Introducing Ember: An Open Source Classifier And Dataset
Editor’s Note: Elastic joined forces with Endgame in October 2019, and has migrated some of the Endgame blog content to elastic.co. See Elastic Security to learn more about our integrated security solutions.

Over the last decade, machine learning has achieved truly impressive results in fields such as optical character recognition, image labeling, and speech recognition. Advancements in hardware and rapidly growing datasets have been instrumental in this progress, as has the presence of public, open-source, benchmark datasets to track advancements in the field. Although there is no shortage of data in security, many applications of machine learning in the security industry lack similar benchmark datasets because of the presence of personally identifiable information, sensitive network infrastructure information, or private intellectual property.
Today, Endgame is releasing ember to address this lack of open-source datasets in the domain of static malware detection. Ember (Endgame Malware BEnchmark for Research) is an open source collection of 1.1 million portable executable file (PE file) sha256 hashes that were scanned by VirusTotal sometime in 2017. The dataset includes metadata, derived features from the PE files, and a benchmark model trained on those features. Importantly, ember does NOT include the files themselves so that we can avoid releasing others’ intellectual property. With this dataset, researchers can now quantify the effectiveness of new machine learning techniques against a well defined and openly available benchmark.
The Data
The 1.1 million samples include 900K training samples (300K malicious, 300K benign, 300K unlabeled) and 200K test samples (100K malicious, 100K benign). Each sample includes the sha256 hash of the file, the month the files was first seen, a label, and features derived from the file. A date histogram in figure 1 graphs the training data compared to the test data. Including the date with each file and structuring the train/test split this way is important because of the evolving and adversarial nature of the static malware detection problem. Defenders must train a model at some point in time with all available information, but the goal is to best identify benign and malicious files that have not been seen yet. On top of that challenge, attackers are actively searching for samples that fool your model.
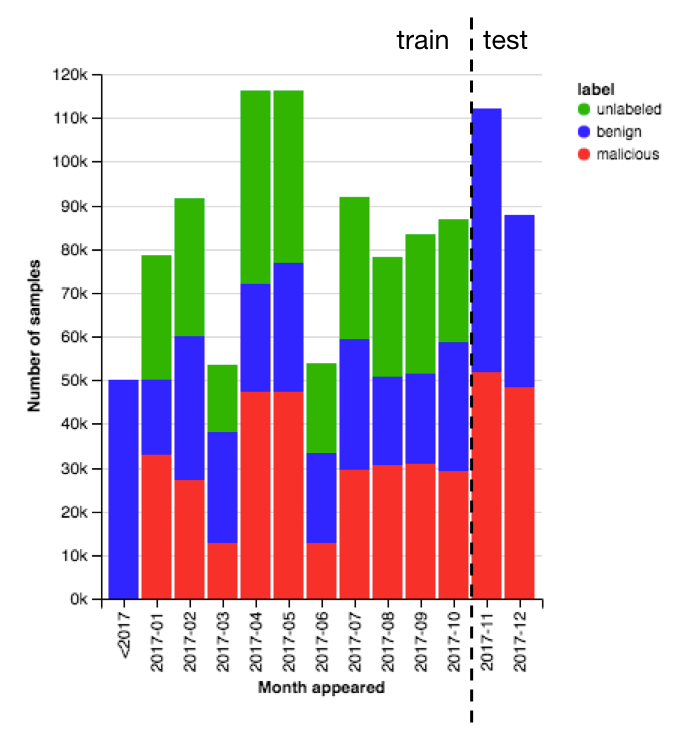
Figure 1: Distribution of dates that ember files were first seen
Along with the data, we are releasing a repository on GitHub that makes it very easy to work with the data. The ember repository defines the software environment that the benchmark model was trained in and allows anyone to reproducibly train it themselves. A Jupyter notebook is also provided that generates graphics and performance information related to the benchmark model. The process of how the derived features are calculated from the PE files is explicitly defined in code. With this, anyone can download the benchmark model and then use the repository to classify new PE files.
The Model
The benchmark ember model is a gradient boosted decision tree (GBDT) trained with LightGBM with default model parameters. The performance of this model on the test set is shown in figure 2. The area under the ROC curve is a good method for comparing binary classifiers and the ember benchmark model achieves a score of 0.9991123 on the test set. There are many easy ways to improve this score with the same GBDT algorithm including optimizing model parameters, running feature selection, or engineering better features. As feature-less deep learning techniques work to match the performance of GBDTs in the domain of static malware classification, ember can provide a benchmark that measures their progress towards that goal.
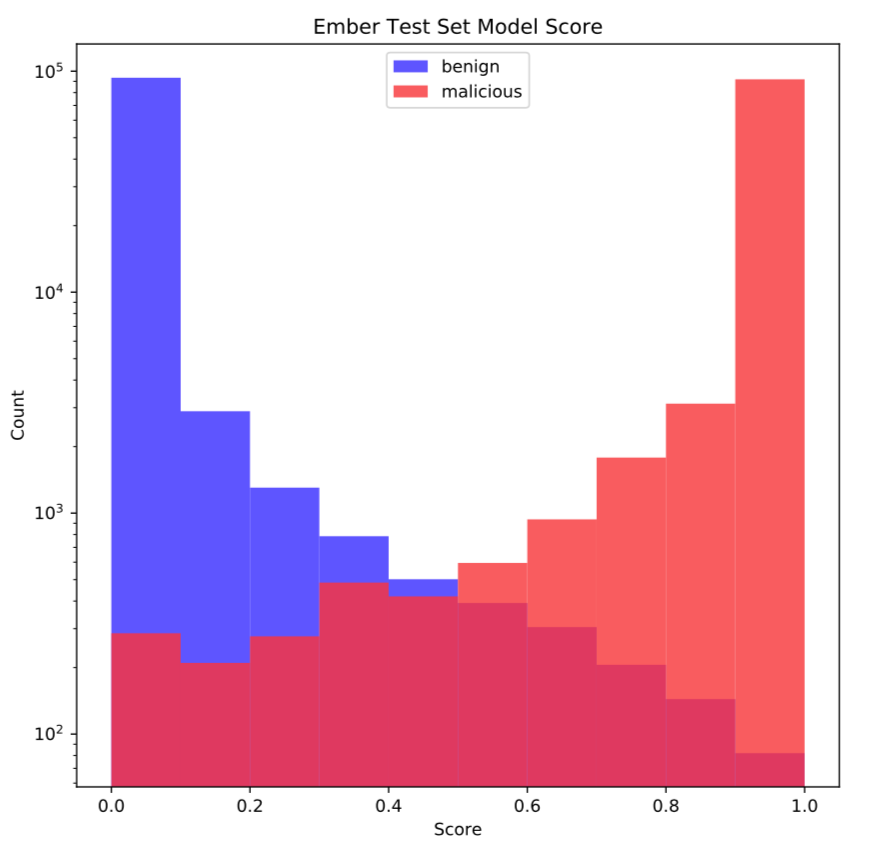
Figure 2: Ember model scores on the test set files
Spurring Future Research
Despite this ease of use, we have to advise against using the ember model as your antivirus engine. This is a research model and not a production model like Endgame MalwareScore®. The ember model is not optimized, it is not constantly updated with new data, and performs worse than most production systems available. The purpose of the ember model is to provide comparison performance data and a jumping off point for future research. With the data it provides, researchers can demonstrate the benefits of feature selection, model parameter optimization, feature engineering, and semi-supervised learning in classifying the test set. Other institutions which have independent access to the files themselves can also demonstrate the benefits of new and improved features or featureless neural network based models. Last year at BlackHat, we talked about how machine learning could aid attackers in bypassing antivirus engines. This benchmark model can provide a good target for future research in that field.
For more details, take a look at our recently published arXiv paper. Also, I’ll be presenting more details about ember at BSidesSF or BSidesCharm, so please stop by and say hi if you’ll be attending.