Why assigning custom data view IDs matters in Kibana


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
I was recently introduced to a TV show called Young Sheldon. I’ve never seen The Big Bang Theory, so I wasn’t sure what to expect. That said, this post isn’t really about the show. I’ll be using a dataset related to it, but the actual data could’ve been anything: business-related, observability-related, security-related — you name it. For those who know me, you know I’m always going to find a way to infuse a little semi-chaotic fun. So, let’s get into it.
The most slept-on feature in Kibana
I’m about to let you in on a little secret. This is one of the most overlooked features in Kibana. It’s something I’m always encouraging my customers to use, and I consider it to be a best practice.
Insert dramatic drumroll here. One of the most unexpectedly powerful features in Kibana is the ability to assign custom data view IDs when creating data views.
Before I go full tangent mode, let me give you a quick overview of where this is going:
A little about me … and a few things I’ve seen
A use case to set the stage
Why things tend to go sideways
A step-by-step walkthrough with Young Sheldon examples
Stuff that trips teams up
A few suggestions (Honestly, you could skip everything below, trust me, and just do this part.)
Fin. Channel your inner Aaron Pierre and hit the Mufasa dance.
As a consulting architect at Elastic, I get to work directly with customers every day. I’ve used several SIEM-like tools throughout my career, and I know how complex some solutions can be — custom syntaxes that feel like code, intimidating interfaces, slow onboarding, and delayed ROI. That’s why one of my favorite things about working with Kibana is watching users discover how intuitive it is.
The moment the data is ingested and usable, users are in it. Dashboards and visualizations pop up everywhere. There’s a sense of excitement and creativity. But with that energy also comes a bit of chaos.
Here’s what I often see: Someone builds a dashboard just to get familiar with Kibana. Then they realize it’s actually really good. So they started using it in production. And there’s nothing wrong with that! But … here's where things start to unravel: Data views get created ad hoc, often with similar and seemingly duplicate attributes.
Why duplicate data views matter
Let me walk you through a scenario to illustrate how data views, and their custom data view IDs, can affect visualizations and dashboards.
3 users, 3 data views, 1 dataset
Meet our users: Sheldon, Missy, Georgie, and Paige. Sheldon, Missy, and Georgie are new and enthusiastic security analysts, eager to explore and contribute. Paige, on the other hand, is a seasoned admin and subject matter expert with a strong focus on process and standardization, and a clear dislike for digital clutter. Together, they work aboard the Starship Enterprise.
Monday – Sheldon:
Sheldon is poking around in Kibana, specifically interested in the zeek logs. He notices there's no existing data view for them, so he creates one called Zeek, setting the index pattern to zeek-*. Kibana assigns it a random data view IDs like e4f6268b-9c4a-4f36-8a56-49ef18fbd147. He starts building dashboards and visualizations and, impressed with the results, considers them production-ready. His team starts using them. They’re loving it. Stamp of approval.
Tuesday – Missy:
Missy logs into Kibana for the first time. She knows Zeek data has been ingested but doesn’t realize Sheldon already made a data view. Eager to dive in, she creates her own called Zeek Logs — again pointing to zeek-*. Kibana assigns it a different data view ID like 04851901-723f-41fe-bdc7-3917b41aa1f7. She starts exploring in Discover, builds some visualizations, and leaves them in place for future refinement.
Wednesday – Georgie:
Georgie logs in and is new to Kibana, too. Excited by the UI, he jumps right in. You guessed it — he creates another data view for zeek-*, this time naming it Dem Zeeky Zeek Logs, with yet another randomly generated data view ID like b331a8a5-d7e1-412d-b83f-c5d9672ab0c1. And off he goes, building his own visualizations.
Thursday – Paige:
Paige, the team SME, notices multiple data views for the same Zeek index. She assumes they’re redundant and starts cleaning house, deleting Sheldon’s and Georgie’s data views. From her perspective, she’s just tidying things up.
Friday – Chaos:
Sheldon and Georgie log back in, only to find their dashboards are broken. The visualizations are no longer functional. Why? Because the visualizations in the dashboards were tied to the now-deleted data views associated with unique, randomly generated data view IDs. Meanwhile, Missy’s dashboards still work just fine.
Why did this happen?
This all boils down to how Kibana handles saved objects like data views.
When a user creates visualizations, dashboards, data views, etc., they are saved in Kibana as saved objects. These objects have relationships. In this case, the visualizations are directly tied to the data view ID of the data view used to create them. So when Paige deleted the data views, she unknowingly broke the relationship between the visualizations and the specific custom data view IDs they relied on.
Now here’s the kicker — and why I believe assigning custom data view IDs should be considered a best practice.
As previously stated, by default, Kibana assigns long, randomly generated data view IDs to data views. These values are arbitrary and difficult for most users to remember for reuse. The problem? When a data view is deleted, any visualizations that were built using it continue to reference that now-missing data view IDs.
Technically, a user could recreate the deleted data view and manually assign it the same randomly generated data view ID — if they had saved it somewhere. Doing so would restore the broken visualizations. But notice: Even in that recovery scenario, the solution requires assigning a custom data view ID.
So why not start there?
By creating an intuitive custom data view ID naming standard from the beginning, like zeek, you significantly improve the workflow. Here’s how:
-
Avoid duplicate data views: Kibana won’t allow multiple data views to use the same custom data view ID. If someone tries to create a new one with the same ID, they’ll be alerted that it already exists.
-
Simplify recovery: If a data view is accidentally deleted, a user can quickly recreate it using the same custom data view ID (e.g., zeek) instead of trying to remember a complex value like b331a8a5-d7e1-412d-b83f-c5d9672ab0c1.
-
Enable better scalability: When your environment grows and you’re managing hundreds of visualizations, this small practice makes a huge difference. Without it, users may unknowingly create multiple Zeek-related data views with different data view IDs and spread them across dashboards. If some of those get deleted, the affected visualizations break — leading to confusion and wasted time.
This may seem like a small detail you can ignore, but I’ve seen teams get tripped up by this exact issue more times than I can count. Things get messy fast. Assigning custom data view IDs from the start brings order to that chaos.
A walkthrough using Young Sheldon data (because why not?)
Sheldon creates a data view using the demo-young-sheldon index. The following parameters are used:
-
Name: demo-young-sheldon
-
Index Pattern: demo-young-sheldon
- Custom Data View ID: demo-young-sheldon
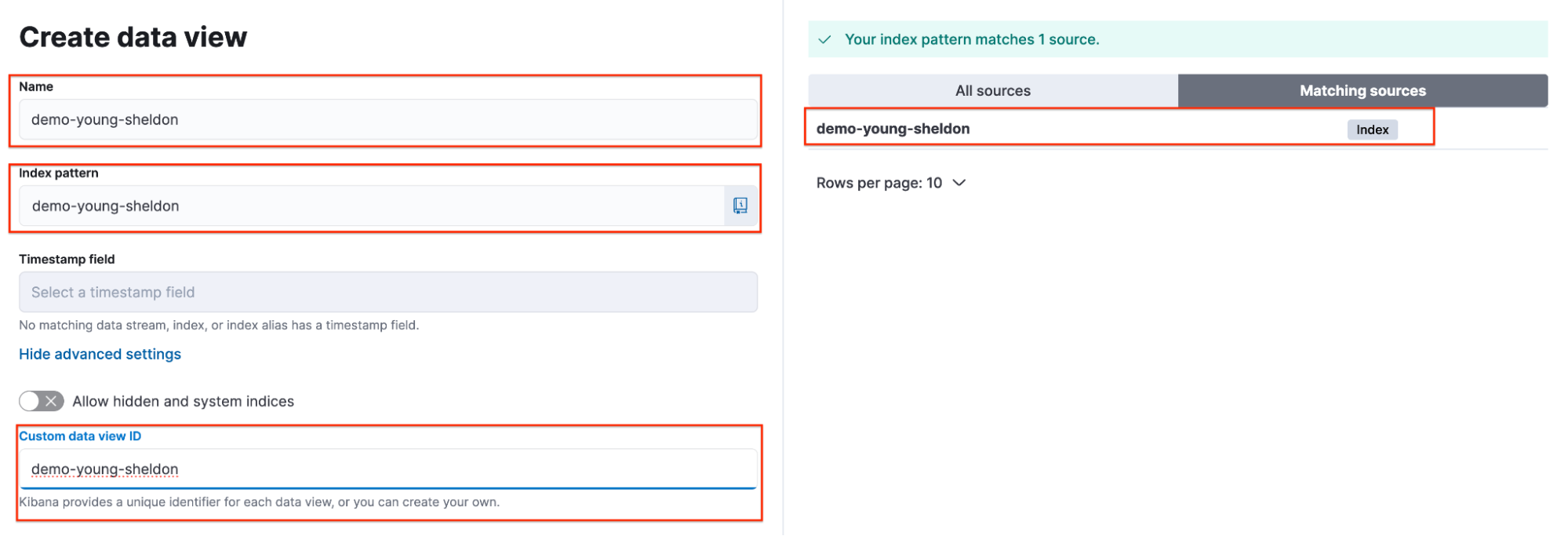
Sheldon selects the data view and confirms that the custom data view ID is correctly set.
