Drei Wege, wie wir die Skalierbarkeit von Elasticsearch verbessert haben


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
“One finds limits by pushing them.”
Herbert A. Simon
Wir bei Elastic möchten Nutzern schnelle, relevante und nützliche Ergebnisse auch bei großen Datenmengen liefern – Geschwindigkeit, Skalierbarkeit und Relevanz sind Teil unserer DNA. In Elasticsearch 7.16 haben wir den Fokus auf die Skalierbarkeit gelegt und die Grenzen von Elasticsearch weiter ausgedehnt, um die Suche noch schneller zu machen, die Arbeitsspeicheranforderungen weiter zu drücken und für stabilere Cluster zu sorgen. Dabei haben wir festgestellt, dass es Skalierungsprobleme bei großen Shard-Zahlen gibt, und konnten durch entsprechende Gegenmaßnahmen die Geschwindigkeit von Elasticsearch so verbessern, dass sie neue Höhen erreicht.
In der Vergangenheit haben wir empfohlen zu vermeiden, dass im Cluster übergroße Mengen von Shards erstellt werden, weil dies zu einem großen Ressourcen-Overhead führt. Bei der neuen Strategie der Indexierung von Datenstreams in Fleet werden jedoch durch Security- und Observability-Anwendungsfälle immer mehr kleinere Shards generiert, was es notwendig macht, neue Möglichkeiten des Umgangs mit der wachsenden Zahl von Shards zu finden. In diesem Blogpost beschäftigen wir uns mit drei Skalierungsproblemen in Elasticsearch und damit, was wir getan haben, um das Nutzungserlebnis in 7.16 und darüber hinaus zu verbessern.

Rationalisierung der Autorisierung
Stellen Sie sich vor, Sie besuchen in den USA eine Bar (zur Erinnerung: Alkoholausschank erst ab 21 Jahren!). Beim Betreten der Bar kontrolliert man Ihren Ausweis und jedes Mal, wenn Sie einen Drink bestellen, wird Ihr Ausweis erneut kontrolliert. Genau so lief es mit der Autorisierung bis zur Version 7.16 ab: Jeder Knoten (Eingangstür) verlangte eine Autorisierung und jede Shard (Drinkbestellung) ebenfalls. Wie wäre es aber, wenn eine einmalige Ausweisprüfung an der Eingangstür ausreichen würde? Lassen Sie uns dieses Gleichnis auf eine Autorisierung in Elasticsearch anwenden!
Bei Elasticsearch können Nutzer eine rollen-/attributbasierte Zugriffssteuerung einrichten, um granulare Berechtigungen auf Feld-, Dokument- oder Indexebene zu gewähren. Vorher gab es in vielen Phasen einer Suchabfrage Autorisierungsschritte, um sicherzustellen, dass niemand Unbefugtes auf Daten zugreifen kann. Die Sicherheit, die die Autorisierungsfunktion ermöglicht, hat aber ihren Preis und einige der dabei verwendeten Logiken lassen sich nicht horizontal skalieren, wenn der Cluster größer wird. So kann zum Beispiel das Abrufen von Feldfunktionen für alle Felder in allen Indizes in einem großen Cluster viele Sekunden oder sogar Minuten dauern, wobei fast die gesamte Ausführungszeit mit autorisierungsbezogenen Arbeiten verbracht wird.
7.16 nimmt sich dieser Probleme von zwei Seiten aus an:
- Algorithmische Verbesserungen sorgen für schnellere individuelle Anforderungsautorisierungen, sowohl was REST-Anforderungen als auch was Autorisierungen während der Kommunikation in der Transportschicht (also die gesamte interne Netzwerkkommunikation zwischen den Knoten in einem Elasticsearch-Cluster) betrifft.
