벡터 검색부터 강력한 REST API에 이르기까지 Elasticsearch는 개발자에게 가장 광범위한 검색 툴킷을 제공합니다. Elasticsearch Labs 리포지토리의 샘플 노트북을 살펴보고 새로운 기능을 직접 체험해 보세요. 무료 체험을 시작하거나 지금 바로 Elasticsearch를 로컬에서 실행해 보세요.
Go를 포함한 모든 프로그래밍 언어로 소프트웨어를 구축하는 것은 평생에 걸친 학습에 전념하는 것입니다. 대학과 직장 경력을 통해 Carly는 벡터 검색의 최신 및 최고의 구현을 포함하여 많은 프로그래밍 언어와 기술을 다뤄왔습니다. 하지만 그것만으로는 충분하지 않았습니다! 그래서 최근에 칼리도 바둑을 시작했습니다.
동물, 프로그래밍 언어, 친근한 작가와 마찬가지로 검색도 검색 사용 사례에 따라 결정하기 어려울 정도로 다양한 방식으로 진화해 왔습니다. 이 블로그에서는 벡터 검색에 대한 개요와 함께 Elasticsearch와 Elasticsearch Go 클라이언트를 사용한 각 접근 방식의 예를 공유하겠습니다. 이 예제에서는 Elasticsearch와 Go에서 벡터 검색을 사용해 고퍼를 찾고 고퍼가 무엇을 먹는지 알아내는 방법을 보여드립니다.
필수 구성 요소
이 예제를 따라 하려면 다음 전제 조건이 충족되는지 확인하세요:
- Go 버전 1.21 이상 설치
- 를 사용하여 나만의 Go 리포지토리를 생성합니다.
- 위키피디아에서 친숙한 Gopher를 포함한 설치류 기반 페이지 세트로 채워진 자체 Elasticsearch 클러스터를 생성합니다:
Elasticsearch에 연결
이 예제에서는 Go 클라이언트에서 제공하는 Typed API를 사용하겠습니다. 쿼리에 대한 보안 연결을 설정하려면 다음 중 하나를 사용하여 클라이언트를 구성해야 합니다:
- Elastic Cloud를 사용하는 경우 클라우드 ID와 API 키입니다.
- 클러스터 URL, 사용자 이름, 비밀번호 및 인증서를 입력합니다.
Elastic Cloud에 위치한 클러스터에 연결하면 다음과 같이 됩니다:
그런 다음 다음 섹션에 표시된 것처럼 client 연결을 벡터 검색에 사용할 수 있습니다.
벡터 검색
벡터 검색은 벡터를 사용하여 검색 문제를 수학적 비교로 변환하여 이 문제를 해결하려고 시도합니다. 문서 임베딩 프로세스에는 모델을 사용하여 문서를 고밀도 벡터 표현 또는 단순히 숫자 스트림으로 변환하는 추가 단계가 있습니다. 이 접근 방식의 장점은 이미지나 오디오와 같은 텍스트가 아닌 문서를 쿼리와 함께 벡터로 변환하여 검색할 수 있다는 점입니다.
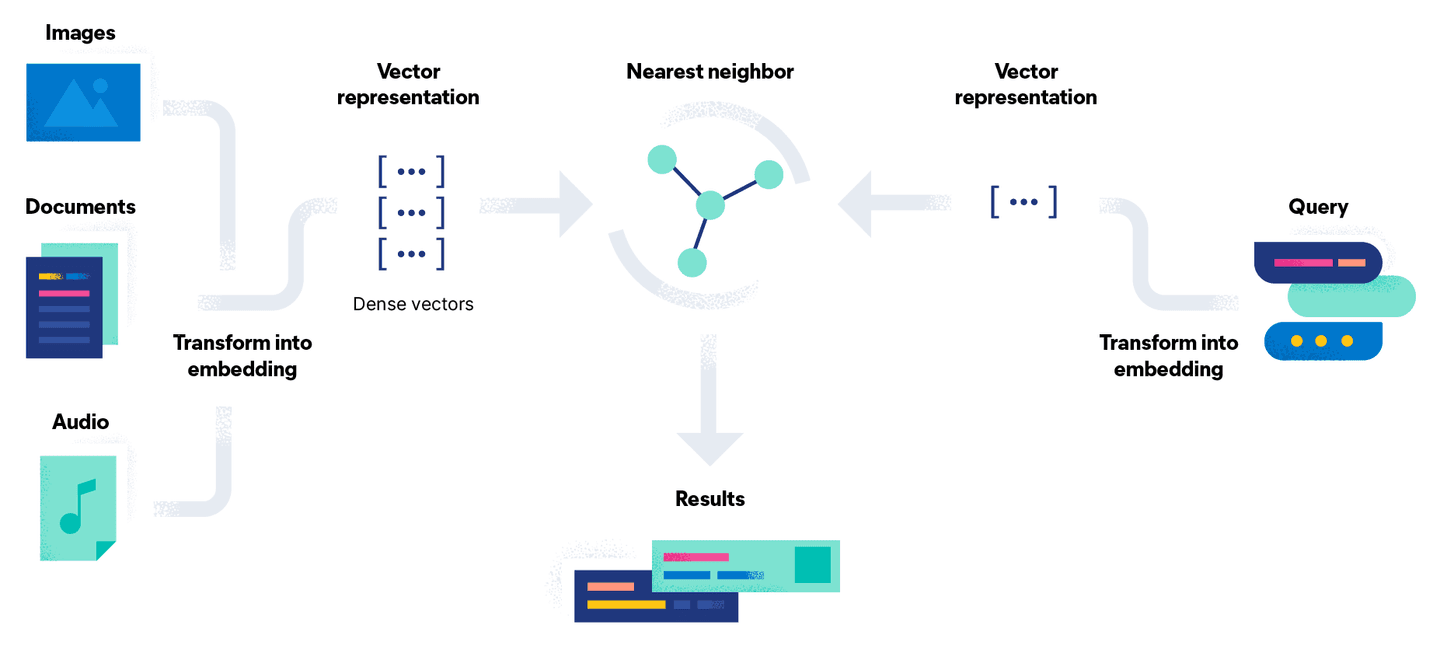
간단히 말해서 벡터 검색은 벡터 거리 계산의 집합입니다. 아래 그림에서는 쿼리 Go Gopher의 벡터 표현을 벡터 공간의 문서와 비교하여 가장 가까운 결과(상수 k 로 표시됨)를 반환합니다:

문서 임베딩을 생성하는 데 사용하는 접근 방식에 따라 고퍼가 무엇을 먹는지 알아내는 방법은 두 가지가 있습니다.
접근 방식 1: 나만의 모델 가져오기
플래티넘 라이선스를 사용하면 모델을 업로드하고 추론 API를 사용하여 Elasticsearch 내에서 임베딩을 생성할 수 있습니다. 모델을 설정하는 데는 6단계가 있습니다:
- 모델 리포지토리에서 업로드할 PyTorch 모델을 선택합니다. 이 예제에서는 임베딩을 생성하기 위해 Hugging Face의 문장 트랜스포머/msmarco-MiniLM-L-12-v3를 사용하고 있습니다.
- Elasticsearch 클러스터에 대한 자격 증명과 작업 유형
text_embeddings을 사용하여 Python용 Eland Machine Learning 클라이언트를 사용하여 모델을 Elastic에 로드합니다. Eland가 설치되어 있지 않은 경우 아래와 같이 Docker를 사용하여 가져오기 단계를 실행할 수 있습니다:
- 업로드가 완료되면 샘플 문서로
sentence-transformers__msmarco-minilm-l-12-v3모델을 빠르게 테스트하여 임베딩이 예상대로 생성되는지 확인합니다:

- 추론 프로세서가 포함된 수집 파이프라인을 만듭니다. 이렇게 하면 업로드한 모델을 사용하여 벡터 표현을 생성할 수 있습니다:
- 각 문서에 대해 생성된 벡터 임베딩을 저장하기 위해
dense_vector유형의text_embedding.predicted_value필드를 포함하는 새 인덱스를 만듭니다:
- 새로 생성된 수집 파이프라인을 사용하여 문서를 재색인하여 각 문서에 추가 필드
text_embedding.predicted_value로 텍스트 임베딩을 생성합니다:
이제 아래 예시와 같이 새 인덱스 vector-search-rodents 를 사용하여 동일한 검색 API에서 Knn 옵션을 사용할 수 있습니다:
마샬링 해제를 통해 JSON 결과 객체를 변환하는 것은 키워드 검색 예제와 똑같은 방식으로 수행됩니다. 상수 K 및 NumCandidates 을 사용하여 반환할 이웃 문서의 수와 샤드당 고려할 후보의 수를 구성할 수 있습니다. 후보자 수를 늘리면 결과의 정확도는 높아지지만 더 많은 비교가 수행되므로 쿼리 실행 시간이 길어집니다.
What do Gophers eat? 쿼리를 사용하여 코드를 실행하면 반환되는 결과는 아래와 유사하게 표시되며, 이전 키워드 검색과 달리 Gopher 문서에 요청된 정보가 포함되어 있음을 강조합니다:
접근 방식 2: 허깅 얼굴 추론 API
또 다른 옵션은 Elasticsearch 외부에서 동일한 임베딩을 생성하여 문서의 일부로 수집하는 것입니다. 이 옵션은 Elasticsearch 머신 러닝 노드를 사용하지 않으므로 무료 티어에서 수행할 수 있습니다.
허깅 페이스는 무료로 사용할 수 있는 속도 제한이 없는 추론 API를 제공하며, 계정과 API 토큰을 사용하면 실험 및 프로토타이핑을 위해 동일한 임베딩을 수동으로 생성하여 시작할 수 있습니다. 프로덕션용으로는 권장하지 않습니다. 로컬에서 자체 모델을 호출하여 임베딩을 생성하거나 유료 API를 사용하는 것도 비슷한 방식으로 수행할 수 있습니다.
아래 함수 GetTextEmbeddingForQuery 에서는 쿼리 문자열에 대한 추론 API를 사용하여 POST 요청에서 엔드포인트로 반환된 벡터를 생성합니다:
그런 다음 []float32 유형의 결과 벡터가 QueryVectorBuilder 옵션을 사용하는 대신 QueryVector 으로 전달되어 이전에 Elastic에 업로드한 모델을 활용합니다.
K 및 NumCandidates 옵션은 두 옵션에 관계없이 동일하게 유지되며 동일한 모델을 사용하여 임베딩을 생성하기 때문에 동일한 결과가 생성됩니다.
결론
여기서는 Elasticsearch Go 클라이언트를 사용하여 Elasticsearch에서 벡터 검색을 수행하는 방법에 대해 설명했습니다. 이 시리즈의 모든 코드는 GitHub 리포지토리에서 확인하세요. 3부에서는 1부에서 다룬 벡터 검색과 키워드 검색 기능을 Go에서 결합하는 방법에 대한 개요를 살펴봅니다.
그때까지 고퍼 사냥을 즐기세요!
리소스
관련 콘텐츠

2026년 4월 23일
세계에서 가장 빠른 벡터 검색을 위해 Elasticsearch simdvec을 구축한 방법
Elasticsearch의 모든 벡터 검색 쿼리 뒤에 있는 수동 조정 SIMD 커널 라이브러리인 Elasticsearch simdvec을 어떻게 구축했는지 알아보세요.

Elasticsearch 검색 리콜을 측정하고 개선하는 방법: 하이브리드 검색을 통해 0.43에서 0.75로 향상하기
BM25 어휘 검색과 Jina AI 벡터 임베딩을 결합하여 Elasticsearch에서 검색 회상률을 측정하고 개선하는 방법을 알아보고, rank_eval API를 사용해 실제 숫자로 개선 효과를 검증하세요.

Elasticsearch와 Jina 임베딩을 활용한 비지도형 문서 클러스터링
Elasticsearch와 Jina 임베딩을 활용한 비지도형 문서 클러스터링을 위한 실용적이고 재현 가능한 접근 방식.

TSDS와 ILM의 만남: 늦게 도착하는 데이터를 거부하지 않는 시계열 데이터 스트림 설계
TSDS 시간 제한이 ILM 단계와 상호 작용하는 방법과 늦게 도착하는 메트릭을 처리할 수 있는 정책 설계 방법

LINQ to Elasticsearch ES|QL: C# 작성, Elasticsearch 쿼리
Elasticsearch .NET 클라이언트의 새로운 LINQ to Elasticsearch ES|QL 제공자를 살펴보세요. 이 제공자를 사용하면 C# 코드를 작성하여 ES|QL 쿼리로 자동 변환할 수 있습니다.