Erkennung abnormaler Muster auf Basis von Eltern-Kind-Beziehungen
Seitdem dateibasierte Angriffe von Virenschutzsoftware und der Machine Learning-basierten Malware-Erkennung immer besser erkannt werden, haben Angreifer sich auf improvisierte Techniken verlegt, um moderne Sicherheitslösungen zu täuschen. Dabei werden beispielsweise Systemtools ausgeführt, die zum Betriebssystem gehören oder die von einem Administrator installiert wurden, um Verwaltungsaufgaben zu erledigen, Skripts in regelmäßigen Abständen zu starten, Code auf Remotesystemen auszuführen und vieles mehr. Angreifer, die vertraute BS-Tools wie powershell.exe, wmic.exe oder schtasks.exe nutzen, sind unter Umständen schwer zu identifizieren. Diese Binärdateien sind an sich gutartig und werden in vielerlei Umgebungen eingesetzt. Daher können Angreifer die erste Verteidigungslinie problemlos umgehen, indem sie sich unter das Grundrauschen der regelmäßig ausgeführten Aufgaben mischen. Um diese Art von Mustern nach einem Angriff zu erkennen, müssen Millionen von Ereignissen ohne eindeutigen Startpunkt durchsucht werden.
Als Reaktion darauf haben Sicherheitsforscher Detektoren entwickelt, die verdächtige Eltern-Kind-Prozessketten unter die Lupe nehmen. Mit MITRE ATT&CK™ als Vorlage haben die Forscher eine Erkennungslogik entwickelt, die eine Warnung verschickt, wenn ein bestimmter Elternprozess einen Kindprozess mit bestimmten Befehlszeilenparametern startet. Ein gutes Beispiel ist ein MS Office-Prozess, der powershell.exe mit base64-codierten Argumenten startet. Dieser zeitraubende Prozess ist erfordert jedoch umfassende Fachkenntnisse und eine explizite Feedbackschleife für die Feinabstimmung übereifriger Detektoren.
Sicherheitsexperten haben verschiedene „Rot gegen Blau“-Frameworks als Open Source entwickelt, um die Detektorleistung zu prüfen, aber jeder noch so effektive Detektor kann mit seiner Logik nur einen bestimmten Angriff erkennen. Die Detektoren können nicht verallgemeinert werden, um neue Angriffe zu erkennen, wodurch sich eine Gelegenheit für Machine Learning ergibt.
Graphen zur Rettung
Als wir auf die Idee gekommen sind, nach abnormalen Eltern-Kind-Prozessen zu suchen, habe ich sofort versucht, das Problem mit einem Graph zu lösen. Schließlich kann die Prozessausführung für jeden beliebigen Host als Graph dargestellt werden. Die Knoten in unserem Graph sind einzelne Prozesse mit ihrer jeweiligen Prozess-ID (PID), und die Verbindungslinien zwischen den Knoten bilden „process_creation“-Ereignisse ab. Jede Verbindungslinie enthält wichtige Metadaten für das Ereignis, wie etwa Zeitstempel, Befehlszeilenargumente und den Benutzer.
