Agroknow minimizes food safety risks with help from the Elastic Stack
Agroknow, a Greek data and technology company, was recently recognized as an honoree in the 2019 EMEA Elastic Search Awards. We’ve invited Mihalis Papakonstantinou to tell us how Agroknow is using the Elastic Stack to extract insights from agricultural data.
Public food safety data comes in various forms, from many different sources, at a global scale, and in a variety of official languages. Within Europe especially, insights for mitigating food safety risk are crucial. To bridge these practical gaps and help tackle challenges faced by the agricultural industry, we started Agroknow and developed FOODAKAI, a SaaS product that detects potential hazards in the food supply chain.
Before landing on the Elastic Stack as the backbone our data solution, we knew needed the following for our technology stack.
- Text-oriented (since most of the collected data is text based)
- Easily deployed and scalable to anticipate the growing demand
- Out-of-the-box monitoring to keep track of usage and foresee issues
- Automated text mining capabilities to streamline FOODAKAI’s publishing workflows
The first step in creating an effective tool for food intelligence involves collecting worldwide food and food safety data. Using crawlers, we collect food safety incident reports, sensor readings from the field, agricultural product pricing data and lab test results by food companies and Food Safety Authorities. As part of the ingest, we collect data on the reason behind a recall (e.g. bacteria), the product brands involved, the manufacturers or distributors, countries that were affected by each recall, and the origin country of the main ingredient.
Next, the data is analyzed, identifying key factors behind issues like food product recalls. This information is made available and searchable on the platform so that our customers — who can vary from QA and R&D departments of food companies to researchers in the field of food safety — can understand and analyze the reasons behind production setbacks.
Elasticsearch is also used throughout to power text-based queries.
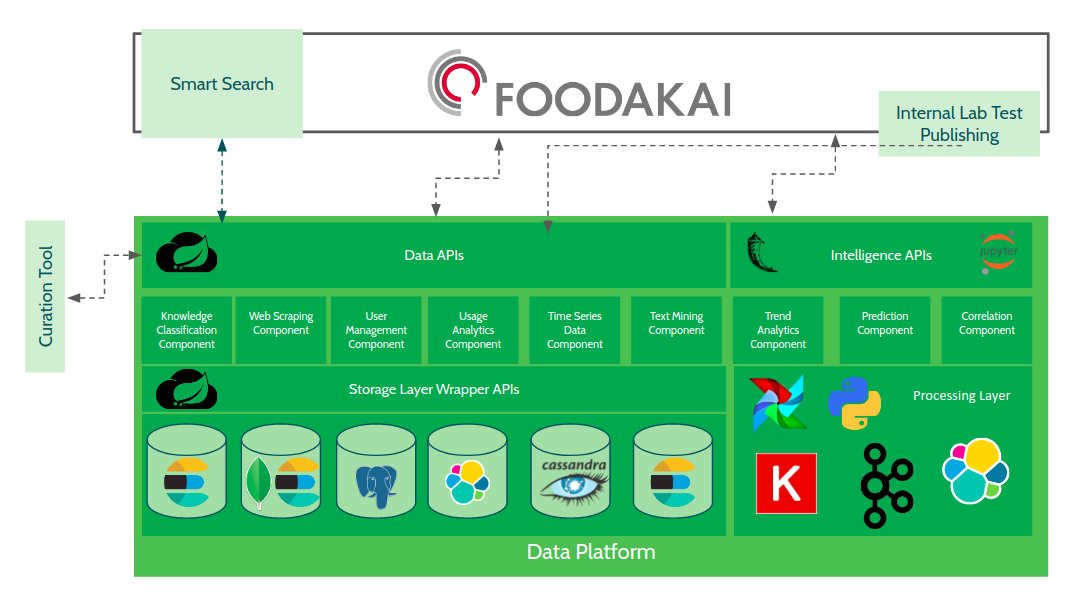

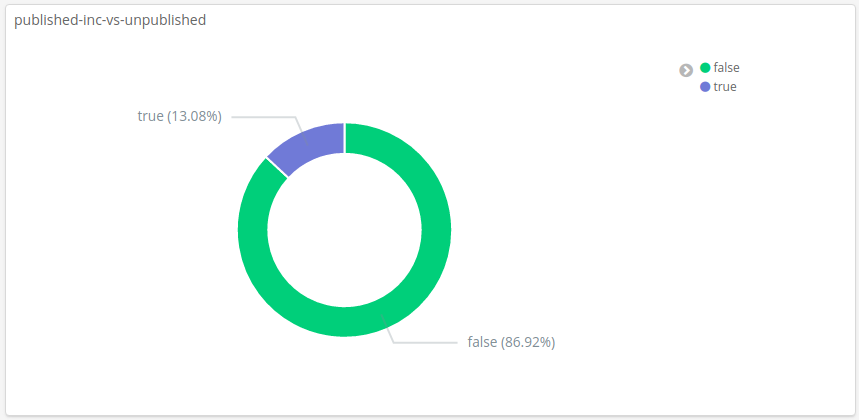
By storing documents with raw materials, hazards, countries and food companies in Elasticsearch, we can query each of the raw food recalls collected, annotate each of them automatically, and make them ready for expert review, prior to them being published in the web application that FOODAKAI customers use. To show the importance of automatic annotation, the figure below shows the percentage of the published incidents versus the ones that have yet to be reviewed and approved by the domain expert.
