Unterstützung für weitere Sprachen in Ihren Elastic Enterprise Search-Modulen hinzufügen


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Mit Elastic App Search-Modulen können Sie Dokumente indexieren und vorkonfigurierte, justierbare Suchfunktionen bereitstellen. Module unterstützen standardmäßig eine vordefinierte Liste an Sprachen. Falls Ihre Sprache nicht zu dieser Liste gehört, erfahren Sie in diesem Blogeintrag, wie Sie zusätzliche Sprachen unterstützen können. Zu diesem Zweck erstellen wir ein App Search-Modul und richten Analyzer für die entsprechende Sprache ein.
Bevor wir uns mit den Details befassen, sollten wir den Begriff „Elasticsearch-Analyzer“ definieren:
Ein Elasticsearch-Analyzer ist ein Paket mit drei fundamentalen Bausteinen: Zeichenfilter, Tokenizer und Token-Filter. Sie können integrierte oder benutzerdefinierte Analyzer verwenden. Integrierte Analyzer kombinieren Bausteine zu passenden Analyzern für unterschiedliche Sprachen und Texttypen.
Analyzer für die einzelnen Felder erfüllen die folgenden Funktionen:
- Indexieren Jedes Dokumentfeld wird mit dem entsprechenden Analyzer verarbeitet und in Token unterteilt, um die Suche zu erleichtern.
- Suchen Sie Suchabfrage wird analysiert, um passende Übereinstimmungen mit den bereits zuvor analysierten und indexierten Feldern zu garantieren.
Mit indexbasierten Elasticsearch-Modulen können Sie App Search-Module aus vorhandenen Elasticsearch-Indizes erstellen. Wir werden einen Elasticsearch-Index mit unseren eigenen Analyzern und Mappings erstellen und diesen Indexieren in App Search verwenden.
Dieser Prozess umfasst vier Schritte:
1. Elasticsearch-Index erstellen und Dokumente indexieren
Als Ausgangspunkt verwenden wir einen Index, der noch für keine Sprache optimiert wurde. Wir gehen davon aus, dass es sich um einen neuen Index ohne vordefinierte Mappings handelt, der beim ersten Indexieren der Dokumente erstellt wurde.
Der Begriff Mapping in Elasticsearch bezeichnet den Prozess, der definiert, wie ein Dokument und die darin enthaltenen Felder gespeichert und indexiert werden. Jedes Dokument ist eine Sammlung von Feldern, die jeweils einen eigenen Datentyp haben. Beim Mapping Ihrer Daten erstellen Sie eine Mapping-Definition, die eine Liste der Felder für das jeweilige Dokument enthält.
Zurück zu unserem Beispiel. Der Index heißt books (Bücher), und der title (Titel) liegt jeweils auf Rumänisch vor. Wir verwenden Rumänisch, weil es meine Muttersprache ist und nicht zu der Liste der standardmäßig in App Search unterstützten Sprachen gehört.
POST books/_doc/1
{
"title": "Un veac de singurătate",
"author": "Gabriel García Márquez"
}
POST books/_doc/2
{
"title": "Dragoste în vremea holerei",
"author": "Gabriel García Márquez"
}
POST books/_doc/3
{
"title": "Obosit de viaţă, obosit de moarte",
"author": "Mo Yan"
}
POST books/_doc/4
{
"title": "Maestrul și Margareta",
"author": "Mihail Bulgakov"
}2. Sprach-Analyzer zum Bücher-Index hinzufügen
Beim Betrachten des Index-Mappings für books stellen wir fest, dass das Mapping nicht für Rumänisch optimiert ist. Das erkennen wir daran, dass kein analysis-Feld im settings-Block vorhanden ist und dass die Textfelder keinen benutzerdefinierten Analyzer verwenden.
GET books
{
"books": {
"aliases": {},
"mappings": {
"properties": {
"author": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "books",
"creation_date": "1679310576178",
"number_of_replicas": "1",
"uuid": "0KuiDk8iSZ-YHVQGg3B0iw",
"version": {
"created": "8080099"
}
}
}
}
}Beim Versuch, ein App Search-Modul mit dem Index books zu erstellen, stoßen wir auf zweierlei Probleme. Einerseits sind die Suchergebnisse nicht für Rumänisch optimiert, und andererseits sind Features wie etwa das Präzisions-Tuning deaktiviert.