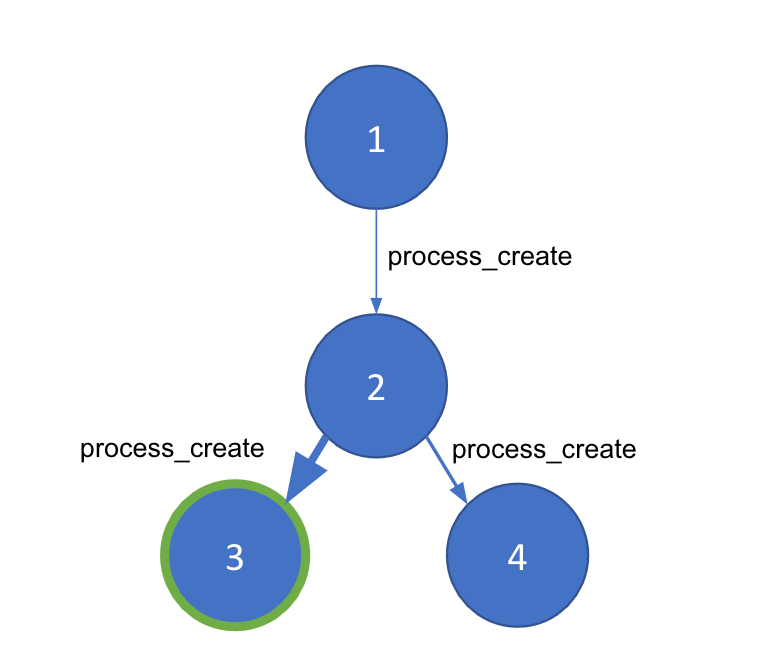
Wir können die Prozessereignisse eines Hostcomputers also als Graph abbilden. Improvisierte Angriffe können jedoch aus den Prozessen auf Systemebene entstehen, die immer ausgeführt werden. Wir brauchen eine Methode, um gute und schlechte Prozessketten innerhalb eines Graphs voneinander zu unterscheiden. Bei der Community-Erkennung wird ein großer Graph nach der Dichte der Kanten zwischen den Knoten in kleinere „Communitys“ aufgeteilt. Wir müssen die Kanten zwischen den Knoten gewichten, um sicherzustellen, dass die Community-Erkennung korrekt funktioniert und die abnormalen Teile unseres Graphen identifiziert. Dazu verwenden wir Machine Learning.
Machine Learning
Wir generieren unser Modell mit gewichteten Kanten mit überwachtem Machine Learning, einem Ansatz, bei dem das Modell mit beschrifteten Daten trainiert wird. Glücklicherweise können wir die bereits erwähnten „Rot und Blau“ Open Source-Frameworks nutzen, um einen Teil der Trainingsdaten zu generieren. Hier sind einige der „Rot und Blau“ Open Source-Frameworks, die wir für unseren Trainings-Korpus verwendet haben:
Frameworks für das rote Team:
- Atomic Red Team (Red Canary)
- Red Team Automation (Endgame/Elastic)
- Caldera Adversary Emulation (MITRE)
- Metta (Uber)
Frameworks für das blaue Team:
- Atomic Blue (Endgame/Elastic)
- Cyber Analytics Repository (MITRE)
- MSFT ATP Queries (Microsoft)
Dateningestion und -normalisierung

Nachdem wir einige Ereignisdaten ingestiert haben, müssen wir sie in eine numerische Darstellungsform transformieren (Abb. 2). Mit dieser Darstellung lernt das Modell weitere Details der Eltern-Kind-Beziehung bei einem Angriff kennen, um die reinen Lernsignaturen umgehen zu können.
Zunächst verarbeiten wir Prozessnamen und Befehlszeilenargumente mit Feature Engineering (Abb. 3). Wir erfassen die statistische Bedeutung bestimmter Wörter für ein Ereignis in unserem Datensatz mit TF-IDF-Vektorisierung. Durch die Konvertierung von Zeitstempeln in Ganzzahlen können wir die Zeitdifferenz zwischen dem Start des Elternprozesses und dem Start des Kindprozesses ermitteln. Andere Merkmale werden binär abgebildet (z. B. 1 oder 0, ja oder nein). Beispiele für binäre Merkmale:
- Ist der Prozess signiert?
- Vertrauen wir der Signatur?
- Hat der Prozess erhöhte Berechtigungen?

Nach der Transformation können wir unseren Datensatz verwenden, um ein überwachtes Lernmodell zu trainieren (Abb. 4). Dieses Modell liefert eine Abweichungsbewertung zwischen 0 (gutartig) und 1 (abnormal) für jedes Prozesserstellungsereignis. Diese Abweichungsbewertung können wir als Kantengewichtung in unserem Graph verwenden!
