The Go client for Elasticsearch: Working with data
In our previous two blogs, we provided an overview of the architecture and design of the Elasticsearch Go client and explored how to configure and customize the client. In doing so, we pointed to a number of examples available in the GitHub repository. The goal of these examples is to provide executable "scripts" for common operations, so it's a good idea to look there whenever you're trying to solve a specific problem with the client.
In this post, we’ll look at different ways of encoding and decoding JSON payloads, as well as using the esutil.BulkIndexer helper.
Encoding and decoding JSON payloads
One of the topics we have touched only briefly is working with the JSON payloads. The client, as mentioned in a previous blog, exposes the request and response body as an io.Reader, leaving any encoding and decoding to the calling code. Let's have a look at various approaches, starting with decoding (deserializing) the response body.
The easiest option is to simply use the encoding/json package from the standard library to decode the response into a map[string]interface{} or a custom a struct type; the main example provides a demonstration:
var r map[string]interface{}
res, _ := es.Search(es.Search.WithTrackTotalHits(true))
json.NewDecoder(res.Body).Decode(&r)
fmt.Printf(
"[%s] %d hits; took: %dms\n",
res.Status(),
int(r["hits"].(map[string]interface{})["total"].(map[string]interface{})["value"].(float64)),
int(r["took"].(float64)),
)
// => [200 OK] 1 hits; took: 10ms
While easy, this option is far from the most convenient or effective: notice how you have to type-cast each part of the structure in order to make the value useful in your code. There are better ways.
If all you're interested in is getting a couple of values from the response and using or displaying them, an attractive option is to use the tidwall/gjson package. It allows you to use the "dot notation" — familiar from the jq command line utility — to "pluck" the values from the response easily, as well as more efficiently:
var b bytes.Buffer
res, _ := es.Search(es.Search.WithTrackTotalHits(true))
b.ReadFrom(res.Body)
values := gjson.GetManyBytes(b.Bytes(), "hits.total.value", "took")
fmt.Printf(
"[%s] %d hits; took: %dms\n",
res.Status(),
values[0].Int(),
values[1].Int(),
)
// => [200 OK] 1 hits; took: 10ms
Yet another option, especially for more complex codebase, is to use a package such as mailru/easyjson, which uses code generation to efficiently encode and decode the JSON payload into custom struct types — please refer to the corresponding example and the associated model folder.
Note: Run the benchmarks in your own environment to compare the performance of different JSON packages.
When it comes to encoding (serializing) the request body, the easiest option is to use a type which supports the io.Reader interface, such as bytes.Buffer. Again, the main example provides a demonstration:
var b bytes.Buffer
b.WriteString(`{"title" : "`)
b.WriteString("Test")
b.WriteString(`"}`)
res, _ := es.Index("test", &b)
fmt.Println(res)
// => [201 Created] {"_index":"test","_id":"uFeRWXQBeb...
Since encoding structs or map[string]interface{} values is so frequent, the esutil package provides the helper which performs the serialization and conversion into io.Reader, so the equivalent of the code above would look like this:
type MyDocument struct {
Title string `json:"title"`
}
doc := MyDocument{Title: "Test"}
res, _ := es.Index("test", esutil.NewJSONReader(&doc))
fmt.Println(res)
// [201 Created] {"_index":"test","_id":"wleUWXQBe...
Note: The helper plays well with custom JSON encoders. If the type implements the esutil.JSONEncoder interface, the EncodeJSON() method is automatically used; otherwise, it falls back to the standard library.