Ein kurzer Hinweis zu den verschiedenen Typen von Elastic App Search-Modulen:
- Die Standardoption ist ein verwaltetes App Search-Modul, das automatisch einen ausgeblendeten Elasticsearch-Index erstellt und verwaltet. Mit dieser Option müssen Sie die App Search Documents API verwenden, um Daten in Ihr Modul zu ingestieren.
- Mit der anderen Option erstellt App Search ein Modul mit einem vorhandenen Elasticsearch-Index und verwendet den Index in seiner aktuellen Form. In diesem Fall können Sie die Elasticsearch Index Documents API verwenden, um Daten direkt in den zugrunde liegenden Index zu ingestieren.
[Weiterführender Artikel: Elasticsearch Search API: A new way to locate App Search documents (Eine neue Methode zur Lokalisierung von App Search-Dokumenten, nur auf Englisch)]
Wenn Sie ein Modul aus einem vorhandenen Elasticsearch-Index erstellen und die Mappings nicht den App Search-Konventionen folgen, werden für dieses Modul nicht alle Features aktiviert. Werfen wir einen Blick auf die Mapping-Konventionen für App Search, indem wir uns ein vollständig von App Search verwaltetes Modul ansehen. Dieses Modul enthält zwei Felder – title und author – und verwendet Englisch als Sprache.
GET .ent-search-engine-documents-app-search-books/_mapping/field/title
{
".ent-search-engine-documents-app-search-books": {
"mappings": {
"title": {
"full_name": "title",
"mapping": {
"title": {
"type": "text",
"fields": {
"date": {
"type": "date",
"format": "strict_date_time||strict_date",
"ignore_malformed": true
},
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"float": {
"type": "double",
"ignore_malformed": true
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"location": {
"type": "geo_point",
"ignore_malformed": true,
"ignore_z_value": false
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
},
"index_options": "freqs",
"analyzer": "iq_text_base"
}
}
}
}
}
}Wie Sie sehen, hat das Feld title mehrere untergeordnete Felder. Die untergeordneten Felder date, float und location sind keine Textfelder.
Wir möchten gerne erfahren, wie wir die für App Search benötigten Textfelder einrichten können. Wir haben eine riesige Menge an Feldern zur Auswahl! Diese Dokumentationsseite erklärt die in App Search verwendeten Textfelder. Sehen wir uns die Analyzer an, die App Search für einen ausgeblendeten Index festlegt, der zu einem von App Search verwalteten Modul gehört:
GET .ent-search-engine-documents-app-search-books/_settings/index.analysis*
{
".ent-search-engine-documents-app-search-books": {
"settings": {
"index": {
"analysis": {
"filter": {
"front_ngram": {
"type": "edge_ngram",
"min_gram": "1",
"max_gram": "12"
},
"bigram_joiner": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "false",
"type": "shingle"
},
"bigram_max_size": {
"type": "length",
"max": "16",
"min": "0"
},
"en-stem-filter": {
"name": "light_english",
"type": "stemmer"
},
"bigram_joiner_unigrams": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "true",
"type": "shingle"
},
"delimiter": {
"split_on_numerics": "true",
"generate_word_parts": "true",
"preserve_original": "false",
"catenate_words": "true",
"generate_number_parts": "true",
"catenate_all": "true",
"split_on_case_change": "true",
"type": "word_delimiter_graph",
"catenate_numbers": "true",
"stem_english_possessive": "true"
},
"en-stop-words-filter": {
"type": "stop",
"stopwords": "_english_"
}
},
"analyzer": {
"i_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"front_ngram"
],
"tokenizer": "standard"
},
"iq_text_delimiter": {
"filter": [
"delimiter",
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter",
"en-stem-filter"
],
"tokenizer": "whitespace"
},
"q_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding"
],
"tokenizer": "standard"
},
"iq_text_base": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter"
],
"tokenizer": "standard"
},
"iq_text_stem": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stop-words-filter",
"en-stem-filter"
],
"tokenizer": "standard"
},
"i_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stem-filter",
"bigram_joiner",
"bigram_max_size"
],
"tokenizer": "standard"
},
"q_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"en-stem-filter",
"bigram_joiner_unigrams",
"bigram_max_size"
],
"tokenizer": "standard"
}
}
}
}
}
}
}Wenn wir einen Index erstellen möchten, den wir in App Search für eine andere Sprache verwenden können, wie etwa Norwegisch, Finnisch oder Arabisch, dann brauchen wir ähnliche Analyzer. Für unser Beispiel müssen wir sicherstellen, dass die Stamm- und Stoppwortfilter die rumänische Version verwenden.