- Die Autorisierung interner Anforderungen wird entweder von vorherigen Prüfungen übernommen oder in vielen Fällen deutlich kostengünstiger gemacht. Bis zur Version 7.16 hat Elasticsearch beim Autorisieren interner Transportanforderungen innerhalb des Clusters dieselbe Autorisierungslogik eingesetzt, die auch schon die erste externe Anforderung hat durchlaufen müssen. Auf diese Weise wurde die Einführung einer Angriffsoberfläche in der internen Knoten-zu-Knoten-Kommunikation verhindert, die es einem Angreifer ermöglicht hätte, mithilfe gefälschter interner Anfragen die Autorisierungslogik zu umgehen. Durch das Überspringen der Platzhalter-Erweiterung bei Unteranfragen, das Überspringen der Autorisierung für knotenlokale Anfragen (im selben Knoten) und die Reduzierung der Gesamtzahl von Anforderungen, die für Aktionen wie die Suche erforderlich sind, ist dies jetzt mit deutlich weniger Kosten verbunden.
Reduzierung von Shard-Anfragen in der Vorabfilterphase
In 7.16 wurde eine neue Suchstrategie für die mit pre_filter_shard_size eingerichtete Vorabfilterphase implementiert, mit der die Zahl der Anfragen pro gefundenen Knoten auf eine reduziert wird. Bis zur Version 7.16 erforderte die erste Phase einer Suche, in der versucht wird, alle Shards aus der Abfrage herauszufiltern, von denen bekannt ist, dass sie keine relevanten Daten enthalten, seitens des koordinierenden Knotens für jede Shard eine eigene Anfrage an einen Datenknoten. Wenn Tausende von Shards gleichzeitig abgefragt werden, bedeutete dies, dass Tausende von Anfragen pro Suchanfrage vom koordinierenden Knoten gesendet, Tausende von Antworten auf dem koordinierenden Knoten verwaltet und alle diese Anfragen auf den Datenknoten bearbeitet werden mussten. Das Skalieren des Clusters durch Hinzufügen zusätzlicher Datenknoten hilft zwar, die Performance der Verarbeitung dieser Menge von Anfragen auf den Datenknoten zu verbessern, bringt aber nichts für die Performance dieser Operation auf dem koordinierenden Knoten.
In Version 7.16 wurde die Strategie zur Ausführung der Vorabfilterphase so geändert, dass pro Knoten nur noch eine Anfrage gesendet wird, die dann für alle Shards auf dem Knoten gilt. Dies wird in Abbildung 1 dargestellt. Für ein Cluster mit Tausenden von Shards, die über drei Datenknoten verteilt sind, bedeutet dies, dass sich die Zahl der Netzwerkanfragen in der anfänglichen Suchphase von Tausenden auf drei oder weniger reduziert, und dies ganz unabhängig von der Zahl der Shards in der Suche. Da die Anfragen pro Shard in den Versionen vor 7.16 im Wesentlichen alle dieselben Daten enthielten – nämlich die Suchabfrage –, führt das Senden nur einer Anfrage pro Knoten dazu, dass diese Informationen nicht mehr über mehrere Anfragen dupliziert werden. Das Ergebnis ist eine sehr deutliche Reduzierung der Zahl der Bytes, die durch das Netzwerk geschickt werden.