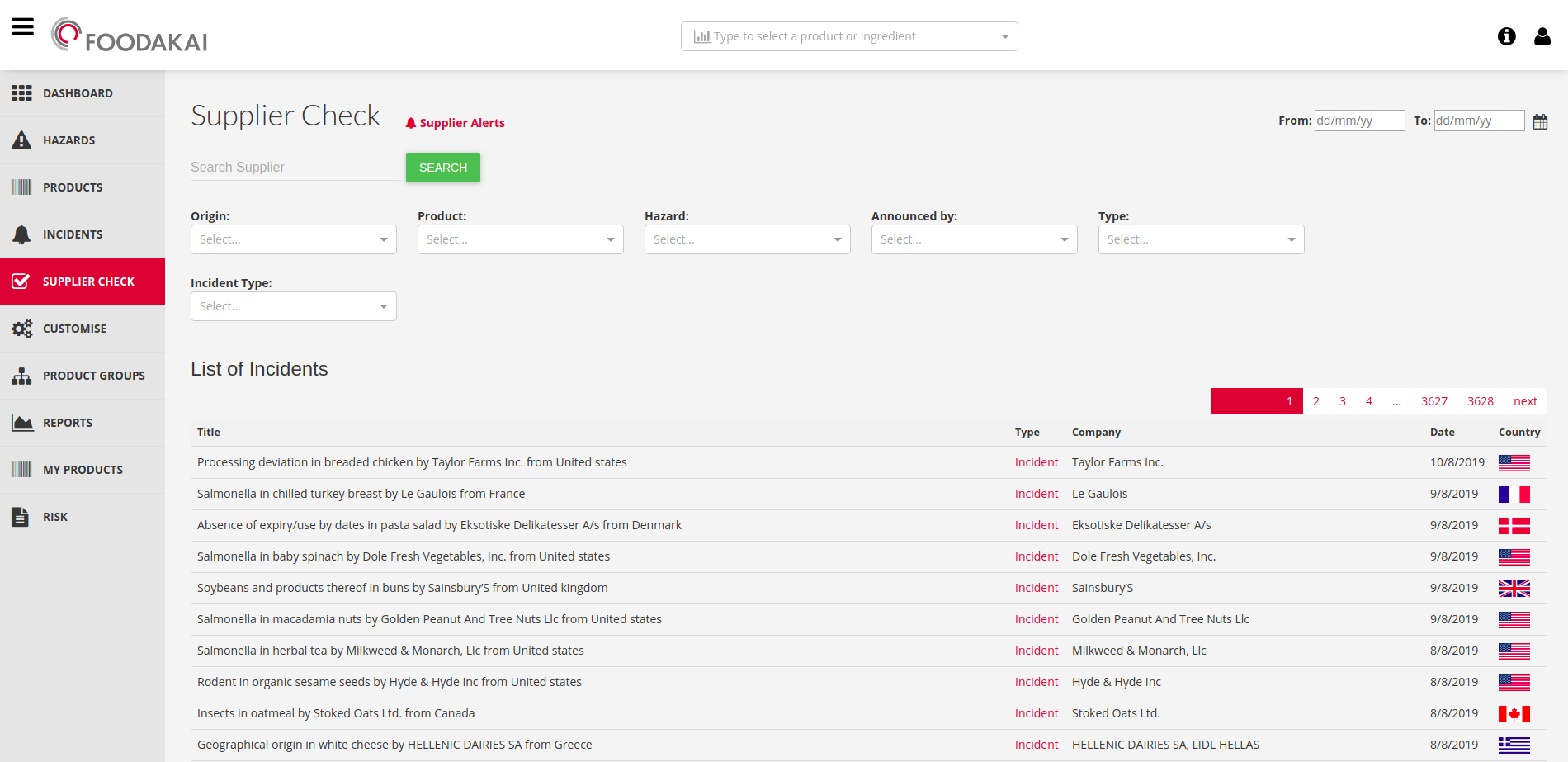
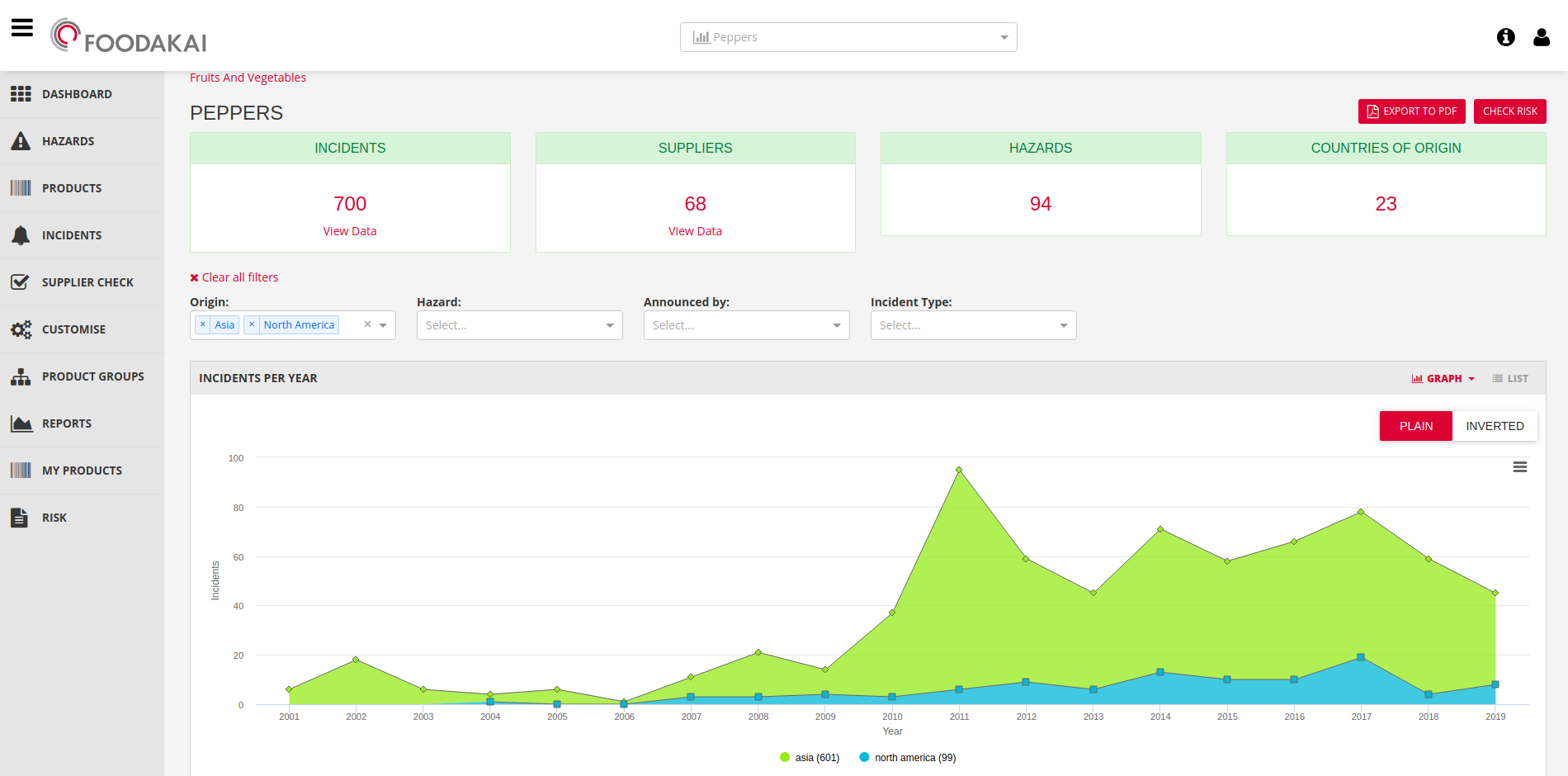
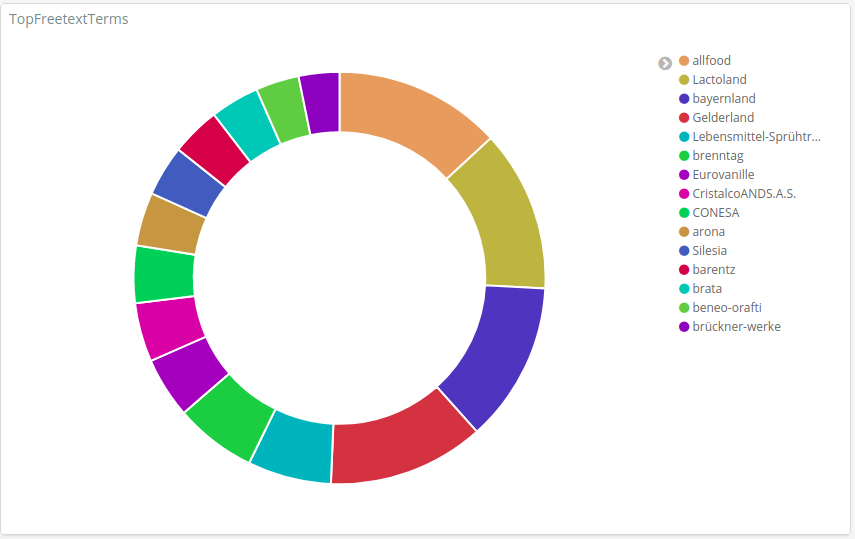
Following the collection, automatic annotation, review, and approval by a domain expert, food-safety-related incidents are published on the FOODAKAI web application. Next, a freetext search powered by a named-entity recognition (NER) technique is performed on all the published data and aggregated information on specific fields on top of such searches, for the respective diagrams to be produced on the application layer.
In both the case of the NER-powered freetext search as well as the aggregations of specific fields, the Elastic Stack features are employed to take advantage of both the ability to analyze fields based on their nature and usage (and use these analyzed fields in freetext searches), as well as use aggregations in specific fields as input for visualizations within the application. Furthermore, the documents stored into Elasticsearch, along with their entity types, are used in order to make the freetext search NER-powered.