Kehren wir zu unserem ursprünglichen Index books zurück und fügen wir die passenden Analyzer hinzu.
An dieser Stelle ein kurzer Hinweis. In einem vorhandenen Index sind Analyzer eine Art von Elasticsearch-Einstellung, die nur geändert werden kann, wenn ein Index geschlossen wird. In diesem Fall haben wir einen vorhandenen Index und müssen daher den Index schließen, Analyzer hinzufügen und den Index anschließend erneut öffnen.
Hinweis: Alternativ können Sie den Index auch mit den passenden Mappings neu erstellen und anschließend alle Dokumente indexieren. Falls diese Variante besser zu Ihrem Anwendungsfall passt, können Sie in dieser Anleitung die Schritte überspringen, in denen wir den Index öffnen, schließen und neu indexieren.
Sie können den Index mit dem Befehl POST books/_close schließen. Anschließend fügen wir die Analyzer hinzu:
PUT books/_settings
{
"analysis": {
"filter": {
"front_ngram": {
"type": "edge_ngram",
"min_gram": "1",
"max_gram": "12"
},
"bigram_joiner": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "false",
"type": "shingle"
},
"bigram_max_size": {
"type": "length",
"max": "16",
"min": "0"
},
"ro-stem-filter": {
"name": "romanian",
"type": "stemmer"
},
"bigram_joiner_unigrams": {
"max_shingle_size": "2",
"token_separator": "",
"output_unigrams": "true",
"type": "shingle"
},
"delimiter": {
"split_on_numerics": "true",
"generate_word_parts": "true",
"preserve_original": "false",
"catenate_words": "true",
"generate_number_parts": "true",
"catenate_all": "true",
"split_on_case_change": "true",
"type": "word_delimiter_graph",
"catenate_numbers": "true"
},
"ro-stop-words-filter": {
"type": "stop",
"stopwords": "_romanian_"
}
},
"analyzer": {
"i_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"front_ngram"
],
"tokenizer": "standard"
},
"iq_text_delimiter": {
"filter": [
"delimiter",
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter",
"ro-stem-filter"
],
"tokenizer": "whitespace"
},
"q_prefix": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding"
],
"tokenizer": "standard"
},
"iq_text_base": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter"
],
"tokenizer": "standard"
},
"iq_text_stem": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stop-words-filter",
"ro-stem-filter"
],
"tokenizer": "standard"
},
"i_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stem-filter",
"bigram_joiner",
"bigram_max_size"
],
"tokenizer": "standard"
},
"q_text_bigram": {
"filter": [
"cjk_width",
"lowercase",
"asciifolding",
"ro-stem-filter",
"bigram_joiner_unigrams",
"bigram_max_size"
],
"tokenizer": "standard"
}
}
}
}Wie Sie sehen, fügen wir den „ro-stem-filter“ für unser Stemming (Wortstammerkennung) auf Rumänisch hinzu, um die Suchrelevanz für Wortvarianten der rumänischen Sprache zu verbessern. Außerdem fügen wir den rumänischen Stoppwortfilter (ro-stop-words-filter) hinzu, um sicherzustellen, dass rumänische Stoppwörter nicht für die Suche berücksichtigt werden.
Zuletzt führen wir POST books/_open aus, um den Index erneut zu öffnen.
