Elasticsearch Serviceでコストを節約:データストレージの効率化戦略
Elastic CloudのオフィシャルなElasticsearch Service(ESS)を基盤に、Elasticsearchだけでなく、Elastic LogsやElastic APM、Elastic SIEMなど他にないプロダクトを実行したい、というお問い合わせを多数いただいています。この場をお借りして、心よりお礼申し上げます。7年にわたる運用ノウハウが活かされているESSは、完全なElasticsearchエクスペリエンスと、すべての機能、ソリューション、開発元によるサポートを備えた唯一のマネージドサービスです。プロダクト本体のすぐれた仕様に加えて、運用やデプロイに多くのメリットがあることが特長です。
前回の記事で、サービスやインフラ、ロギングデバイスと、使用するSaaSソリューションのリージョンが同一でない場合、隠れたネットワークコストが莫大になる問題について解説しました。今回の記事では、ワークロードの増大に伴うコストを管理する上で、多様な戦略を選択できるElastic CloudのElasticsearch Serviceの柔軟性についてお伝えします。
成長を伴うあらゆるケースに言えることですが、特にオブザーバビリティとセキュリティ分野では、アプリから生成されるログやメトリック、APMトレース、セキュリティイベントの増大に伴い、それを格納、分析するインフラの費用も増えることになります。ESSには、有意義なデータをより長い期間保持しながら、費用をコントロールするためのデータ管理手法が複数用意されています。同時に、多様なソースから来るデータの統合や可視化のオプション、アラート、異常検知をはじめ、Elastic Stackの便利な機能もすべて提供されます。
本記事では、オブザーバビリティやセキュリティのユースケースなど、時系列データで効果的にコストを削減する方法を取り上げます。はじめに、Elastic Stackをインフラ監視に活用するユーザーの間で最も一般的なアプリケーションを1つ紹介しましょう。Elastic Stackを構成するプロダクトの1つであるBeatsは、クライアント側で動作し、データをクラスターにシッピングする軽量なエージェント群です。Metricbeatは、CPU使用量やディスクIOPSなどのシステムメトリックのほか、Kubernetesで実行するアプリのコンテナーテレメトリの送信に使われています。
アプリのフットプリントが増大すると、生成されたメトリックを格納する監視用のストレージにもより大きな容量が必要になります。そこで、時系列データを大規模に管理するために現在多くの現場で採用されているのが、保持期間を定義するという戦略です。この戦略と併せてESSで利用でき、追加の設定を行うことなく使えるストレージ効率オプションについて詳しく見てゆきます。
シナリオ
1,000台のホストでそれぞれ、エージェントが1メトリックあたり100バイト、10秒あたり100メトリックを収集しており、データ保持期間が30日という監視クラスターがあるとします。このクラスターについて、持続性の観点から、費用を削減する戦略を考えてみましょう。また、高可用に保つ目的で、このクラスターには複製データも格納することとします。複製データを持つことで、あるノードがフェイルした場合にデータロスを回避することができます。まず、必要なストレージ容量を計算します。
|
|
計算の結果、上述のメトリックを格納するストレージの要件は、5.2TBになることがわかりました。現実のシナリオでは、Elasticsearchクラスターの運用にもストレージ容量が必要ですが、複雑化を避けるために今回はその点を考慮しないこととします。
もう一度条件を整理すると:
| 監視するホスト数 | 1,000 |
| 1日あたりの投入量(GB) | 86.4GB |
| 保持期間 | 30日 |
| 複製の数 | 1 |
| ストレージ要件(複製データを含む) | 5.184TB |
Hot-Warmデプロイとインデックスライフサイクル管理を使ったストレージ効率化
ロギングやメトリックといったオブザーバビリティのユースケースでは、時間が経つにつれてデータの有用性が下がります。たとえば、システムインシデントやネットワークトラフィックの予想外のスパイク、セキュリティアラートなどを速やかに調査しようというとき、活用されるのは最近のデータです。データは古くなるほどクエリされる頻度が低くなるのに、同じクラスターに存在し続け、他のクラスターと同じ演算やメモリ、ストレージ用のリソースを使い続けることになります。この結果、まったく異なる2つのデータアクセスパターンが生じ、クラスターは高速な投入と高頻度のクエリに最適化された設定のまま、という状態になります。アクセス頻度が低いデータのストレージとしては最適化されていません。
ここでElasticsearch ServiceのHot-Warmアーキテクチャーの出番です。このデプロイオプションは、同じElasticsearchクラスターに2つのハードウェアプロファイルを提供します。Hotノードは新規に投入されるデータを扱い、高速ストレージを用いてデータをすばやく投入、取得します。Warmノードはストレージを高密度で使用し、データを長期に保存する際のコスト効率に優れています。