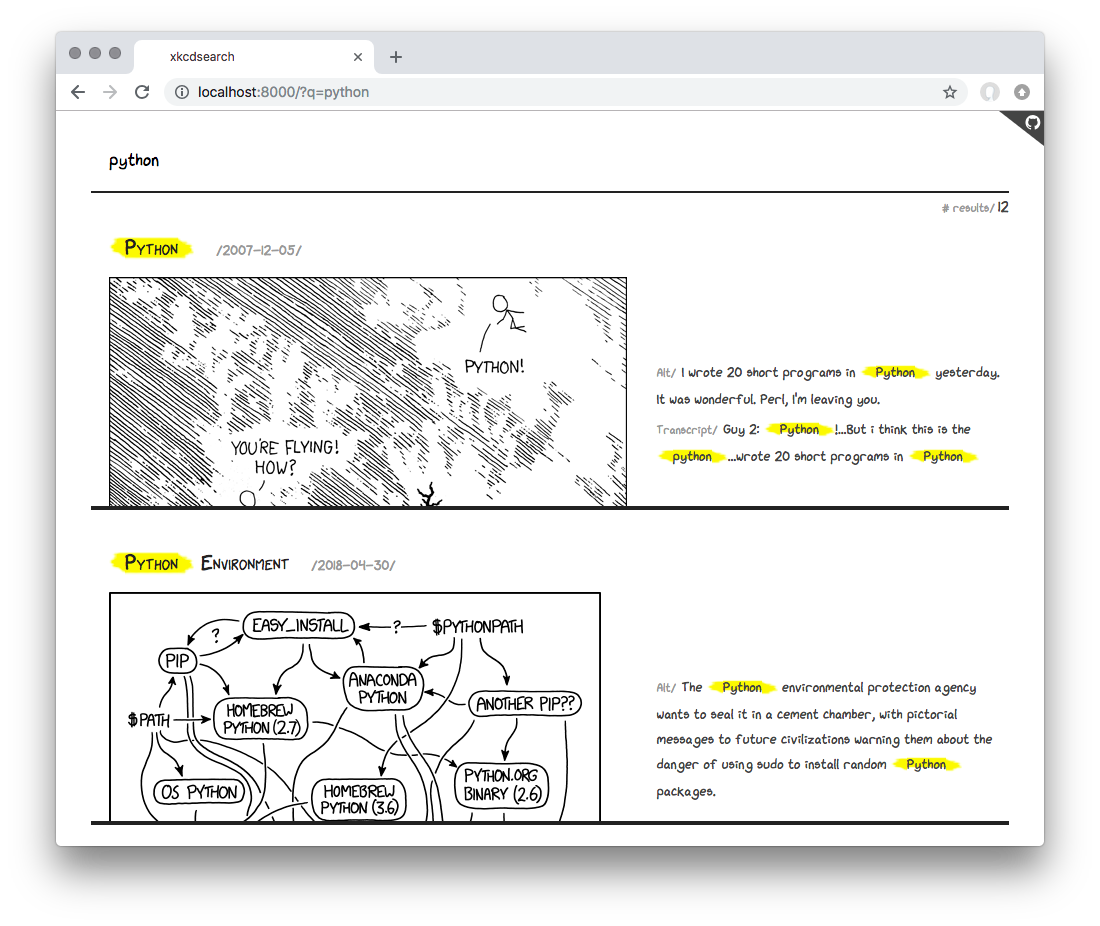
In order to understand how to use the client in a common application, invest some time into getting familiar with the comprehensive xkcdsearch example. It indexes information from the JSON API and allows you to search it on the command line and in the browser. It demonstrates a handful of techniques, such as embedding the client in your own type, building queries, parsing the responses, highlighting the matching phrases in results, mocking the client for tests, and many more. You can preview the application online.
Bulk indexing
One of the most common use cases for any Elasticsearch client is indexing documents into Elasticsearch as quickly and efficiently as possible. The most straightforward option, using the plain Elasticsearch Bulk API, comes with a lot of drawbacks: you have to manually prepare the meta and data pairs of the payload, divide the payload into batches, deserialize the response, inspect the results for errors, display a report, and so on. The default example in the repository demonstrates quite eloquently how involved it all is.
For that reason, the client provides a helper component, esutil.BulkIndexer, similar to bulk helpers in other clients:
$ go doc -short github.com/elastic/go-elasticsearch/v7/esutil.BulkIndexer
type BulkIndexer interface {
// Add adds an item to the indexer.
// ...
Add(context.Context, BulkIndexerItem) error
// Close waits until all added items are flushed and closes the indexer.
Close(context.Context) error
// Stats returns indexer statistics.
Stats() BulkIndexerStats
}
As you can see, the interface is rather minimal, and allows for adding individual items to the indexer, closing the indexing operations when there are no more items to add, and getting statistics about the operations. The component will take care of serializing the items and preparing the payload, sending it in batches, and parallelizing the operations, in a concurrent-safe fashion.
