How to keep Elasticsearch synchronized with a relational database using Logstash and JDBC
In order to take advantage of the powerful search capabilities offered by Elasticsearch, many businesses will deploy Elasticsearch alongside existing relational databases. In such a scenario, it will likely be necessary to keep Elasticsearch synchronized with the data that is stored in the associated relational database. Therefore, in this blog post I will show how Logstash can be used to efficiently copy records and to synchronize updates from a relational database into Elasticsearch. The code and methods presented here have been tested with MySQL, but should theoretically work with any RDBMS.
System configuration
For this blog, I tested with the following:
- MySQL: 8.0.16.
- Elasticsearch: 7.1.1
- Logstash: 7.1.1
- Java: 1.8.0_162-b12
- JDBC input plugin: v4.3.13
- JDBC connector: Connector/J 8.0.16
A high-level overview of the synchronization steps
For this blog we use Logstash with the JDBC input plugin to keep Elasticsearch synchronized with MySQL. Conceptually, Logstash’s JDBC input plugin runs a loop that periodically polls MySQL for records that were inserted or modified since the last iteration of this loop. In order for this to work correctly, the following conditions must be satisfied:
- As documents in MySQL are written into Elasticsearch, the "_id" field in Elasticsearch must be set to the "id" field from MySQL. This provides a direct mapping between the MySQL record and the Elasticsearch document. If a record is updated in MySQL, then the entire associated document will be overwritten in Elasticsearch. Note that overwriting a document in Elasticsearch is just as efficient as an update operation would be, because internally, an update would consist of deleting the old document and then indexing an entirely new document.
- When a record is inserted or updated in MySQL, that record must have a field that contains the update or insertion time. This field is used to allow Logstash to request only documents that have been modified or inserted since the last iteration of its polling loop. Each time Logstash polls MySQL, it stores the update or insertion time of the last record that it has read from MySQL. On its next iteration, Logstash knows that it only needs to request records with an update or insertion time that is newer than the last record that was received in the previous iteration of the polling loop.
If the above conditions are satisfied, we can configure Logstash to periodically request all new or modified records from MySQL and then write them into Elasticsearch. The Logstash code for this is presented later in this blog.
MySQL setup
The MySQL database and table can be configured as follows:
CREATE DATABASE es_db; USE es_db; DROP TABLE IF EXISTS es_table; CREATE TABLE es_table ( id BIGINT(20) UNSIGNED NOT NULL, PRIMARY KEY (id), UNIQUE KEY unique_id (id), client_name VARCHAR(32) NOT NULL, modification_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, insertion_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP );
There are a few interesting parameters in the above MySQL configuration:
es_table: This is the name of the MySQL table that records will be read from and then synchronized to Elasticsearch.id: This is the unique identifier for this record. Notice that “id” is defined as the PRIMARY KEY as well as a UNIQUE KEY. This guarantees each “id” only appears once in the current table. This will be translated to “_id” for updating or inserting the document into Elasticsearch.client_name: This is a field that represents the user-defined data that will be stored in each record. To keep this blog simple, we only have a single field with user-defined data, but more fields could be easily added. This is the field that we will modify to show that not only are newly inserted MySQL records copied to Elasticsearch, but that updated records are also correctly propagated to Elasticsearch.modification_time: This field is defined so that any insertion or update of a record in MySQL will cause its value to be set to the time of the modification. This modification time allows us to pull out any records that have been modified since the last time Logstash requested documents from MySQL.insertion_time: This field is mostly for demonstration purposes and is not strictly necessary for synchronization to work correctly. We use it to track when a record was originally inserted into MySQL.