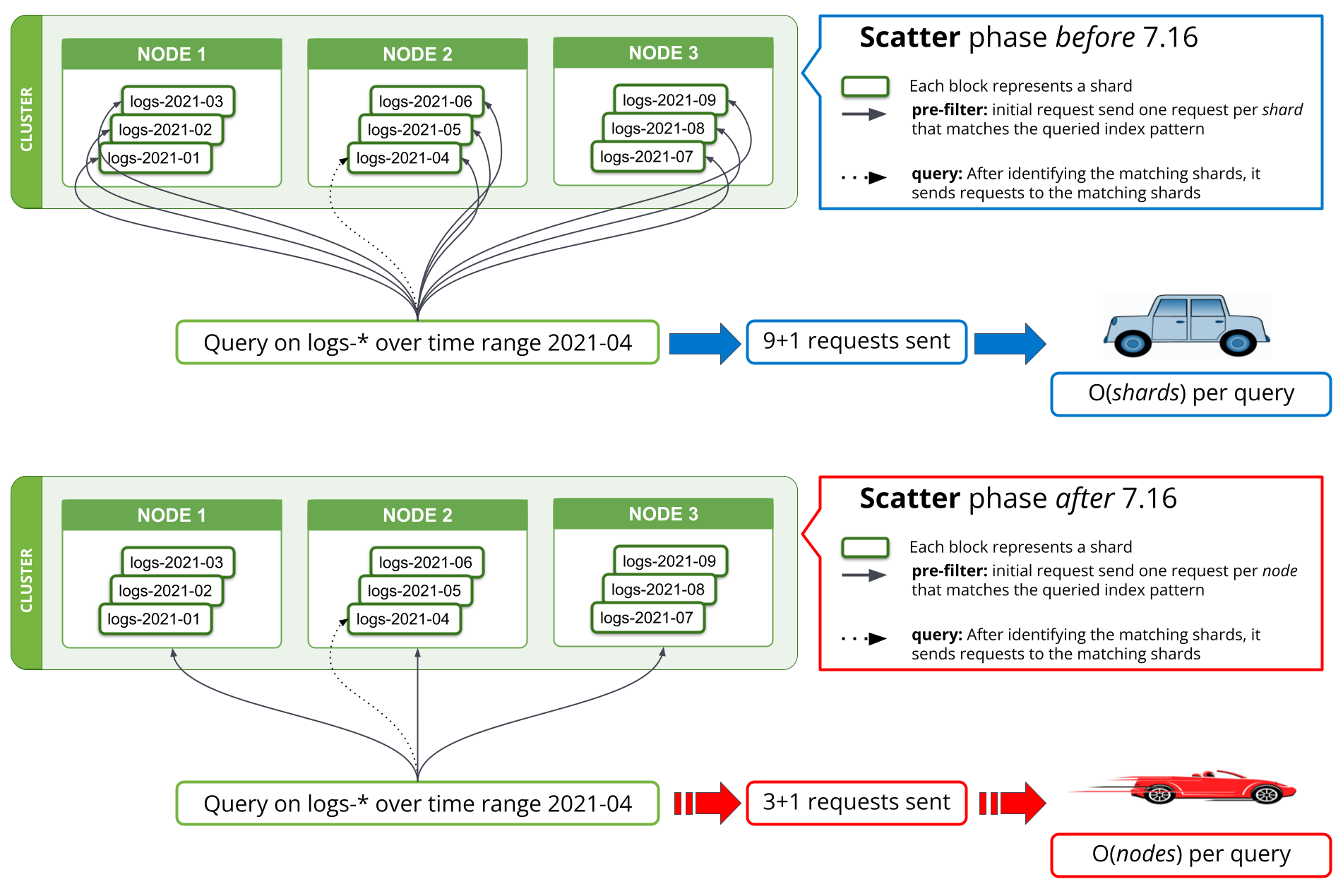
Ein ähnlicher Ansatz gilt für field_caps, das von Kibana- und *QL-Abfragen genutzt wird. Theoretisch wurden die in der Netzwerkanfrage gespeicherten Anfragen von O(Shards) auf O(Knoten) pro Abfrage reduziert; praktisch zeigt unser Benchmarking-Ergebnis, dass das Abfragen von Logdaten aus mehreren Monaten in einem sehr großen Logging-Cluster wenige Minuten oder auch weniger als 10 Sekunden dauern kann. Die damit verbundenen Einsparungen helfen nicht nur, was die Zahl der Netzwerkanfragen betrifft, sondern sie senken auch die mit diesen Anfragen verknüpfte Arbeitsspeicher- und CPU-Belastung.