3. Index-Mapping aktualisieren, um die Analyzer zu verwenden
Nachdem wir die Analyseeinstellungen konfiguriert haben, können wir das Index-Mapping anpassen. App Search verwendet dynamische Vorlagen, um sicherzustellen, dass neue Felder die passenden untergeordneten Felder und Analyzer enthalten. In unserem Beispiel fügen wir nur untergeordnete Felder zu den vorhandenen Feldern title und author hinzu:
PUT books/_mapping
{
"properties": {
"author": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
}
},
"title": {
"type": "text",
"fields": {
"delimiter": {
"type": "text",
"index_options": "freqs",
"analyzer": "iq_text_delimiter"
},
"enum": {
"type": "keyword",
"ignore_above": 2048
},
"joined": {
"type": "text",
"index_options": "freqs",
"analyzer": "i_text_bigram",
"search_analyzer": "q_text_bigram"
},
"prefix": {
"type": "text",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
},
"stem": {
"type": "text",
"analyzer": "iq_text_stem"
}
}
}
}
}4. Dokumente neu indexieren
Der Index books ist jetzt beinahe bereit für den Einsatz in App Search!
Wir müssen nur noch sicherstellen, dass die Dokumente, die wir vor den Mapping-Änderungen indexiert haben, die passenden untergeordneten Felder enthalten. Dazu führen wir eine In-Place-Neuindexierung mit dem Befehl update_by_query aus:
POST books/_update_by_query?refresh
{
"query": {
"match_all": {
}
}
}Wir verwenden eine match_all-Abfrage, daher werden alle vorhandenen Dokumente aktualisiert.