MySQL Operations
Given the above configuration, records can be written to MySQL as follows:
INSERT INTO es_table (id, client_name) VALUES (<id>, <client name>);
Records in MySQL can be updated using the following command:
UPDATE es_table SET client_name = <new client name> WHERE id=<id>;
MySQL upserts can be done as follows:
INSERT INTO es_table (id, client_name) VALUES (<id>, <client name when created> ON DUPLICATE KEY UPDATE client_name=<client name when updated>;
Synchronization code
The following logstash pipeline implements the synchronization code that is described in the previous section:
input {
jdbc {
jdbc_driver_library => "<path>/mysql-connector-java-8.0.16.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://<MySQL host>:3306/es_db"
jdbc_user => <my username>
jdbc_password => <my password>
jdbc_paging_enabled => true
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
schedule => "*/5 * * * * *"
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC"
}
}
filter {
mutate {
copy => { "id" => "[@metadata][_id]"}
remove_field => ["id", "@version", "unix_ts_in_secs"]
}
}
output {
# stdout { codec => "rubydebug"}
elasticsearch {
index => "rdbms_sync_idx"
document_id => "%{[@metadata][_id]}"
}
}
There are a few areas from the above pipeline that should be highlighted:
tracking_column: This field specifies the field “unix_ts_in_secs” (described below) that is used for tracking the last document read by Logstash from MySQL, and is stored on disk in .logstash_jdbc_last_run. This value will be used to determine the starting value for documents that Logstash will request in the next iteration of its polling loop. The value stored in .logstash_jdbc_last_run can be accessed in the SELECT statement as “:sql_last_value”.unix_ts_in_secs: This is a field that is generated by the above SELECT statement, and which contains the “modification_time” as a standard Unix timestamp (seconds since the epoch). This field is referenced by the “tracking column” that we just discussed. A Unix timestamp is used for tracking progress rather than a normal timestamp, as a normal timestamp may cause errors due to the complexity of correctly converting back and forth between UMT and the local timezone.sql_last_value: This is a built-in parameter that contains the starting point for the current iteration of Logstash’s polling loop, and it is referenced in the SELECT statement line of the above jdbc input configuration. This is set to the most recent value of “unix_ts_in_secs”, which is read from .logstash_jdbc_last_run. This is used as the starting point for documents to be returned by the MySQL query that is executed in Logstash’s polling loop. Including this variable in the query guarantees that insertions or updates that have previously been propagated to Elasticsearch will not be re-sent to Elasticsearch.schedule: This uses cron syntax to specify how often Logstash should poll MySQL for changes. The specification of"*/5 * * * * *"tells Logstash to contact MySQL every 5 seconds.modification_time < NOW(): This portion of the SELECT is one of the more difficult concepts to explain and therefore it is explained in detail in the next section.filter: In this section we simply copy the value of “id” from the MySQL record into a metadata field called “_id”, which we will later reference in the output to ensure that each document is written into Elasticsearch with the correct “_id” value. Using a metadata field ensures that this temporary value does not cause a new field to be created. We also remove the “id”, “@version”, and “unix_ts_in_secs” fields from the document, as we do not wish for them to be written to Elasticsearch.output: In this section we specify that each document should be written to Elasticsearch, and should be assigned an “_id” which is pulled from the metadata field that we created in the filter section. There is also a commented-out rubydebug output that can be enabled to help with debugging.
Analysis of the correctness of the SELECT statement
In this section we give a description of why including modification_time < NOW() in the SELECT statement is important. To help explain this concept, we first give counter-examples that demonstrate why the two most intuitive approaches will not work correctly. This is followed by an explanation of how including modification_time < NOW() overcomes problems with the intuitive approaches.
Intuitive scenario one
In this section we show what happens if the WHERE clause does not include modification_time < NOW(), and instead only specifies UNIX_TIMESTAMP(modification_time) > :sql_last_value. In this case, the SELECT statement would look as follows:
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value) ORDER BY modification_time ASC"
At first glance, the above approach appears that it should work correctly, but there are edge cases where it may miss some documents. For example, let's consider a case where MySQL is inserting 2 documents per second and where Logstash is executing its SELECT statement every 5 seconds. This is demonstrated in the following diagram, where each second is represented by T0 to T10, and the records in MySQL are represented by R1 through R22. We assume that the first iteration of Logstash’s polling loop takes place at T5 and it reads documents R1 through R11, as represented by the cyan boxes. The value stored in sql_last_value is now T5 as this is the timestamp on the last record (R11) that was read. We also assume that just after Logstash has read documents from MySQL, another document R12 is inserted into MySQL with a timestamp of T5.
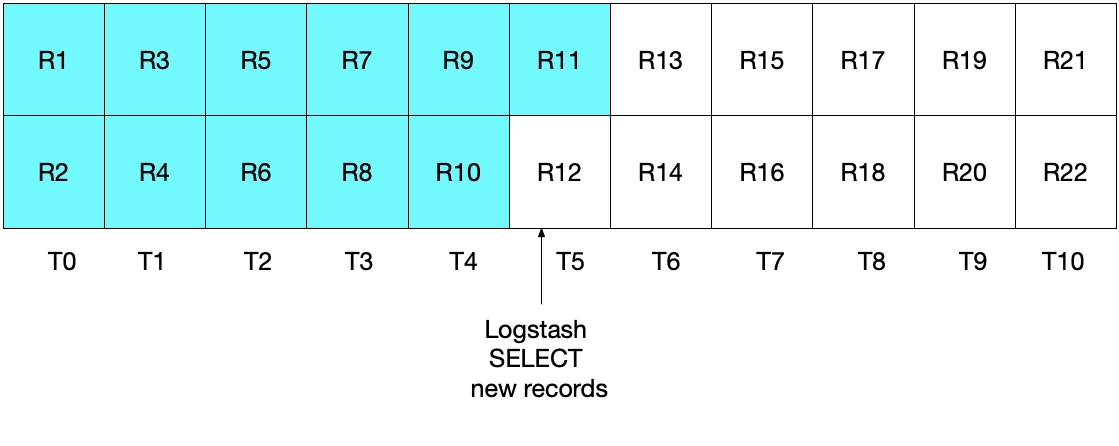
In the next iteration of the above SELECT statement, we only pull documents where the time is WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value)), which means that record R12 will be skipped. This is shown in the diagram below, where the cyan boxes represent the records that are read by Logstash in the current iteration, and the grey boxes represent the records that were previously read by Logstash.