The indexer is configured through the esutil.BulkIndexerConfig struct passed as an argument to the constructor:
$ go doc -short github.com/elastic/go-elasticsearch/v7/esutil.BulkIndexerConfig
type BulkIndexerConfig struct {
NumWorkers int // The number of workers. Defaults to runtime.NumCPU().
FlushBytes int // The flush threshold in bytes. Defaults to 5MB.
FlushInterval time.Duration // The flush threshold as duration. Defaults to 30sec.
Client *elasticsearch.Client // The Elasticsearch client.
Decoder BulkResponseJSONDecoder // A custom JSON decoder.
DebugLogger BulkIndexerDebugLogger // An optional logger for debugging.
OnError func(context.Context, error) // Called for indexer errors.
OnFlushStart func(context.Context) context.Context // Called when the flush starts.
OnFlushEnd func(context.Context) // Called when the flush ends.
// Parameters of the Bulk API.
Index string
// ...
}
The NumWorkers field controls the level of parallelization, i.e., it sets the number of workers performing the flush operations. The FlushBytes and FlushInterval fields set the thresholds for the flush operation, based either on the payload content or the time interval. It is important to experiment with different values for these values, tailored to your data and environment.
The repository contains an executable script which allows you to easily experiment with different settings for these parameters. It is crucial to run it in a topology mirroring your production environment, following the best practices for benchmarking Elasticsearch. For example, on a common notebook, running against a local cluster, the indexer throughput is about 10,000 small documents per second. When the indexer runs on a dedicated machine, against a remote cluster, on a realistic hardware, the throughput nears 300,000 documents per second.
The Client field allows you to pass an instance of elasticsearch.Client, with any desired configuration for logging, security, retries, custom transport, and so on.
Following the common theme of extensibility, the Decoder field accepts a type implementing the esutil.BulkResponseJSONDecoder interface, making it possible to use a more efficient JSON encoder than the standard library's encoding/json.
The documents to be indexed are added as esutil.BulkIndexerItem to the indexer:
go doc -short github.com/elastic/go-elasticsearch/v7/esutil.BulkIndexerItem
type BulkIndexerItem struct {
Index string
Action string
DocumentID string
Body io.Reader
RetryOnConflict *int
OnSuccess func(context.Context, BulkIndexerItem, BulkIndexerResponseItem) // Per item
OnFailure func(context.Context, BulkIndexerItem, BulkIndexerResponseItem, error) // Per item
}
Let's put all these pieces of information together by walking through the code of the repository example. Clone the repository and run cd _examples/bulk && go run indexer.go to execute it locally.
The example indexes a data structure defined by the Article and Author types:
type Article struct {
ID int `json:"id"`
Title string `json:"title"`
Body string `json:"body"`
Published time.Time `json:"published"`
Author Author `json:"author"`
}
type Author struct {
FirstName string `json:"first_name"`
LastName string `json:"last_name"`
}
First, we'll create the Elasticsearch client, using a third-party package, cenkalti/backoff/, for exponential backoff implementation.
// Use a third-party package for implementing the backoff function
//
retryBackoff := backoff.NewExponentialBackOff()
es, err := elasticsearch.NewClient(elasticsearch.Config{
// Retry on 429 TooManyRequests statuses
//
RetryOnStatus: []int{502, 503, 504, 429},
// Configure the backoff function
//
RetryBackoff: func(i int) time.Duration {
if i == 1 {
retryBackoff.Reset()
}
return retryBackoff.NextBackOff()
},
// Retry up to 5 attempts
//
MaxRetries: 5,
})
Next, we'll create the bulk indexer:
// Create the BulkIndexer
//
bi, err := esutil.NewBulkIndexer(esutil.BulkIndexerConfig{
Index: indexName, // The default index name
Client: es, // The Elasticsearch client
NumWorkers: numWorkers, // The number of worker goroutines
FlushBytes: int(flushBytes), // The flush threshold in bytes
FlushInterval: 30 * time.Second, // The periodic flush interval
})
Let's create the data for indexing:
var articles []*Article
names := []string{"Alice", "John", "Mary"}
for i := 1; i <= numItems; i++ {
articles = append(articles, &Article{
ID: i,
Title: strings.Join([]string{"Title", strconv.Itoa(i)}, " "),
Body: "Lorem ipsum dolor sit amet...",
Published: time.Now().Round(time.Second).UTC().AddDate(0, 0, i),
Author: Author{
FirstName: names[rand.Intn(len(names))],
LastName: "Smith",
},
})
}
Note: The indexName, numWorkers, flushBytes and numItems variables are set with the command line flags; see go run indexer.go --help.
