벡터 검색부터 강력한 REST API에 이르기까지 Elasticsearch는 개발자에게 가장 광범위한 검색 툴킷을 제공합니다. Elasticsearch Labs 리포지토리의 샘플 노트북을 살펴보고 새로운 기능을 직접 체험해 보세요. 무료 체험을 시작하거나 지금 바로 Elasticsearch를 로컬에서 실행해 보세요.
소개
전 세계 사용자가 있는 세계에서는 다국어 정보 검색(CLIR)이 매우 중요합니다. CLIR은 검색을 단일 언어로 제한하는 대신 모든 언어로 정보를 찾을 수 있도록 하여 사용자 경험을 개선하고 운영을 간소화합니다. 이커머스 고객이 자신의 언어로 상품을 검색하면 데이터를 미리 현지화할 필요 없이 적절한 결과가 표시되는 글로벌 시장을 상상해 보세요. 또는 학술 연구자들이 뉘앙스와 복잡성이 있는 논문을 모국어로 검색할 수 있으며, 출처가 다른 언어로 되어 있어도 검색할 수 있습니다.
다국어 텍스트 임베딩 모델을 사용하면 바로 그렇게 할 수 있습니다. 임베딩은 텍스트의 의미를 숫자 벡터로 표현하는 방법입니다. 이 벡터는 비슷한 의미를 가진 텍스트가 고차원 공간에서 서로 가깝게 위치하도록 설계되었습니다. 특히 다국어 텍스트 임베딩 모델은 여러 언어에서 동일한 의미를 가진 단어와 구문을 유사한 벡터 공간에 매핑하도록 설계되었습니다.
오픈 소스 다국어 E5와 같은 모델은 대개 대조 학습과 같은 기술을 사용하여 방대한 양의 텍스트 데이터를 학습합니다. 이 접근 방식에서 모델은 유사한 의미를 가진 텍스트 쌍(양의 쌍)과 서로 다른 의미를 가진 텍스트 쌍(음의 쌍)을 구별하는 방법을 학습합니다. 모델은 양성 쌍 간의 유사도는 최대화하고 음성 쌍 간의 유사도는 최소화하도록 생성하는 벡터를 조정하도록 학습됩니다. 다국어 모델의 경우 이 학습 데이터에는 서로 다른 언어로 된 텍스트 쌍이 포함되어 있어 모델이 여러 언어에 대한 공유 표현 공간을 학습할 수 있습니다. 이렇게 생성된 임베딩은 쿼리의 언어에 관계없이 텍스트 임베딩 간의 유사성을 사용하여 관련 문서를 찾는 교차 언어 검색을 비롯한 다양한 NLP 작업에 사용할 수 있습니다.
다국어 벡터 검색의 이점
- 뉘앙스: 벡터 검색은 키워드 매칭을 넘어 의미론적 의미를 포착하는 데 탁월합니다. 이는 언어의 맥락과 미묘한 차이를 이해해야 하는 작업에 매우 중요합니다.
- 언어 간 이해: 쿼리와 문서가 서로 다른 어휘를 사용하는 경우에도 여러 언어에서 효과적으로 정보를 검색할 수 있습니다.
- 연관성: 쿼리와 문서 간의 개념적 유사성에 초점을 맞춰 보다 관련성 높은 결과를 제공합니다.
예를 들어, 여러 국가에서 소셜 미디어가 정치 담론에 미치는 영향( ")을 연구하는 학계 연구자(" )가 있다고 가정해 보겠습니다. 벡터 검색을 사용하면 "l'impatto dei social media sul discorso politico" (이탈리아어) 또는 "ảnh hưởng của mạng xã hội đối với diễn ngôn chính trị" (베트남어) 같은 검색어를 입력하면 관련 문서를 영문으로 찾을 수 있습니다, 스페인어 또는 기타 색인된 언어로 된 관련 문서를 찾아보세요. 벡터 검색은 정확한 키워드가 포함된 논문뿐만 아니라 소셜 미디어가 정치에 미치는 영향에 대한 개념을 논의하는 논문도 찾아내기 때문입니다. 이를 통해 연구의 폭과 깊이를 크게 향상시킬 수 있습니다.
시작하기
기본으로 제공되는 E5 모델을 사용하여 Elasticsearch를 사용하여 CLIR을 설정하는 방법은 다음과 같습니다. 여러 언어로 된 이미지 캡션이 포함된 오픈 소스 다국어 COCO 데이터셋을 사용하여 두 가지 유형의 검색을 시각화해 보겠습니다:
- 하나의 영어 데이터 세트에서 다른 언어로 된 쿼리 및 검색어, 그리고
- 여러 언어로 된 문서가 포함된 데이터 집합을 기반으로 여러 언어로 쿼리할 수 있습니다.