| 
|
Finally, the human approval step involved in the publishing process is the most time consuming. By taking into account the amount of data collected by FOODAKAI and the size of the curation team, we needed a way to focus the approval work of the domain expert based on the customer’s needs.
We used Filebeat, Logstash, Elasticsearch and Kibana to keep track of the usage of FOODAKAI’s API; using this data, Kibana dashboards provided insights as to what the users were searching for throughout the application. This knowledge, which is constantly changing based on the users’ queries, is then used by the domain expert to focus her curation work on the customers’ needs. Using information collected by Filebeat and Logstash, a list of data for review is created to prioritize the domain expert’s work. This list is updated on a daily basis. The Elastic Stack, along with Metricbeat, is used for monitoring the whole FOODAKAI backend stack and its various components
In the future, we plan to take advantage of the machine learning capabilities of the stack. Since some of the data collected has to do with numerical time series, detecting outliers and anomalies in the stream is an important step that currently happens on a different level in the stack. We also look forward to using Kibana to perform data-powered user onboarding based on application use.

| Mihalis Papakonstantinou is a Data Engineer and Team Leader at Agroknow. He has been involved with FOODAKAI since day#1, implementing its data platform that currently contains more than 65M food safety related data points. Over the past years, he has worked on providing data-powered solutions to sectors varying from academic institutes and media to financial institutions. |