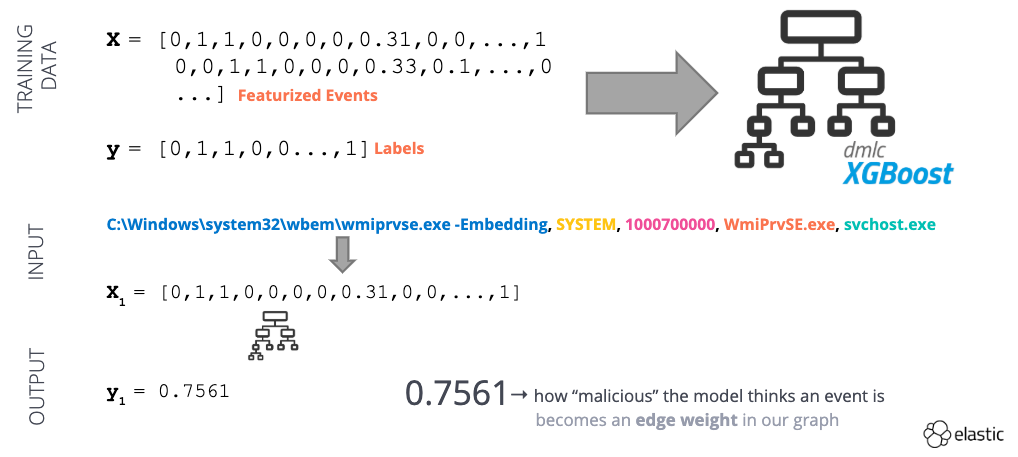
Abb. 4: Beispiel-Flow für überwachtes Machine Learning
Verbreitungsdienst


Abb. 5: Bedingte Wahrscheinlichkeiten für das Verbreitungsmodul
Unser Machine Learning-Modell liefert uns also einen gewichteten Graph. Mission erfüllt, oder nicht? Das trainierte Modell ist gut darin, gute und schlechte Eltern-Kind-Ketten auf Basis unseres allgemeinen Verständnisses von gut und schlecht zu unterscheiden. Allerdings hat jede Kundenumgebung ihre Eigenheiten. Dort können Prozesse ausgeführt werden, die wir noch nie beobachtet haben, und Systemadministratoren nutzen PowerShell für ... nun, für alles.
Wenn wir nur dieses Modell einsetzen, würden wir vermutlich eine Flut an falschen Positivmeldungen sehen und damit die Datenmenge erhöhen, die von Analysten gesichtet werden muss. Als Abhilfe haben wir einen Verbreitungsdienst entwickelt, der uns verrät, wie stark eine bestimmte Eltern-Kind-Prozesskette in der jeweiligen Umgebung verbreitet ist. Wir müssen die lokalen Feinheiten der jeweiligen Umgebung betrachten, um verdächtige Ereignisse besser anheben oder unterdrücken zu können und um tatsächlich abnormale Prozessketten zu identifizieren.
Der Verbreitungsdienst (Abb. 5) verwendet zwei mit bedingter Wahrscheinlichkeit abgeleitete Werte, mit denen wir die folgende Aussage treffen können: „Dieser Elternprozess hat diesen Kindprozess mehr als X % der anderen Kindprozesse gestartet“ UND „Von diesem Prozess habe ich diese Befehlszeile häufiger als X % der anderen Befehlszeilen für den Prozess gesehen“. Sobald wir den Verbreitungsdienst installiert haben, können wir unsere eigentliche Erkennungslogik „find_bad_communities“ fertigstellen.
Suche nach „schlechten“ Communitys

Abb. 6: Python-Code für die Suche nach abnormalen Communitys
In Abbildung 6 sehen Sie den Python-Code, mit dem wir die schlechten Communitys generieren. Die Logik für „find_bad_communities“ ist relativ einfach:
- Jedes „process_create“-Ereignis auf einem Hostcomputer klassifizieren und ein Knotenpaar (Eltern- und Kindknoten) und eine zugehörige Gewichtung (die Ausgabe unseres Modells) generieren.
- Gerichteten Graph erstellen.
- Community-Erkennung ausführen, um eine Liste der Communitys im Graph zu generieren.
- Wir ermitteln innerhalb der einzelnen Communitys, wie weit verbreitet eine Eltern-Kind-Beziehung ist (also die einzelnen Verbindungen). Die abschließende Abweichungsbewertung berücksichtigt, wie verbreitet ein Eltern-Kind-Ereignis ist.
- Wenn die Abweichungsbewertung einen Schwellenwert überschreitet, legen wir die gesamte Community zur Überprüfung durch einen Analysten beiseite.