그런 다음 하이브리드 검색과 재랭크의 힘을 활용하여 검색 결과를 더욱 개선할 것입니다.
필수 구성 요소
- Python 3.6+
- Elasticsearch 8+
- Elasticsearch Python 클라이언트: pip 설치 elasticsearch
데이터 세트
COCO 데이터 세트 는 대규모 캡션 데이터 세트입니다. 데이터 세트의 각 이미지는 여러 언어로 캡션되어 있으며, 언어별로 여러 번역본을 사용할 수 있습니다. 데모용으로 각 번역을 개별 문서로 색인화하여 참조할 수 있도록 가장 먼저 제공되는 영어 번역과 함께 보여드리겠습니다.
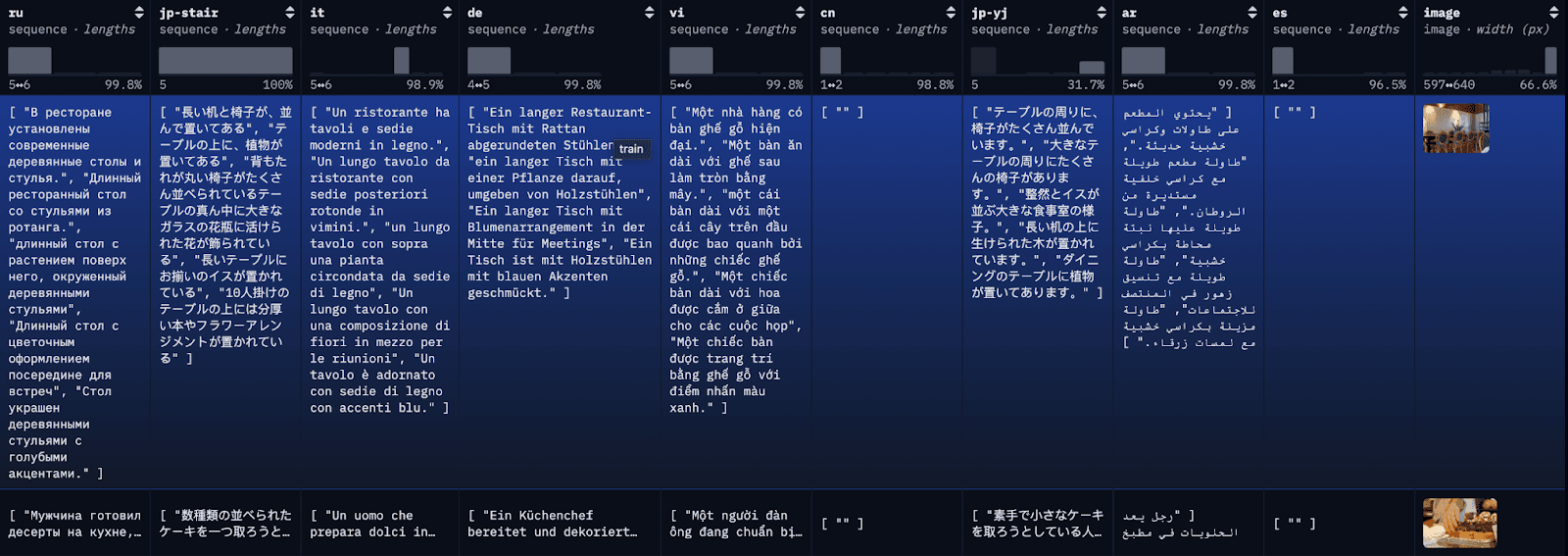
1단계: 다국어 COCO 데이터 세트 다운로드
블로그를 단순화하고 쉽게 따라갈 수 있도록 여기서는 간단한 API 호출을 통해 restval의 처음 100개 행을 로컬 JSON 파일에 로드합니다. 또는 허깅페이스의 라이브러리 데이터셋을 사용하여 전체 데이터셋 또는 데이터셋의 하위 집합을 로드할 수도 있습니다.