Note: This can be quickly verified through the browser URL.
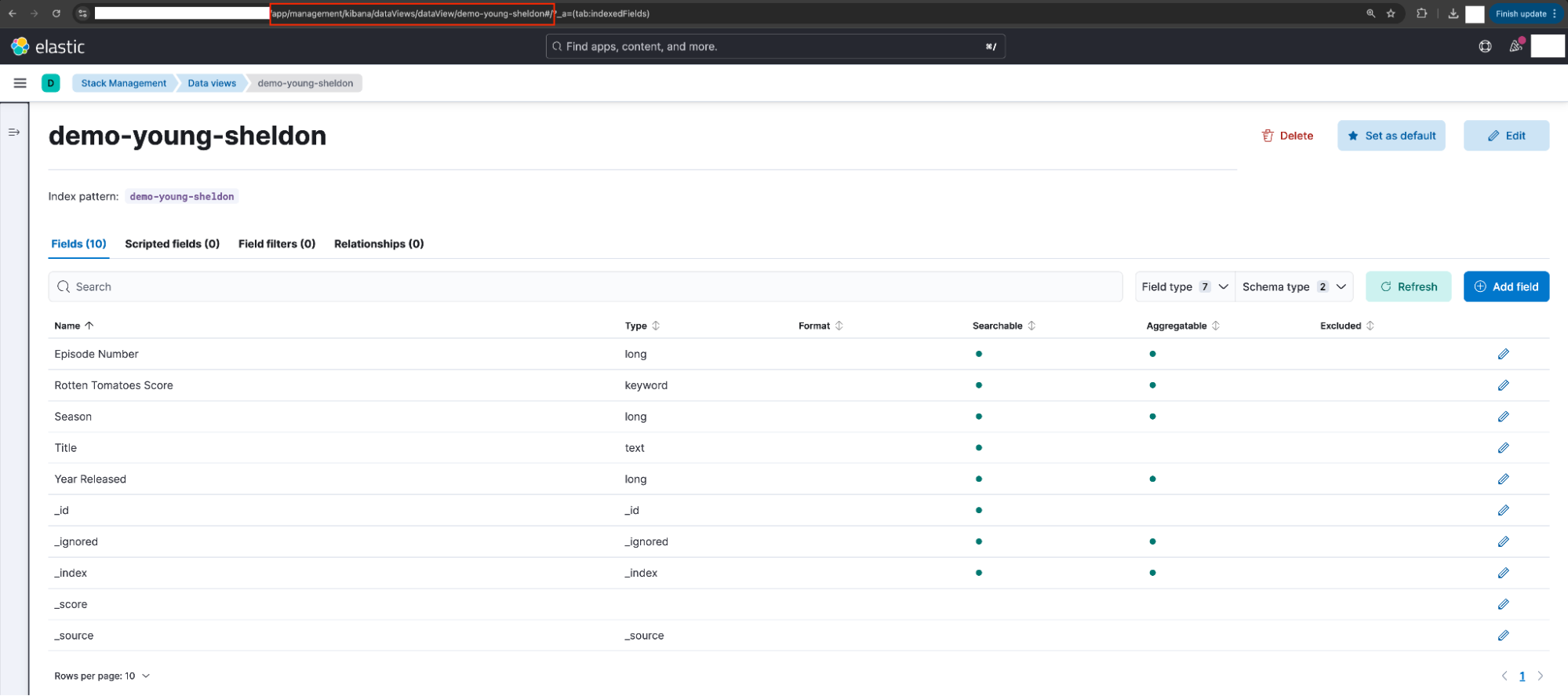
Georgie creates a data view using the demo-young-sheldon index. The following parameters are used:
Name: demo-young-sheldon-test
Index Pattern: demo-young-sheldon
- Custom Data View ID: N/A (Blank)
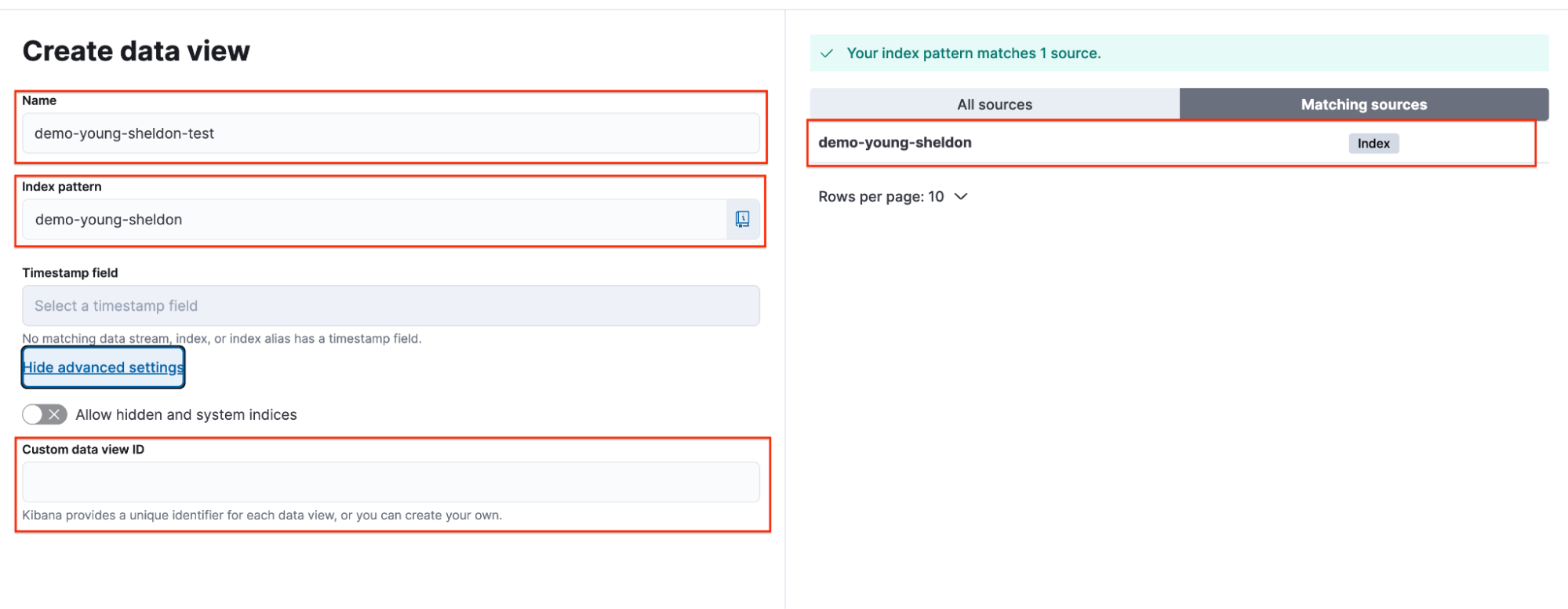
Georgie selects the data view and confirms that the data view ID, because it was left blank, has been set to the random automatically generated string.
Note: This can be quickly verified through the browser URL.
