Com esse contexto (bastante extenso) sobre como os LLMs (Learning Learning Machines) mudaram os processos subjacentes de recuperação de informações, vejamos como eles também mudaram a forma como consultamos dados.
Uma nova forma de interagir com dados
A IA generativa (genAI) e a IA agentiva funcionam de maneira diferente da busca tradicional. Enquanto antes começávamos a pesquisar informações por meio de uma busca ("deixe-me pesquisar isso no Google..."), a ação inicial tanto para a IA de geração de robôs quanto para os agentes geralmente se dá por meio da linguagem natural inserida em uma interface de bate-papo. A interface de bate-papo é uma discussão com um LLM (Literatura Liderada pelo Senhor da Moeda) que usa sua compreensão semântica para transformar nossa pergunta em uma resposta concisa, uma resposta resumida que parece vir de um oráculo com amplo conhecimento de todos os tipos de informação. O que realmente convence é a capacidade do LLM de gerar frases coerentes e ponderadas que conectam os fragmentos de conhecimento que ele apresenta — mesmo quando são imprecisos ou totalmente alucinatórios, há uma sensação de veracidade neles.
Aquela velha barra de pesquisa com a qual nos acostumamos tanto a interagir pode ser considerada o mecanismo RAG que usávamos quando nós mesmos éramos o agente de raciocínio. Hoje em dia, até mesmo os mecanismos de busca da internet estão transformando nossa tradicional experiência de busca lexical, baseada em "catar e digitar", em resumos gerados por inteligência artificial que respondem à consulta com um sumário dos resultados, ajudando os usuários a evitar a necessidade de clicar e avaliar cada resultado individualmente.
IA Generativa e RAG
A IA generativa tenta usar sua compreensão semântica do mundo para analisar a intenção subjetiva expressa em uma solicitação de bate-papo e, em seguida, usa suas habilidades de inferência para criar uma resposta especializada instantaneamente. Uma interação com IA generativa possui várias partes: começa com a entrada/consulta do usuário, conversas anteriores na sessão de bate-papo podem ser usadas como contexto adicional, e a instrução que informa ao LLM como raciocinar e quais procedimentos seguir na construção da resposta. As instruções evoluíram de orientações simples do tipo "explique isso para mim como se eu tivesse cinco anos de idade" para explicações detalhadas de como processar as solicitações. Essas análises geralmente incluem seções distintas que descrevem detalhes da personalidade/função da IA, raciocínio pré-geração/processo de pensamento interno, critérios objetivos, restrições, formato de saída, público-alvo, bem como exemplos para ajudar a demonstrar os resultados esperados.
Além da consulta do usuário e da mensagem do sistema, a geração aumentada de recuperação (RAG, na sigla em inglês) fornece informações contextuais adicionais no que é chamado de "janela de contexto". O RAG tem sido uma adição crucial à arquitetura; é o que usamos para informar o LLM sobre as peças que faltam em sua compreensão semântica do mundo.
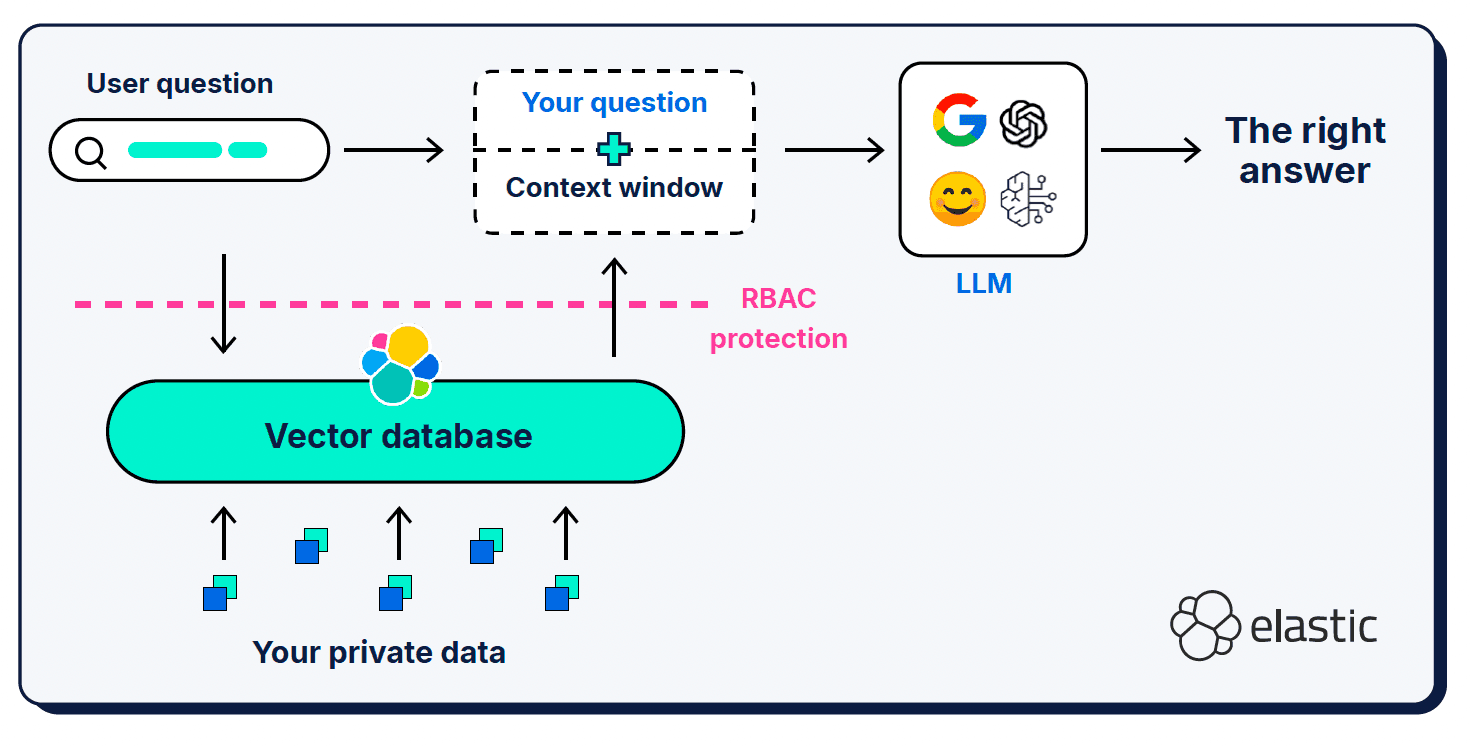
As janelas de contexto podem ser um tanto exigentes em termos do que, onde e quanto você lhes fornece. O contexto selecionado é muito importante, obviamente, mas a relação sinal-ruído do contexto fornecido também importa, assim como o tamanho da janela.
Informação insuficiente
Fornecer pouca informação em uma consulta, prompt ou janela de contexto pode levar a alucinações, pois o LLM não consegue determinar com precisão o contexto semântico correto para gerar uma resposta. Existem também problemas com a similaridade vetorial dos tamanhos dos fragmentos de documentos — uma pergunta curta e simples pode não se alinhar semanticamente com os documentos ricos e detalhados encontrados em nossas bases de conhecimento vetorizadas. Foram desenvolvidas técnicas de expansão de consultas, como Hypothetical Document Embeddings (HyDE) , que utilizam LLMs para gerar uma resposta hipotética mais rica e expressiva do que a consulta curta. O perigo aqui, claro, é que o documento hipotético seja em si uma alucinação que afasta ainda mais o LLM do contexto correto.
Informação em excesso
Assim como acontece conosco, humanos, o excesso de informações em uma janela de contexto pode sobrecarregar e confundir um usuário de linguagem natural sobre quais são as partes importantes. O estouro de contexto (ou "deterioração de contexto ") afeta a qualidade e o desempenho das operações de IA generativa; ele impacta significativamente o "orçamento de atenção" do LLM (sua memória de trabalho) e dilui a relevância entre muitos tokens concorrentes. O conceito de "deterioração do contexto" também inclui a observação de que os autores de livros didáticos tendem a ter um viés posicional — eles preferem o conteúdo no início ou no final de uma janela de contexto em relação ao conteúdo na seção intermediária.
Informações que distraem ou são contraditórias
Quanto maior for a janela de contexto, maior será a probabilidade de incluir informações supérfluas ou conflitantes que podem distrair o usuário do LLM (Liderança em Aprendizagem) de selecionar e processar o contexto correto. De certa forma, isso se torna um problema de "lixo entra, lixo sai": simplesmente despejar um conjunto de resultados de documentos em uma janela de contexto fornece ao LLM muita informação para processar (potencialmente em excesso), mas dependendo de como o contexto foi selecionado, há uma possibilidade maior de informações conflitantes ou irrelevantes se infiltrarem.
IA Agêntica
Eu disse que havia muito o que abordar, mas conseguimos — finalmente estamos falando sobre tópicos de IA agente! A IA Agética é uma nova e empolgante aplicação das interfaces de chat do LLM que expande a capacidade da IA generativa (podemos já chamá-la de "legada"?) de sintetizar respostas com base em seu próprio conhecimento e nas informações contextuais fornecidas pelo usuário. À medida que a IA generativa amadureceu, percebemos que havia um certo nível de tarefas e automação que poderíamos delegar aos LLMs, inicialmente relegadas a atividades tediosas e de baixo risco que podem ser facilmente verificadas/validadas por um humano. Em um curto período de tempo, esse escopo inicial cresceu: uma janela de bate-papo do LLM agora pode ser a faísca que envia um agente de IA para planejar, executar e avaliar e adaptar seu plano de forma autônoma e iterativa para atingir o objetivo especificado. Os agentes têm acesso ao raciocínio dos seus LLMs, ao histórico de conversas e à memória cognitiva (na medida do possível), e também dispõem de ferramentas específicas que podem utilizar para atingir esse objetivo. Também estamos vendo agora arquiteturas que permitem que um agente de nível superior funcione como orquestrador de múltiplos subagentes, cada um com suas próprias cadeias lógicas, conjuntos de instruções, contexto e ferramentas.
Os agentes são o ponto de entrada para um fluxo de trabalho em grande parte automatizado: eles são autônomos, pois conseguem conversar com um usuário e, em seguida, usar a "lógica" para determinar quais ferramentas estão disponíveis para ajudar a responder à pergunta do usuário. As ferramentas são geralmente consideradas passivas em comparação com os agentes e são construídas para realizar um único tipo de tarefa. Os tipos de tarefas que uma ferramenta pode executar são praticamente ilimitados (o que é realmente empolgante!), mas uma das principais tarefas que as ferramentas realizam é coletar informações contextuais para que um agente as considere ao executar seu fluxo de trabalho.
Como tecnologia, a IA ativa ainda está em sua infância e propensa ao equivalente acadêmico do transtorno de déficit de atenção — ela facilmente esquece o que lhe foi pedido para fazer e, muitas vezes, sai fazendo outras coisas que não faziam parte do escopo da tarefa. Por trás da aparente magia, as habilidades de "raciocínio" dos LLMs ainda se baseiam em prever o próximo token mais provável em uma sequência. Para que o raciocínio (ou, um dia, a inteligência artificial geral (IAG)) se torne confiável e digno de confiança, precisamos ser capazes de verificar se, ao recebermos as informações corretas e mais atualizadas, elas raciocinarão da maneira que esperamos (e talvez nos forneçam aquela informação extra que não havíamos imaginado). Para que isso aconteça, as arquiteturas agentivas precisarão da capacidade de se comunicar claramente (protocolos), de aderir aos fluxos de trabalho e restrições que lhes impomos (diretrizes), de lembrar em que ponto da tarefa estão (estado), de gerenciar seu espaço de memória disponível e de validar se suas respostas são precisas e atendem aos critérios da tarefa.
Fale comigo em uma língua que eu possa entender.
Como é comum em novas áreas de desenvolvimento (especialmente no mundo dos LLMs), inicialmente existiram várias abordagens para a comunicação entre agentes e ferramentas, mas elas rapidamente convergiram para o Protocolo de Contexto do Modelo (MCP) como o padrão de facto. A definição de Protocolo de Contexto de Modelo está literalmente no nome: é o protocolo que um modelo usa para solicitar e receber informações contextuais . O MCP funciona como um adaptador universal para que os agentes LLM se conectem a ferramentas e fontes de dados externas; ele simplifica e padroniza as APIs para que diferentes estruturas e ferramentas LLM possam interoperar facilmente. Isso faz do MCP uma espécie de ponto de articulação entre a lógica de orquestração e os comandos do sistema dados a um agente para que ele execute tarefas de forma autônoma a serviço de seus objetivos, e as operações enviadas às ferramentas para que sejam executadas de maneira mais isolada (isolada, pelo menos, em relação ao agente iniciador).
Este ecossistema é tão novo que cada direção de expansão parece uma nova fronteira. Temos protocolos semelhantes para interações agente-a-agente (Agent2Agent (A2A) , claro!), bem como outros projetos para melhorar a memória de raciocínio do agente (ReasoningBank), para selecionar o melhor servidor MCP para a tarefa em questão (RAG-MCP) e usar análise semântica, como classificação zero-shot e detecção de padrões na entrada e saída, como Guardrails para controlar sobre o que um agente pode operar.
Você deve ter percebido que a intenção subjacente de cada um desses projetos é melhorar a qualidade e o controle das informações retornadas para uma janela de contexto do agente/genAI? Embora o ecossistema de IA agente continue a desenvolver a capacidade de lidar melhor com essas informações contextuais (para controlá-las, gerenciá-las e operá-las), sempre haverá a necessidade de recuperar as informações contextuais mais relevantes como matéria-prima para o agente processar.
Bem-vindo à engenharia de contexto!
Se você está familiarizado com os termos de IA generativa, provavelmente já ouviu falar de 'engenharia de prompts' - a essa altura, é quase uma pseudociência em si mesma. A engenharia de prompts é usada para encontrar as melhores e mais eficientes maneiras de descrever proativamente os comportamentos que você deseja que o LLM utilize ao gerar sua resposta. A " engenharia de contexto" estende as técnicas de "engenharia de prompts" além do lado do agente, abrangendo também as fontes e sistemas de contexto disponíveis no lado das ferramentas do protocolo MCP, e inclui os tópicos gerais de gerenciamento, processamento e geração de contexto:
- Gerenciamento de contexto - Relacionado à manutenção da eficiência de estado e contexto em fluxos de trabalho de agentes de longa duração e/ou mais complexos. Planejamento, acompanhamento e orquestração iterativos de tarefas e chamadas de ferramentas para atingir os objetivos do agente. Devido ao limitado "orçamento de atenção" com que os agentes têm que trabalhar, o gerenciamento de contexto se preocupa principalmente com técnicas que ajudam a refinar a janela de contexto para capturar tanto o escopo mais completo quanto os elementos mais importantes do contexto (sua precisão versus abrangência!). As técnicas incluem compressão, sumarização e persistência do contexto de etapas anteriores ou chamadas de ferramentas para liberar espaço na memória de trabalho para contexto adicional em etapas subsequentes.
- Processamento de contexto - Os passos lógicos e, idealmente, em sua maioria programáticos para integrar, normalizar ou refinar o contexto adquirido de fontes distintas, de modo que o agente possa raciocinar sobre todo o contexto de maneira relativamente uniforme. O objetivo principal é tornar o contexto de todas as fontes (sugestões, RAG, memória, etc.) o mais acessível possível ao agente.
- Geração de contexto - Se o processamento de contexto visa tornar o contexto recuperado utilizável para o agente, então a geração de contexto permite que o agente solicite e receba informações contextuais adicionais conforme desejar, mas também com restrições.
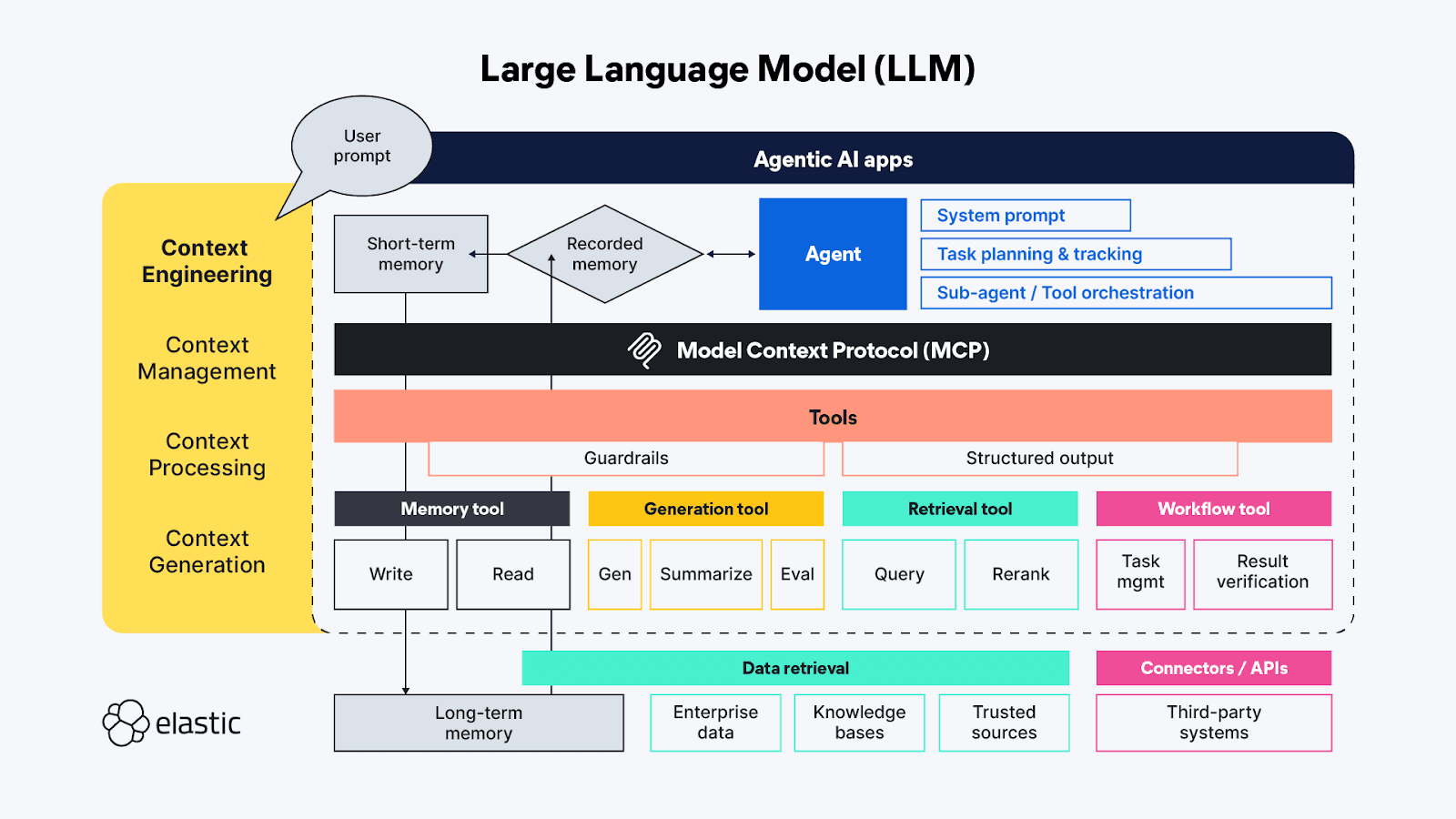
Os diversos elementos efêmeros dos aplicativos de bate-papo do LLM se relacionam diretamente (e às vezes de maneiras sobrepostas) com essas funções de alto nível da engenharia de contexto:
- Instruções / avisos do sistema - Os avisos servem de base para que a atividade de IA generativa (ou agentiva) direcione seu raciocínio para atingir o objetivo do usuário. Os prompts são um contexto por si só; não são apenas instruções de tom — frequentemente incluem lógica de execução da tarefa e regras para coisas como "pensar passo a passo" ou "respirar fundo" antes de responder, para validar se a resposta atende completamente à solicitação do usuário. Testes recentes demonstraram que as linguagens de marcação são muito eficazes para estruturar as diferentes partes de um enunciado, mas também é preciso ter cuidado para calibrar as instruções, encontrando um equilíbrio ideal entre serem vagas demais e específicas demais; queremos fornecer instruções suficientes para que o LLM encontre o contexto correto, mas não ser tão prescritivos a ponto de perder insights inesperados.
- Memória de curto prazo (estado/histórico) - A memória de curto prazo consiste essencialmente nas interações da sessão de bate-papo entre o usuário e o LLM. Essas informações são úteis para refinar o contexto em sessões ao vivo e podem ser salvas para consulta e continuação futuras.
- Memória de longo prazo - A memória de longo prazo deve consistir em informações que sejam úteis em múltiplas sessões. E não se trata apenas de bases de conhecimento específicas de domínio acessadas por meio do RAG; pesquisas recentes utilizam os resultados de solicitações anteriores de IA agentiva/generativa para aprender e referenciar em interações agentivas atuais. Algumas das inovações mais interessantes na área da memória de longo prazo estão relacionadas ao ajuste da forma como o estado é armazenado e vinculado, para que os agentes possam retomar de onde pararam.
- Saída estruturada - A cognição exige esforço, então provavelmente não é surpresa que, mesmo com capacidades de raciocínio, os LLMs (assim como os humanos) queiram despender menos esforço ao pensar e, na ausência de uma API ou protocolo definido, ter um mapa (um esquema) de como ler os dados retornados por uma chamada de ferramenta é extremamente útil. A inclusão de Saídas Estruturadas como parte da estrutura agentiva ajuda a tornar essas interações máquina a máquina mais rápidas e confiáveis, com menos necessidade de análise sintática guiada pelo pensamento.
- Ferramentas disponíveis - As ferramentas podem realizar todo tipo de tarefa, desde coletar informações adicionais (por exemplo, enviar consultas RAG para repositórios de dados corporativos ou por meio de APIs online) até executar ações automatizadas em nome do agente (como reservar um quarto de hotel com base nos critérios da solicitação do agente). As ferramentas também podem ser subagentes com suas próprias cadeias de processamento.
- Geração Aumentada por Recuperação (RAG) - Eu realmente gosto da descrição de RAG como "integração dinâmica de conhecimento". Conforme descrito anteriormente, RAG é a técnica para fornecer as informações adicionais às quais o LLM não teve acesso durante seu treinamento, ou seja, é uma reiteração das ideias que consideramos mais importantes para obter a resposta correta — aquela que é mais relevante para nossa pergunta subjetiva.
Poder cósmico fenomenal, espaço vital minúsculo!
A IA agente tem muitos novos domínios fascinantes e empolgantes para explorar! Ainda existem muitos dos antigos problemas tradicionais de recuperação e processamento de dados a serem resolvidos, mas também novas classes de desafios que só agora estão vindo à tona na nova era dos LLMs. Muitos dos problemas imediatos que estamos enfrentando hoje estão relacionados à engenharia de contexto, ou seja, a como fornecer aos LLMs (Learning Learning Machines - Máquinas de Memória de Longo Prazo) as informações contextuais adicionais de que precisam sem sobrecarregar seu espaço limitado de memória de trabalho.
A flexibilidade de agentes semiautônomos que têm acesso a uma variedade de ferramentas (e outros agentes) dá origem a tantas novas ideias para implementar IA que é difícil imaginar as diferentes maneiras pelas quais poderíamos juntar as peças. A maior parte da pesquisa atual se enquadra no campo da engenharia de contexto e está focada na construção de estruturas de gerenciamento de memória que possam lidar e rastrear quantidades maiores de contexto — isso porque os problemas de raciocínio profundo que realmente queremos que os LLMs resolvam apresentam maior complexidade e etapas de pensamento mais longas e multifásicas, onde a memorização é extremamente importante.
Grande parte da experimentação em curso na área visa encontrar a gestão de tarefas e as configurações de ferramentas ideais para alimentar a "boca" dos agentes. Cada chamada de ferramenta na cadeia de raciocínio de um agente acarreta um custo cumulativo, tanto em termos de computação necessária para executar a função dessa ferramenta quanto em termos do impacto na janela de contexto limitada. Algumas das técnicas mais recentes para gerenciar o contexto de agentes LLM causaram efeitos em cadeia indesejados, como o "colapso de contexto ", em que a compressão/resumo do contexto acumulado para tarefas de longa duração resulta em perda excessiva de dados. O objetivo é obter ferramentas que retornem um contexto conciso e preciso, sem que informações irrelevantes ocupem o valioso espaço de memória da janela de contexto.
Tantas possibilidades
Desejamos separação de funções com flexibilidade para reutilizar ferramentas/componentes, portanto, faz todo o sentido criar ferramentas dedicadas e automatizadas para conectar-se a fontes de dados específicas — cada ferramenta pode se especializar em consultar um tipo de repositório, um tipo de fluxo de dados ou até mesmo um caso de uso. Mas atenção: na ânsia de economizar tempo/dinheiro/provar que algo é possível, haverá uma forte tentação de usar os LLMs como ferramenta de federação… Tente não fazer isso, já passamos por essa situação antes! A consulta federada funciona como um "tradutor universal" que converte uma consulta recebida na sintaxe que o repositório remoto entende e, em seguida, precisa racionalizar os resultados de múltiplas fontes em uma resposta coerente. A federação como técnica funciona bem em pequenas escalas, mas em grandes escalas, e especialmente quando os dados são multimodais, a federação tenta preencher lacunas que são simplesmente muito grandes.
No mundo agentivo, o agente seria o federador e as ferramentas (através do MCP) seriam as conexões definidas manualmente com recursos distintos. Utilizar ferramentas específicas para acessar fontes de dados desconectadas pode parecer uma nova e poderosa maneira de unir dinamicamente diferentes fluxos de dados para cada consulta, mas usar essas ferramentas para fazer a mesma pergunta a várias fontes provavelmente acabará causando mais problemas do que soluções. Cada uma dessas fontes de dados provavelmente consiste em diferentes tipos de repositórios subjacentes, cada um com suas próprias capacidades de recuperar, classificar e proteger os dados neles contidos. Essas variações ou "incompatibilidades de impedância" entre os repositórios aumentam a carga de processamento, obviamente. Eles também podem introduzir informações ou sinais conflitantes, onde algo aparentemente inócuo como um desalinhamento na pontuação pode alterar drasticamente a importância atribuída a um trecho do contexto retornado e afetar a relevância da resposta gerada no final.
A troca de contexto também é difícil para os computadores.
Quando você envia um agente em uma missão, muitas vezes a primeira tarefa dele é encontrar todos os dados relevantes aos quais ele tem acesso. Assim como acontece com os humanos, se cada fonte de dados à qual o agente se conecta responde com informações diferentes e desagregadas, haverá uma carga cognitiva (embora não exatamente do mesmo tipo) associada à extração dos elementos contextuais relevantes do conteúdo recuperado. Isso requer tempo/computação, e cada pequeno detalhe se soma na cadeia lógica agentiva. Isso nos leva à conclusão de que, assim como está sendo discutido para o MCP, a maioria das ferramentas de agentes deveria se comportar mais como APIs — funções isoladas com entradas e saídas conhecidas, ajustadas para atender às necessidades de diferentes tipos de agentes. Aliás, estamos até percebendo que os LLMs precisam de contexto para contexto — eles se saem muito melhor em conectar os pontos semânticos, especialmente quando se trata de uma tarefa como traduzir linguagem natural para sintaxe estruturada, quando têm um esquema ao qual se referir (leia o manual, de fato!).
Intervalo da sétima entrada!
Já abordamos o impacto que os LLMs tiveram na recuperação e consulta de dados, bem como a forma como a janela de bate-papo está evoluindo para uma experiência de IA ativa. Vamos juntar os dois tópicos e ver como podemos usar nossos recursos modernos de busca e recuperação para melhorar nossos resultados em engenharia de contexto. Vamos para a Parte III: O poder da busca híbrida na engenharia de contexto!
Conteúdo relacionado

Descreva, não desenhe: dashboards nativos de IA do Kibana via MCP e ES|QL
Do prompt ao dashboard. Aprenda a construir dashboards do Kibana com linguagem natural, usando example-mcp-dashbuilder: uma aplicação MCP open source que escreve consultas ES|QL, cria gráficos interativos e exporta dashboards totalmente funcionais diretamente para Kibana.

8 de abril de 2026
Como criar aplicações de IA agentiva com Mastra e Elasticsearch
Aprenda como construir aplicações de IA agentiva usando Mastra e Elasticsearch com um exemplo prático.

25 de março de 2026
A ferramenta shell não é uma solução milagrosa para engenharia de contexto
Saiba quais ferramentas de recuperação de contexto existem para a engenharia de contexto, como elas funcionam e as vantagens e desvantagens.

23 de março de 2026
Usando a API de Inferência Elasticsearch junto com modelos de Hugging Face
Aprenda a conectar o Elasticsearch a modelos do Hugging Face usando endpoints de inferência e a construir um sistema multilíngue de recomendação de blogs com busca semântica e conclusões de chat.

27 de março de 2026
Criando um servidor MCP do Elasticsearch com TypeScript
Saiba como criar servidor MCP do Elasticsearch com TypeScript e Claude Desktop.