데이터가 JSON 파일에 성공적으로 로드되면 다음과 비슷한 내용이 표시됩니다:
Data successfully downloaded and saved to multilingual_coco_sample.json
2단계: (Elasticsearch를 시작하고) Elasticsearch에서 데이터 색인하기
a) 로컬 Elasticsearch 서버를 시작합니다.
b) Elasticsearch 클라이언트를 시작합니다.
c) 인덱스 데이터
데이터가 색인되면 다음과 비슷한 내용이 표시됩니다:
Successfully bulk indexed 4840 documents
Indexing complete!
3단계: E5 학습된 모델 배포하기
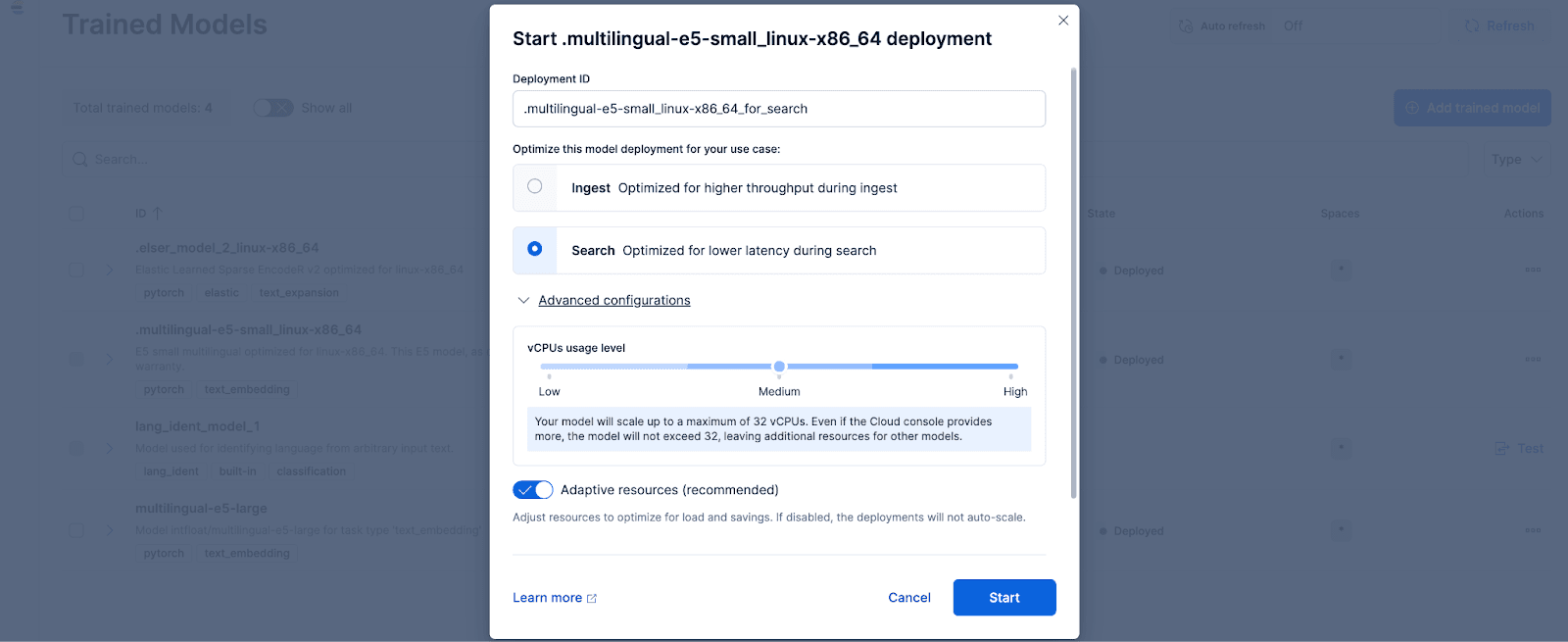
Kibana에서 스택 관리 > 학습된 모델 페이지로 이동하고 .multilingual-e5-small_linux-x86_64에 대한 배포를 클릭합니다. 옵션을 선택합니다. 이 E5 모델은 Linux-x86_64에 최적화된 소규모 다국어 버전으로, 즉시 사용할 수 있습니다. '배포'를 클릭하면 배포 설정 또는 vCPU 구성을 조정할 수 있는 화면이 표시됩니다. 간단하게 하기 위해 사용량에 따라 배포를 자동으로 확장하는 적응형 리소스를 선택한 기본 옵션을 사용하겠습니다.
선택적으로 다른 텍스트 임베딩 모델을 사용하려는 경우 사용할 수 있습니다. 예를 들어, BGE-M3를 사용하려면 Elastic의 Eland Python 클라이언트를 사용하여 HuggingFace에서 모델을 가져올 수 있습니다.
그런 다음 학습된 모델 페이지로 이동하여 가져온 모델을 원하는 구성으로 배포합니다.
4단계: 배포된 모델을 사용하여 원본 데이터에 대한 임베딩을 벡터화하거나 생성합니다.
임베딩을 생성하려면 먼저 텍스트를 가져와 추론 텍스트 임베딩 모델을 통해 실행할 수 있는 수집 파이프라인을 만들어야 합니다. 이 작업은 Kibana의 사용자 인터페이스 또는 Elasticsearch의 API를 통해 수행할 수 있습니다.
Kibana 인터페이스를 통해 이 작업을 수행하려면, 학습된 모델을 배포한 후 테스트 버튼을 클릭합니다. 이렇게 하면 생성된 임베딩을 테스트하고 미리 볼 수 있습니다. coco 인덱스에 대한 새 데이터 보기를 만들고, 데이터 보기를 새로 만든 코코 데이터 보기로 설정하고, 필드를 임베딩을 생성할 필드이므로 description 로 설정합니다.
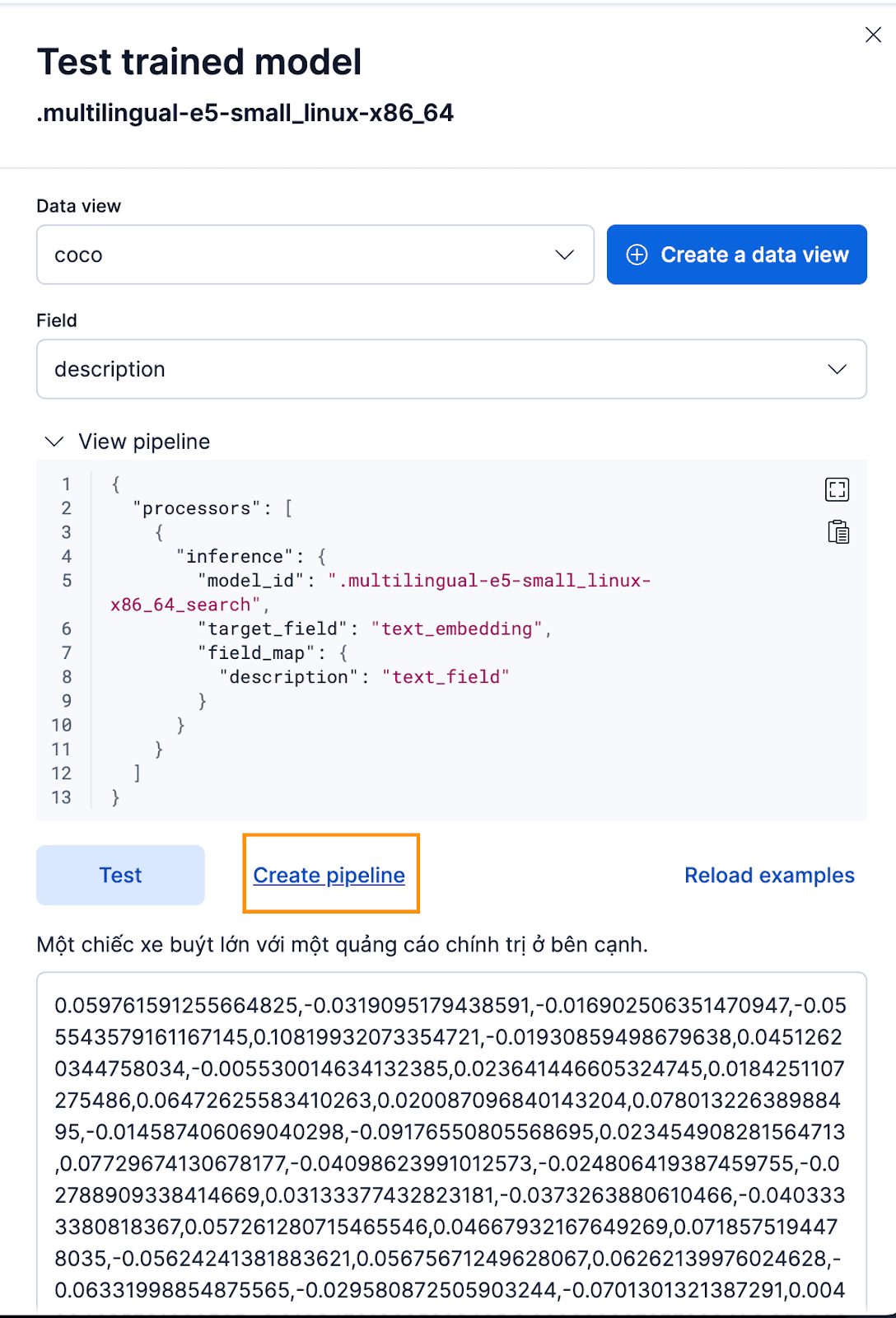
잘 작동합니다! 이제 수집 파이프라인을 생성하고 원본 문서를 재색인하고 파이프라인을 통과하여 임베딩이 포함된 새 인덱스를 생성할 수 있습니다. 파이프라인 생성을 클릭하면 임베딩을 만드는 데 필요한 프로세서가 자동으로 채워지는 파이프라인 생성 프로세스를 안내합니다.
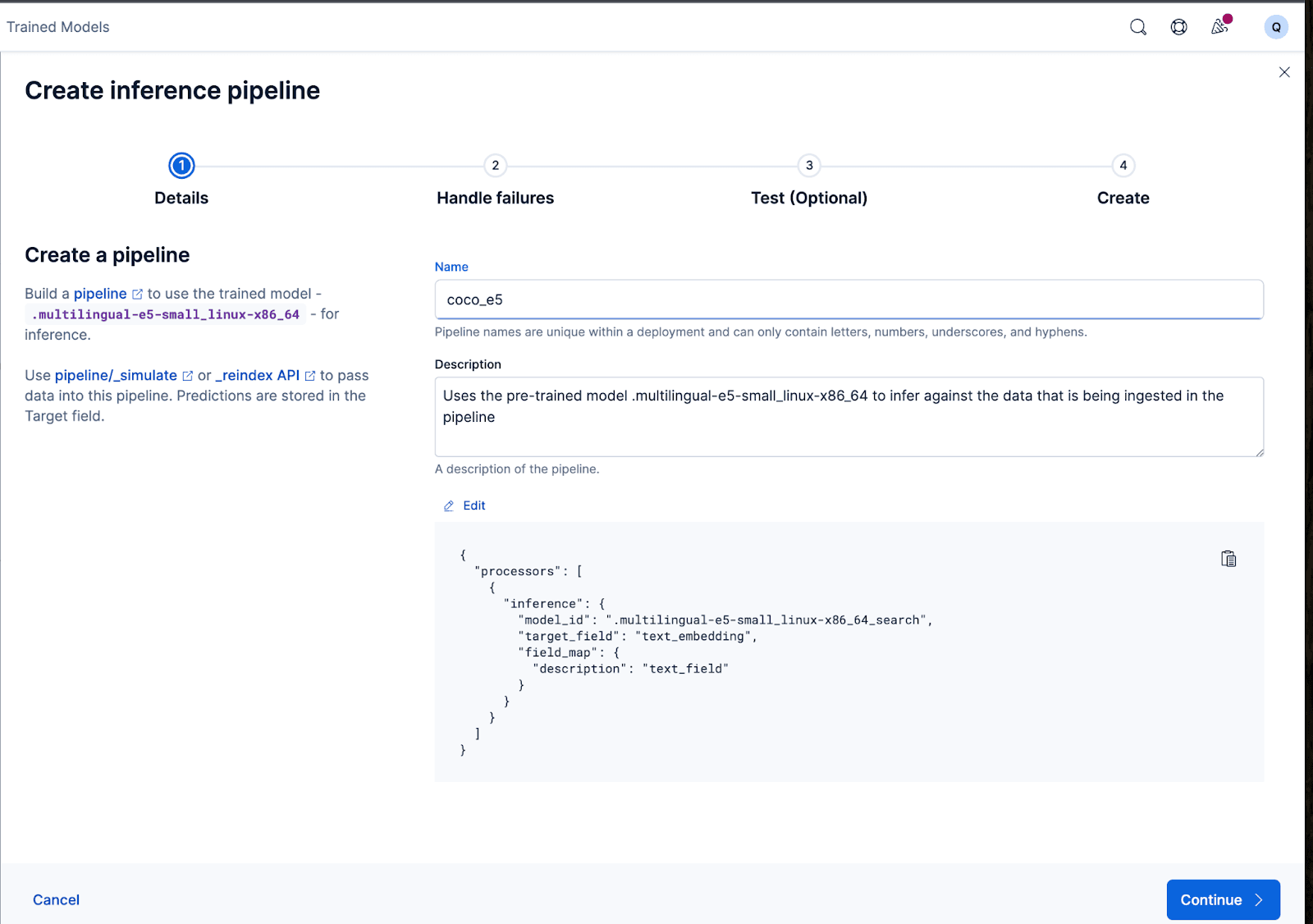
마법사는 데이터를 수집하고 처리하는 동안 장애를 처리하는 데 필요한 프로세서를 자동으로 채울 수도 있습니다.
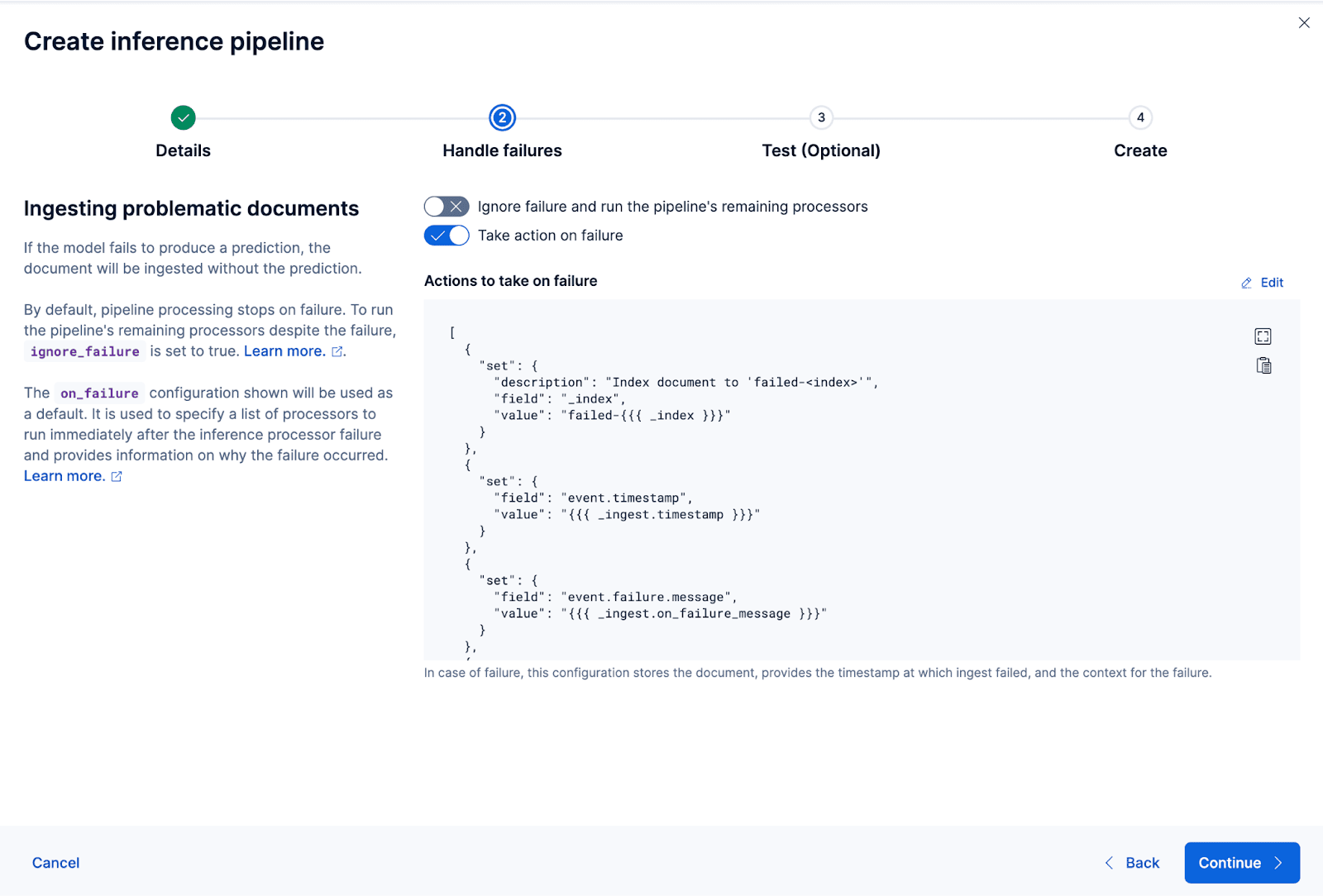
이제 수집 파이프라인을 만들어 보겠습니다. 파이프라인의 이름을 coco_e5 으로 지정합니다. 파이프라인이 성공적으로 생성되면, 마법사에서 원래 색인된 데이터를 새 색인으로 재색인하여 임베딩을 생성하는 데 즉시 파이프라인을 사용할 수 있습니다. 색인 재생성을 클릭하여 프로세스를 시작합니다.
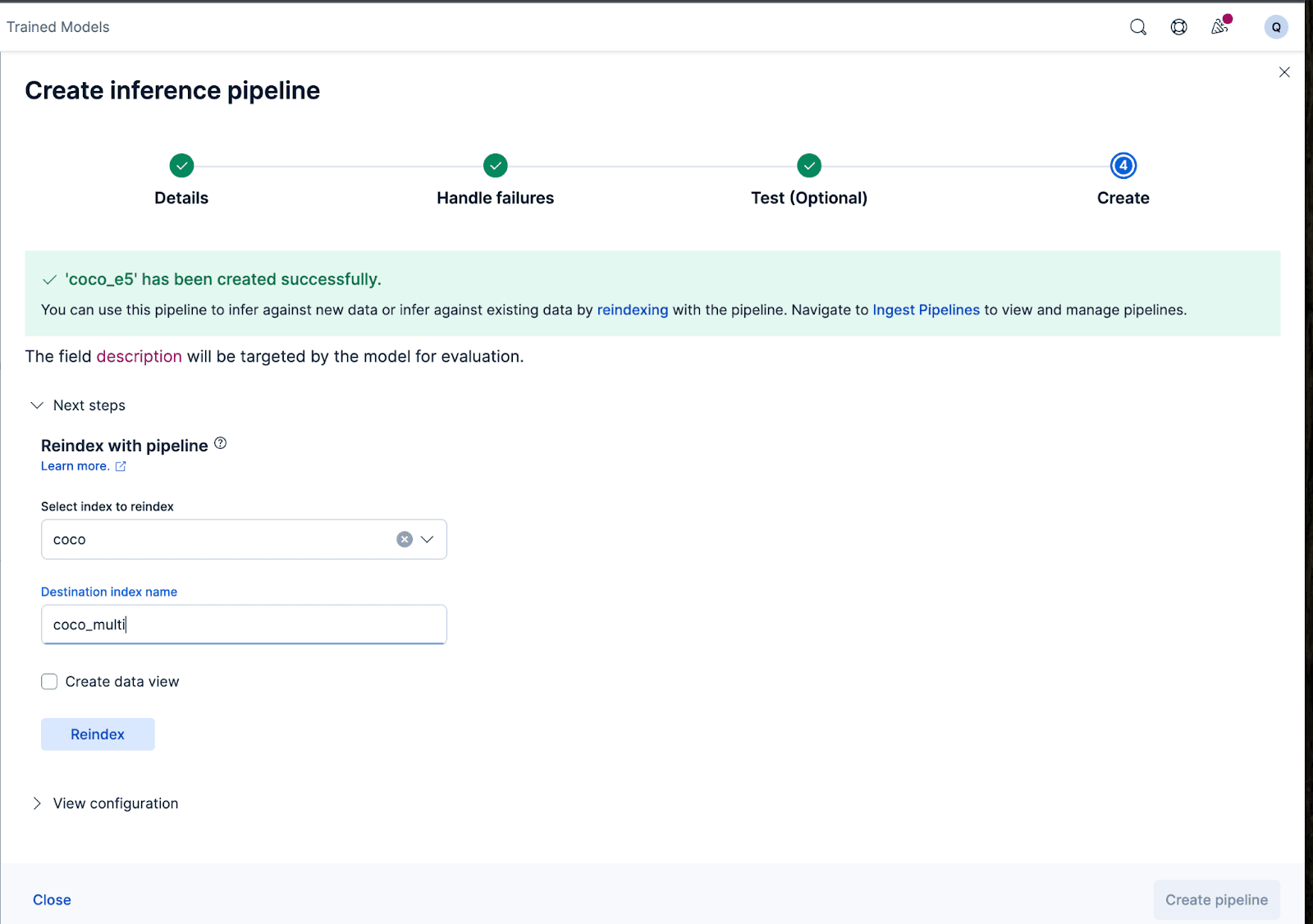
보다 복잡한 구성의 경우, Elasticsearch API를 사용할 수 있습니다.
일부 모델의 경우 모델 학습 방식에 따라 임베딩을 생성하기 전에 실제 입력에 특정 텍스트를 미리 추가하거나 추가해야 할 수 있으며, 그렇지 않으면 성능이 저하될 수 있습니다.
예를 들어, e5의 경우 모델은 입력 텍스트가 "passage: {content of passage}". 이를 위해 수집 파이프라인을 활용해 보겠습니다: 새로운 수집 파이프라인 벡터화_descriptions를 생성하겠습니다. 이 파이프라인에서는 임시 temp_desc 필드를 새로 만들고, "passage: "를 description 텍스트에 추가하고, 모델에서 temp_desc 을 실행하여 텍스트 임베딩을 생성한 다음 temp_desc 을 삭제합니다.
또한 생성된 벡터에 어떤 양자화 유형을 사용할지 지정할 수도 있습니다. 기본적으로 Elasticsearch는 int8_hnsw 을 사용하지만 여기서는 각 차원을 단일 비트 정밀도로 축소하는 Better Binary Quantization (또는 bqq_hnsw)을 사용하려고 합니다. 이렇게 하면 메모리 사용량이 96% (또는 32배)로 줄어드는 대신 정확도는 더 높아집니다. 이 정량화 유형을 선택한 이유는 나중에 정확도 손실을 개선하기 위해 리랭커를 사용할 것이라는 것을 알고 있기 때문입니다.
이를 위해 coco_multi라는 새 인덱스를 생성하고 매핑을 지정합니다. 여기서 마법은 벡터_설명필드에 있으며, 여기서 인덱스_옵션의유형을 bbq_hnsw로 지정합니다.
이제 설명 필드를 '벡터화'하거나 임베딩을 생성하는 수집 파이프라인을 사용하여 원본 문서를 새 인덱스로 재색인할 수 있습니다.
여기까지입니다! 우리는 Elasticsearch와 Kibana로 다국어 모델을 성공적으로 배포했으며, Kibana 사용자 인터페이스 또는 Elasticsearch API를 통해 Elastic으로 데이터로 벡터 임베딩을 생성하는 방법을 단계별로 배웠습니다. 이 시리즈의 두 번째 파트에서는 다국어 모델 사용의 결과와 뉘앙스에 대해 살펴봅니다. 그 동안 자체 클라우드 클러스터를 생성하여 원하는 언어와 데이터 세트에서 즉시 사용 가능한 E5 모델을 사용하여 다국어 시맨틱 검색을 사용해 볼 수 있습니다.
관련 콘텐츠

2026년 5월 18일
안전한 쿼리 실행을 위한 Elasticsearch의 결정론적 가드레일을 사용한 에이전틱 AI 검색
에이전틱 AI 검색 시스템은 LLM이 쿼리를 직접 생성할 때 실패하는 경우가 많습니다. 결정론적 가이드레일과 제어 평면 아키텍처가 어떻게 Elasticsearch를 사용해 안전하고 신뢰할 수 있는 관리형 쿼리를 실행하는 방법을 알아보세요.

2026년 5월 11일
이커머스 검색 개인화: 구매 이력 및 사용자 코호트 통합하기
거버넌스를 유지하면서 Elasticsearch에서 개인화된 이커머스 검색 경험을 구축하는 방법을 알아보세요. 본 게시물에서는 구매자가 이전에 구매했던 상품을 부스트하는 방법과 사용자 프로필을 기반으로 코호트별 맞춤 정책을 활성화하는 방법을 설명합니다.

2026년 5월 4일
전자상거래 검색 관리를 위한 Elasticsearch 퍼콜레이터: 모호한 쿼리를 통제된 검색 전략으로 변환
Elasticsearch 퍼콜레이터를 사용하여 검색 거버넌스를 구현하는 방법을 알아보세요. 이 블로그에서는 실제 운영 환경에서 거버넌스가 적용된 정책 엔진을 구축하고, 통제된 검색 전략을 만드는 데 필요한 패턴들을 설명합니다.

2026년 5월 1일
전자 상거래 검색을 관리하기 위한 제어 평면 구축
코드 변경 없이 충돌하는 검색 정책을 단일 실행 계획으로 통합하는 전자 상거래용 거버넌스 기반 제어 평면을 구축하는 방법을 알아봅니다.

2026년 4월 24일
매핑 충돌로 인한 데이터 스트림 재색인
데이터 스트림을 재색인하여 Elasticsearch 매핑 충돌을 해결하는 방법을 알아보세요. 이 블로그에서는 재색인 프로세스와 새 데이터가 올바르게 매핑되는지 확인하는 방법을 설명합니다.