Sheldon (demo-young-sheldon) and Georgie (demo-young-sheldon-test) each create visualizations using their respective data views and add them to a shared dashboard.
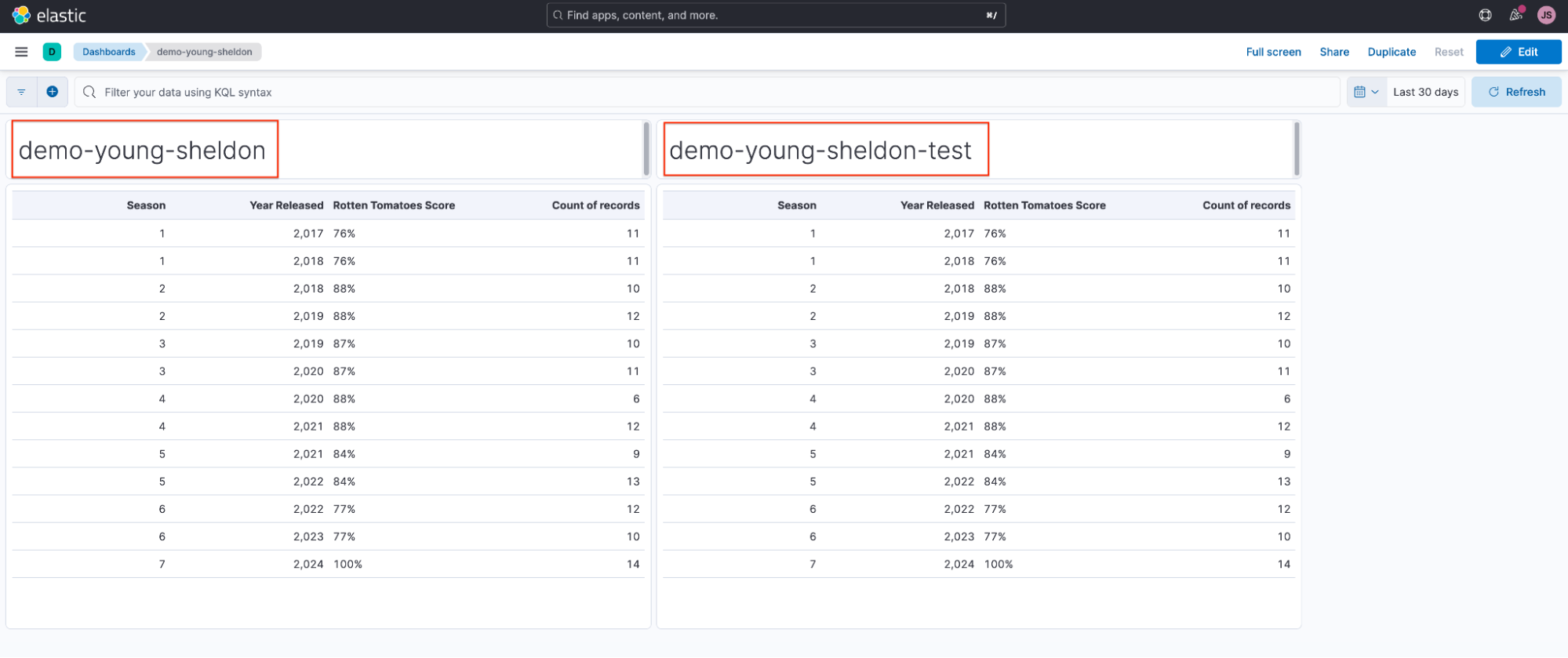
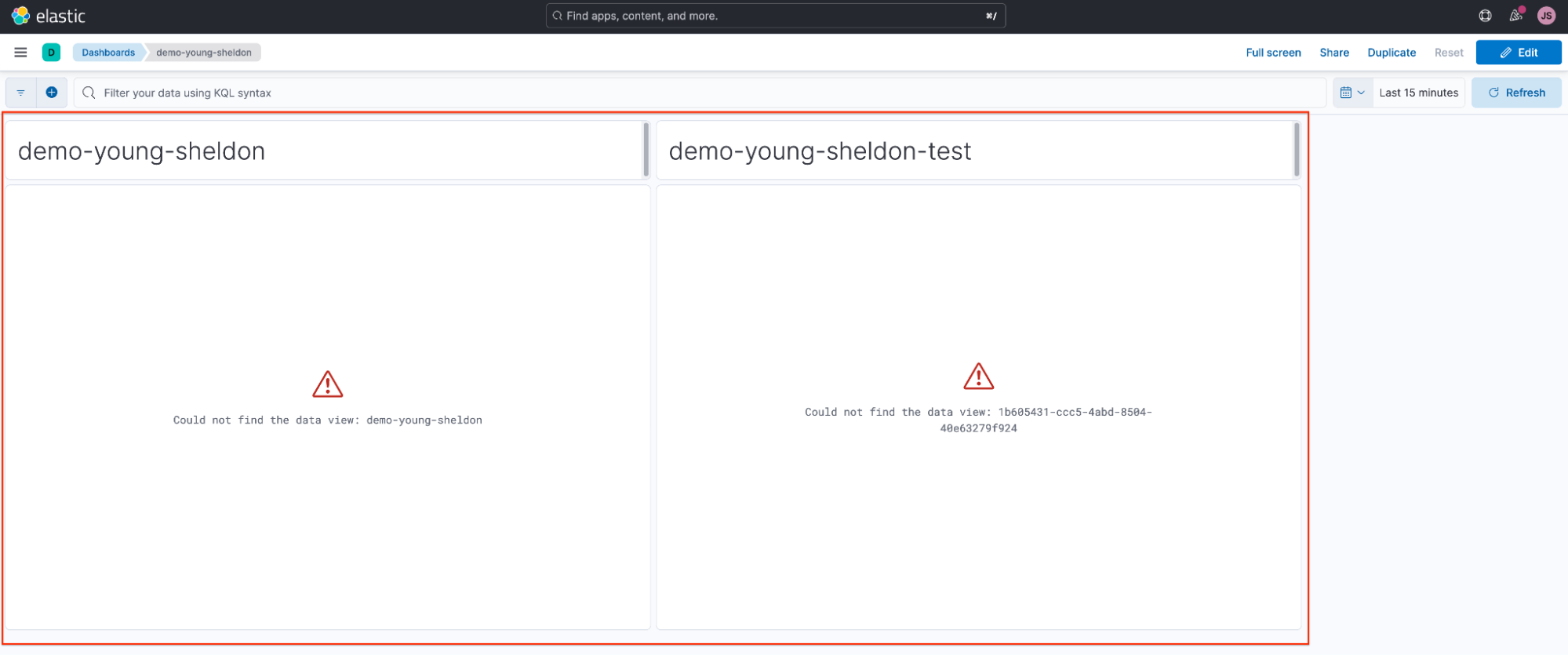
Sheldon and Georgie accidentally delete their data views and when they navigate back to the dashboard, they notice their visualizations are broken.
