。
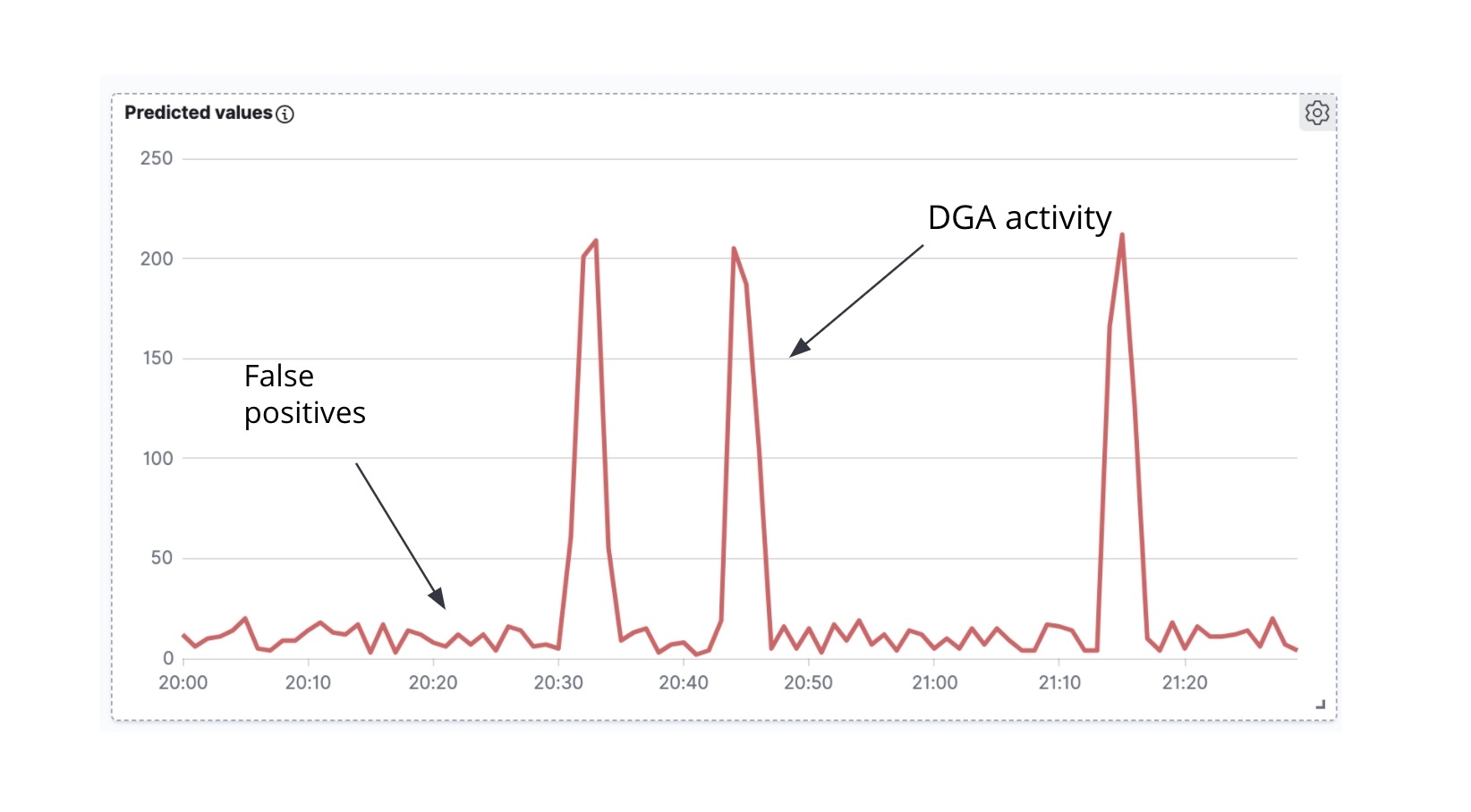
次に重要な点は、DGAのマルウェアがC&Cサーバーへの通信を活発に試みると、一度に大量のDNSリクエストが起きたことを示す“波”がしばしば生じる(例外もありますが)ということです(マルウェアがアルゴリズムで生成した多数のドメインを順繰りに使用し、各ドメインのIPアドレスの解決を試みるため)。悪意があると予測されたドメインが時間とともにどう変化するかを示した時系列分析(図6)には、アクティビティの複数のピークが確認できるほか、ピークとピークの間に小さなノイズが生じていることもわかります。ピークは、モデルによって短時間に多数のドメインが“悪意あり”と分類されたことを示すものであり、真のDGAである可能性が高いと考えられます。逆に、ピーク間のバックグラウンドノイズは偽陽性の可能性が高いということになります。この洞察に基づき、先ほどの時系列データをhigh_count異常検知ジョブにエンコードすることを検討してみましょう。
異常検知のスイムレーンを図7の時系列プロッティングに重ねると、異常検知アラートの発生状況と時系列のピーク(真のDGAアクティビティ)が一致することがわかります。さらに、ピークとピークの間(偽陽性のバックグランドノイズ)では、アラートが生じていないこともわかります。
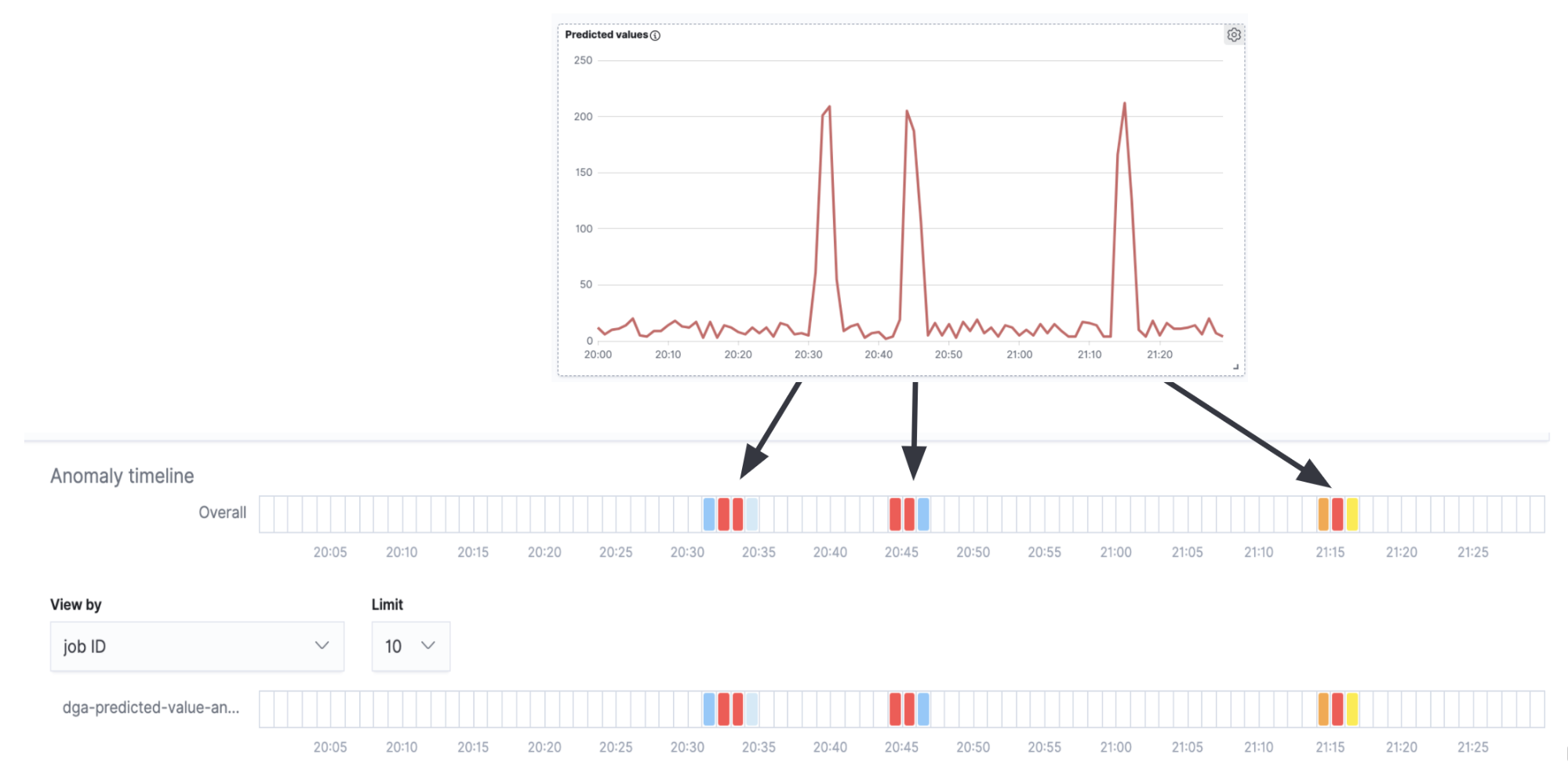