Mit einer update by query-Anfrage können wir außerdem einen Skriptparameter angeben, um zu definieren, wie die Dokumente aktualisiert werden sollen.
Beachten Sie, dass wir die Dokumente nicht ändern, sondern lediglich vorhandene Dokumente neu indexieren, um sicherzustellen, dass die Textfelder author und title die passenden untergeordneten Felder enthalten. Daher müssen wir in unserer „update by query“-Anfrage kein script angeben.
Damit haben wir einen sprachoptimierten Index, den wir mit Elasticsearch-Modulen in App Search verwenden können! In den folgenden Screenshots sehen Sie eine Demonstration der verschiedenen Vorteile.
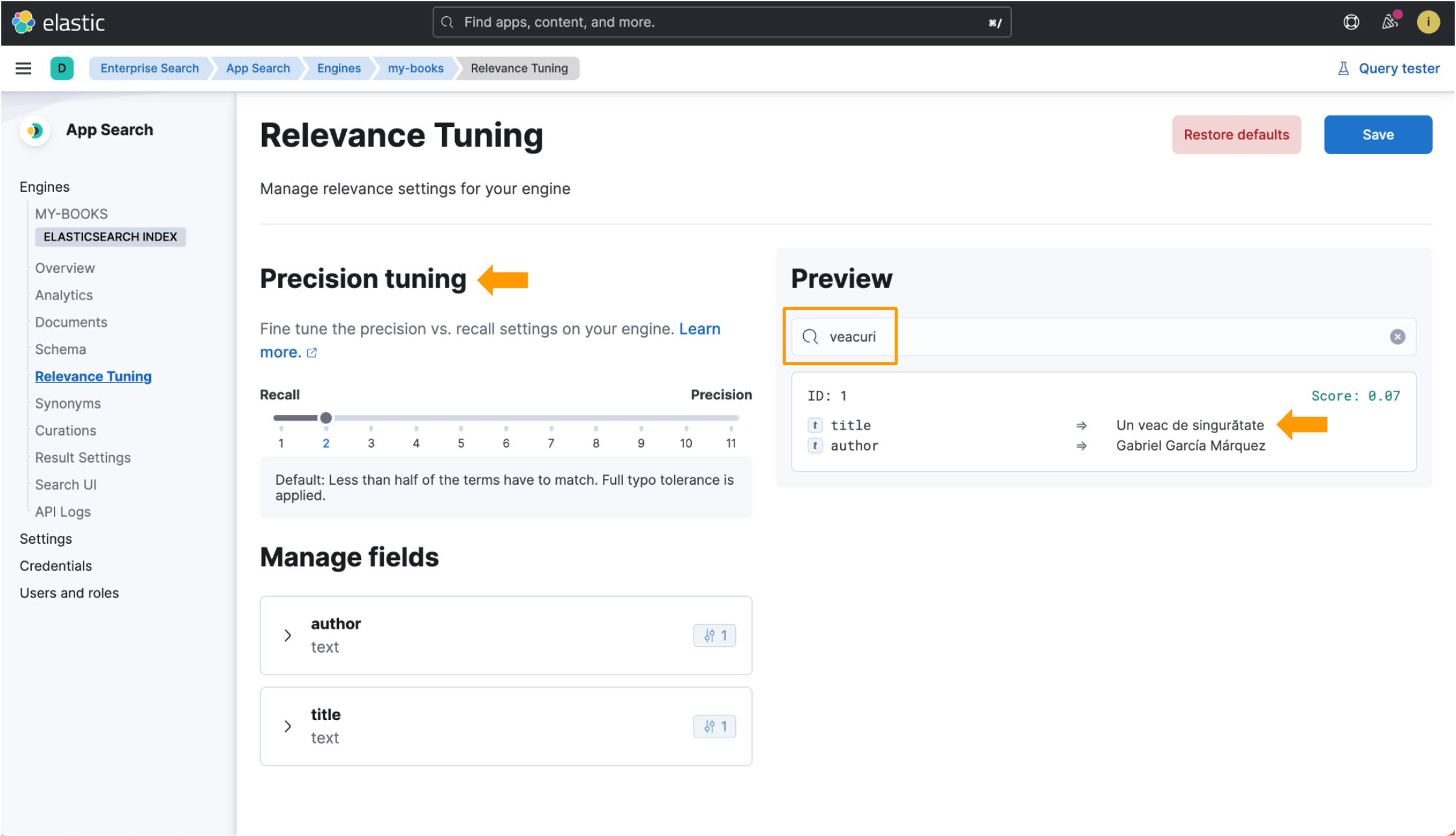
Wir verwenden den Buchtitel One Hundred Years of Solitude als Referenz. Die rumänische Übersetzung des Titels lautet Un veac de singurătate. Beachten Sie dabei das rumänische Wort für „Jahrhundert“: veac. Wir führen eine Suche mit der Pluralform von veac aus, also mit veacuri. Wir haben in beiden Beispielen, die wir uns gleich ansehen werden, den folgenden Datensatz ingestiert:
{
"title": "Un veac de singurătate",
"author": "Gabriel García Márquez"
}Wenn ein Index nicht für eine Sprache optimiert ist, wird der rumänische Buchtitel Un veac de singurătate mit dem Standard-Analyzer indexiert, der für die meisten Sprachen gut geeignet ist, aber unter Umständen nicht immer alle relevanten Dokumente findet. Die Suche nach veacuri gibt keine Ergebnisse zurück, da die Sucheingabe nicht mit dem reinen Text im Datensatz übereinstimmt.