- Nachdem die Communitys analysiert wurden, geben wir eine Liste der „schlechten“ Communitys sortiert nach der höchsten Abweichungsbewertung zurück.
Ergebnisse
Wir haben das endgültige Modell mit einer Kombination aus echten und simulierten gut- und bösartigen Daten trainiert. Für die gutartigen Daten haben wir drei Tage lang die Windows-Prozessereignisdaten in unserem internen Netzwerk gesammelt. Als Datenquelle haben wir eine Mischung aus Benutzer-Workstations und Servern verwendet, um ein Kleinunternehmen abzubilden. Für die bösartigen Daten haben wir alle ATT&CK-Techniken eingesetzt, die über das Endgame RTA-Framework verfügbar sind, und verschiedene Makro- und binärbasierte Malware von erweiterten Bedrohungen wie FIN7 und Emotet ausgeführt.
Für unser Hauptexperiment haben wir Ereignisdaten aus der MITRE ATT&CK-Auswertung des Mordor-Projekts von Roberto Rodriguez verwendet. Die ATT&CK-Auswertung hat FOSS/COTS-Tools wie etwa PSEmpire und CobaltStrike eingesetzt, um die APT3-Aktivität zu simulieren. Mit diesen Tools können improvisierte Techniken verkettet werden, um Aufgaben in den Bereichen Ausführung, Persistenz und Tarnung auszuführen.
Mit dem Framework wurden verschiedene mehrstufige Angriffsketten identifiziert, die ausschließlich Prozesserstellungsereignisse verwendet haben. Wir haben Ermittlung (Abb. 7) und Lateral Movement (Abb. 8) für die Überprüfung durch Analysten hervorgehoben.

Abb. 7: Prozesskette für Ermittlungstechniken

Abb. 8: Prozesskette für Lateral Movement
Datenreduktion
Mit unserem Ansatz können wir nicht nur abnormale Prozessketten entdecken, sondern auch die Vorteile des Verbreitungsmoduls beim Unterdrücken falscher Positivmeldungen demonstrieren. Mit dieser Kombination konnten wir die Menge an Ereignisdaten, die von Analysten geprüft werden müssen, drastisch reduzieren. Dazu einige Zahlen:
- Wir haben etwa 10K Prozesserstellungsereignisse pro Endpunkt im APT3-Szenario erhoben (5 Endpunkte insgesamt).
- Wir haben etwa 6 abnormale Communitys pro Endpunkt identifiziert.
- Jede Community bestand aus etwa 6-8 Ereignissen.
Blick in die Zukunft
Wir sind momentan dabei, diese Forschungsergebnisse aus unserer Machbarkeitsstudie als integrierte Lösung in Elastic Security zu entwickeln. Das vielversprechendste Feature ist dabei das Verbreitungsmodul. Es existieren zahlreiche Verbreitungsmodule für die Auftretenshäufigkeit von Dateien, aber mit der Verbreitung der Beziehungen zwischen Ereignissen können Sicherheitsexperten Bedrohungen auf neue Arten entdecken, indem sie danach suchen, was in ihrem Unternehmen selten/häufig vorkommt, und irgendwann auch anhand von Messungsdaten dazu, was global selten/häufig vorkommt.
Fazit
Wir haben dieses graphbasierte Framework (mit dem Namen ProblemChild) letztes Jahr auf den Konferenzen VirusBulletin und CAMLIS vorgestellt, um das benötigte Spezialwissen zum Schreiben von Detektoren zu reduzieren. Mit dem überwachten Machine Learning-Ansatz zur Erstellung eines gewichteten Graphen konnten wir Communitys aus scheinbar unzusammenhängenden Ereignissen zu größeren Angriffssequenzen gruppieren. Unser Framework verwendet bedingte Wahrscheinlichkeiten, um abnormale Communitys automatisch zu bewerten und um häufig auftretende Eltern-Kind-Ketten zu ignorieren. Im Hinblick auf beide Ziele können Analysten dieses Framework einsetzen, um Detektoren zu erstellen oder zu verfeinern, und um falsche Positivmeldungen im Lauf der Zeit zu reduzieren.