今回は非常にシンプルな例を取り上げています。本番環境のユースケースにはさらに細かな微調整や設定が必要となると考えられますが、総体として、推論結果の二次分析に異常検知ジョブが効果的であると示すことができました。
まとめ
この記事では、教育済みの分類モデルを使って、インジェスト時にネットワークデータ(Packetbeatドキュメント)をエンリッチする方法を紹介しました。エンリッチのプロセスでは推論プロセッサーとインジェストパイプラインを使用し、DNSリクエストでクエリされた各ドメインに予測結果のラベルを追加しました。その分類のラベルが、ドメインの悪意度を示します。記事の後半では、偽陽性のアラートを削減する目的で、推論結果に異常検知ジョブを使用する方法を検討しました。Elasticでは今後、Elastic SIEMからDGA検知用にキュレーション済みの設定と各種モデルをリリースする計画を進めています。
ご紹介した方法を実際のネットワークデータを使って、ご自身で試してみたいという場合は、14日間のElasticsearch Service無料トライアルがおすすめです。インジェストから分析まで、すべての機能をお試しいただくことができます。また、ローカルにElastic Stackをダウンロードしてトライアルライセンスを適用し、30日間機械学習を無料でお試しいただくこともできます。併せて、無料かつオープンなElastic SIEMもぜひどうぞ。組織のデータ保護をすぐに開始できます。