Elasticsearch Serviceは一般的に、Hotノードにはローカルに接続されたNVMe SSDsを1対30のRAM対ディスク比で、Warmノードには高密度HDDを1:160のRAM対ディスク比でプロビジョニングします。このパワフルなアーキテクチャーは、もう1つの重要な機能、インデックスライフサイクル管理(ILM)を併用して構成されています。ILMは、時間経過に伴うインデックス管理を自動化する手段です。インデックスサイズやドキュメント数、インデックスの時間経過など、一定の基準に基づいて、HotノードからWarmノードへのデータ移行をシンプル化します。
連携する2つの機能により、クラスター内に2つの異なるハードウェアプロファイルと、2つのティア間でデータを移動させるインデックス自動化ツールを持たせることができます。
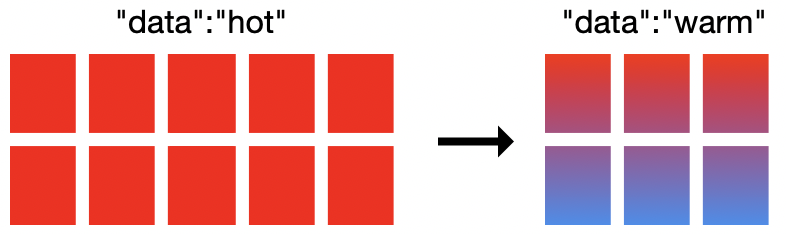
実際に、Hot-Warmデプロイに移行し、ILMポリシーを設定してみましょう。ESSで新規のHot-Warmデプロイを作成する場合、オプションとして、別のクラスターのスナップショットを使って復元することもできます。すでに高I/Oで作成したデプロイがある場合は、クラスターにWarmノードを追加して、シンプルにHot-Warmデプロイに移行することができます。ILMポリシーを使って、データを7日間Hotノードに置き、その後はWarmノードに移行するよう設定できます。
このポリシーの下、データを移行するWarmフェーズでは、インデックスの書き込みは行われません。さらに、コスト節約のため、Warmノードには複製データを格納しないという選択肢も生まれます。Warmノードで障害が発生した場合、複製データからではなく、最新のスナップショットから復元することになります。
このアプローチのデメリットとして、スナップショットからの復元は一般的に低速で、障害発生後の復旧にかかる時間が長くなる点があります。しかし、一般的にWarmノードは低頻度でクエリされるデータしか持たず、実際の影響が大きくなることはありません。したがって、このデメリットは多くのケースで許容できる可能性があります。
最後に、シナリオの保持ポリシーに沿って、期間が30日に達したデータを削除します。先ほどのように計算式を使って、このアプローチを概算してみましょう。
| 従来型のクラスター | Hot-Warm+ILM | |
| 監視するホスト数 | 1,000 | 1,000 |
| 1日あたりの投入量(GB) | 86.4GB | 86.4GB |
| 保持期間 | 30日 |
Hot:7日
Warm:30日 |
| 必要な複製 | 1 |
Hotノード:1
Warmノード:0 |
| ストレージ要件: | 5.184TB |
Hot:1.2096TB(複製含む)
Warm:1.9872TB(複製なし) |
| 必要なクラスターサイズの概算値 | 232GB RAM(6.8TB SSDストレージ) |
Hot:58GB RAM、SSD
Warm:15GB RAM、HDD |
| 月々のクラスター費用 | 3,772.01米国ドル | 1,491.05米国ドル |
このアプローチは、スケーラブルかつ回復力のある形でデータを保持しつつ、1か月あたりのコストを約60%と、著しく削減する結果になっています。実際のシナリオではILMポリシーを細かに調整して最適なロールオーバー期間を探り、Warmノードのストレージを最大に活用することもできます。
データのロールアップでストレージ容量をさらに空ける
ストレージを節約する上で、もう1つ検討したいオプションがデータのロールアップです。ロールアップAPIは、Elasticsearch内の1つのサマリードキュメントにデータを"ロールアップ"することでデータを要約し、データをよりコンパクトに格納します。その後、オリジナルデータをアーカイブしたり、削除したりしてストレージ容量を空けることが可能です。
ロールアップを作成する際は、将来分析に使う可能性のあるフィールドをすべて選択しておきます。生成される新しいインデックスは、選択した(ロールアップ済みの)データのみ保持します。この手法は、監視のユースケースで特に有用です。扱うのは主に数値データであり、分や時間単位、場合によっては1日の単位で簡単にデータ粒度を上げ、要約できます。要約後のデータでも、時間経過に伴う傾向を確認することが可能です。要約済みのインデックスはKibana全体で扱うことができ、既存のダッシュボードに簡単に追加できます。この方法なら、分析作業中にデータ破損が生じるといった事態も回避できます。この設定はすべて、Kibanaで直接行うことができます。
引き続き冒頭のシナリオで考えてみましょう。1,000台のホストからくるメトリックデータを、高可用性のための複製とともに、30日間格納する場合に必要なストレージ容量は5.2TBでした。そこで先ほどは、Hot-Warmデプロイテンプレートを使ったシナリオを検討しました。今度は、データロールアップAPIを使ってロールアップジョブを実行し、データが7日間を経過したら少し粒度を上げて、ストレージ容量を節約するパターンを検討してみます。