We can loop over the articles collection now, adding each item to the indexer:
var countSuccessful uint64
start := time.Now().UTC()
for _, a := range articles {
// Prepare the data payload: encode article to JSON
//
data, err := json.Marshal(a)
if err != nil {
log.Fatalf("Cannot encode article %d: %s", a.ID, err)
}
// Add an item to the BulkIndexer
//
err = bi.Add(
context.Background(),
esutil.BulkIndexerItem{
// Action field configures the operation to perform (index, create, delete, update)
Action: "index",
// DocumentID is the (optional) document ID
DocumentID: strconv.Itoa(a.ID),
// Body is an `io.Reader` with the payload
Body: bytes.NewReader(data),
// OnSuccess is called for each successful operation
OnSuccess: func(ctx context.Context, item esutil.BulkIndexerItem, res esutil.BulkIndexerResponseItem) {
atomic.AddUint64(&countSuccessful, 1)
},
// OnFailure is called for each failed operation
OnFailure: func(ctx context.Context, item esutil.BulkIndexerItem, res esutil.BulkIndexerResponseItem, err error) {
if err != nil {
log.Printf("ERROR: %s", err)
} else {
log.Printf("ERROR: %s: %s", res.Error.Type, res.Error.Reason)
}
},
},
)
if err != nil {
log.Fatalf("Unexpected error: %s", err)
}
}
The indexer will send the items to the cluster in batches, based on the configured thresholds. In our case, we have exhausted the collection, so we'll close the indexer to flush any remaining buffers:
if err := bi.Close(context.Background()); err != nil {
log.Fatalf("Unexpected error: %s", err)
}
The indexer collects a number of metrics via the esutil.BulkIndexerStats type:
$ go doc -short github.com/elastic/go-elasticsearch/v7/esutil.BulkIndexerStats
type BulkIndexerStats struct {
NumAdded uint64
NumFlushed uint64
NumFailed uint64
NumIndexed uint64
NumCreated uint64
NumUpdated uint64
NumDeleted uint64