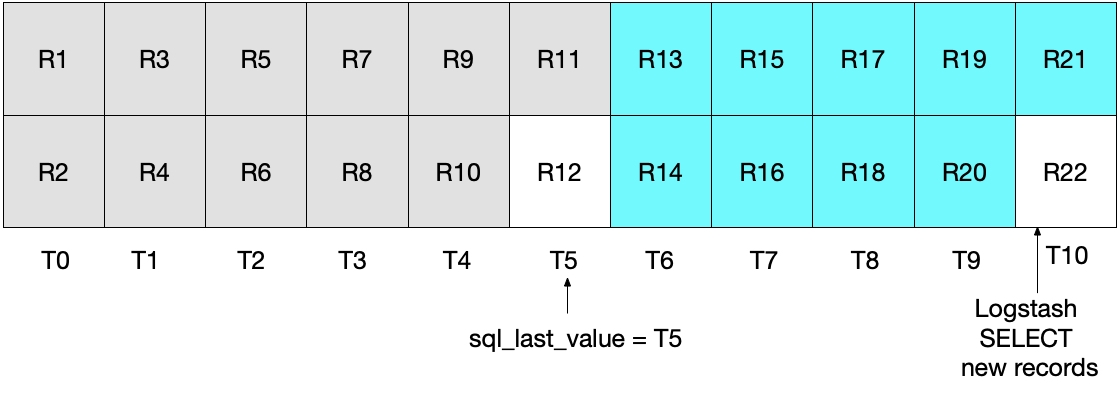
Notice that with this scenario’s SELECT, the record R12 will never be written to Elasticsearch.
Intuitive scenario two
To remedy the above issue, one may decide to change the WHERE clause to
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) >= :sql_last_value) ORDER BY modification_time ASC"
However, this implementation is also not ideal. In this case, the problem is that the most recent document(s) read from MySQL in the most recent time interval will be re-sent to Elasticsearch. While this does not cause any issues with respect to correctness of the results, it does create unnecessary work. As in the previous section, after the initial Logstash polling iteration, the diagram below shows which documents have been read from MySQL.
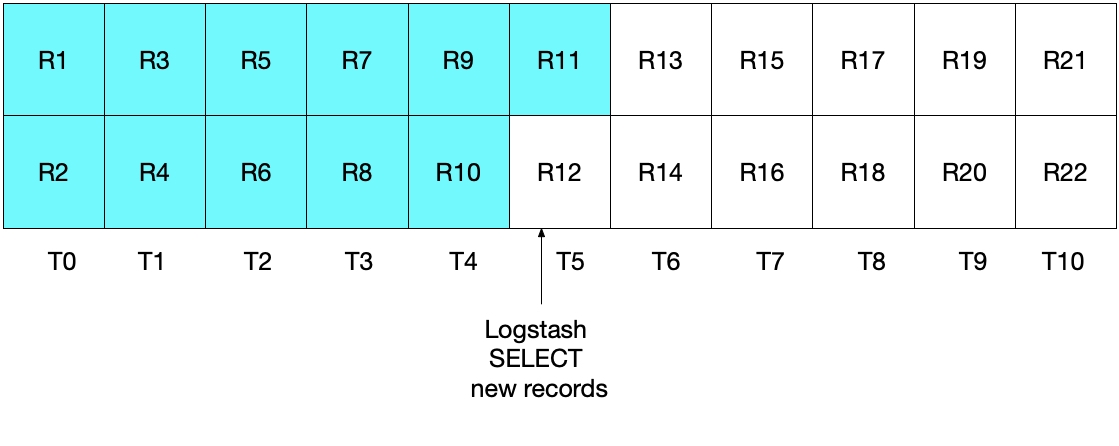
When we execute the subsequent Logstash polling iteration, we pull all documents where the time is greater than
Neither of the previous two scenarios are ideal. In the first scenario data can be lost, and in the second scenario redundant data is read from MySQL and sent to Elasticsearch.
How to fix the intuitive approaches
Given that neither of the previous two scenarios are ideal, an alternative approach should be employed. By specifying (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()), we send each document to Elasticsearch exactly once.
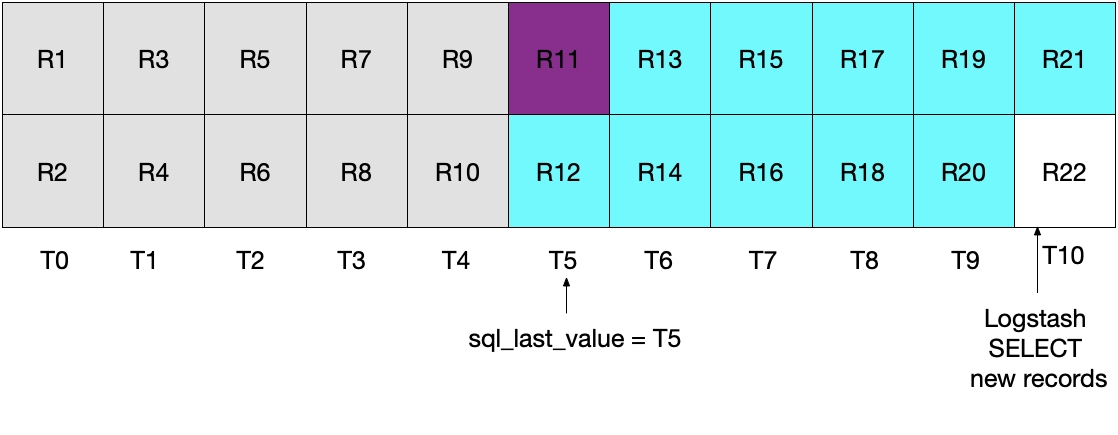
This is demonstrated by the following diagram, where the current Logstash poll is executed at T5. Notice that because modification_time < NOW() must be satisfied, only documents up to, but not including, those in the period T5 will be read from MySQL. Since we have retrieved all documents from T4 and no documents from T5, we know that sql_last_value will then be set to T4 for the next Logstash polling iteration.
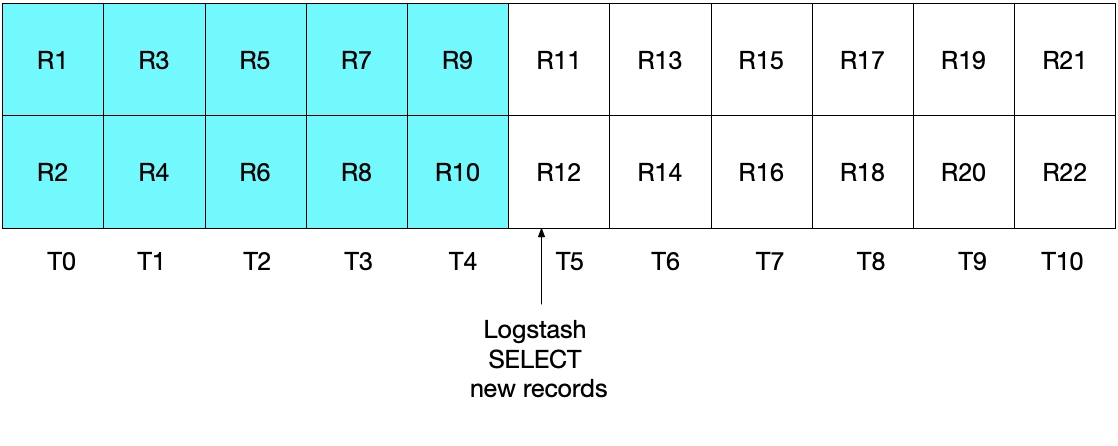
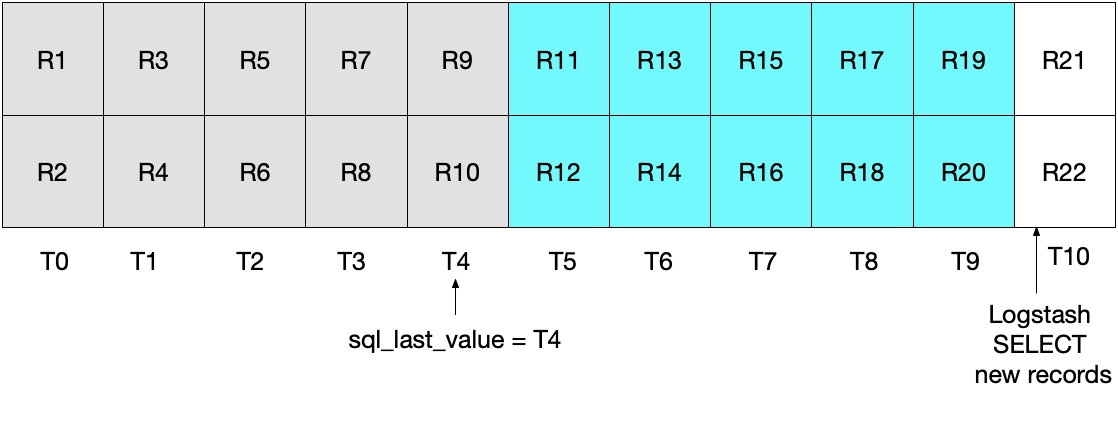
The diagram below demonstrates what happens on the next iteration of the Logstash poll. Since UNIX_TIMESTAMP(modification_time) > :sql_last_value, and because sql_last_value is set to T4, we know that only documents starting from T5 will be retrieved. Additionally, because only documents that satisfy modification_time < NOW() will be retrieved, only documents up to and including T9 will be retrieved. Again, this means that all documents in T9 are retrieved, and that sql_last_value will be set to T9 for the next iteration. Therefore this approach eliminates the risk of retrieving only a subset of MySQL documents from any given time interval.
Testing the system
Simple tests can be used to demonstrate that our implementation performs as desired. We can write records into MySQL as follows:
INSERT INTO es_table (id, client_name) VALUES (1, 'Jim Carrey'); INSERT INTO es_table (id, client_name) VALUES (2, 'Mike Myers'); INSERT INTO es_table (id, client_name) VALUES (3, 'Bryan Adams');
Once the JDBC input schedule has triggered reading records from MySQL and written them to Elasticsearch, we can execute the following Elasticsearch query to see the documents in Elasticsearch:
GET rdbms_sync_idx/_search
which returns something similar to the following response:
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "rdbms_sync_idx",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"insertion_time" : "2019-06-18T12:58:56.000Z",
"@timestamp" : "2019-06-18T13:04:27.436Z",
"modification_time" : "2019-06-18T12:58:56.000Z",
"client_name" : "Jim Carrey"
}
},
Etc …
We can then update the document that corresponds to _id=1 in MySQL as follows:
UPDATE es_table SET client_name = 'Jimbo Kerry' WHERE id=1;
which correctly updates the document identified by _id of 1. We can look directly at the document in Elasticsearch by executing the following:
GET rdbms_sync_idx/_doc/1
which returns a document that looks as follows:
{
"_index" : "rdbms_sync_idx",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"insertion_time" : "2019-06-18T12:58:56.000Z",
"@timestamp" : "2019-06-18T13:09:30.300Z",
"modification_time" : "2019-06-18T13:09:28.000Z",
"client_name" : "Jimbo Kerry"
}
}
Notice that the _version is now set to 2, that the modification_time is now different than the insertion_time, and that the client_name field has been correctly updated to the new value. The @timestamp field is not particularly interesting for this example, and is added by Logstash by default.
An upsert into MySQL can be done as follows, and the reader of this blog can verify that the correct information will be reflected in Elasticsearch:
INSERT INTO es_table (id, client_name) VALUES (4, 'Bob is new') ON DUPLICATE KEY UPDATE client_name='Bob exists already';
What about deleted documents?
The astute reader may have noticed that if a document is deleted from MySQL, then that deletion will not be propagated to Elasticsearch. The following approaches may be considered to address this issue:
- MySQL records could include an "is_deleted" field, which indicates that they are no longer valid. This is known as a "soft delete". As with any other update to a record in MySQL, the "is_deleted" field will be propagated to Elasticsearch through Logstash. If this approach is implemented, then Elasticsearch and MySQL queries would need to be written so as to exclude records/documents where "is_deleted" is true. Eventually, background jobs can remove such documents from both MySQL and Elastic.
- Another alternative is to ensure that any system that is responsible for deletion of records in MySQL must also subsequently execute a command to directly delete the corresponding documents from Elasticsearch.
Conclusion
In this blog post I showed how Logstash can be used to synchronize Elasticsearch with a relational database. The code and methods presented here were tested with MySQL, but should theoretically work with any RDBMS.
If you have any questions about Logstash or any other Elasticsearch-related topics, have a look at our Discuss forums for valuable discussion, insights, and information. Also, don't forget to try out our Elasticsearch Service, the only hosted Elasticsearch and Kibana offering powered by the creators of Elasticsearch.