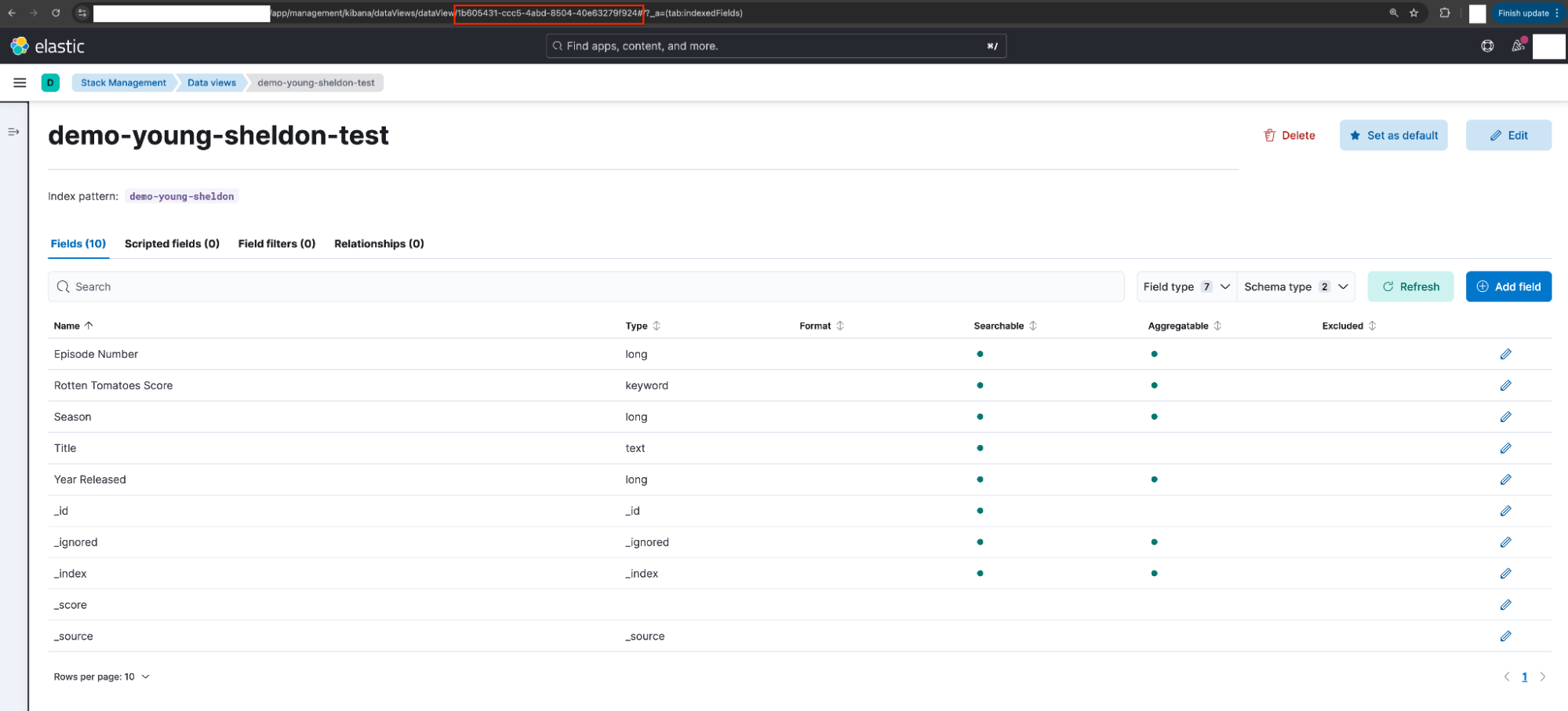
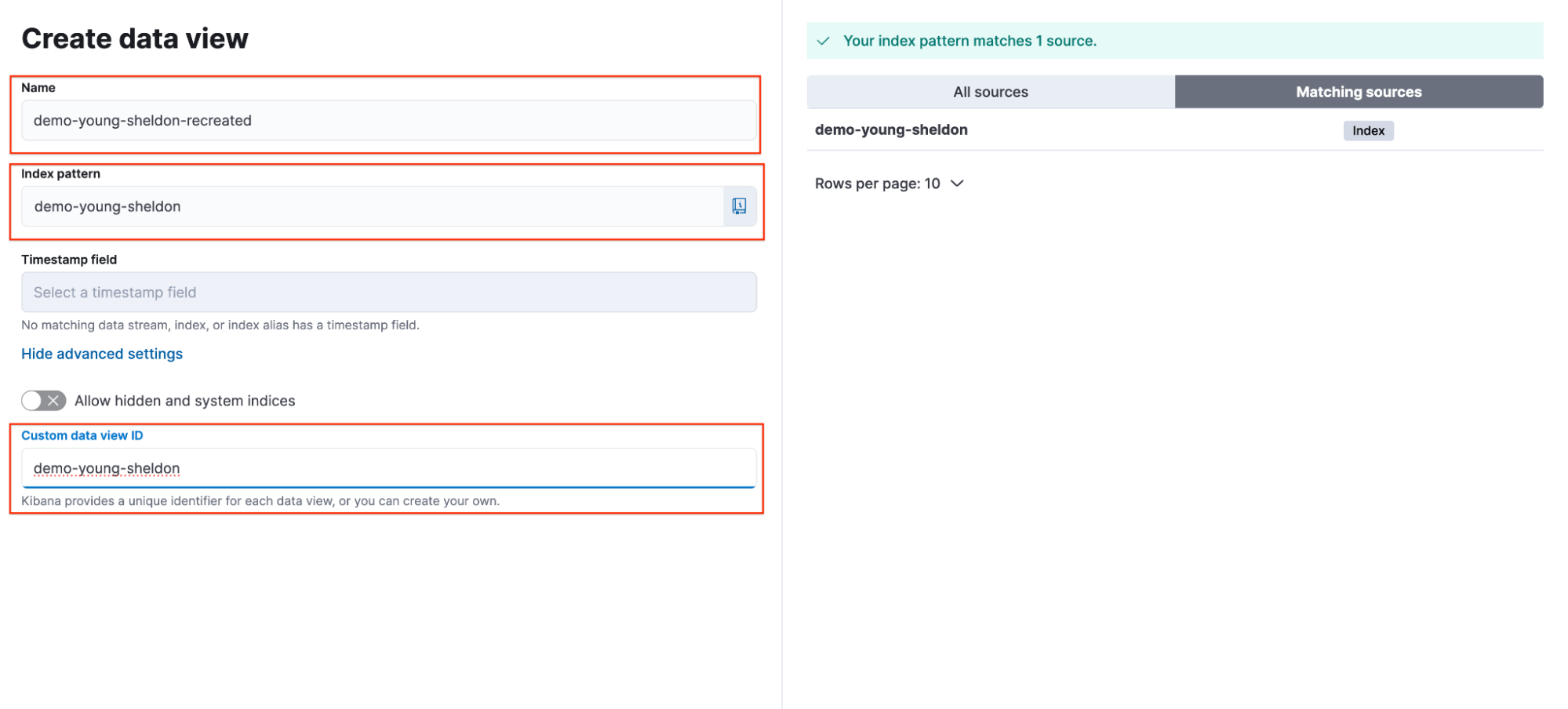
Sheldon strategically assigned a custom data view ID to his data view, making recovery simple. To restore his visualization, he simply recreates the data view and reuses the same custom data view ID: demo-young-sheldon.
The following parameters are used:.
-
Name: demo-young-sheldon-recreated
-
Index Pattern: demo-young-sheldon
-
Custom Data View ID: demo-young-sheldon
Note: In this walkthrough, I’ve slightly modified the data view name for clarity and to differentiate it from earlier steps (Name: demo-young-sheldon → demo-young-sheldon-recreated).
Sheldon returns to the shared dashboard and confirms that his visualization has been successfully restored.
Georgie can follow a similar process to restore his visualization. However, he must set the custom data view ID to match the randomly generated string shown in the image on the right.
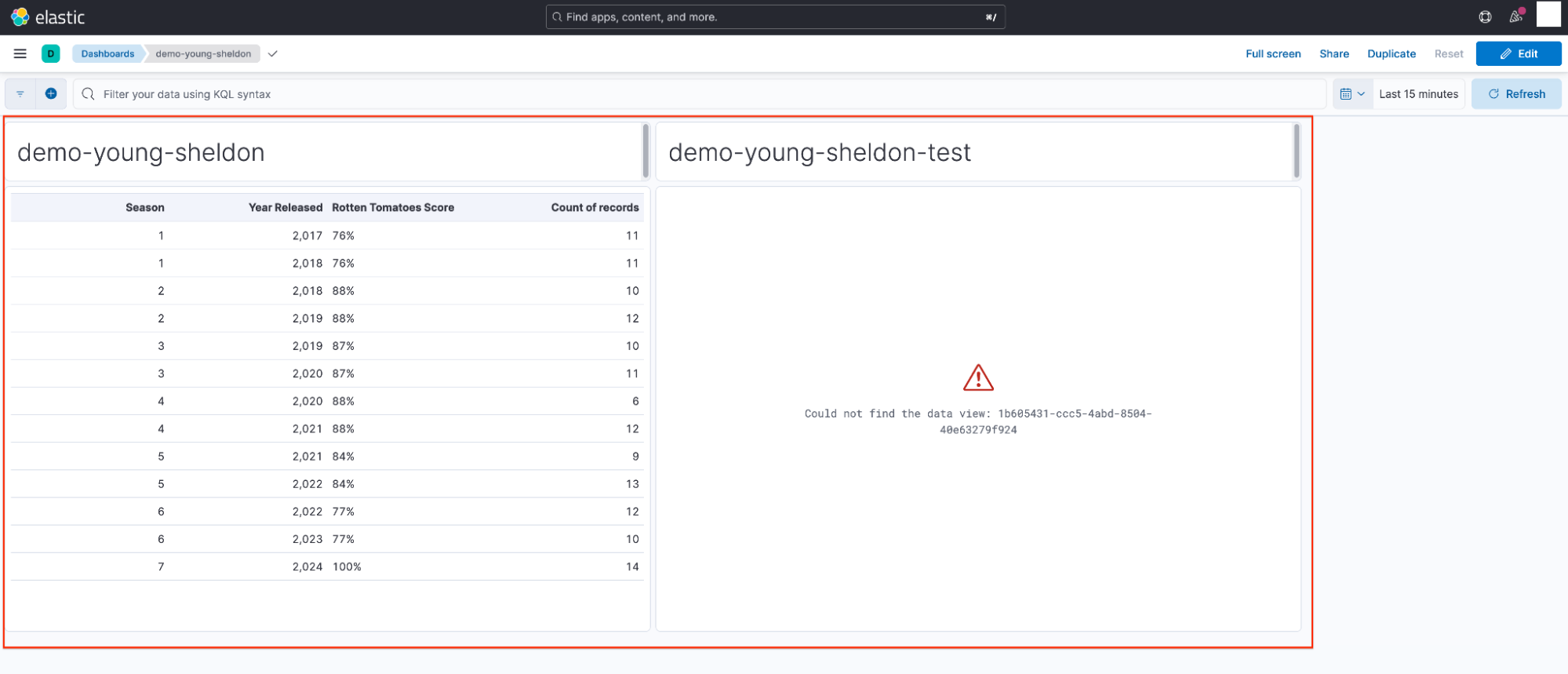
You're thinking it and you're not entirely wrong (but not right either)
You might be thinking, "Well, I could just recreate the `demo-young-sheldon-test data view and manually assign the same randomly generated data view ID referenced in the visualization."

And you’d be absolutely right. That approach does work — in theory.
But now, let’s scale the scenario.
Imagine you have 30 users, and 10 of them each create their own variation of the demo-young-sheldon data view, each with a different, randomly generated data view ID. They build hundreds of visualizations using these various data views, which are then distributed across multiple dashboards.
Later, someone reviewing the environment sees 10 data views with similar names and the same index pattern associated with all of them. Assuming they’re duplicates, they delete 9 of them unaware that each one is uniquely tied to specific visualizations via data view ID.
Now, you’ve got a problem. Many of these visualizations are spread across multiple dashboards, and in many cases, the users are unaware that the visualizations within a single dashboard are not using the same data view. For example, a user notices the following data views: zeek-1, zeek-2, zeek-3, zeek-4, and zeek-5.
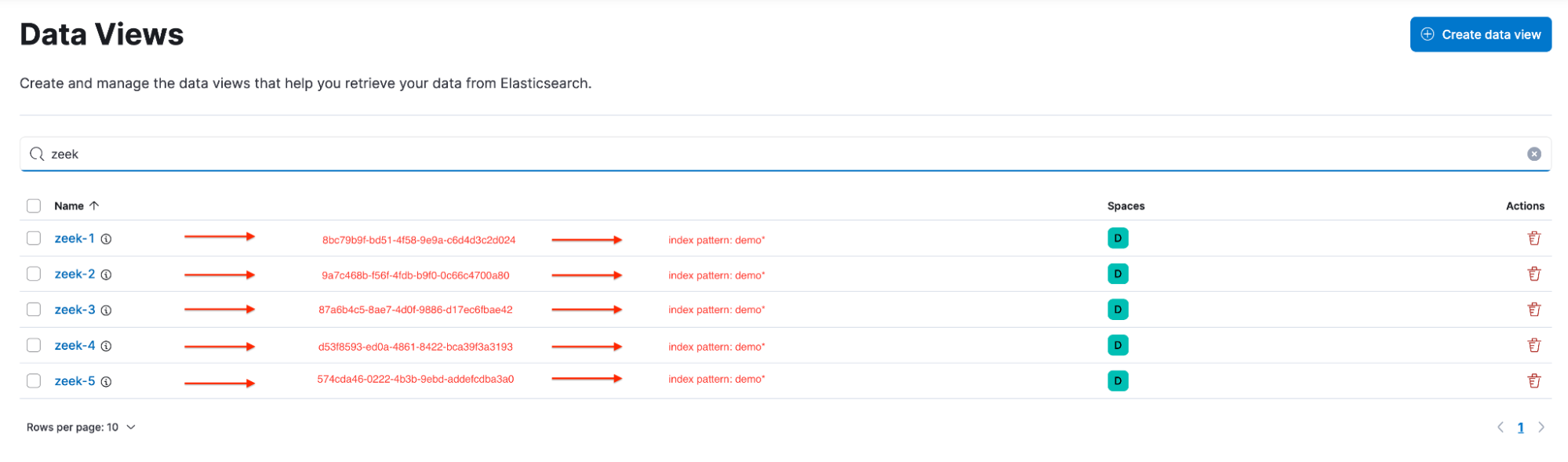
Since all of the data views point to the same index pattern, users often don’t think twice when building a visualization and adding it to a shared dashboard.
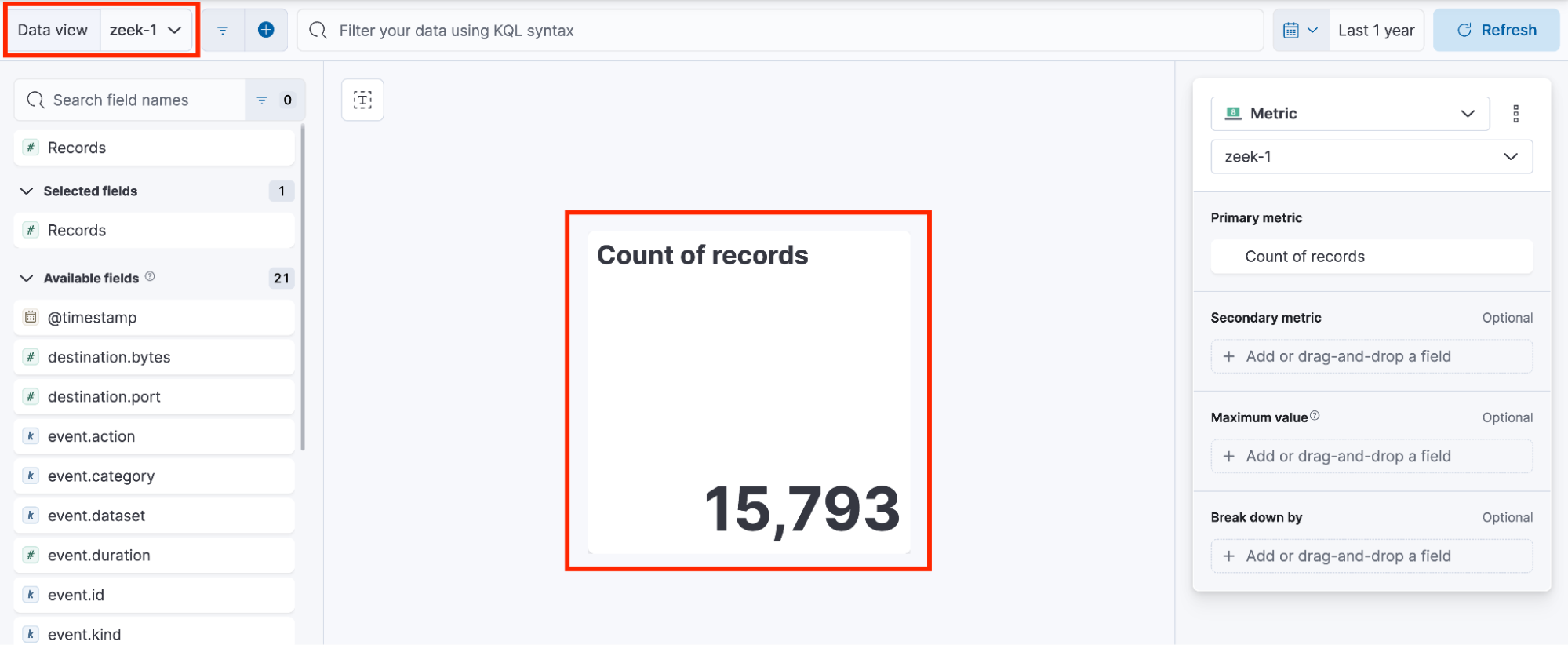
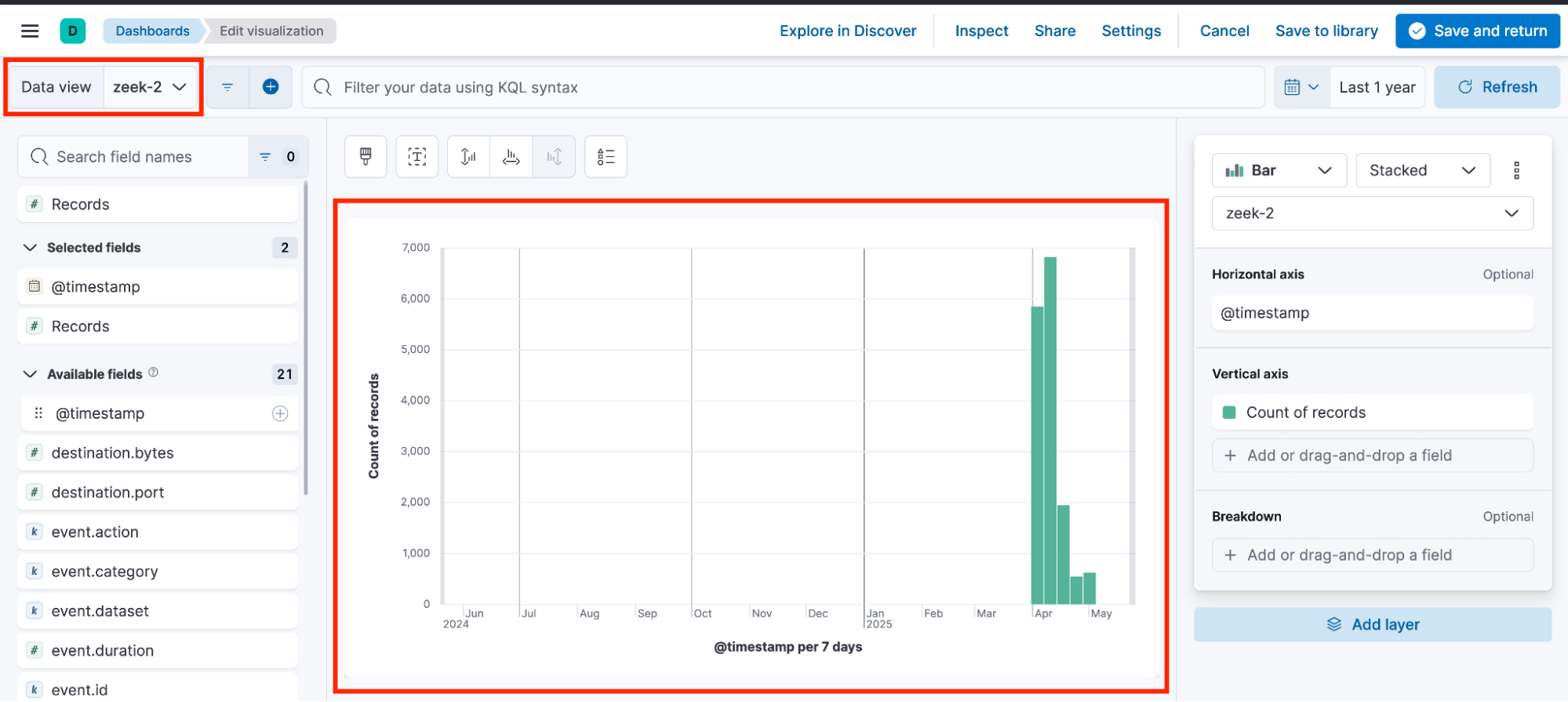
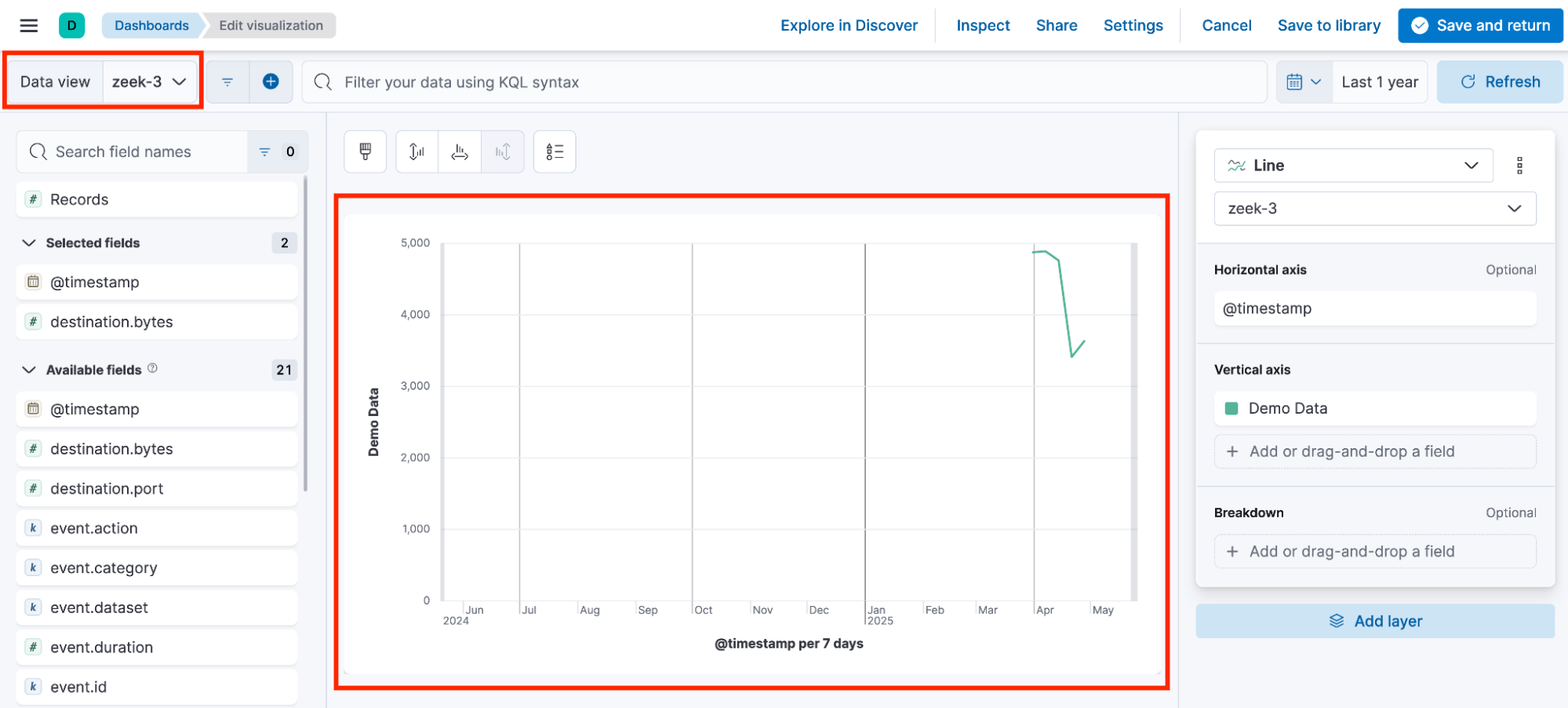
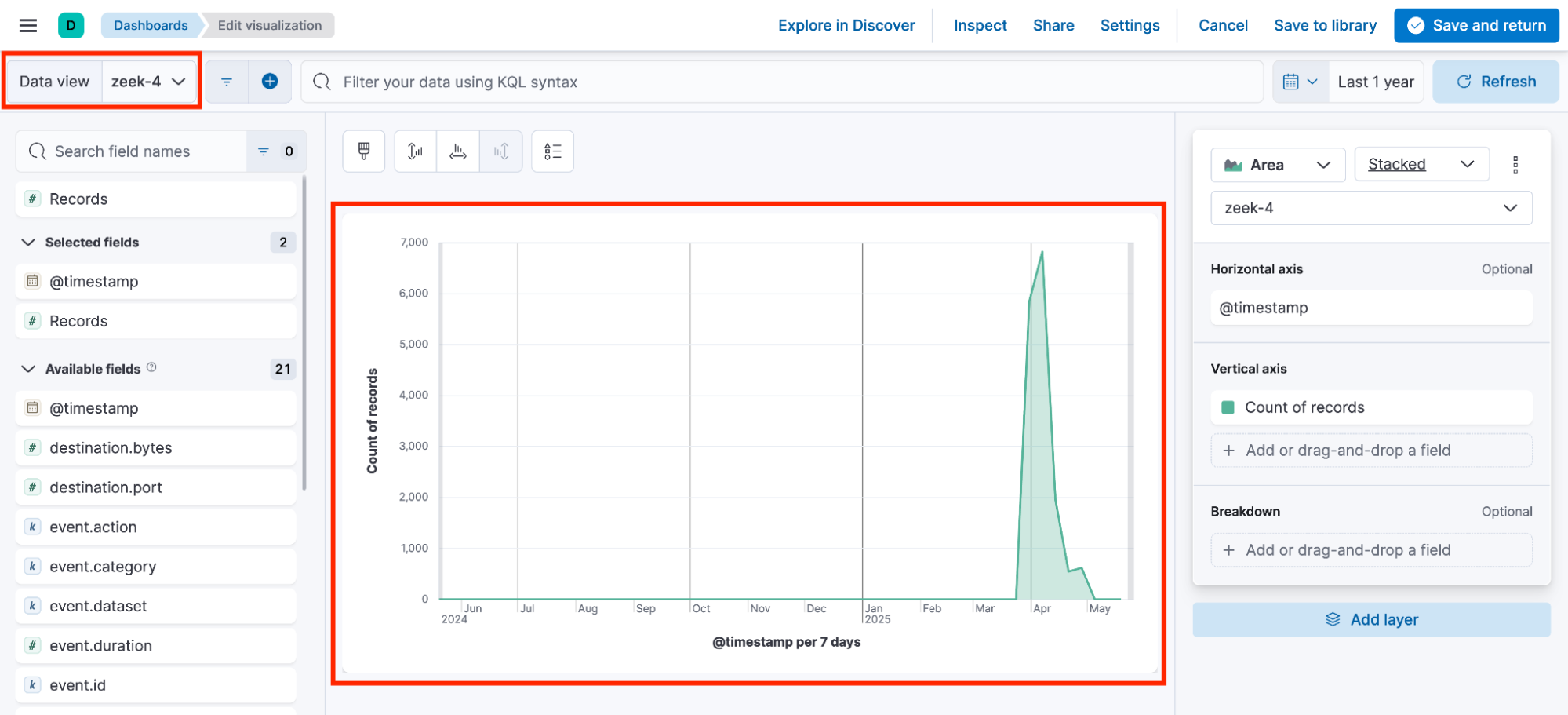
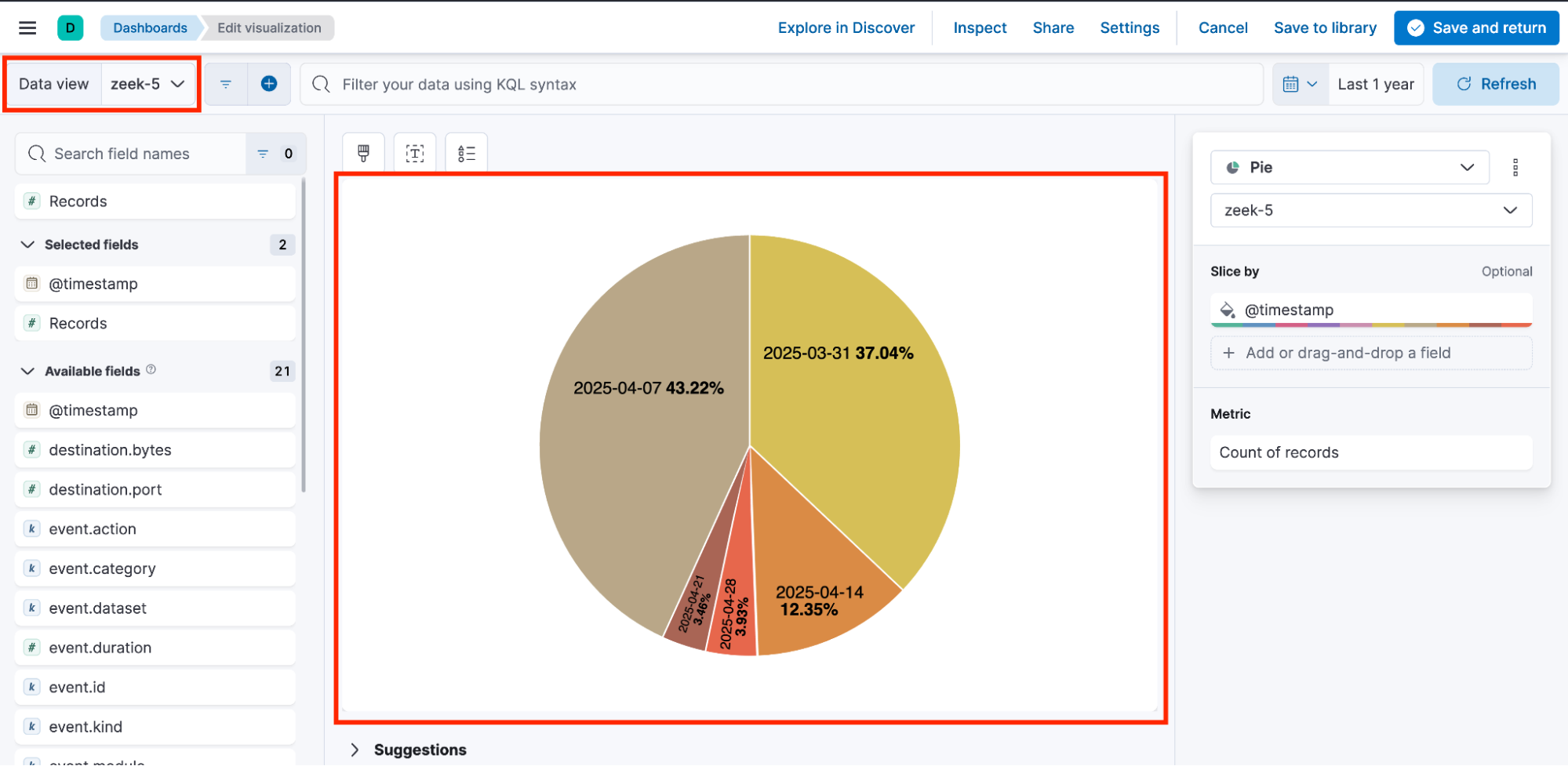
As a result, the dashboard ends up containing visualizations that rely on different data views, each with its own randomly generated ID.
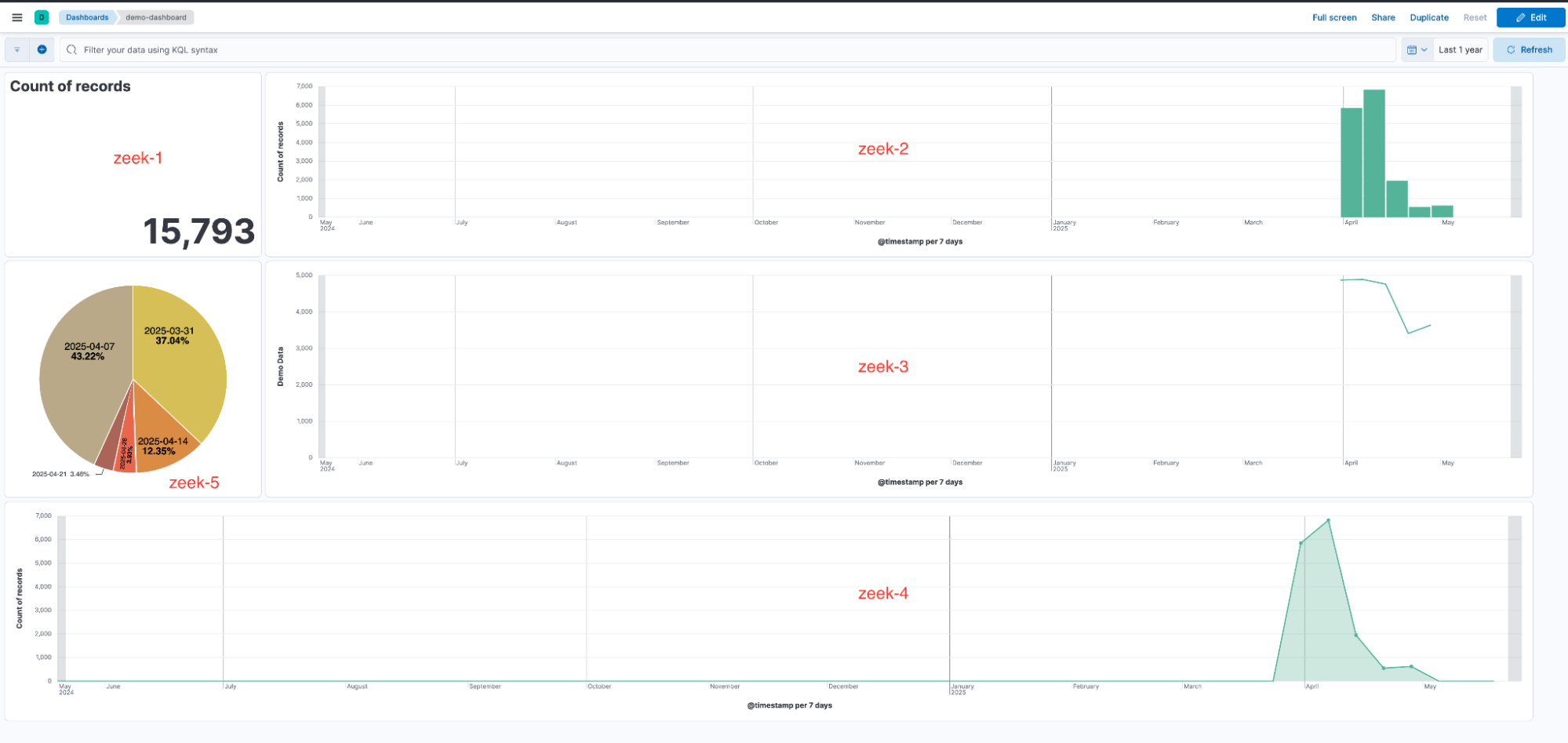
These inconsistencies can cause visualizations to break when one of the associated data views is deleted, as demonstrated earlier in the Young Sheldon walkthrough.
Common issues in collaborative environments
It’s a common issue in collaborative environments. To fix them, you’d need to manually recreate each of the 9 deleted data views and somehow recover and reassign the original UUIDs or modify each of the visualizations to use the one remaining Data View — a tedious and error-prone task.
Compare that to this alternative: If all users had used a shared, custom data view IDs like demo-young-sheldon, you'd only need to recreate a single data view with that same ID to restore everything. No guesswork, no scattered IDs, no unnecessary cleanup.
In short: Custom data view IDs dramatically reduce complexity and risk in collaborative environments.
Some suggestions
If you have made it to this point, I am convinced you’re ready to start using the totally underrated custom data view ID feature. You have made a wise decision. I’m proud of you!
Now that you’re on the team, it’s time for me to give you the keys.
There are several ways to approach a custom data view ID strategy. The method I recommend is simple, scalable, and easy to manage.
Step 1: Choose a clear, memorable name that reflects the dataset
Make it easy to identify at a glance.
Example: Demo Young Sheldon Data becomes demo-young-sheldon
Step 2: Append the name of the space where the data view was created
This helps distinguish environments and avoids naming collisions.
Example: demo-young-sheldon-demo
Step 3: Document it and keep it simple
Document the naming convention and strategy in a shared knowledge repository for easy access and reference. A consistent naming approach helps keep your environment organized and makes it significantly easier to recreate or identify data views, especially when working in collaborative teams.
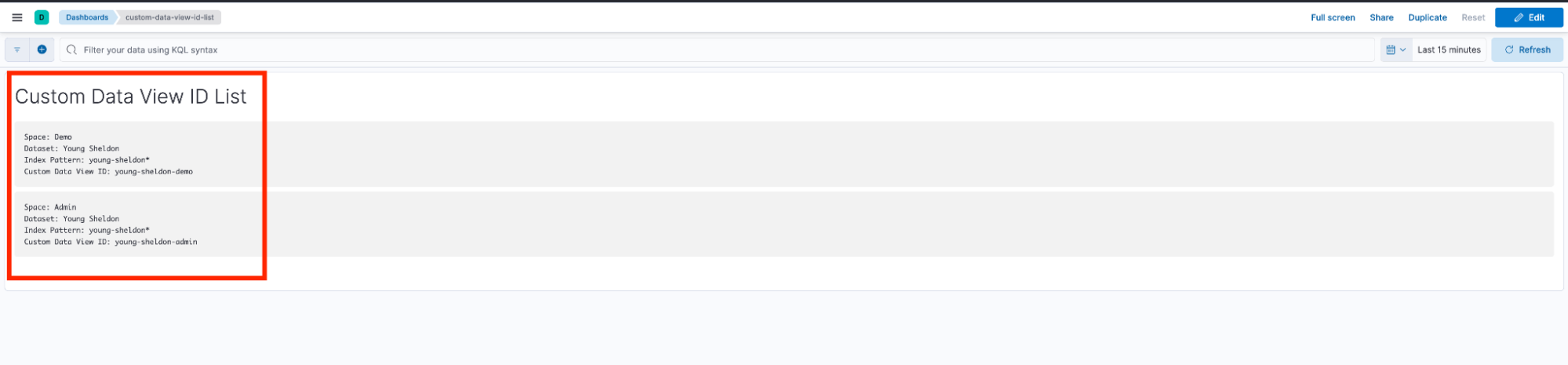
Note: If you want to get a little fancy, you can document the strategy directly in Kibana using a text panel as shown in the image above. Alternatively, you can use a team wiki, GitHub repo, or even a simple spreadsheet (whatever works best for your workflow).
Wrap-up
A lot has happened, so here’s the TL;DR version of this entire blog post:
The custom data view ID feature deserves a starring role in your environment. Think of it like Georgie in Young Sheldon — he was around for seven seasons before fans realized he was a core part of the story. Now Georgie and Mandy is its own thing. Same with custom data view IDs; they have always been important, but they’re just now getting the attention they deserve.
When you're working with larger teams, custom data view IDs become incredibly valuable. They allow users to quickly restore visualizations if a critical data view is deleted. Relying on random, auto-generated IDs can turn recovery into a frustrating and time-consuming task. Custom IDs keep things cleaner, faster, and far less chaotic.
Additionally, We walked through a use case, stepped through a hands-on example, and I even shared my personal recommendations (a.k.a. my self-proclaimed) best practice. It might seem like a small detail, but in my experience, skipping this small thing has led to some very real and very big problems.
You made it to the end. That’s dope. Thanks for sticking with me. Go ahead and log into Kibana and give the custom data view ID strategy a try. I think you’ll dig it.
Looking to automate the creation of custom data view IDs? Check out this Terraform resource.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print