

 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
Les moteurs de recherche d'Elastic App Search vous permettent d'indexer des documents et fournissent des capacités de recherche ajustables prêtes à l'emploi. Par défaut, les moteurs sont compatibles avec une liste de langues prédéfinie. Si votre langue ne se trouve pas dans la liste, cet article de blog vous explique comment vous pouvez en ajouter d'autres. Pour cela, nous créerons un moteur de recherche App Search dont les analyseurs sont configurés pour cette langue.
Avant de nous plonger dans les détails, définissons ce qu'est un analyseur Elasticsearch :
Un analyseur Elasticsearch est un pack contenant trois éléments de bas niveau : des filtres de caractère, des générateurs de tokens et des filtres de tokens. Les analyseurs peuvent être intégrés ou personnalisés. Les analyseurs intégrés empaquettent les éléments en analyseurs compatibles pour différentes langues et différents types de textes.
Les analyseurs de chaque champ servent à :
- Indexer. Chaque champ de documents sera traité avec son analyseur correspondant et décomposé en tokens pour faciliter la recherche.
- Rechercher. La requête de recherche sera analysée pour garantir une correspondance adéquate avec les champs indexés ayant déjà été analysés.
Les moteurs Elasticsearch basés sur l'index vous permettent de créer des moteurs de recherche App Search à partir d'index Elasticsearch existants. Nous créerons un index Elasticsearch avec nos propres analyseurs et mappings et l'utiliserons dans App Search.
Ce processus comporte quatre étapes :
1. Créer un index Elasticsearch et indexer des documents
Pour commencer, prenons un index n'ayant encore été optimisé pour aucune langue. Supposons qu'il s'agit d'un nouvel index sans mapping prédéfini, et qu'il est créé lorsque des documents sont indexés pour la première fois.
Dans Elasticsearch, le mapping est le processus qui définit la façon dont un document et les champs qu'il contient sont stockés et indexés. Chaque document est une compilation de champs, ayant chacun son propre type de données. Lorsque vous mappez vos données, vous créez une définition de mapping, qui contient une liste de champs en rapport avec le document.
Revenons-en à notre exemple. Cet index est appelé books, et le titre (title) est en roumain. Nous avons choisi le roumain, car il s'agit de ma langue et qu'elle n'est pas incluse dans la liste de langues avec lesquelles App Search est compatible par défaut.
POST books/_doc/1
{
"title": "Un veac de singurătate",
"author": "Gabriel García Márquez"
}
POST books/_doc/2
{
"title": "Dragoste în vremea holerei",
"author": "Gabriel García Márquez"
}
POST books/_doc/3
{
"title": "Obosit de viaţă, obosit de moarte",
"author": "Mo Yan"
}
POST books/_doc/4
{
"title": "Maestrul și Margareta",
"author": "Mihail Bulgakov"
}2. Ajouter des analyseurs linguistiques à l'index livres
Lorsque nous examinons le mapping d'index books, nous pouvons voir qu'il n'est pas optimisé pour le roumain. On le sait, car il n'y a pas de champ analysis dans le bloc settings, et que les champs de texte n'utilisent pas d'analyseur personnalisé.
GET books
{
"books": {
"aliases": {},
"mappings": {
"properties": {
"author": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "books",
"creation_date": "1679310576178",
"number_of_replicas": "1",
"uuid": "0KuiDk8iSZ-YHVQGg3B0iw",
"version": {
"created": "8080099"
}
}
}
}
}Si nous essayons de créer un moteur de recherche App Search avec l'index books, nous rencontrerons deux problèmes. Premièrement, les résultats de recherche ne seront pas optimisés pour le roumain, et ensuite, les fonctionnalités telles que le Réglage de la précisionseront désactivées.
Précision concernant les différents types de moteurs de recherche Elastic App Search :
- L'option par défaut est un moteur de recherche App Search géré, qui créera et gérera automatiquement un index Elasticsearch masqué. Avec cette option, vous devez utiliser l'API de documents App Search pour ingérer les données dans votre moteur.
- Avec l'autre option, App Search crée un moteur avec un index Elasticsearch existant, dans ce cas, App Search utilisera l'index tel quel. Ici, vous pouvez ingérer les données directement dans l'index sous-jacent en utilisant l'API de documents d'index Elasticsearch.
[Article associé : Api Search d'Elasticsearch : une nouvelle manière de localiser des documents App Search]
Lorsque vous créez un moteur à partir d'un index Elasticsearch existant, si les mappings ne suivent pas les conventions App Search, les fonctionnalités ne seront pas toutes activées pour ce moteur. Regardons de plus près les conventions de mapping App Search en examinant un moteur entièrement géré par App Search. Ce moteur contient deux champs, title et author, et utilise la langue anglaise.
GET .ent-search-engine-documents-app-search-books/_mapping/field/title
{
".ent-search-engine-documents-app-search-books": {
"mappings": {
"title": {
"full_name": "title",
"mapping": {
"title": {
"type": "text",
"fields": {
"date": {
"type": "date",
"format": "strict_date_time||strict_date",
"ignore_malformed": true
},
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"float": {
"type": "double",
"ignore_malformed": true
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"location": {
"type": "geo_point",
"ignore_malformed": true,
"ignore_z_value": false
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
},
"index_options": "freqs",
"analyzer": "iq_text_base"
}
}
}
}
}
}Vous verrez que le champ title possède plusieurs sous-champs. Les sous-champs date, float et location ne sont pas des champs de texte.
Nous nous intéressons ici à comment définir les champs de texte requis par App Search. Il y a beaucoup de champs ! Cette page de documentation explique les champs de texte utilisés dans App Search. Jetons un œil aux analyseurs qu'App Search a définis pour un index masqué appartenant à un moteur App Search géré :
GET .ent-search-engine-documents-app-search-books/_settings/index.analysis*
{
".ent-search-engine-documents-app-search-books": {
"settings": {
"index": {
"analysis": {
"filter": {
"front_ngram": {
"type": "edge_ngram",
"min_gram": "1",
"max_gram": "12"
},
"bigram_joiner": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "false",
"type": "shingle"
},
"bigram_max_size": {
"type": "length",
"max": "16",
"min": "0"
},
"en-stem-filter": {
"name": "light_english",
"type": "stemmer"
},
"bigram_joiner_unigrams": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "true",
"type": "shingle"
},
"delimiter": {
"split_on_numerics": "true",
"generate_word_parts": "true",
"preserve_original": "false",
"catenate_words": "true",
"generate_number_parts": "true",
"catenate_all": "true",
"split_on_case_change": "true",
"type": "word_delimiter_graph",
"catenate_numbers": "true",
"stem_english_possessive": "true"
},
"en-stop-words-filter": {
"type": "stop",
"stopwords": "_english_"
}
},
"analyzer": {
"i_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"front_ngram"
],
"tokenizer": "standard"
},
"iq_text_delimiter": {
"filter": [
"delimiter",
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter",
"en-stem-filter"
],
"tokenizer": "whitespace"
},
"q_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding"
],
"tokenizer": "standard"
},
"iq_text_base": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter"
],
"tokenizer": "standard"
},
"iq_text_stem": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter",
"en-stem-filter"
],
"tokenizer": "standard"
},
"i_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stem-filter",
"bigram_joiner",
"bigram_max_size"
],
"tokenizer": "standard"
},
"q_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stem-filter",
"bigram_joiner_unigrams",
"bigram_max_size"
],
"tokenizer": "standard"
}
}
}
}
}
}
}Si nous souhaitons créer un index que nous pouvons utiliser dans App Search, pour une langue différente (par exemple le norvégien, le finnois ou l'arabe), nous aurions besoin d'analyseurs similaires. Pour notre exemple, nous devons nous assurer que les filtres de racinisation et de mots non significatifs utilisent la version roumaine.
Pour en revenir à notre index books initial, ajoutons les bons analyseurs.
Petite mise en garde. Pour les index existants, les analyseurs sont un type de paramètre Elasticsearch qui ne peut être modifié que lorsqu'un index est fermé. Dans cette démarche, nous commençons avec un index existant et avons donc besoin de fermer l'index, d'ajouter des analyseurs, puis de rouvrir l'index.
Remarque : Vous pouvez également recréer l'index de A à Z avec les bons mappings, puis indexer ensuite tous les documents. Si cette solution convient mieux à votre cas d'utilisation, n'hésitez pas à ignorer les sections de ce guide qui traitent de l'ouverture et de la fermeture de l'index, ainsi que de la réindexation.
Vous pouvez fermer l'index en exécutant POST books/_close. Après cela, nous ajouterons les analyseurs :
PUT books/_settings
{
"analysis": {
"filter": {
"front_ngram": {
"type": "edge_ngram",
"min_gram": "1",
"max_gram": "12"
},
"bigram_joiner": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "false",
"type": "shingle"
},
"bigram_max_size": {
"type": "length",
"max": "16",
"min": "0"
},
"ro-stem-filter": {
"name": "romanian",
"type": "stemmer"
},
"bigram_joiner_unigrams": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "true",
"type": "shingle"
},
"delimiter": {
"split_on_numerics": "true",
"generate_word_parts": "true",
"preserve_original": "false",
"catenate_words": "true",
"generate_number_parts": "true",
"catenate_all": "true",
"split_on_case_change": "true",
"type": "word_delimiter_graph",
"catenate_numbers": "true"
},
"ro-stop-words-filter": {
"type": "stop",
"stopwords": "_romanian_"
}
},
"analyzer": {
"i_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"front_ngram"
],
"tokenizer": "standard"
},
"iq_text_delimiter": {
"filter": [
"delimiter",
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter",
"ro-stem-filter"
],
"tokenizer": "whitespace"
},
"q_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding"
],
"tokenizer": "standard"
},
"iq_text_base": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter"
],
"tokenizer": "standard"
},
"iq_text_stem": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter",
"ro-stem-filter"
],
"tokenizer": "standard"
},
"i_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stem-filter",
"bigram_joiner",
"bigram_max_size"
],
"tokenizer": "standard"
},
"q_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stem-filter",
"bigram_joiner_unigrams",
"bigram_max_size"
],
"tokenizer": "standard"
}
}
}
}Vous pouvez voir que nous ajoutons le filtre ro-stem-filter pour laracinisation en roumain, ce qui améliorera la pertinence de la recherche pour les variations de mots spécifiques au roumain. Nous incluons le filtre de mots roumains non significatifs (ro-stop-words-filter) pour nous assurer que les mots roumains non significatifs ne seront pas pris en compte pour la recherche.
Nous allons maintenant rouvrir l'index en exécutant POST books/_open.
3. Mettre le mapping d'index à jour pour utiliser les analyseurs
Une fois les paramètres de l'analyse mis en place, nous pouvons modifier le mapping d'index. App Search utilise des modèles dynamiques pour garantir que les nouveaux champs possèdent les bons sous-champs et analyseurs. Pour notre exemple, nous ajouterons uniquement les sous-champs aux champs title et author existants :
PUT books/_mapping
{
"properties": {
"author": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
}
},
"title": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
}
}
}
}4. Réindexer les documents
L'index books est désormais presque prêt à être utilisé dans App Search !
Tout ce qui nous reste à faire est de nous assurer que les documents que nous avons indexés avant de modifier le mapping possèdent tous les bons sous-champs. Pour cela, nous pouvons exécuter une réindexation à la place à l'aide de update_by_query:
POST books/_update_by_query?refresh
{
"query": {
"match_all": {
}
}
}Puisque nous utilisons une requête match_all, tous les documents existants seront mis à jour.
Avec une requête de type Mettre à jour par recherche, nous pouvons également inclure un paramètre de script pour définir comment mettre les documents à jour.
Notez que nous ne modifions pas les documents, nous souhaitons cependant réindexer les documents existants tels quels pour garantir que les champs de texte author et title possèdent les mêmes sous-champs. En conséquence, nous n'avons pas besoin d'inclure de script dans notre requête Mettre à jour par recherche.
Nous avons désormais un index linguistique optimisé, que nous pouvons utiliser dans App Search avec les moteurs de recherche Elasticsearch ! Vous verrez les avantages en action dans les captures d'écran suivantes.
Nous utiliserons le titre de livre Cent Ans de solitude comme référence. Le titre traduit en roumain est Un veac de singurătate. Faites attention au mot veac, qui est le mot roumain pour « siècle ». Nous allons lancer une recherche avec la forme au pluriel deveac, qui est veacuri. Nous avons ingéré cet enregistrement de données dans les deux exemples que nous allons examiner :
{
"title": "Un veac de singurătate",
"author": "Gabriel García Márquez"
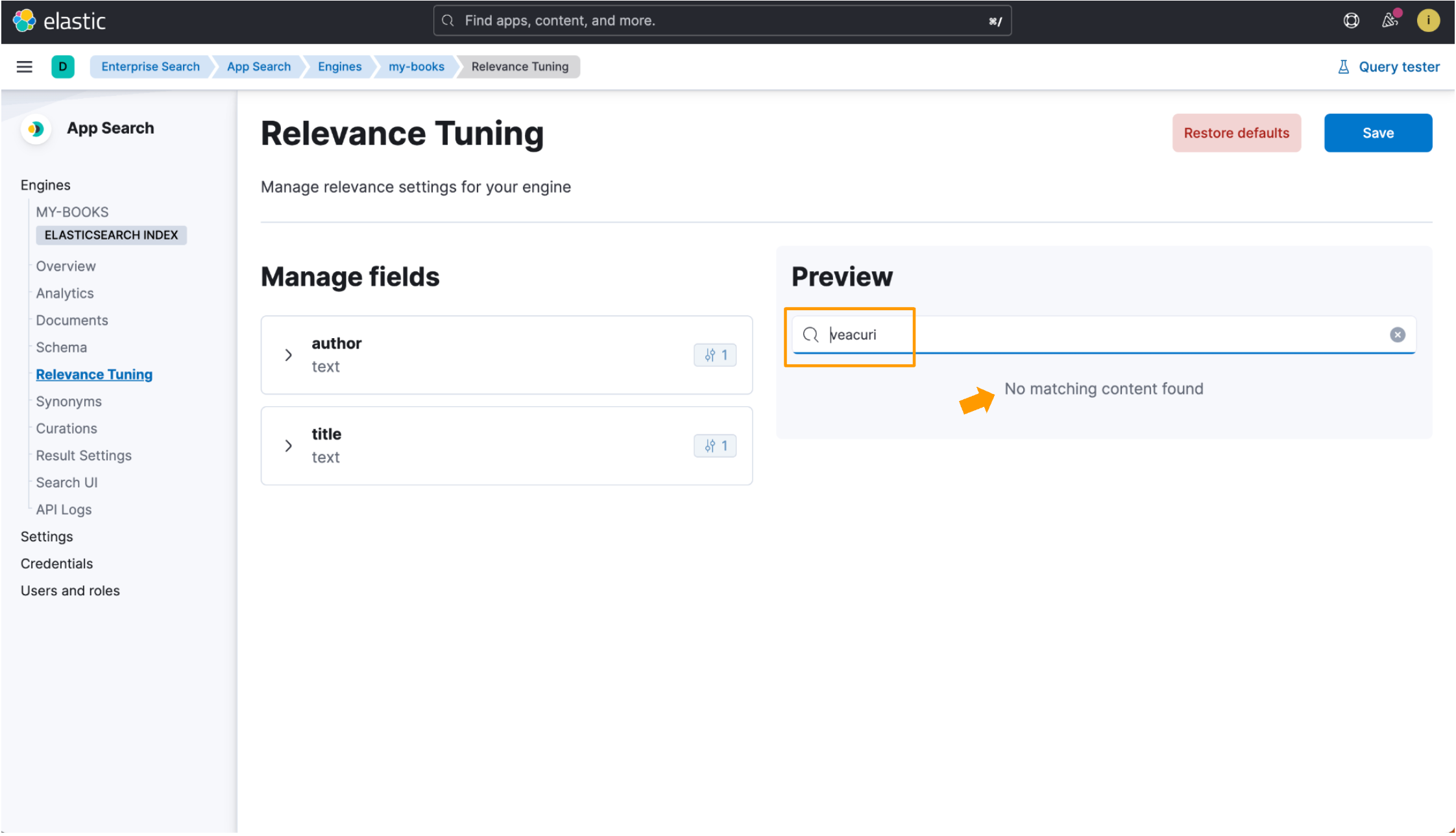
}Lorsqu'un index n'est pas optimisé pour une langue, le titre de livre roumain Un veac de singurătate est indexé avec l'analyseur standard, qui fonctionne très bien avec la plupart des langues, mais qui ne correspond pas forcément toujours aux documents pertinents. Rechercher veacuri ne renvoie aucun résultat, car l'entrée de recherche ne correspond à aucun texte brut dans l'enregistrement de données.
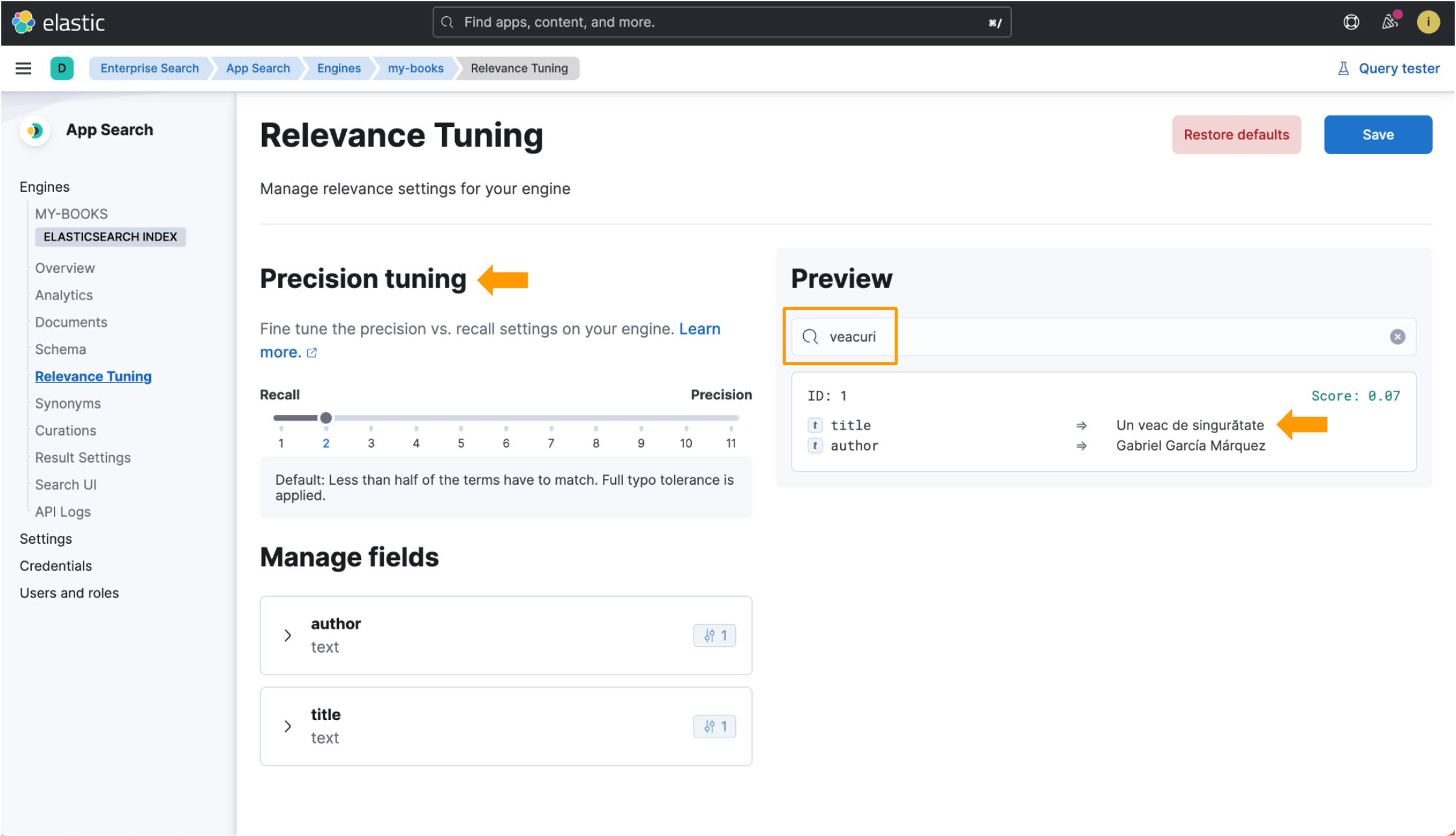
Cependant, lorsque vous recherchez veacuri en utilisant l'index optimisé pour la langue, Elastic App Search le fait correspondre au mot roumain veac et renvoie les données que nous recherchons. Les champs de réglage de la précision sont également disponibles au sein de la vue Réglage de la pertinence ! Regardez les parties mises en évidence sur cette image :
Sur ce, nous avons donc ajouté le roumain, qui est ma langue, à Elastic Enterprise Search ! Le processus utilisé dans ce guide peut être répliqué pour créer des index optimisés pour n'importe quelle langue compatible avec Elasticsearch. Pour une liste complète des analyseurs linguistiques compatibles avec Elasticsearch, consultez cette page de documentation.
Les analyseurs dans Elasticsearch sont un sujet fascinant. Si vous souhaitez en apprendre plus, voici quelques ressources qui pourraient vous intéresser :
- Page des documents Elasticsearch Aperçu de l'analyse des textes
- Page des documents Elasticsearch Référence des analyseurs intégrés (consultez cette sous-page pour obtenir une liste des analyseurs linguistiques compatibles.)
- En savoir plus sur l'essai d'Elastic Enterprise Search et d'Elastic Cloud
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer
Comment ajouter d'autres langues à vos moteurs de recherche Elastic Enterprise Search