NumRequests uint64
}
Let's use it to display a simple report about the whole operation, using the dustin/go-humanize package for better readability:
biStats := bi.Stats()
dur := time.Since(start)
if biStats.NumFailed > 0 {
log.Fatalf(
"Indexed [%s] documents with [%s] errors in %s (%s docs/sec)",
humanize.Comma(int64(biStats.NumFlushed)),
humanize.Comma(int64(biStats.NumFailed)),
dur.Truncate(time.Millisecond),
humanize.Comma(int64(1000.0/float64(dur/time.Millisecond)*float64(biStats.NumFlushed))),
)
} else {
log.Printf(
"Sucessfuly indexed [%s] documents in %s (%s docs/sec)",
humanize.Comma(int64(biStats.NumFlushed)),
dur.Truncate(time.Millisecond),
humanize.Comma(int64(1000.0/float64(dur/time.Millisecond)*float64(biStats.NumFlushed))),
)
}
// => Successfully indexed [10,000] documents in 1.622s (6,165 docs/sec)
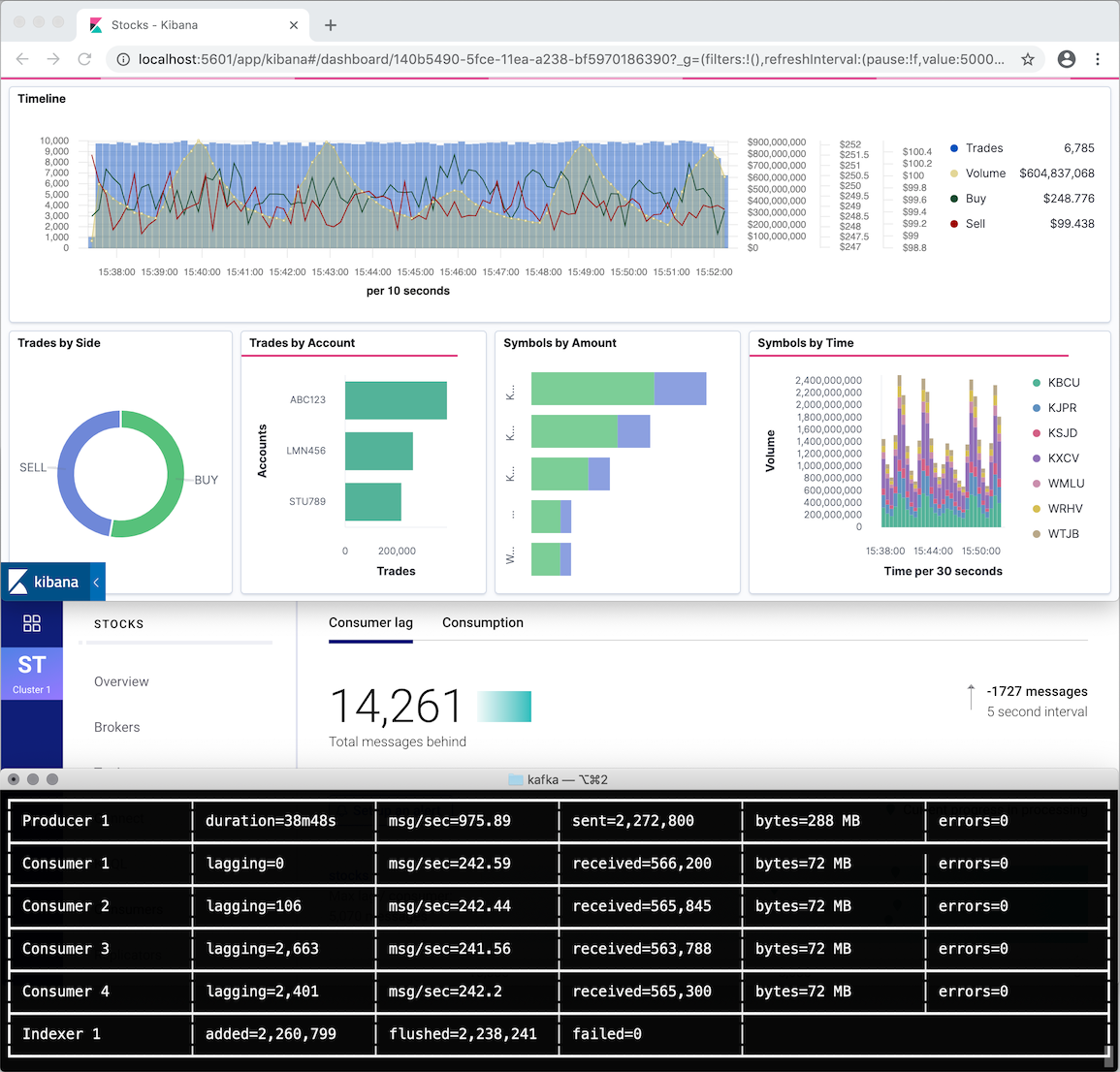
This example illustrates the inner workings of the bulk indexer and the available configuration options. To see how to use it in a realistic application, have a look at the _examples/bulk/kafka example in the repository. It uses Docker to launch a full environment with Zookeeper, Kafka, Confluent Control Center, Elasticsearch, APM Server, and Kibana, and demonstrates ingesting data consumed from a Kafka topic. To try it locally, just follow the instructions in the repository.
Wrapping up
In this series of blogs, we've introduced the architecture and design of the client, explained the various configuration and customization options, and finally saw how to encode and decode JSON payloads and use the bulk helper.
Hopefully, the examples in the Go client for Elasticsearch repository will help you find solutions to common problems and use the client effectively. If you have any questions or comments, just open an issue in the repository.