10秒のメトリックデータをロールアップして、1時間単位で要約したドキュメントを作成するようにデータロールアップジョブを設定します。古いメトリックを1時間間隔でクエリ、および可視化することができるので、Kibanaの可視化やLensでデータの傾向を示したり、重要な瞬間を確認することができます。次に、ロールアップしたオリジナルのドキュメントを削除して、クラスターのストレージにまとまった空き容量を作ります。ここで、ロールアップ済みのデータに必要なストレージサイズを計算してみましょう。
|
|
ロールアップの対象となるのは7日目以降のデータで、先ほどのシナリオではHot-Warmクラスター内のWarmノードに格納されていました。Warmノードの1.99TBのデータは、削除します。表の一番右の列が、今回のシナリオの結果です。
| 従来型のクラスター | Hot-Warm+ILM | Hot-Warm+ILM、データロールアップを併用 | |
| 監視するホスト数 | 1,000 | 1,000 | 1,000 |
| 1日あたりの投入量(GB) | 86.4GB | 86.4GB | 86.4GB |
| 保持期間 | 30日 |
Hot:7日
Warm:30日 |
Hot:7日
Warm:30日 |
| データ粒度 | 10秒 | 10秒 |
最初の7日間:10秒
8日目以降:1時間 |
| 必要な複製 | 1 |
Hotノード:1
Warmノード:0 |
Hotノード:1
Warmノード:0 |
| ストレージ要件: | 5.184TB |
Hot:1.2096TB(複製含む)
Warm:1.9872TB(複製なし) |
Hot:1.2096TB(複製含む)
Warm:5.52GB(複製なし、ロールアップ済みデータ) |
| 必要なクラスターサイズの概算値 | 232GB RAM(6.8TB SSDストレージ) |
Hot:58GB RAM、SSD
Warm:15GB RAM、HDD |
Hot:58GB RAM、SSD
Warm:2GB RAM、HDD |
| 月々のクラスター費用 | 3,772.01米国ドル | 1,491.05米国ドル | 1,024.92米国ドル |
劇的にコストを削減する結果となりました。既存のHot-Warmクラスターでデータロールアップを併用し、31%のコストを節減するという試算です。ハードウェアティアが1つしかない最初のシナリオと最後のシナリオで比べると、73%もの節約になっています。
自由にデプロイ
どんな手法にも、メリットとデメリットが存在します。しかしElasticのプロダクトはフレキシブルです。ユーザーは戦略を微調整して、各自のニーズに最適にフィットさせることができます。
ILMポリシーを使うと、インデックスサイズやドキュメント数、ドキュメントの経過時間に基づいてロールオーバー期間を定義し、Hot-Warmクラスター内のWarmノードにデータを移動させることができます。Warmノードは大容量のストレージを効率的に使用し、演算コストを節約します。Hotノードに比べてクエリ時間のパフォーマンスは落ちますが、クエリされる頻度が低いデータには好ましいアプローチです。
データのロールアップは、データを粒度の粗いドキュメントに要約する手法です。データが古くなり、オリジナルのデータほど低い粒度で保持する必要がなくなった場合に有効です。ロールアップが済んだソースドキュメントは削除でき、ストレージコストの節約に役立ちます。また、ドキュメントを要約する粒度や、タイミングをユーザーが定義できる点もメリットです。ロールアップ済みのデータからも、時間経過に伴う傾向や、トラフィックのスパイクによるシステムの挙動など、主要なインサイトを得られるように、最適なバランスを追及することができます。
ここまで読んでくださった方は、Elasticsearchクラスターのメトリックワークロードを最適化するにあたり、簡単に実行できる複数の戦略をマスターしたことになります。ところで、空いたストレージ容量は何に使うとよいでしょうか?Elastic Stackは、ログやAPMトレース、監査イベント、エンドポイントデータなど、無数のユースケースをサポートします。
Elastic CloudのElasticsearch Serviceは、Elastic Stackの全機能を、開発元による最適な運用サービスとセットで提供するサービスです。まだ新しいユースケースを導入する予定がないという場合は、引き続きストレージ最適化を活用してクラスターを使うことができます。コストはそのままで、データの保持期間を長期化させたり、格納するデータを増やしたりするのも1つの手です。あるいは、数クリックの簡単な操作で可視性はそのままに、クラスターサイズだけを引き下げて節約するという手もあります。
Elastic CloudのElasticsearch Serviceの導入をご検討中ですか?14日間の無料トライアルでお試しください。