Benchmarking Elasticsearch cross-cluster replication
One of the highly anticipated features of Elasticsearch 6.7 and 7.0 was cross-cluster replication (CCR), or the ability to replicate indices across clusters, e.g., for disaster recovery planning or geographically distributed deployments. Since this feature introduces a lot of changes to the Elasticsearch code base, we need our users to be confident about its performance, resilience and stability.
While our standard Elasticsearch benchmarking tool, Rally, provided a lot of capabilities that we needed, it was necessary to expand it in several areas:
- Ability to communicate with more than one cluster
- Collecting metrics (this is performed using telemetry devices in Rally) from the new Elasticsearch ccr-stats and recovery API endpoints.
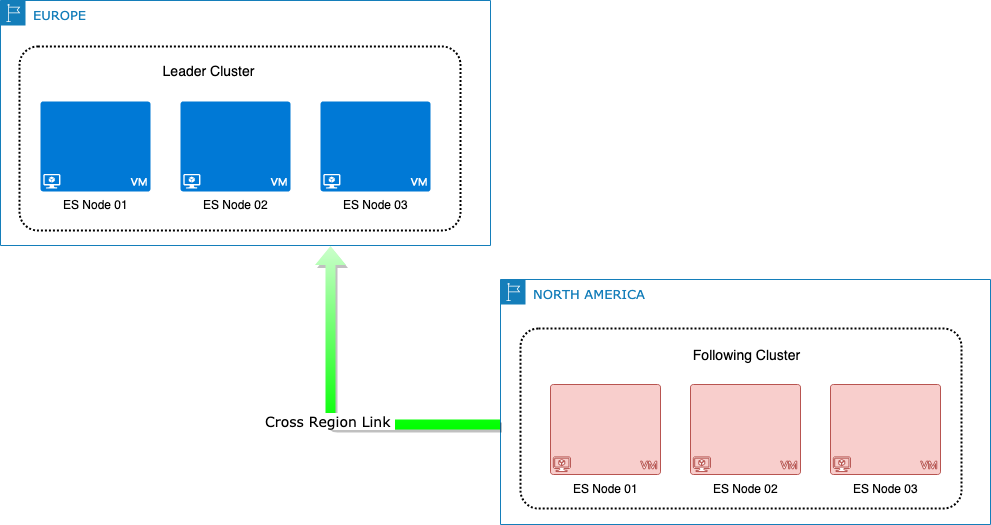
With these features added, we defined a topology involving a leader cluster in a geographical region (Europe) far from the following cluster (North America), ensuring a network latency of at least 100ms:
The benchmarking scenarios used to evaluate different aspects of CCR were:
Ensure follower is always able to catch up with different types of load
We picked three completely different load scenarios representing very small, medium and very large document sizes.
With these were able to tune default values for following indices — for example, to avoid long garbage collection (GC) pauses with large doc sizes we’ve changed the default value of the CCR parameter max_read_request_size from unlimited to 32MB.
Ensure remote recovery is performing optimally
Similarly, we wanted to be sure that bootstrapping a follower index with remote recovery is performing well for most cases with the default configuration.
With the same topology, we used the medium doc size dataset in different scenarios, including indexing it entirely first and then enabling CCR on the following cluster, as well as indexing it up to a certain percentage followed by enabling CCR while indexing continued.
Immediately from the first scenario we observed that the time taken to recover was too long, so we added the ability to fetch chunks from different files in parallel and optimized the remote recovery settings default values.
… but what about network compression?

Remote clusters can be optionally configured to compress requests on the transport layer.
We also evaluated whether transport compression can reduce the time taken for remote recovery and realized that without tweaking a number of settings to saturate the network, enabling compression actually ends up making the recovery process slower due to increased CPU usage.
Stability
Another aspect we looked at is CCR stability over a period of 10 days in different scenarios. Keeping the same network topology we used data modelled on the Filebeat nginx module format.
One scenario concerned leader indices managed using index lifecycle management (ILM) with CCR auto-follow configured: a total of 17bn docs got indexed, the index rolled over 341 times, each rolled over index containing ~52 million docs and 20GB worth of data (not including replicas).
We also conducted the same ten-day scenario with random restarts of the following cluster — with a five-minute pause period before starting them again — to ensure all data gets recovered as expected.
Try benchmarking CCR with Rally yourself!
We’ve prepared an easy to use recipe based on Docker to spin up a local CCR environment for tests pulling metrics and shipping them to an Elasticsearch metrics store. Enjoy!