Reduzierung der Arbeitsspeichernutzung
Fluglinien nutzen zur deutlichen Reduzierung des Flugzeuggewichts Tricks wie die Einsparung einer Olive im Salat, die Verwendung dünnerer Gläser und das Drucken von Zeitschriften in einem kleineren Format. In Elasticsearch machen wir das ähnlich, indem wir die Arbeitsspeicherkosten pro Feld reduzieren. Das bringt pro Feld zwar nur ein paar Kilobytes, aber hochgerechnet auf mehrere Millionen Felder aus allen Indizes in einem Cluster lassen sich so enorme Heap-Mengen einsparen.
Die Heap-Nutzung bei Elasticsearch-Datenknoten hängt davon ab, wie viele Indizes, Felder pro Index und Shards im Cluster-State vorhanden sind. Durch die große Zahl von Indizes ist der Heap-Speicher ständig belegt – egal, wie stark der Knoten unter Last steht. In 7.16 haben wir die Feld-Builder für die Felder text und number umstrukturiert und so eine Reduzierung ihres Arbeitsspeicher-Fußabdrucks und eine Reduzierung der Arbeitsspeichernutzung allein durch diese Feldstrukturen um mehr als 90 % erreicht.
Ingestiert, gesucht, gewonnen
Seit Veröffentlichung von Version 7.16 können wir uns ein Bild von den Verbesserungen machen, die in Clustern mit realistischen Workloads erzielt wurden. Die folgenden Diagramme zeigen die Auswirkungen des Upgrades für einen Cluster mit 60 Datenknoten.
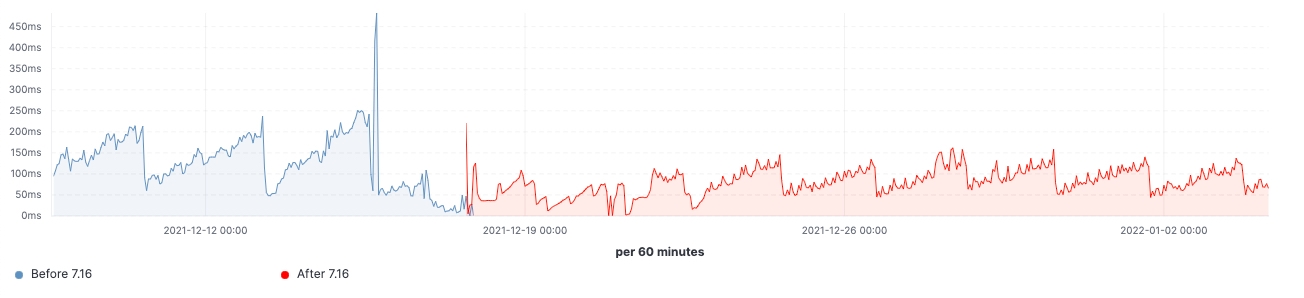
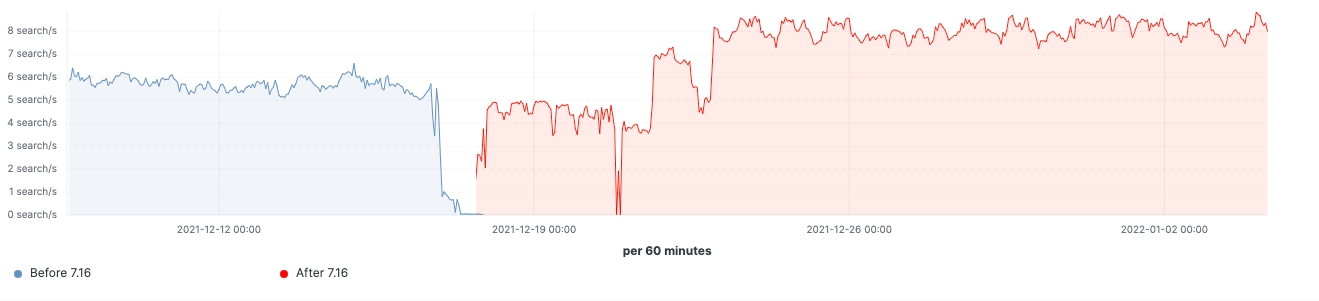
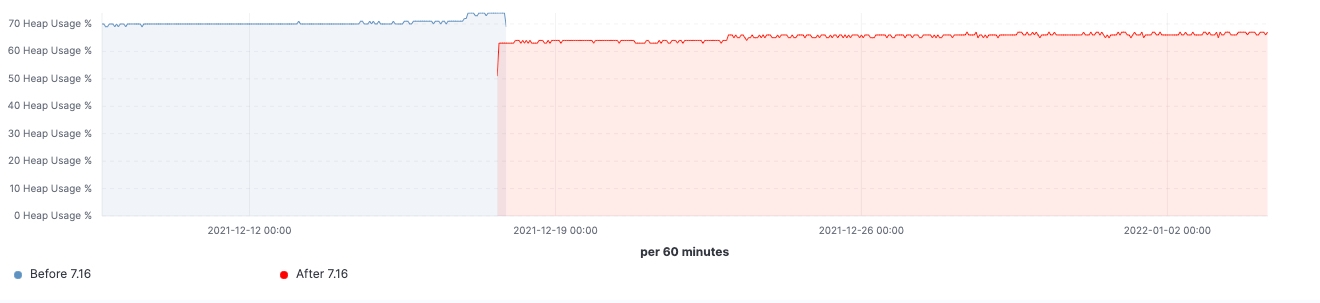
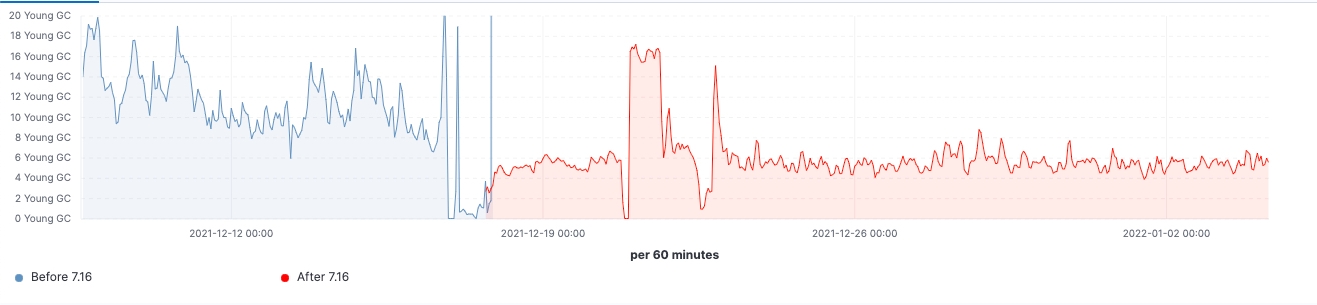