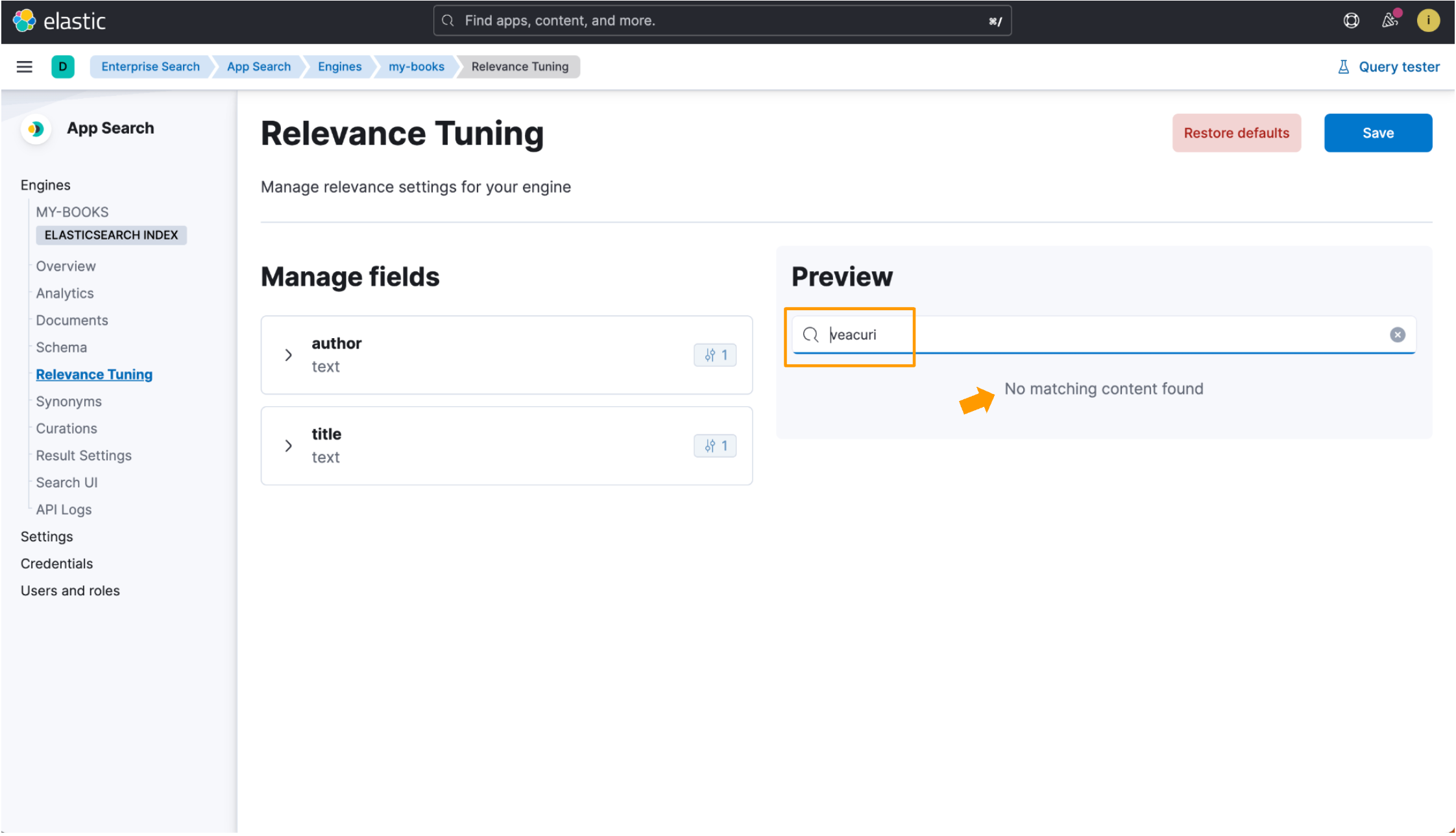
Wenn wir jedoch mit dem sprachoptimierten Index nach veacuri suchen, findet Elastic App Search das rumänische Wort veac und gibt die Daten zurück, nach denen wir gesucht haben. Die Felder für die Feinabstimmung sind auch in der Relevanz-Tuning-Ansicht verfügbar! Sehen Sie sich die Hervorhebungen in diesem Bild an:
Wir haben also gesehen, wie wir meine Muttersprache Rumänisch in Elastic Enterprise Search unterstützen können! Mit dem hier gezeigten Prozess können Sie Ihre Indizes für beliebige andere Sprachen optimieren, die von Elasticsearch unterstützt werden. Eine vollständige Liste der unterstützten Sprach-Analyzer in Elasticsearch finden Sie auf dieser Seite in der Dokumentation.
Analyzer in Elasticsearch sind ein faszinierendes Thema. Hier sind einige Ressourcen, falls Sie mehr darüber erfahren möchten (größtenteils nur auf Englisch):
- Elasticsearch-Dokumentation zur Textanalyse
- Elasticsearch-Dokumentation für integrierte Analyzer (sowie die untergeordnete Seite mit einer Liste der unterstützten Sprach-Analyzer.)
- Erfahren Sie mehr über Elastic Enterprise Search und die Elastic Cloud-Testversion.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken