Introdução
No Elastic Stack, existem muitos aplicativos agentivos baseados em LLM, como o futuro Elastic AI Agent no Agent Builder (atualmente em versão de pré-visualização técnica) e o Attack Discovery (disponível para o público geral nas versões 8.18 e 9.0+), com mais em desenvolvimento. Durante o desenvolvimento, e mesmo após a implementação, é importante responder a estas perguntas:
- Como podemos estimar a qualidade das respostas dessas aplicações de IA?
- Se fizermos uma alteração, como podemos garantir que ela seja realmente uma melhoria e não cause deterioração na experiência do usuário?
- Como podemos testar esses resultados de forma fácil e repetível?
Diferentemente dos testes de software tradicionais, a avaliação de aplicações de IA generativa envolve métodos estatísticos, análises qualitativas minuciosas e uma compreensão profunda dos objetivos do usuário.
Este artigo detalha o processo que a equipe de desenvolvimento da Elastic utiliza para realizar avaliações, garantir a qualidade das alterações antes da implantação e monitorar o desempenho do sistema. Nosso objetivo é garantir que cada mudança seja respaldada por evidências, resultando em resultados confiáveis e verificáveis. Parte desse processo está integrada diretamente ao Kibana, refletindo nosso compromisso com a transparência como parte de nossa filosofia de código aberto. Ao compartilhar abertamente partes de nossos dados e métricas de avaliação, buscamos fomentar a confiança da comunidade e fornecer uma estrutura clara para qualquer pessoa que desenvolva agentes de IA ou utilize nossos produtos.
Exemplos de produtos
Os métodos utilizados neste documento serviram de base para a forma como iteramos e aprimoramos soluções como o Attack Discovery e o Elastic AI Agent. Uma breve introdução aos dois, respectivamente:
Descoberta de ataques da Elastic Security
A descoberta de ataques utiliza LLMs para identificar e resumir sequências de ataques no Elastic. Com base nos alertas do Elastic Security em um determinado período (padrão de 24 horas), o fluxo de trabalho automatizado do Attack Discovery identificará automaticamente se ocorreram ataques, além de informações importantes, como quais hosts ou usuários foram comprometidos e quais alertas contribuíram para essa conclusão.

O objetivo é que a solução baseada em LLM produza um resultado pelo menos tão bom quanto o de um ser humano.
Agente de IA Elástico
O Elastic Agent Builder é a nossa nova plataforma para criar agentes de IA sensíveis ao contexto que aproveitam todos os nossos recursos de busca. Ele vem com o Elastic AI Agent, um agente pré-construído de uso geral, projetado para ajudar os usuários a entender e obter respostas a partir de seus dados por meio de interação conversacional.
O agente consegue isso identificando automaticamente informações relevantes no Elasticsearch ou em bases de conhecimento conectadas e utilizando um conjunto de ferramentas pré-construídas para interagir com elas. Isso permite que o Elastic AI Agent responda a uma ampla gama de consultas de usuários, desde perguntas e respostas simples sobre um único documento até solicitações complexas que exigem agregação e buscas de uma ou várias etapas em diversos índices.
Medindo melhorias por meio de experimentos
No contexto de agentes de IA, um experimento é uma mudança estruturada e testável no sistema, projetada para melhorar o desempenho em dimensões bem definidas (por exemplo, utilidade, correção, latência). O objetivo é responder de forma definitiva: "Se incorporarmos essa alteração, podemos garantir que ela representa uma melhoria real e não prejudicará a experiência do usuário?"
A maioria dos experimentos que realizamos geralmente inclui:
- Uma hipótese: uma afirmação específica e falseável. Exemplo: “Adicionar acesso a uma ferramenta de descoberta de ataques melhora a precisão das consultas relacionadas à segurança.”
- Critérios de sucesso: Limiares claros que definem o que significa "sucesso". Exemplo: “Melhoria de 5% na pontuação de correção no conjunto de dados de segurança, sem degradação em outros locais.”
- Plano de avaliação: Como medimos o sucesso (métricas, conjuntos de dados, método de comparação)
Um experimento bem-sucedido é um processo sistemático de investigação. Toda alteração, desde um pequeno ajuste de um prompt até uma grande mudança arquitetônica, segue estes sete passos para garantir que os resultados sejam significativos e acionáveis:
- Etapa 1: Identificar o problema
- Etapa 2: Definir métricas
- Etapa 3: Formule uma hipótese clara
- Etapa 4: Preparar o conjunto de dados de avaliação
- Etapa 5: Execute o experimento
- Etapa 6: Analisar resultados + iterar
- Etapa 7: Tome uma decisão e documente-a.
Um exemplo dessas etapas é ilustrado na Figura 1. As subseções a seguir explicarão cada etapa, e detalharemos os aspectos técnicos de cada etapa em documentos futuros.

Figura 1: Etapas do ciclo de vida da experimentação
Passo a passo com exemplos reais do Elastic
Etapa 1: Identificar o problema
Qual é exatamente o problema que essa mudança visa resolver?
Exemplo de detecção de ataques: os resumos são ocasionalmente incompletos ou atividades benignas são erroneamente sinalizadas como ataques (falsos positivos).
Exemplo de agente de IA elástica: a seleção de ferramentas do agente, especialmente para consultas analíticas, é subótima e inconsistente, muitas vezes levando à escolha da ferramenta errada. Isso, por sua vez, aumenta os custos dos tokens e a latência.
Etapa 2: Definir métricas
Torne o problema mensurável, para que possamos comparar uma mudança com o estado atual.
As métricas comuns incluem precisão e revocação, similaridade semântica, factualidade, e assim por diante. Dependendo do caso de uso, utilizamos verificações de código para calcular as métricas, como a correspondência de IDs de alerta ou URLs recuperados corretamente, ou técnicas como LLM-as-judge para respostas mais livres.
Abaixo estão alguns exemplos (lista não exaustiva) de métricas usadas nos experimentos:
Descoberta de ataques
| Métrica | Descrição |
|---|---|
| Precisão e memorização | Compare os IDs de alerta entre as saídas reais e esperadas para medir a precisão da detecção. |
| Semelhança | Utilize o BERTScore para comparar a similaridade semântica do texto de resposta. |
| Factualidade | Os principais indicadores de comprometimento (IOCs) estão presentes? As táticas MITRE (taxonomia de ataques do setor) estão corretamente representadas? |
| Consistência da cadeia de ataque | Compare o número de descobertas para verificar se houve superestimação ou subestimação da notificação do ataque. |
Agente de IA Elástico
| Métrica | Descrição |
|---|---|
| Precisão e memorização | Comparar os documentos/informações recuperados pelo agente para responder a uma consulta do usuário com as informações ou documentos realmente necessários para responder à consulta, a fim de medir a precisão da recuperação de informações. |
| Factualidade | Os principais fatos necessários para responder à consulta do usuário estão presentes? Os fatos estão na ordem correta para questões processuais? |
| Relevância da resposta | A resposta contém informações periféricas ou não relacionadas à consulta do usuário? |
| Completude da resposta | A resposta atende a todas as partes da consulta do usuário? A resposta contém todas as informações presentes na verdade fundamental? |
| Validação ES|QL | O código ES|QL gerado está sintaticamente correto? É funcionalmente idêntico ao ES|QL original? |
Etapa 3: Formule uma hipótese clara
Estabeleça critérios de sucesso claros usando o problema e as métricas definidas acima.
Exemplo de agente de IA elástico:
- Implementar alterações nas descrições das ferramentas relevance_search e nl_search para definir claramente suas funções e casos de uso específicos.
- Prevemos que melhoraremos a precisão da invocação de nossa ferramenta em 25%.
- Verificaremos se isso representa um saldo positivo, garantindo que não haja impacto negativo em outras métricas, por exemplo... factualidade e completude.
- Acreditamos que isso funcionará porque descrições precisas das ferramentas ajudarão o agente a selecionar e aplicar com mais exatidão a ferramenta de busca mais adequada para diferentes tipos de consulta, reduzindo o uso incorreto e melhorando a eficácia geral da busca.
Etapa 4: Preparar o conjunto de dados de avaliação
Para medir o desempenho do sistema, utilizamos conjuntos de dados que capturam cenários do mundo real.
Dependendo do tipo de avaliação que estivermos realizando, podemos precisar de diferentes formatos de dados, como dados brutos inseridos em um LLM (por exemplo, cenários de ataque para descoberta de ataques) e resultados esperados. Se o aplicativo for um chatbot, as entradas podem ser consultas do usuário e as saídas podem ser respostas corretas do chatbot, links corretos que ele deveria ter recuperado e assim por diante.
Exemplo de descoberta de ataques:
| 10 novos cenários de ataque |
|---|
| 8 episódios de Oh My Malware (ohmymalware.com) |
| 4 cenários de múltiplos ataques (criados pela combinação de ataques nas duas primeiras categorias) |
| 3 cenários benignos |
Exemplo de conjunto de dados para avaliação de agentes de IA elástica (Link para o conjunto de dados do Kibana):
| 14 Índices que utilizam conjuntos de dados de código aberto para simular múltiplas fontes em KB. |
|---|
| 5 tipos de consulta (analítica, recuperação de texto, híbrida…) |
| 7 tipos de intenção de consulta (procedimental, factual - classificação, investigativa; …) |
Etapa 5: Execute o experimento
Execute o experimento gerando respostas tanto do agente existente quanto da versão modificada em relação ao conjunto de dados de avaliação. Calcule métricas como a veracidade factual (ver passo 2).
Combinamos diversas avaliações com base nas métricas exigidas na Etapa 2:
- Avaliação baseada em regras (por exemplo, (Use Python/TypeScript para verificar se o arquivo .json é válido)
- LLM como juiz (consultar um LLM separado para verificar se uma resposta é factualmente consistente com um documento original)
- Revisão com intervenção humana para verificações de qualidade e nuances.

Este é um exemplo de resultado de avaliação gerado por nossa estrutura interna. Apresenta diversas métricas de um experimento realizado em diferentes conjuntos de dados.
Etapa 6: Analisar resultados + iterar
Agora que temos as métricas, vamos analisar os resultados. Mesmo que os resultados atendam aos critérios de sucesso definidos na etapa 3, ainda faremos uma revisão humana antes de incorporar a alteração à produção; se os resultados não atenderem aos critérios, iteraremos e corrigiremos os problemas e, em seguida, executaremos as avaliações na nova alteração.
Prevemos que serão necessárias algumas iterações para encontrarmos a melhor alteração antes de a consolidarmos. Assim como é feito executar testes de software locais antes de enviar uma alteração, as avaliações offline podem ser executadas com alterações locais ou com várias alterações propostas. Automatizar o salvamento de resultados experimentais, pontuações compostas e visualizações é útil para agilizar a análise.
Etapa 7: Tome uma decisão e documente-a.
Com base em uma estrutura de decisão e critérios de aceitação, decida sobre a incorporação da alteração e documente o experimento. A tomada de decisões é multifacetada e pode considerar fatores que vão além do conjunto de dados de avaliação, como verificar cenários de regressão em outros conjuntos de dados ou ponderar o custo-benefício de uma mudança proposta.
Exemplo: Após testar e comparar algumas iterações, escolha a alteração com a melhor pontuação para enviar aos gerentes de produto e outras partes interessadas relevantes para aprovação. Anexe os resultados das etapas anteriores para auxiliar na tomada de decisão. Para mais exemplos sobre a descoberta de ataques, consulte Nos bastidores dos recursos de IA generativa do Elastic Security.
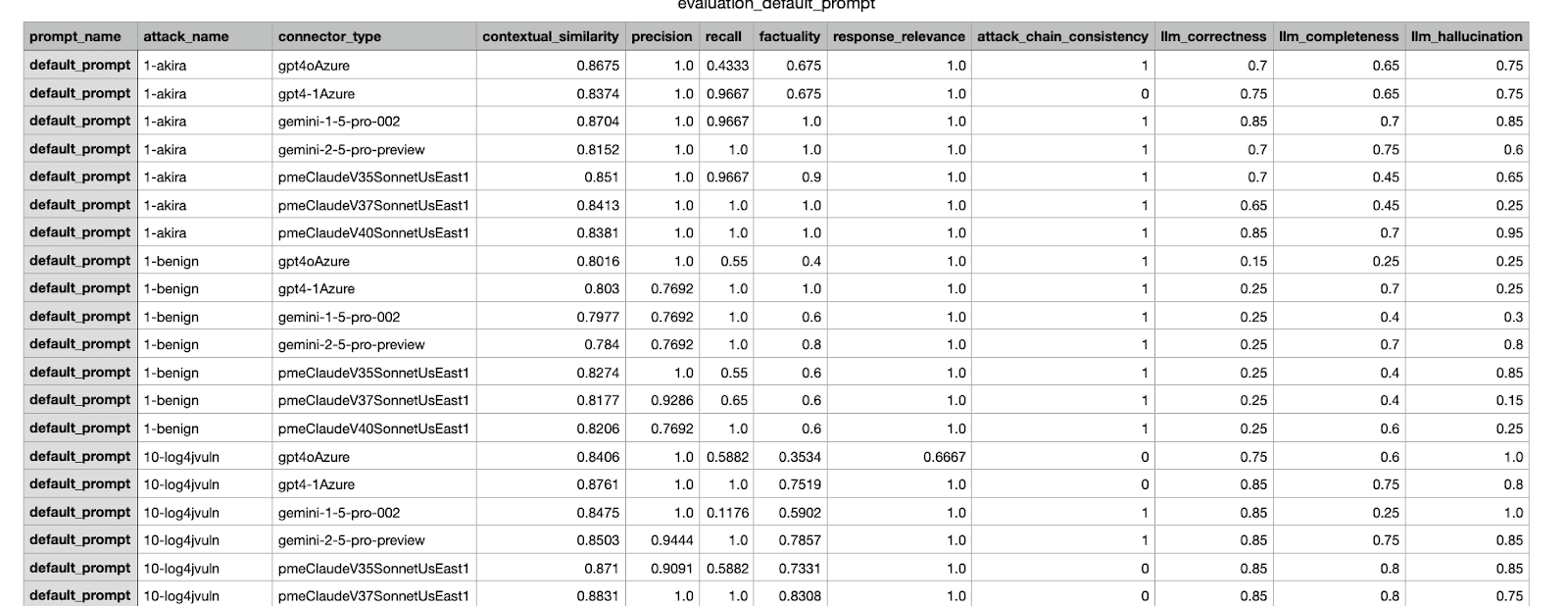
Exemplo de um relatório CSV enviado às partes interessadas; o experimento com a pontuação mais alta foi selecionado para ser incorporado.
Conclusão
Neste blog, descrevemos o processo completo de um fluxo de trabalho de experimento, ilustrando como avaliamos e testamos as alterações em um sistema de agentes antes de disponibilizá-las aos usuários da Elastic. Também fornecemos alguns exemplos de como aprimorar fluxos de trabalho baseados em agentes no Elastic. Em publicações subsequentes no blog, detalharemos diferentes etapas, como criar um bom conjunto de dados, projetar métricas confiáveis e tomar decisões quando várias métricas estão envolvidas.
Conteúdo relacionado

Descreva, não desenhe: dashboards nativos de IA do Kibana via MCP e ES|QL
Do prompt ao dashboard. Aprenda a construir dashboards do Kibana com linguagem natural, usando example-mcp-dashbuilder: uma aplicação MCP open source que escreve consultas ES|QL, cria gráficos interativos e exporta dashboards totalmente funcionais diretamente para Kibana.

8 de abril de 2026
Como criar aplicações de IA agentiva com Mastra e Elasticsearch
Aprenda como construir aplicações de IA agentiva usando Mastra e Elasticsearch com um exemplo prático.

25 de março de 2026
A ferramenta shell não é uma solução milagrosa para engenharia de contexto
Saiba quais ferramentas de recuperação de contexto existem para a engenharia de contexto, como elas funcionam e as vantagens e desvantagens.

23 de março de 2026
Usando a API de Inferência Elasticsearch junto com modelos de Hugging Face
Aprenda a conectar o Elasticsearch a modelos do Hugging Face usando endpoints de inferência e a construir um sistema multilíngue de recomendação de blogs com busca semântica e conclusões de chat.

27 de março de 2026
Criando um servidor MCP do Elasticsearch com TypeScript
Saiba como criar servidor MCP do Elasticsearch com TypeScript e Claude Desktop.