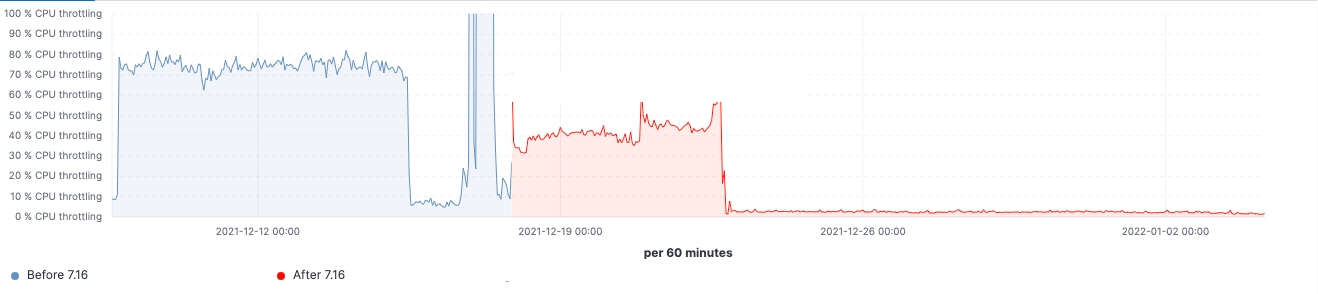
Bei diesem Cluster können wir sowohl vor als auch nach dem Upgrade eine gleichbleibende Arbeitslast sehen, aber das 99. Perzentil der Suchlatenz wurde gleichmäßig reduziert, die Suchgeschwindigkeit (Durchsatz) hat sich erhöht und die Heap-Nutzung bei Knoten mit „eingefrorenen“ Daten +++ist dank des niedrigeren Arbeitsspeicher-Fußabdrucks beim Speichern der Datenstruktur durchgehend niedriger. Man kann davon ausgehen, dass sich das auf alle Daten-Tiers auswirken wird, am ehesten aber auf die Tier für „eingefrorene“ Daten, bei der sich die Heap-Nutzung im Wesentlichen auf die Speicherung der Datenstruktur beschränkt, während der Heap bei den Knoten für „heiße“ Daten für das Indexieren, das Abfragen und andere Aktivitäten genutzt werden kann. Eine Aufschlüsselung auf die verschiedenen Knotenrollen ergibt, dass die koordinierenden Knoten durch die Reduzierung der Shard-Anfragen in der Vorabfilterphase die deutlichste Reduzierung bei der „Young GC“-Zahl aufzuweisen haben. Außerdem wird durch Verbesserungen bei der Cluster-State-Verwaltung auch eine spürbare Verringerung der Notwendigkeit des CPU-Throttlings erreicht.
Wir haben untersucht, warum Elasticsearch beim Skalieren auf Zehntausende Shards Performance-Probleme hatte, und führen mit Elasticsearch 7.16 Verbesserungen bei der Skalierbarkeit ein. Die Verwendung übergroßer Mengen von Shards und Mapping-Explosionen sind bekannte Faktoren für Elasticsearch-Abstürze und sollten daher weiterhin vermieden werden. Aber mit den Verbesserungen in 7.16 dürften die Auswirkungen dieser Faktoren deutlich geringer werden. Bei dieser Version wurde das Hauptaugenmerk auf die Gesamtgröße des Clusters gelegt. Im Ergebnis konnten die für die Verarbeitung von Cluster-State-Aktualisierungen benötigte Master-Größe reduziert und die Suchkoordination bei großen Indexmengen rationalisiert werden.
Durch die Verbesserungen in Elasticsearch 7.16 arbeitet Ihre Suchmaschine jetzt noch schneller, die Anforderungen an Ihren Arbeitsspeicher sind geringer und Ihr Cluster ist stabiler – das Upgrade lohnt sich also. Wir arbeiten weiter an der Verbesserung verschiedener Aspekte im Bereich der Skalierbarkeit und werden Sie über unsere Erfolge in 8.x auf dem Laufenden halten.
Bereit, noch mehr zu skalieren?
Wenn Sie bereits Elastic Cloud-Kunde sind, können Sie direkt von der Elastic Cloud-Konsole aus auf viele dieser Features zugreifen. Neuen Nutzern von Elastic Cloud empfehlen wir unsere Quick Start-Anleitungen (kurze Schulungsvideos für einen schnellen Einstieg) oder unsere kostenlosen Grundlagenschulungen. Oder Sie probieren Elastic Cloud 14 Tage lang kostenlos aus. Und wer das Ganze lieber selbst verwalten möchte, kann den Elastic Stack kostenlos herunterladen.
Mehr zu diesen Funktionen erfahren Sie in den Versionshinweisen zu Elastic Stack. Eine Zusammenstellung der Elastic Stack-Highlights finden Sie im Blogpost zu Elastic 7.16.Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken