Viewing Activity in Elastic Cloud Enterprise
Elastic Cloud is our hosted service that lets you deploy and manage Elasticsearch and Kibana with ease. Now Elastic Cloud Enterprise (ECE) brings that same proven platform to your own datacenter. Since ECE shares the same code, it benefits from all the experience that Elastic has gained for more than 2 years of running clusters at scale, from handling node failures through to a streamlined UI.
At Elastic we manage thousands of clusters in our Cloud service using the same UI that's now part of ECE. Over time, we found that sometimes it was hard to tell what was happening at any given moment, simply due to the number of hosts, clusters and nodes involves. For example, if a host is starting to fail and it holds 50 nodes of 50 different clusters, all those nodes need to be migrated before we decommission the host.
To help us understand the current state of the system, we developed the Activity Feed and Cluster Activity view, both of which feature in Elastic Cloud Enterprise (ECE).
Activity Feed
When we're dealing with thousands of clusters, we can't simply display them all on a page and expect our software engineers and site reliability engineers (SREs) to deal with all the data - it simply doesn't scale. Instead, the UI shared by Elastic Cloud and ECE has the Activity Feed. It's a kind of an event log, showing what has happened recently to clusters and what actions are currently pending. Take this example:
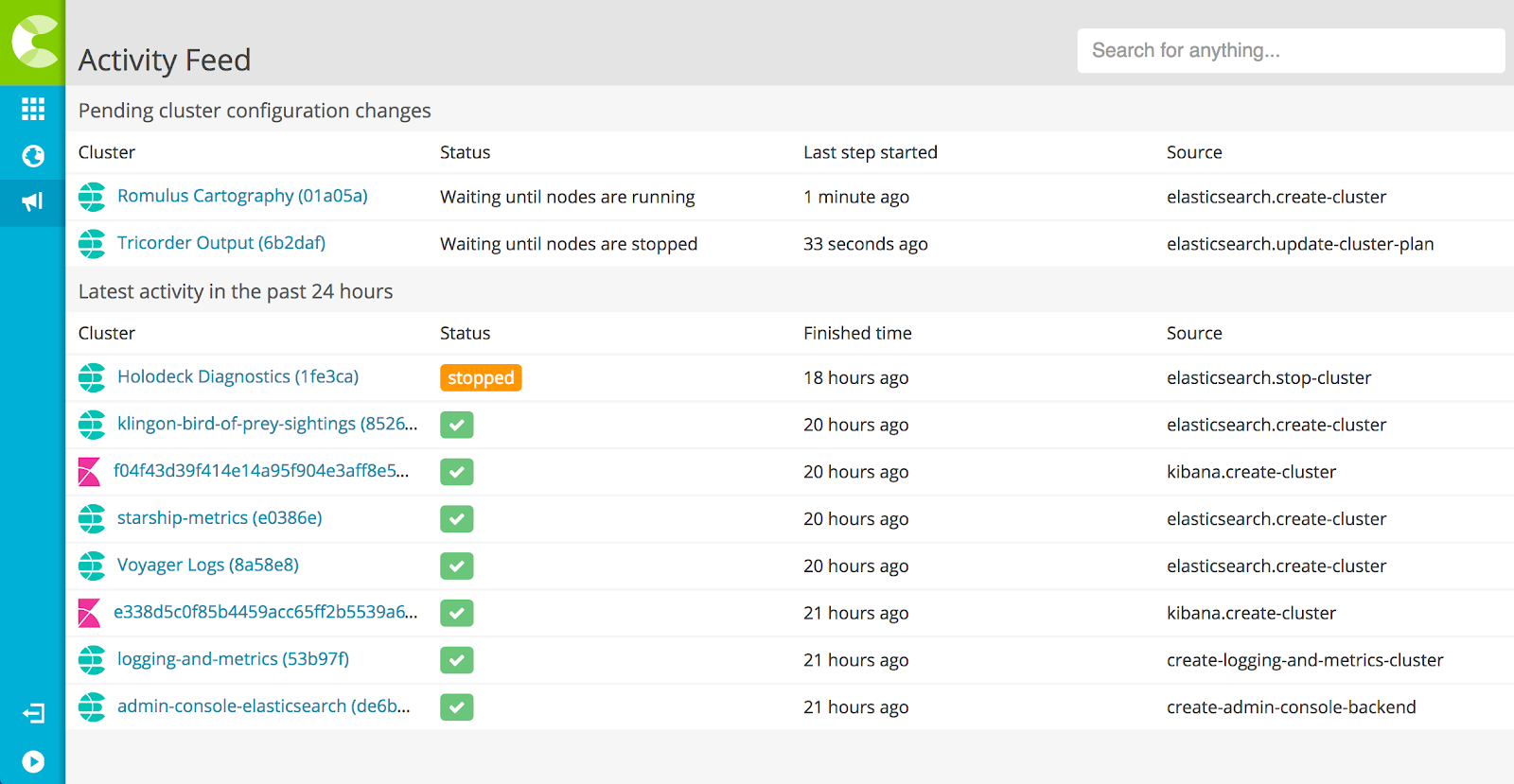
An SRE looking at this can tell at a glance that one cluster is in the process of being updated, one is being created, one has recently been stopped, and a number of other clusters have finished being created recently.
Cluster Activity
When it comes to understanding why a cluster is in a particular state, sometimes our engineers need to know the backstory, and they don't want to go hunting through logs, trying to piece together what changed. This is where the Cluster Activity view comes in:
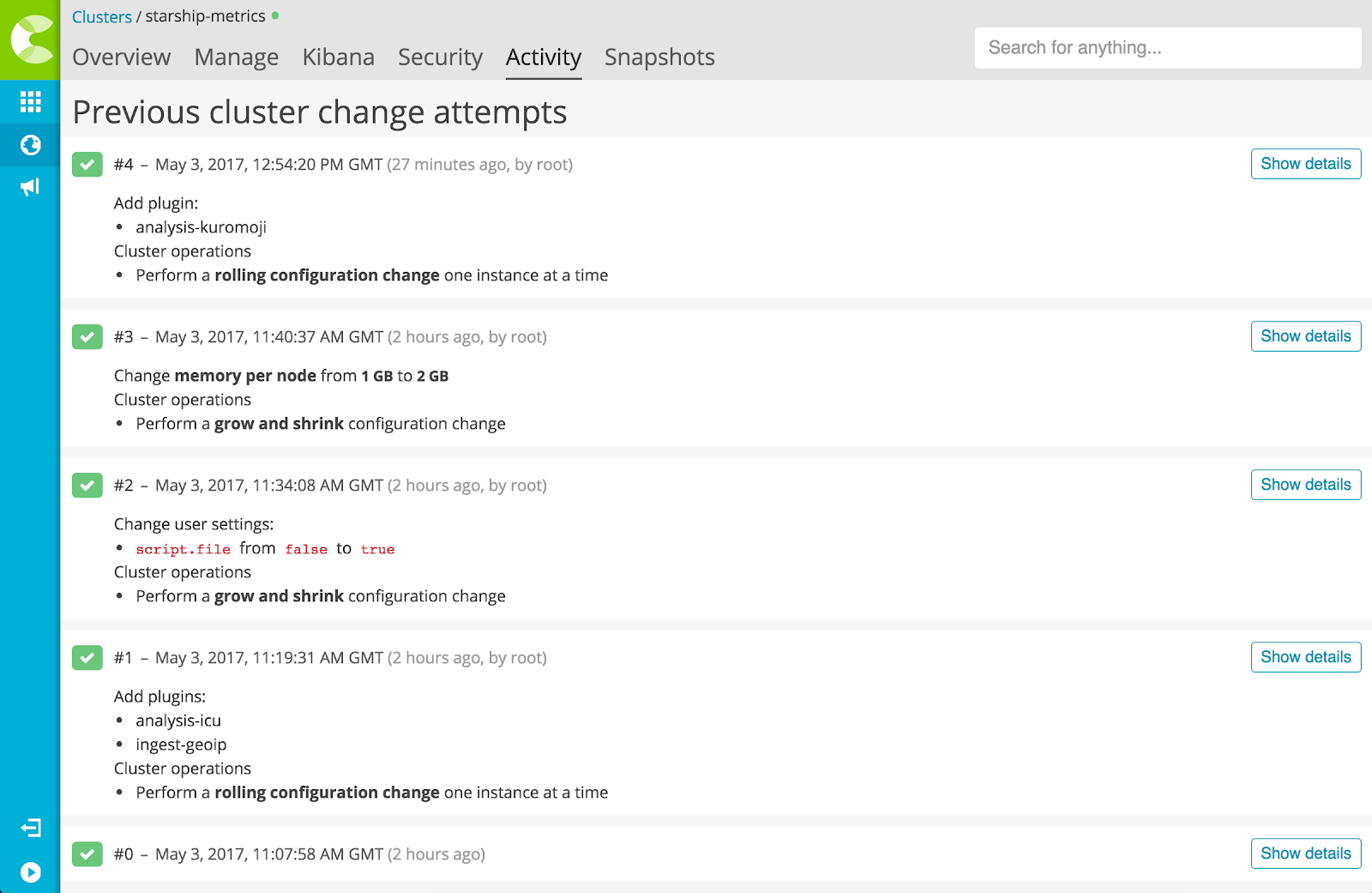
This view lists all the attempted changes to a cluster, and what those changes were. It includes attempted changes that didn't succeed - for example, attempting to grow a cluster when there isn't enough disk space to accommodate it. This gives our SREs a complete history of a cluster.
They can even drill right down and see diffs of the cluster's configuration, and how long each step of a reconfiguration took.
Future Improvements
We're always looking for ways to streamline our UIs and help our SREs do their job. For example, we're trialling ways to make the cluster history more visual and quicker to digest.
Find Out More
Learn more about Elastic Cloud Enterprise at elastic.co/cloud/enterprise. You can also read the documentation online.
Banner image credit: MusicOomph.com